数据采集与融合技术实践第三次实验作业
数据采集与融合技术实践第三次实验作业
作业①:
1.题目
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
2.实验思路
作业选择的网站是京东的商城网站,搜索关键词“电脑”
单线程爬取:
try:
url = 'https://search.jd.com/Search'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0'
}
for page in range(1,27):#一页5张,爬130张,需要爬26页
params = {
'keyword':'电脑',
'enc':'utf-8',
'page':page
}
req = requests.get(url,params=params,headers=headers).text
#print(req.text)
reg = r'<img width="220" height="220".+jpg'
tags = re.findall(reg, req)
for index in range(1,6):#一页爬五张
name = "031904130 " + str(page) + "_" + str(index)
imgPath = "http:" + tags[index][58:] # 去除58之前的其他信息,只留下url信息
SaveImg(imgPath,name,'Single')
except:
print("requests出现异常")
return ""
多线程爬取:
imgPaths = []
for page in range(1,27):#一页5张,爬130张,需要爬26页
params = {
'keyword':'电脑',
'enc':'utf-8',
'page':page
}
req = requests.get(url,params=params,headers=headers).text
#print(req.text)
reg = r'<img width="220" height="220".+jpg'
tags = re.findall(reg, req)
for index in range(1,6):#一页爬五张
name = "031904130 " + str(page) + "_" + str(index)
imgPath = "http:" + tags[index][58:] # 去除58之前的其他信息,只留下url信息
imgPaths.append(imgPath)
多线程爬取在单线程的基础上修改了保存方式,先用列表存下所有的图片地址
for index in range(len(imgPaths)):
imgPath = imgPaths[index]
T = threading.Thread(target=SaveImg, args=(imgPath, '031904130 '+str(index//5 + 1) + '_' + str(index%5),'Multi'))
T.setDaemon(False)
T.start()
threads.append(T)
然后再用多线程方法保存图片
控制台单线程打印结果
控制台多线程打印结果
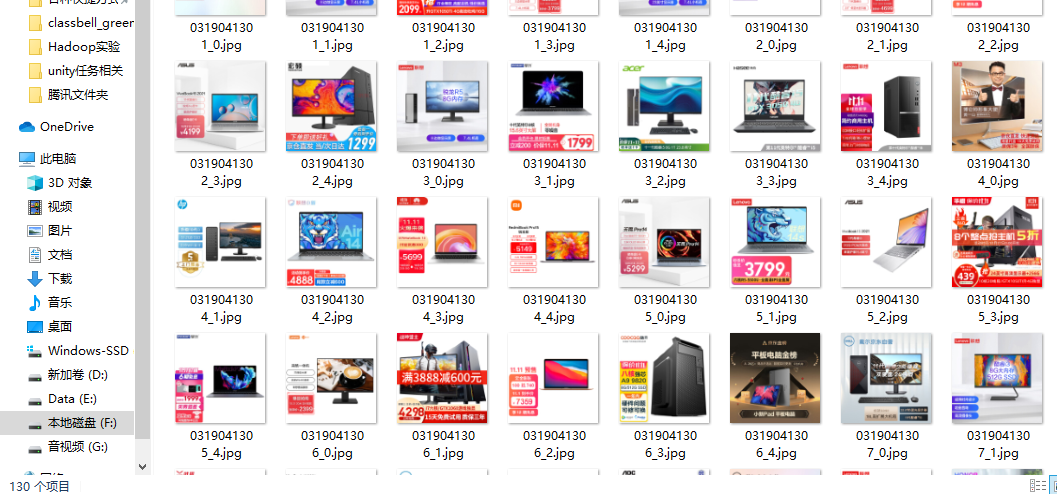
下载的图片,共130张
3.心得体会
本次实验主要复习了多线程爬取的方法
作业②:
1.题目
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
2.实验思路
class test3_2(scrapy.Spider):
name = "test3_2"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0'
}
def start_requests(self):
url = "https://search.jd.com/Search?"
for page in range(1, 27):
params = {"keyword": "电脑",
"enc": 'utf-8',
"page": str(page)}
# 构造get请求
yield scrapy.FormRequest(url=url, callback=self.parse, method="GET",headers=self.headers,formdata=params)
获取需要爬取的url,构造get请求
def parse(self, response):
try:
req = response.text
#print(req)
reg = r'<img width="220" height="220".+jpg'
tags = re.findall(reg, req)
for index in range(1, 6): # 一页爬五张
item = Test32Item()
item["imgUrl"] = "http:" + tags[index][58:]
print(item["imgUrl"])
yield item
except Exception as err:
print(err)
进一步parse函数获取response然后用正则表达式获取其中的url(同①)
def process_item(self, item, spider):
try:
image = requests.get(item['imgUrl'])
# 以二进制格式打开文件用于写入,从头编辑(已有文件会删除)
f = open('images/' + item['imgUrl'].split('/')[-1], 'wb')
# 将下载到的图片二进制数据写入文件
f.write(image.content)
f.close()
print("图片保存成功,url = " + item['imgUrl'])
except Exception as err:
print(err)
return item
最后在pipelines中获取图片信息并保存

控制台打印信息
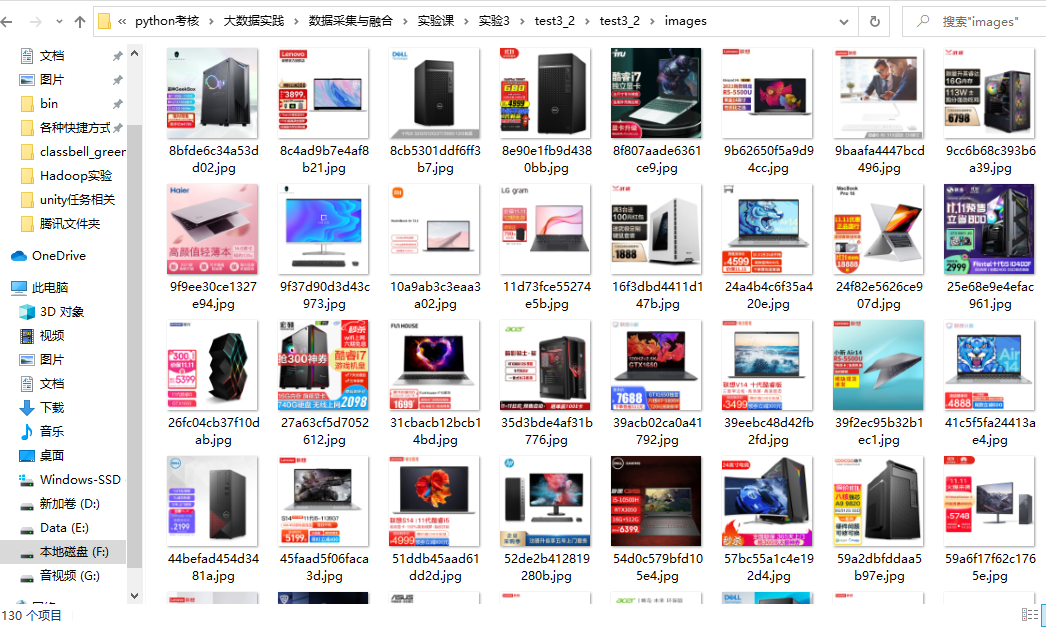
下载的图片
3.心得体会
本次实验主要熟悉scrapy框架
作业③:
1.题目
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
候选网站: https://movie.douban.com/top250
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2.... |
2.实验思路
class Test33Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
no = scrapy.Field()
name = scrapy.Field()
director = scrapy.Field()
actor = scrapy.Field()
introduction = scrapy.Field()
score = scrapy.Field()
image = scrapy.Field()
url = scrapy.Field()
pass
在items中记录需要获取的信息
def start_requests(self):
url = "https://movie.douban.com/top250?"
#爬10页,每页的start参数都是25*页数
for page in range(0,10):
params = {"start": str(25*page),
"filter": ''}
# 构造get请求
yield scrapy.FormRequest(url=url, callback=self.parse, method="GET",headers=self.headers,formdata=params)
构造get请求
def parse(self, response):
try:
data = response.body.decode("utf-8")
selector = scrapy.Selector(text=data)
movies = selector.xpath("//li/div[@class='item']")
for movie in movies:
item = Test33Item()
item['no'] = int(movie.xpath(".//em[@class='']/text()").extract_first())
item['name'] = movie.xpath(".//span[@class='title']/text()").extract_first()
item['director'] = movie.xpath(".//div[@class='bd']/p/text()").extract_first().split(':')[1][:-2]
item['actor'] = movie.xpath(".//div[@class='bd']/p/text()").extract_first().split(':')[-1]
item['introduction'] = movie.xpath(".//span[@class='inq']/text()").extract_first()
item['score'] = movie.xpath(".//span[@property='v:average']/text()").extract_first()
item['url'] = movie.xpath(".//img/@src").extract_first()
item['image'] = item['url'].split('/')[-1]
逐一获取需要的信息
class Test33Pipeline:
db = MovieDB()
def __init__(self):
self.db.openDB()
def process_item(self, item, spider):
try:
image = requests.get(item['url'])
# 以二进制格式打开文件用于写入,从头编辑(已有文件会删除)
f = open('imgs/' + item['image'], 'wb')
# 将下载到的图片二进制数据写入文件
f.write(image.content)
f.close()
print(item['name'] + "图片保存成功,path="+item['image'])
self.db.insert(item['no'],item['name'],item['director'],item['actor'],item['introduction'],item['score'],item['image'])
except Exception as err:
print(err)
return item
最后在pipelines中下载图片并保存到数据库中


数据库的信息(分别为排序前和排序后)
下载的图片
3.心得体会
本次实验再次使用了scrapy框架,并且使用了数据库进行保存信息,可以更加熟悉scrapy框架和数据库的使用方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号