数据采集与融合技术实践第二次实验作业
数据采集与融合技术实践第二次实验作业
作业①:
1.题目
-
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
-
输出信息:
序号 地区 日期 天气信息 温度 1 北京 7日(今天) 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 31℃/17℃ 2 北京 8日(明天) 多云转晴,北部地区有分散阵雨或雷阵雨转晴 34℃/20℃ 3 北京 9日(后台) 晴转多云 36℃/22℃ 4 北京 10日(周六) 阴转阵雨 30℃/19℃ 5 北京 11日(周日) 阵雨 27℃/18℃ 6......
2.实验思路
def RequestsGetSoup(u):
try:
url = u
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3776.400'
}
r = requests.get(url=url, headers=headers)
r.encoding = 'utf-8'#修改编码方式
#print(r.text)
soup = BeautifulSoup(r.content, 'lxml')
#print(soup.prettify())
#GetInfo(soup)
return soup
except:
print("出现异常")
return None
soup = RequestsGetSoup('http://www.weather.com.cn/weather/101040100.shtml')
用requests方法和beautifulsoup获取soup
#城市
tags = soup.select('div[class="crumbs fl"] > a')
city.append(tags[1].text)
#日期
tags = soup.select('h1')
#tags = soup.select('li[class="sky skyid lv3"] > hl')
for index in range(7):#获取前7个
date.append(tags[index].text)
#天气信息
tags = soup.select('p[class="wea"]')
for tag in tags:
wea.append(tag.text)
#温度
tags = soup.select('p[class="tem"]')
for tag in tags:
tem.append(tag.text.replace("\n",""))
依次获取城市、日期、天气信息、温度等需要的信息
db = WeatherDB()
db.openDB()
for i in range(len(date)):
db.insert(city[0], date[i], wea[i], tem[i])
db.show()
db.closeDB()
将其存入数据库中

最后数据库的结果
3.心得体会
作业1复习了requests和beautifulsoup的用法,并且具体实践了数据库的简单用法
作业②
1.题目
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
-
输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
2.实验思路
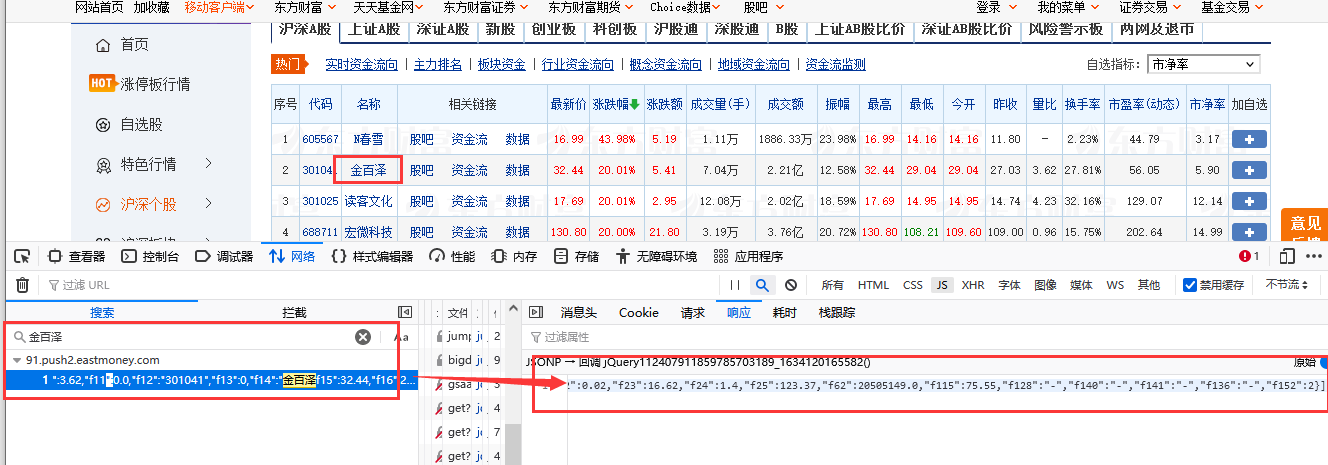

通过搜索快速找到股票列表加载使用的url
url =
'http://60.push2.eastmoney.com/api/qt/clist/get?pn={}&pz={}&po=1&np=1&fltt=2&invt=2&fid=f3&fs=m:1+s:2&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1634093266574'.format(1, 40)
测试后发现其中的cb、ut参数可以删除,pn参数表示页码,pz参数表示一页的股票信息数量,因此可以调成pn=1,pz=40用于爬取40个股票信息
html = requests.get(u).text
textJson = json.loads(html.split("(")[-1].split(")")[0])#获取json格式的信息
#print(textJson)
通过split获取括号里的json信息

db = ShareDB()
db.openDB()
for dataList in textJson['data']['diff']:
db.insert(dataList['f12'],
dataList['f14'],
dataList['f2'],
dataList['f3'],
dataList['f4'],
dataList['f5'],
dataList['f6'],
dataList['f7'],
dataList['f15'],
dataList['f16'],
dataList['f17'],
dataList['f18'],
)
# db.show()
db.closeDB()
观察F12响应里的数据与网页显示的数据,可以得知每个f对应的数值,存入需要的数值

最后数据库的结果
3.心得体会
作业2实践了用F12获取股票列表这种动态数据的信息,与以往的爬虫都有所不同
作业③:
1.题目
- 要求: 爬取中国大学2021主榜 https://www.shanghairanking.cn/rankings/bcur/2021
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。 - 技巧: 分析该网站的发包情况,分析获取数据的api
- 输出信息:
| 排名 | 学校 | 总分 |
|---|---|---|
| 1 | 清华大学 | 969.2 |
2.实验思路

获取url的过程:与作业2类似,用搜索找到存有所有学校信息的url
def RequestsGetText(u):
try:
text = requests.get(u).text
return text
except Exception as e:
print("出现异常", e)
return None
url = 'https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/2021/payload.js'
html = RequestsGetText(url)
获取网页text
def GetInfo(text):
db = SchoolDB()
db.openDB()
name = re.findall(r'univNameCn:"(.*?)"', text)
score = re.findall(r'score:(.*?),', text)
rank = []
获取需要的校名和总分信息
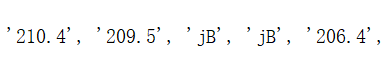
其中score会出现一些不是分数的英文字符串,比如‘jB’,'mz',与原网站对比后发现这些都是相同总分时出现的情况,此时总分相同的学校的排名也相同,因此需要检测并修改英文数据
for i in range(len(name)):
rank.append(i+1)
#有一些总分相同排行相同的情况,分数是一些字母,这时需要特殊处理
try:
float(score[i])
except:
#运行此处代码说明该学校与上一个学校是同成绩,则修改这个学校的成绩和排名
score[i] = score[i-1]
rank[i] = rank[i-1]
db.insert(i,rank[i],name[i],score[i])
db.show()
db.closeDB()
我使用的方法是检查是否能够将成绩转换为浮点数,如果不行就说明是与上一个学校成绩相同,复制上一个学校的成绩和排名,最后存入数据库

最后数据库显示结果,其中排名相同的学校排名、成绩都能正常显示
3.心得体会
作业3再次使用F12获取了学校所有信息的url,并且用了一些特殊方法处理获取到的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号