x = list(range(10))
print('整数输出1: ', end = '')
for i in x:
print(i, end=' ')
print('\n整数输出2: ', end = '')
for i in x:
print(f'{i:02d}', end = '-')
print('\n整数输出3: ', end = '')
for i in x[:-1]:
print(f'{i:02d}', end = '-')
print(f'{x[-1]:02d}')
print('\n字符输出1: ', end = '')
y1 = [str(i) for i in range(10)]
print('字符输出2: ', end = '')
y2 = [str(i).zfill(2) for i in range(10)]
![]()
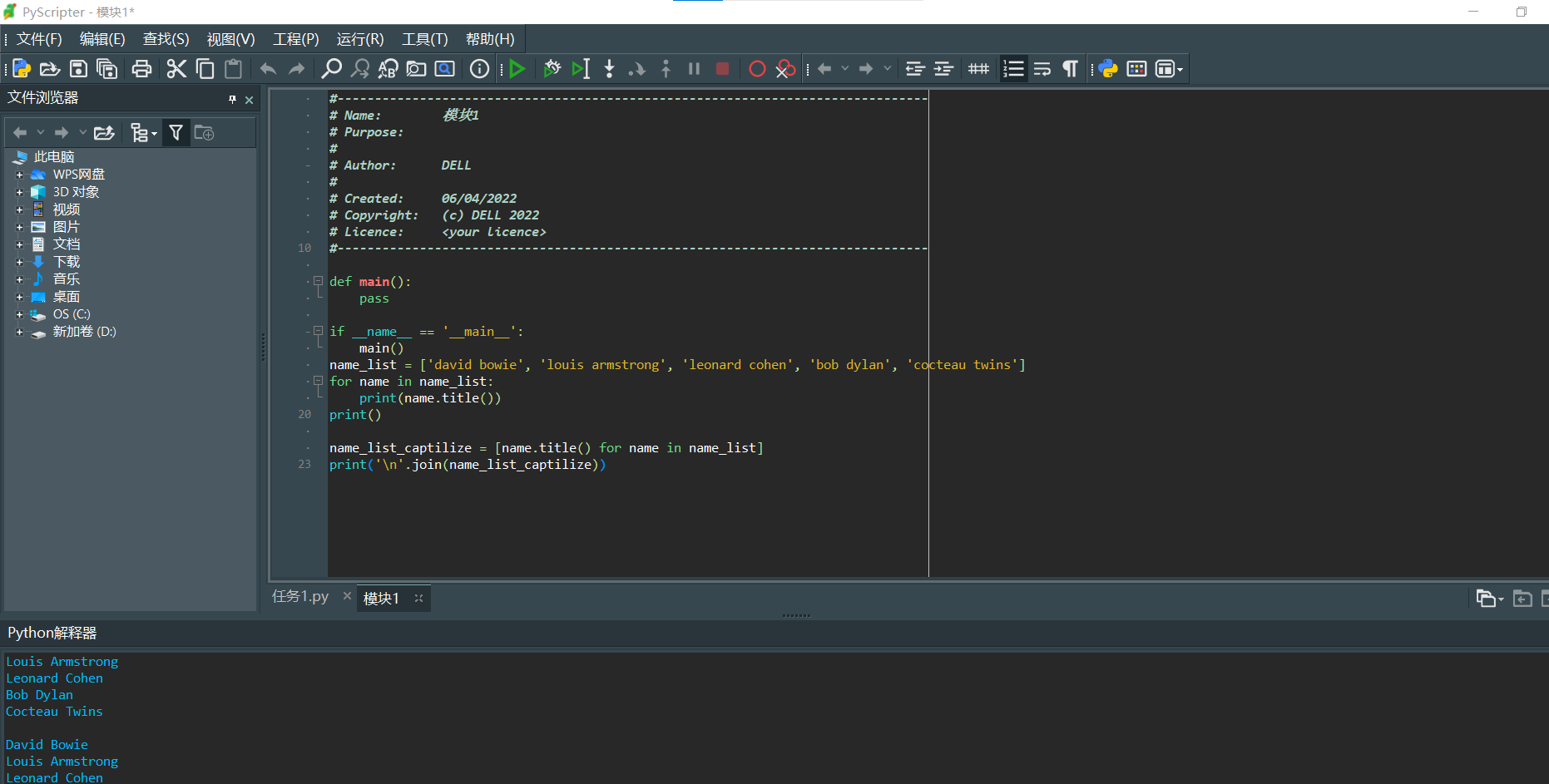
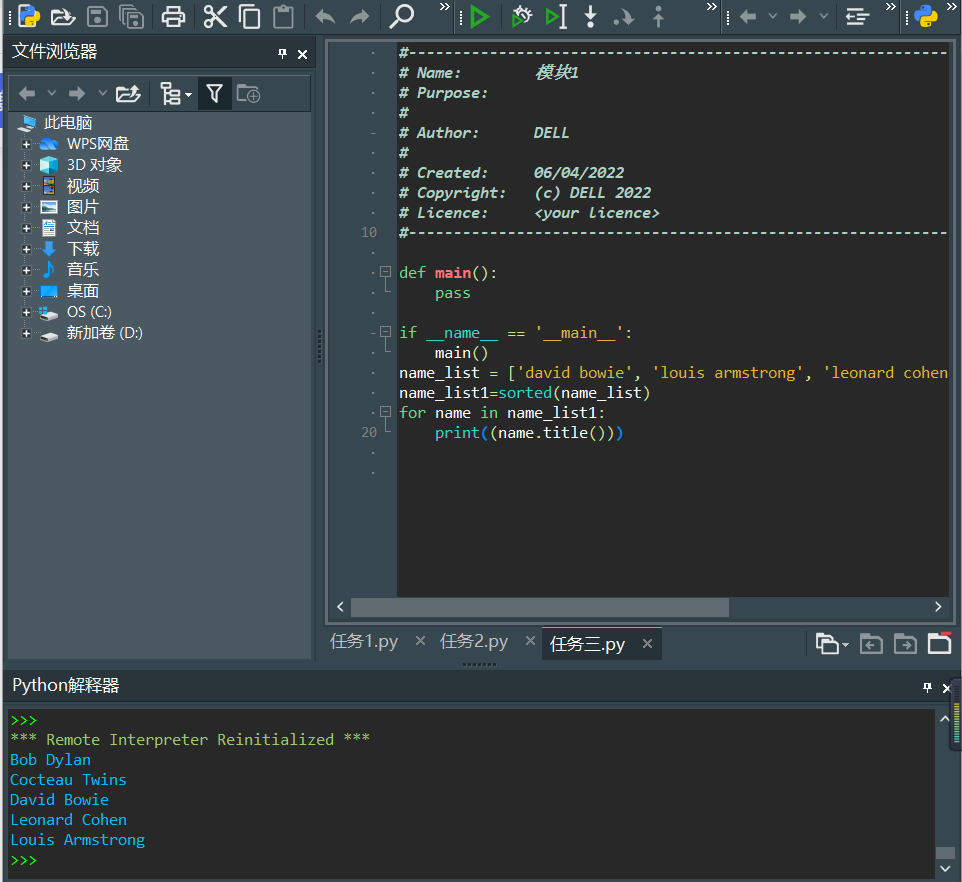
name_list = ['david bowie', 'louis armstrong', 'leonard cohen', 'bob dylan', 'cocteau twins']
for name in name_list:
print(name.title())
print()
name_list_captilize = [name.title() for name in name_list]
print('\n'.join(name_list_captilize))
![]()
data = ['99 81 75', '30 42 90 87', '69 50 96 77 89 93', '82 99 78 100']
a=data[0]
b=data[1]
c=data[2]
d=data[3]
a1=int(a[0]+a[1]+a[2])
b1=int(b[0]+b[1]+b[2]+b[3])
c1=int(c[0]+c[1]+c[2]+c[3]+c[4]+c[5])
d1=int(d[0]+d[1]+d[2]+d[3])
e=(a1+b1+c1+d1)/4
e1=round(e,2)
print(e1)
![]()
s='''import this'''
alpha,num,space,other=0,0,0,0
for i in s:
if i.isalpha():
alpha+=1
elif i.isdigit():
num+=1
elif i.isspace():
space+=1
else:
other+=1
print('英文字符数{},数字字符数{},空格字符数{},其他字符数{}'.format(alpha,num,space,other))
![]()
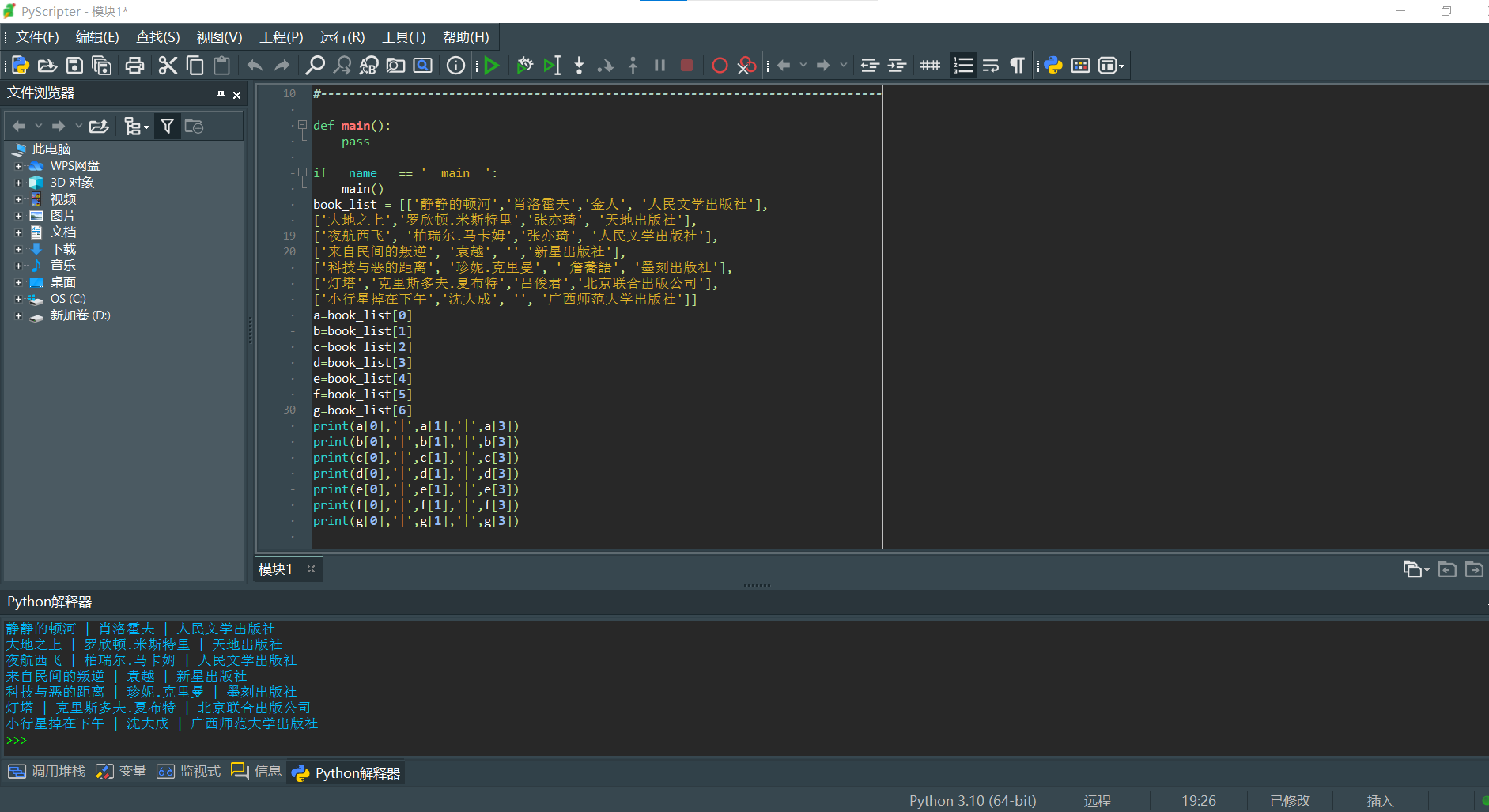
book_list = [['静静的顿河','肖洛霍夫','金人', '人民文学出版社'],
['大地之上','罗欣顿.米斯特里','张亦琦', '天地出版社'],
['夜航西飞', '柏瑞尔.马卡姆','张亦琦', '人民文学出版社'],
['来自民间的叛逆', '袁越', '','新星出版社'],
['科技与恶的距离', '珍妮.克里曼', ' 詹蕎語', '墨刻出版社'],
['灯塔','克里斯多夫.夏布特','吕俊君','北京联合出版公司'],
['小行星掉在下午','沈大成', '', '广西师范大学出版社']]
a=book_list[0]
b=book_list[1]
c=book_list[2]
d=book_list[3]
e=book_list[4]
f=book_list[5]
g=book_list[6]
print(a[0],'|',a[1],'|',a[3])
print(b[0],'|',b[1],'|',b[3])
print(c[0],'|',c[1],'|',c[3])
print(d[0],'|',d[1],'|',d[3])
print(e[0],'|',e[1],'|',e[3])
print(f[0],'|',f[1],'|',f[3])
print(g[0],'|',g[1],'|',g[3])
![]()
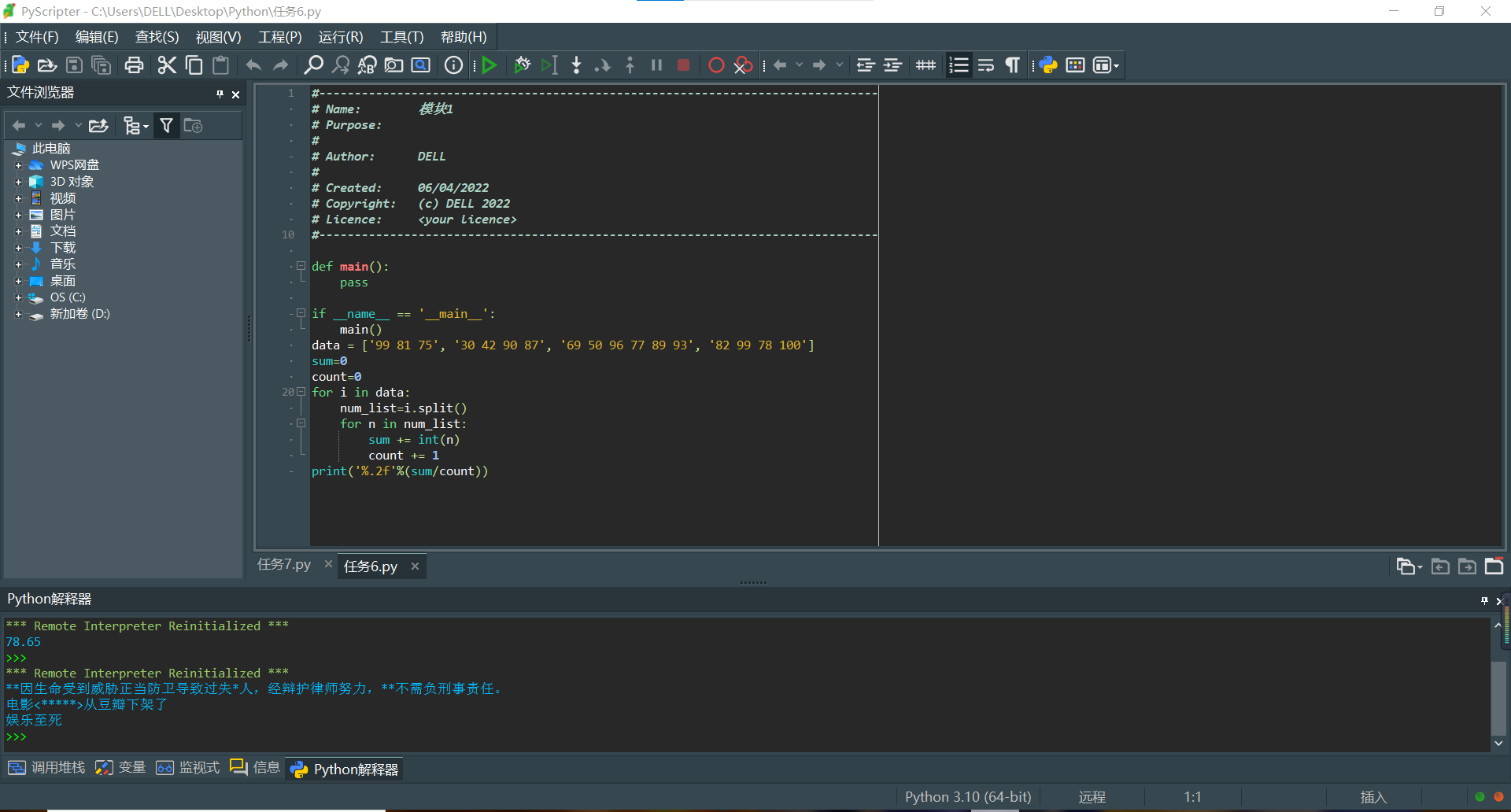
data = ['99 81 75', '30 42 90 87', '69 50 96 77 89 93', '82 99 78 100']
sum=0
count=0
for i in data:
num_list=i.split()
for n in num_list:
sum += int(n)
count += 1
print('%.2f'%(sum/count))
![]()
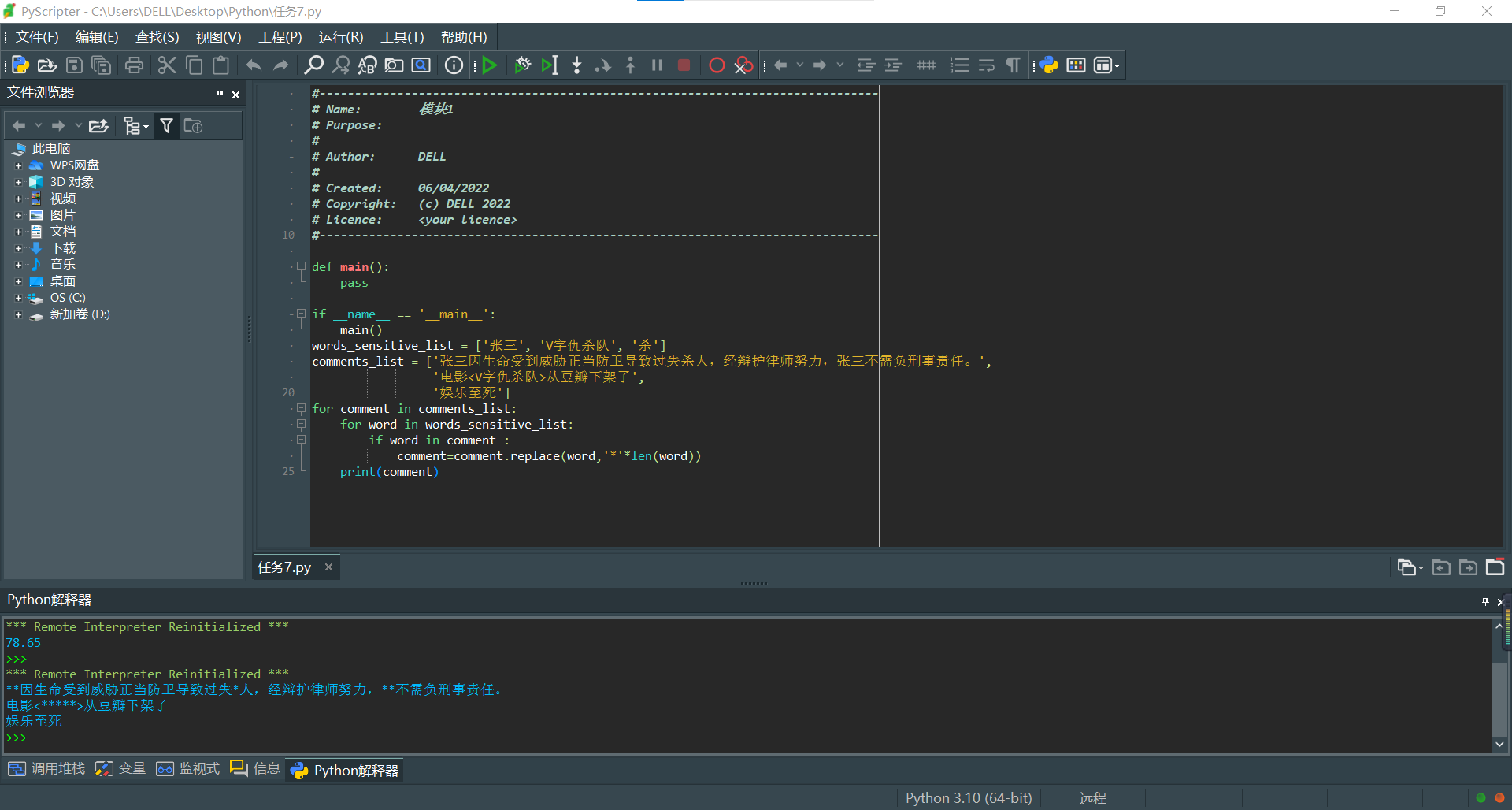
words_sensitive_list = ['张三', 'V字仇杀队', '杀']
comments_list = ['张三因生命受到威胁正当防卫导致过失杀人,经辩护律师努力,张三不需负刑事责任。',
'电影<V字仇杀队>从豆瓣下架了',
'娱乐至死']
for comment in comments_list:
for word in words_sensitive_list:
if word in comment :
comment=comment.replace(word,'*'*len(word))
print(comment)
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号