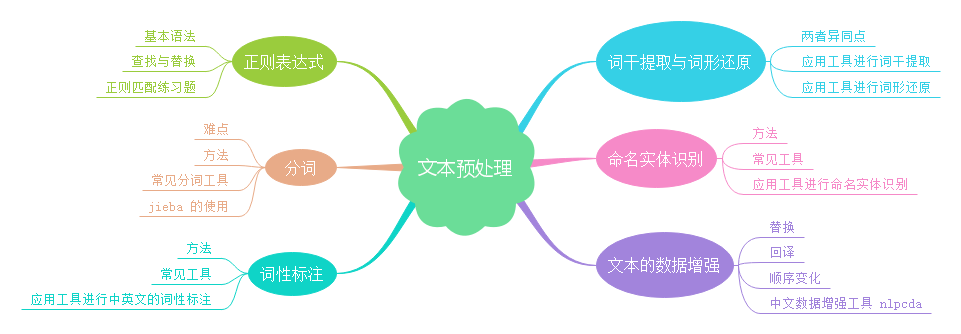
文本数据处理
文本数据处理
情无论巨细,往往存在一个准备阶段。比如做饭炒菜,需要择菜、洗菜、切菜、热锅等准备工作;出远门需要整理好身份证、手机、钱包等随身物品。类似地,在处理文本的任务中,也存在预处理这么一个重要阶段,包括诸如统一数据格式、去噪、词形还原、分词之类的基本操作,以及语义分析、关键词提取、对于数据不平衡的处理等更进一步的精细处理。
知识点
- 正则表达式
- 分词
- 词性标注
- 词干提取与词形还原
- 命名实体识别
- 文本的数据增强
正则表达式
假设有一天,你的上司给你几百个 txt 文本,并且布置了一个任务,找出文本中所有出现的身份证号以及电话号码,并且要求在一个小时内完成。这时候该怎么办呢?总不可能肉眼一个个地去找吧,太费时了!在这里,正则表达式就派上用场了。学会了正则表达式,你就能在 20 分钟内完成此任务。
正则表达式,又称规则表达式,英语称为 Regular Expression,通常被用来检索、替换那些符合某个模式(规则)的文本,例如在以上任务中匹配身份证号或者电话号码,是在文本预处理过程中常用的技术。
那么,正则表达式怎么写呢?在这之前,让我们首先来熟悉一些基本的正则表达式的语法:
- . : 能够匹配除换行符 \n 以外的任意单个字符。
- \w :与单个字母数字字符匹配。
- \W :与单个非字母数字字符匹配。
- \d :与单个数字匹配。
- \D :与单个非数字匹配。
- \s :与单个空格字符(空格,换行符,返回符,制表符,表格)匹配。
- \S :与任何非空格字符匹配。
- \t :匹配单个 tab 符。
- \n :匹配单个换行符。
- \r :匹配单个回车符。
- ^ 和 $ :分别匹配字符串的开头或结尾。
- [..] :匹配方括号中..表达的字符。
- [^..] :匹配方括号中..表达以外的任何字符。
- {m,n} :匹配前一个字符的出现次数在 m 至 n 次之间。
- a|b :匹配 a 或 b。
- ?:匹配前一个字符出现次数 0 或 1。
- +:模式前一个字符出现 1 次或多次。
- *:模式前一个字符出现 0 次或多次。
- \ :转义字符,通常用于将一些被占用成为正则表达的符号还原为原来的意思,比如 + 表示加号。
- ():被括起来的表达式部分将作为分组,并返回相匹配的文本。
如果是第一次接触正则表达式的朋友,可能会觉得这些语法有些难记有些抽像,并且难以理解,这是正常现象,不必担心。事实上,我们通过一些代码示例及练习,便可以快速地在实践中学会灵活使用正则表达式。而在 Python 中,通过内嵌集成 re 模块,我们可以直接调用从而快速实现正则匹配,re 中常用的功能有:
- re.match():从字符串中的首字符开始匹配相应的模式串。
- re.search():从字符串中的任意位置都可以匹配相应的模式串,只要找到第一个匹配即返回,如果字符串没有匹配,则返回 None 。
- re.findall():从字符串中的任意位置都可以匹配相应的模式串,找到所有匹配情况后返回,如果字符串没有匹配,则返回 None 。
- re.sub():从字符串中的任意位置都可以匹配相应的模式串,找到所有匹配情况后替换成希望的表达形式,返回替换后的字符串。
注:这里的“模式串”,英文称为 pattern,指的便是使用正则语法所构成的一种表达式。
接下来分别就 re.match(),re.search(),re.findall() 做一些简单的代码演示,同学们可以观察结果,深入理解这三者的区别。
import re
# r'自然语言'指模式串,'自然语言处理'指要被匹配的字符串
# 注:模式串前加 r 是为了防止字符转义
result = re.match(r'自然语言', '自然语言处理')
print(result) # 匹配成功返回一个匹配的对象,否则返回None
# <re.Match object; span=(0, 4), match='自然语言'>
基于不同函数获取结果的不同部分:
print('Matching string :', result.group()) # 获取被匹配到的部分
print('Starting position of the match :', result.start()) # 获取被匹配到的部分初始位置
print('Ending position of the match :', result.end()) # 获取被匹配到的部分结束位置

result = re.match(r'语言', '自然语言处理') # 注意 match 需要从首字符开始匹配
print(result) # 匹配成功返回一个匹配的对象,否则返回 None
# None
# 搜寻字符串中任意位置都可能匹配的模式串,找到首个即返回
result = re.search(r'语言', '自然语言处理自然语言')
print(result) # 匹配成功返回一个匹配的对象,否则返回 None
print('Matching string :', result.group()) # 获取被匹配到的部分

# 搜寻字符串中任意位置都可能匹配的模式串,遍历匹配,可以获取字符串中所有匹配的字符串,
result = re.findall(r'语言', '自然语言处理自然语言')
print(result) # 返回一个列表
# ['语言', '语言']
在这里总结一下 re.match() , re.search() 以及 re.findall() 之间的区别:
- re.match() 只从字符串的开始位置进行匹配,如果字符串不符合正则表达式,则匹配失败,函数返回 None ;
- re.search() 匹配整个字符串,从任意位置都可以开始匹配,直到找到一个匹配即返回 ;
- re.findall() 则会找到所有匹配结果并返回。
如果想替换字符串中的符合某些模式的地方,可以使用 re.sub():
# r'自然语言'指模式串,'language'指替换内容,'自然语言处理'指要被匹配的字符串
result = re.sub(r'语言', 'language', '自然语言处理语言')
print(result)
通过以上简单的例子,我们熟悉了 re 模块中一些常用函数的功能,接下来增加难度,尝试用更复杂的正则表达式语法规则来解决一些实际问题。
题目:抽取一段英文中的首个单词。
# 使用了模式串 r'^\w+',这是因为 ^ 表示字符串的开始部分,而 \w+ 可以表示多个连续的字母。
result = re.findall(r'^\w+', 'Whatever is worth doing is worth doing well.')
print(result)
# ['Whatever']
题目:返回邮箱地址中的域名。
# r'@\w+\.(\w+)' 中最后的 \w+ 左右加了括号,因此只会返回括号中匹配的部分
# . 能够匹配除换行符 \n 以外的任意单个字符,这里需要匹配原本的 . 所以加上转义字符变为 \.
result = re.findall(
r'@\w+\.(\w+)', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print(result)
# ['com', 'in', 'com', 'biz']
题目:返回字符串中固定格式的日期,如 11-09-2020。
# \d{2}表示两个数字,同理得表达式为 r'\d{2}-\d{2}-\d{4}'
result = re.findall(
r'\d{2}-\d{2}-\d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print(result)
# ['12-05-2007', '11-11-2011', '12-01-2009']
题目:只保留字符串中的中文字符。
# 中文的Unicode范围为 \u4e00-\u9fa5,前面加 ^ 表示非汉字
# 注意 ^ 放在[]中才表示“非”的意义,而放在外面则表示“初始位置”的意义
result = re.sub(r'[^\u4e00-\u9fa5]', '', 'language自然!!·~语言##处理;’;')
print(result)
# 自然语言处理
题目:验证是否为身份证号码。
注:身份证号可能为 15 或 18 位,15 位全为数字,18 位中前 17 位为数字,最后一位为 X 或者 x。
# r'(^\d{15}$)|(^\d{18}$)|(^\d{17}(X|x)$)' 中三个大括号中的表达式分别对应以上三种情况
# 一头一尾的 ^ 以及 $ 表明匹配的范围是字符串的起止范围
result = re.match(
r'(^\d{15}$)|(^\d{18}$)|(^\d{17}(X|x)$)', '94023856739300998X')
print(result)
分词
分词是自然语言处理中的重要步骤,也就是将句⼦、段落、⽂章这种⻓⽂本,分解为以词为基本单位的数据结构,⽅便后续的处理分析⼯作。为什么要分词呢?这是因为词是表达完整含义的最⼩单位,将文本进行分词后,可以做更细化的文本表征(例如词袋模型、词向量等方式)以及更多的预处理操作(如提取关键词、获取主题)。那为啥不分字或者以句子为单位呢?一方面,字的粒度太⼩,⽆法表达完整含义,⽐如”⿏“可以是”⽼⿏“,也可以是”⿏标“。 另一方面,句⼦的粒度太⼤,承载的信息量多,很难复⽤。所以一般用粒度适中的词作为切分单位。
当然,在有些情况下,分字也可能是更好的选择,比如,处理的文本是古文,这是因为古文中大多以字为词。另外,分字不容易遇到未登录字(专业术语,其实就是“生词”的意思)的问题,而分词容易遇到未登录词的问题。这是因为中文中的字的数量远远小于词的数量,因此很容易在训练文本中覆盖大部分的测试文本中的字。而有的时候,我们也会对粒度进行扩张,比如有些固定短语或者专业术语经常搭配出现(神经网络,支持向量机),也会被当作切分的单位。因此,我们需要根据具体情况进行切分分析。英⽂有天然的空格作为分隔符,但是中⽂没有。所以如何切分中文是⼀个难点,再加上中⽂⾥⼀词多义的情况⾮常多,导致很容易出现歧义,可以简单地概括为以下三大难点:
- 没有统⼀的标准:⽬前中⽂分词没有统⼀的标准,也没有公认的规范,比如 “中华人民共和国”可以看作一个词汇,也可以看作三个词汇,“中华/人民/共和国”,因此很多词汇本身存在分词歧义性。
- 歧义词难以切分:比如 “羽毛球拍卖完了”可以切分为 “羽毛球/拍卖/完了”或者 “羽 毛球拍/卖/完了”,在语法上都逻辑正确,需要一定的生活常识或者联系上下文才能断定到底哪种分词模式更正确。
- 未登录词难以识别:信息爆炸的时代,三天两头就会冒出来⼀堆新词,如何快速地识别出这些新词是⼀⼤难点。⽐如「我方了」、「奥利给」等等,就需要实时更新词表才能准确识别。
分词的⽅法⼤致分为三类:
-
基于词典的匹配分词⽅式:
- 优点:速度快、成本低。
- 缺点:适应性不强,不同领域效果差异⼤。
- 基于词典的匹配,首先将待分词的中⽂⽂本根据⼀定规则切分和调整,然后和词典中的词语进⾏匹配,匹配成功则按照词典的词分词,匹配失败通过调整或者重新选择,如此反复循环即可。代表⽅法有正向最⼤匹配和逆向最⼤匹配及双向匹配法。
-
基于统计的分词⽅法:
- 优点:适应性较强。
- 缺点:成本较⾼,速度较慢。
- ⽬前常⽤的是算法是 HMM 、CRF 、SVM 、深度学习等算法,⽐如 stanford 、Hanlp 分词⼯具便是基于 CRF 的算法。以 CRF 为例,基本思路是对汉字进⾏标注训练,不仅考虑了词语的出现频率,还考虑上下⽂,具备较好的学习能⼒,因此其对歧义词和未登录词的识别都具有良好的效果。
-
基于深度学习:
- 优点:准确率⾼、适应性强。
- 缺点:成本⾼,速度慢。
- 可以使⽤双向 LSTM+CRF 实现分词器,其本质上也是序列标注,所以有通⽤性,命名实体识别等都可以使⽤该模型,准确率较⾼,但是需要大量标注数据。
常⻅的分词器都是使⽤机器学习算法和词典相结合的方法,⼀⽅⾯能够提⾼分词准确率,另⼀⽅⾯能够改善领域适应性。
注:对于如何把分词问题转化为序列标注问题,这里有些朋友可能会觉得疑惑。实际上我们可以这样来做: 分别用 B、M、E 来表示某词的头、中、尾三部分,并且 S 代表单字成词。以句子 “王先生就职于武汉大学”为例,以每个字为单位对其进行序列标注,便是 “BMEBESBMME”,再根据词的头、中、尾规则进行切分成词,便是 “BME/BE/S/BMME”,如此一来,便可以对应到分词结果 “王先生/就职 /于/武汉大学”。
根据 GitHub 上的 star 数排名的中文分词工具:
- Hanlp
- Stanford 分词
- ansj 分词器
- 哈⼯⼤ LTP
- KCWS分词器
- jieba
- 清华⼤学THULAC
- ICTCLAS
在实际应用中,一般情况下,我们只需要调包进行分词就可以了,几行代码就能搞定分词。接下来以 jieba 为例,我们来实现中文的分词。
全模式,也就是会把所有可能的分词结果都展示出来:
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list))
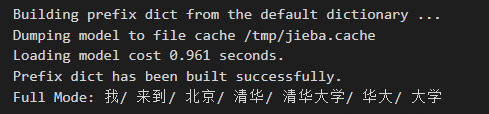
确模式,只取一种最有可能的切分方式:
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))

搜索引擎模式,在精确模式的基础上,对长词再次划分:
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造")
print(", ".join(seg_list))

当然,简单的调包有时候在下游任务中并不完全适用,比如难以正确地切分一些专业词汇、领域词汇或者新出现的词汇,可以通过在 jieba 中添加新词的方式进行解决。如何应用呢?首先,我们要新建一个词典文件,如 new_word.txt ,其中的内容规则如下:
- 一个新词占一行。
- 每一行分三部分:词语、词频 freq(可省略)、词性 tag(可省略),用空格隔开,顺序不可颠倒。
- 文件优先用UTF-8来编码。
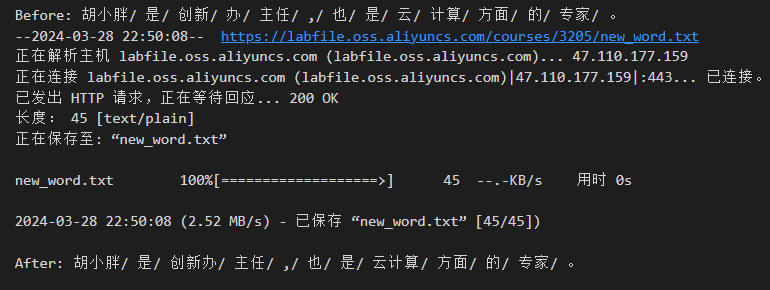
最后,通过 jieba.load_userdict(file_path) 就能加载新的词典,其中 file_path 表示词典文件的路径,我们可以对比新词载入前后的效果。
# 示例:
seg_list = jieba.cut("胡小胖是创新办主任,也是云计算方面的专家。", cut_all=False)
print("Before: " + "/ ".join(seg_list))
!wget -nc "https://labfile.oss.aliyuncs.com/courses/3205/new_word.txt"
jieba.load_userdict("new_word.txt")
seg_list = jieba.cut("胡小胖是创新办主任,也是云计算方面的专家。", cut_all=False)
print("After: " + "/ ".join(seg_list))
另外需要注意的是,如果新词数较少,通过创建、导入词典的文件过于复杂,或者定义了词典,又想做一些改动。在这些情况下,可以通过在代码中使用 add_word(word, freq=None, tag=None) 和 del_word(word) ,在程序中动态修改词典:
- add_word(word, freq=None, tag=None):添加新词。
- del_word(word) :去除某个词。
# 在程序中动态地去除新词“创新办”
jieba.del_word("创新办")
seg_list = jieba.cut("胡小胖是创新办主任,也是云计算方面的专家。", cut_all=False)
print("After: " + "/ ".join(seg_list))

词性标注
首先观察这样两个文本:
- “我好喜欢跑步啊”
- “我好喜欢跑步”
其中的助词 “啊” 存不存在对于语义并无太大影响,而“跑步”好像是句子中非常关键的单词。
通过以上例子可知,一般而言,文本里的动词可能比较重要,而助词可能不太重要,那么这个时候可以先对词汇进行词性标注(即在文本中判定每个词的语法范畴,确定其词性并加以标注的过程,这也是⾃然语⾔处理中⼀项⾮常重要的基础性⼯作),再基于词性提取关键词。因此,词性标注为文本处理提供了相当关键的信息。
特别地,中文是⼀种缺乏词形态变化的语⾔,词的类别不能像印欧语那样,直接从词的形态变化上来判别。在中文- 中,常⽤词兼类(某一词具备多种词性)现象严重,比如:
- “这个领导我不喜欢”
- “我不喜欢他领导我们的方式”
其中 “领导” 在不同的语境下分别为 “名词” 以及 “动词”,因此 “领导” 便是一个 “兼类词”。常⽤词中兼类词所占的⽐例⾼达 22.5%,⽽且越是常⽤的词,不同的⽤法越多。由于兼类使⽤程度⾼,兼类现象涉及汉语中⼤部分词类,因⽽造成在汉语⽂本中词类歧义排除的任务量巨⼤。
词性标注的方法可大致分为四类:
- 基于规则的词性标注⽅法:较早的⼀种词性标注⽅法,其基本思想是按兼类词搭配关系和上下⽂语境建造词类消歧规则。早期的规则⼀般由⼈⼯构建。随着标注语料库规模的增⼤,可利⽤的资源也变得越来越多,这时候以⼈⼯提取规则的⽅法显然有些力不从心,而需要通过数据统计让机器发现一些规律。
- 基于统计模型的词性标注⽅法:将词性标注看作是⼀个序列标注问题。其基本思想是,给定带有各⾃标注的词的序列,我们可以确定下⼀个词最可能的词性。常用的模型有有隐⻢尔可夫模型(HMM)、条件随机场(CRF)等统计模型。
- 基于统计⽅法与规则⽅法相结合的词性标注⽅法 :这类⽅法的主要特点在于对统计标注结果的筛选,只对那些被认为可疑的标注结果,才采⽤规则⽅法进⾏歧义消解,⽽不是对所有情况都既使⽤统计⽅法⼜使⽤规则⽅法。
- 基于深度学习的词性标注⽅法:可以当作序列标注的任务来做,⽬前深度学习解决序列标注任务常⽤⽅法包括 LSTM+CRF、BiLSTM+CRF 等。
同分词一样,词性标注也属于于自然语言处理中较底层、技术较为成熟的基础任务,应用现成的工具可以轻松实现,以下是一些常见的具备词性标注功能的工具:
- jieba
- SnowNLP
- THULAC
- StanfordCoreNLP
- HanLP
- NLTK
- SpaCy:注意不⽀持中⽂
接下来以 jieba 为例,我们来实现中文的词性标注。
import jieba.posseg
# jieba.posseg.cut()能够同时实现分词并词性标注
sentence_taged = jieba.posseg.cut("胡小胖是创新办主任,也是云计算方面的专家。")
for i in sentence_taged:
print(i.word, i.flag) # flag 即表示词性

词干提取与词形还原
在初学英语的时候,相信大家都会遇到一个令人头疼的问题,同一个单词在不同情况下会发生时态变化。实际上对于机器而言,这也对文本的后续处理造成了一定困扰,比如我在搜索引擎中键入 “apple”,查询相关的文章,假如有个文本中包含了 "apples" ,它是否也该返回作为搜索结果呢?理论上是的。所以在这里,就需要对文本中的 "apples" 做一些特殊处理,以便其能与 “apple” 产生关联,这里就涉及到了两种技术,即词干提取以及词形还原。
词⼲提取,英文称为 Stemming,指的是去除单词的前后缀得到词根的过程,一般应⽤于扩展检索。常⻅的前后词缀有「第三人称」、「进⾏式」、「过去分词」等,对于单词 "walk",有如下变化形式:
- 「第三人称」:walks
- 「进⾏式」:walking
- 「过去分词」:walked
它们在进行词干提取后,都得到 "walk"。
词形还原,英文称为 Lemmatisation,指的是基于词典,将单词的复杂形态转变成最基础的形态,属于文本预处理中的前序步骤,将一些词汇统一成一般形式以便后续的分析处理。词形还原不是简单地将前后缀去掉,⽽是会根据词典将单词进⾏转换。比如:
- are
- is
- been
- was
- were
以上单词在进行词形还原后,均得到 "be"。
很多人对词干提取与词形还原的定义还是觉得模糊,事实上,两者确实存在一些相似之处:
- ⽬标类似:词⼲提取和词形还原的⽬标均为将词的屈折形态或派⽣形态简化或归并为词⼲或原形的基础形式,都是⼀种对词的不同形态的统⼀归并的过程。
- 结果部分交叉:⼀部分词利⽤这两类⽅法都能达到相同的词形转换效果,如 “dogs” 的词⼲为 “dog” ,其原形也为 “dog”。
- 主流实现⽅法类似:均是利⽤语⾔中存在的规则或利⽤词典映射提取词⼲或获得词的原形。
当然,两者也存在很多不同之处:
- 变换原理不同:词⼲提取主要是采⽤“缩减”的⽅法,将词转换为词⼲,如将 “cats” 处理为 “cat”,将 “effective” 处理为 “effect”。⽽词形还原主要采⽤“转变”的⽅法,将词转变为其原形,如将 “drove” 处理为 “drive”,将 “driving” 处理为 “drive”。
- 算法复杂性不同:词⼲提取⽅法相对简单,词形还原则需要返回词的原形,需要对词形进⾏分析,不仅要进⾏词缀的转化,还要进⾏词性识别,区分相同词形但原形不同的词的差别。词性标注的准确率也直接影响词形还原的准确率,因此,词形还原更为复杂。
- 语义词⼲提取和词形还原结果有区别:词⼲提取的结果可能并不是完整的、具有意义的词,⽽只是词的⼀部分,如 “revival” 词⼲提取的结果为 “reviv”,“ailiner” 词⼲提取的结果为 “airlin”。⽽经词形还原处理后获得的结果是具有⼀定意义的、完整的词,⼀般为词典中的有效词。
- 应⽤领域各有侧重:虽然⼆者均被应⽤于信息检索和⽂本处理中,但侧重不同。词⼲提取更多被应⽤于信息检索领域,如 Solr、Lucene 等,⽤于扩展检索,粒度较粗。词形还原更主要被应⽤于⽂本挖掘,⽤于更细粒度、更为准确的⽂本分析和表达。
需要注意的是,词干提取与词形还原只针对具有形态变化的语言,比如英文、法文、德文等,中文是固定形态语言,因此并不存在这两种预处理操作。 对于某个文本,实施词形还原需要以下三个步骤:
- 分词
- 词性标注
- 词形还原
命名实体识别
现在有这样一个任务:《西游记》里出现过哪些人物,师徒四人都走过了哪些地方。这时候,命名实体识别就派上用场了。命名实体识别,英文称为 Named Entity Recognition,简称为 NER,目的在于识别文本中具有特定意义的实体,比如人名、地点名、组织机构名、时间等,常常用于语义挖掘及信息提取。
NER 的方法可大致分为三类:
- 基于规则的⽅法、基于字典的⽅法:这是最早期的基于专家知识的⽅法,当然会遇到规则难以尽全的瓶颈。
- 传统机器学习:把命名实体识别当作序列标注任务,常用的模型有有隐⻢尔可夫模型(HMM)、条件随机场(CRF)等统计模型。
- 深度学习:同样把命名实体识别当作序列标注任务,⽬前深度学习解决序列标注任务常⽤⽅法包括 LSTM+CRF、BiLSTM+CRF 等。
以下是一些常见的具备命名实体识别功能的工具:
- Stanford NER:斯坦福⼤学开发的基于条件随机场的命名实体识别系统,该系统参数基于 CoNLL、MUC-6、MUC-7和ACE命名实体语料训练而得。
- MALLET:麻省理工⼤学开发的⼀个统计⾃然语⾔处理的开源包。
- Hanlp HanLP:⼀系列模型与算法组成的 NLP ⼯具包,由⼤快搜索主导并完全开源,⽬标是普及⾃然语⾔处理在⽣产环境中的应⽤。
- nltk
- SpaCy:⼯业级的⾃然语⾔处理⼯具,但不⽀持中⽂。
- Crfsuite:可以载⼊⾃⼰的数据集去训练 CRF 实体识别模型。
需要注意的是,大部分工具只能识别一些基本的常见的人名、地名、组织名、时间等,如果是特殊领域的实体,比如医疗领域中的药物名,疾病名,大部分工具便难以识别了,这是因为这些工具背后所应用的训练集不存在这些实体。这个时候,需要标注好的领域数据,可以应用 Crfsuite 训练个性化的识别器,也可以自己搭建一些深度学习的模型进行序列标注训练。
文本的数据增强
在文本处理任务中,我们所收集的真实数据往往存在数据类别不平衡的问题,因为在现实场景下,不是所有的类别都以均等的机会出现。比如,垃圾邮件比正常邮件少些,有错字的文本比正常的文本少些。
那么,对于样本少的类别,模型可能就学习不到其特性。而有时候我们恰恰又非常希望模型能够识别某些出现比较少的类,比如对于错别词的预测。因此,对于数据不平衡的处理或者说数据增强是数据预处理过程中的关键环节。
针对文本数据而言,在未转化成数值表征形式的时候,可以在字符层面进行数据增广,常见的方法有:
- 同义词替换:根据同义词典或者词向量相似度替换相同用法的词汇,以此获取不同的文本表述方式。
- 文本回译:将文本翻译成某一语言再反译回来,一般能生成意思相近但表达不同的文本,这里需要注意的两点是,某些特殊文风、特殊领域或长度较长的文本翻译效果不佳,再回译会造成更多的误差传递,需慎用。选择回译语言的时候尽量选择与源语言渊源相近的语言或者被广泛应用于翻译研究的语言,如对于中文而言,可选择渊源更近的日文或者研究广泛的英文以减少回译误差。
- 词汇顺序变化:针对某些具备特殊条件的文本,在语块层面重新进行语序的排列并不影响整体的语义表达(如一些条例类的文本),也是可以尝试的数据增强手段。
nlpcda 是一个中文数据增强工具,能够快速实现包括随机替换、回译等方式的文本增强,以下是几个案例。
nlpcda 中的 Randomword() 能够实现随机(等价)实体替换,输入的两个主要参数为:
- create_num = 3 :返回 3 个增强文本。
- change_rate = 0.3 : 随机替换的概率。
!pip install nlpcda # 安装 nlpcda
from nlpcda import Randomword
sentence = "今天是2020年12月8日:我面试了58同城"
smw = Randomword(create_num=3, change_rate=0.3)
result = smw.replace(sentence)
print('随机实体替换结果:')
for r in result:
print(r)

nlpcda 中的 Similarword() 能够实现随机同义词替换,用法与 Randomword() 一致。
from nlpcda import Similarword
sentence = "今天是2020年12月8日:我面试了58同城"
smw = Similarword(create_num=3, change_rate=0.8)
result = smw.replace(sentence)
print('随机实体替换结果:')
for r in result:
print(r)

nlpcda 中的 baidu_translate() 能够实现百度中英翻译互转实现的增强,输入的四个主要参数为:
- content :原文本
- appid :百度翻译 api 的 appid
- secretKey :百度翻译 api 的 secretKey
- t_from :原文本的语言
- t_to :翻译文本的语言
注:申请 appid、secretKey 链接: http://api.fanyi.baidu.com/api/trans
from nlpcda import baidu_translate
zh = '天气晴朗,天气很不错,空气很好'
# 申请你的 appid、secretKey 分别填入 "xxx" 后代码才能运行
en_s = baidu_translate(content=zh, appid='xxx',
secretKey='xxx', t_from='zh', t_to='en') # 中文转英文
zh_s = baidu_translate(content=en_s, appid='xxx',
secretKey='xxx', t_from='en', t_to='zh') # 英文转回中文
print(zh_s)
中文文本分词
文本分类是人们日常工作中经常遇到的问题,也是机器学习和自然语言处理的重要研究内容。通常意义下的文本分类,实际上仅是符号化的标记(即自然数),并没有额外的过程性或说明性的知识,也没有元数据(如中图法分类号),只能从文档的内容本身提取信息来对文档进行分类。当然,对于特定的应用,使用外部知识或元数据可提高分类器的泛化能力。
那么,对于一个文本分类问题,我们一般采用如下流程进行处理:

在语言理解中,词是最小的能够独立活动的有意义的粒度。由词到句,由句成文。因此,文本分词一般都是自然语言处理的第一步。将句子分词之后,依旧无法进行分类,原因是机器并无法理解人类能使用的自然语言。所以,接下来就需要将词处理成能输入到算法中的向量,而不同的向量化和预处理方法也被统称为特征提取的过程。最后,基于文本特征建立机器学习分类模型,就能完成文本分类了。
中文分词这个概念自提出以来,经过多年的发展,主要可以分为三个方法:机械分词方法,统计分词方法,以及两种结合起来的分词。
其中,机械分词方法又叫做基于规则的分词方法。这种分词方法按照一定的规则将待处理的字符串与一个词表词典中的词进行逐一匹配,若在词典中找到某个字符串,则切分,否则不切分。机械分词方法按照匹配规则的方式,又可以分为:正向最大匹配法,逆向最大匹配法和双向匹配法三种。
正向最大匹配法
正向最大匹配法(Maximum Match Method,简称:MM)是指从左向右按最大原则与词典里面的词进行匹配。假设词典中最长词是 m 个字,那么从待切分文本的最左边取 m 个字符与词典进行匹配,如果匹配成功,则分词。如果匹配不成功,那么取 m−1 个字符与词典匹配,一直取直到成功匹配为止。
接下来,我们用一个简单的例子来讲一下正向最大匹配法的过程。假设我们有如下所示的句子和字典。
- 句子:中华民族从此站起来了
- 词典:中华,民族,从此,站起来了
接下来,开始实施正向最大匹配法:
- 第一步:词典中最长是 4 个字,所以我们将 中华民族 取出来与词典进行匹配,匹配失败。
- 第二步:于是,去掉 族,以 中华民 进行匹配,匹配失败。
- 第三步:去掉 中华民 中的 民,以 中华 进行匹配,匹配成功。
- 第四步:在带切分句子中去掉匹配成功的词,待切分句子变成 民族从此站起来了。
- 第五步:重复上面的第 1-4 步骤
- 第六步:若最后一个词语匹配成功,结束。
- 最终句子被分成:中华 / 民族 / 从此 / 站起来了。
逆向最大匹配法
逆向最大匹配法( Reverse Maximum Match Method,简称:RMM)的原理与正向法基本相同,唯一不同的就是切分的方向与正向最大匹配法相反。逆向法从文本末端开始匹配,每次用末端的最长词长度个字符进行匹配。
因为基本原理与正向最大匹配法一样,反向来进行匹配就行。所以这里对算法不再赘述。由于汉语言存在偏正短语,因此逆向匹配法相比与正向匹配的精确度会高一些。
双向最大匹配法
双向最大匹配法(Bi-direction Matching Method,简称:BMM)则是将正向匹配法得到的分词结果与逆向匹配法得到的分词结果进行比较,然后按照最大匹配原则,选取次数切分最少的作为结果。
接下来,我们以正向最大匹配法为例来实现其分词过程。首先,给出示例句子和词典。
t = '我们是共产主义的接班人'
d = ('我们', '是', '共产主义', '的', '接班', '人', '你', '我', '社会', '主义')
首先,实验构造函数 get_max_len_word(),该函数可以获取给定词典长度最大词的长度。
def get_max_len(d):
max_len_word = 0
for key in d:
if len(key) > max_len_word:
max_len_word = len(key)
return max_len_word
get_max_len(d)
接下来,我们按照上方给出的正向最大匹配法伪代码来构建正向最大匹配分词函数。
def mm(t, d):
words = [] # 用于存放分词结果
while len(t) > 0: # 句子长度大于 0,则开始循环
word_len = get_max_len(d)
for i in range(0, word_len):
word = t[0: word_len] # 取出文本前 word_len 个字符
if word not in d: # 判断 word 是否在词典中
word_len -= 1 # 不在则以 word_len - 1
word = [] # 清空 word
else: # 如果 word 在词典当中
t = t[word_len:] # 更新文本起始位置
words.append(word)
word = []
return words
最后,我们使用给出的示例进行测试。
mm(t, d) # 运行测试
# ['我们', '是', '共产主义', '的', '接班', '人']
可以看到,原句子以成功按照给出的字典进行了分词。
通过上面这段代码,虽然可以分词的目的,但也有明显的缺点。首先,这需要一个准备好的词典,而分词算法对于词典中不存在的词是无分辨能力的。其次,算法需要执行多个循环判断,时间复杂度高,不适用于大量文本分词。所以,更多情况下,我们会选择基于统计规则的中文分词方法。
随着语料库的大规模化,以及统计机器学习的蓬勃发展,基于统计规则的中文分词算法逐渐成为现在的主流分词方法。其特点是在给定大量已经分词的文本的前提下,利用统计机器学习模型学习词语切分的规律。
简单来讲,假设我们已经有一个由很多个文本组成的的语料库 D,现在需要对 我有一个苹果 进行分词。其中,两个相连的字 苹 和 果 在不同的文本中连续出现的次数越多,就说明这两个相连字很可能构成 苹果。
与此同时,个 和 苹 这两个相连的词在别的文本中连续出现的次数很少,就说明这两个相连的字不太可能构成 个苹。所以,可以利用统计规则来反应字与字成词的可信度。当字连续组合的概率高过一个临界值时,就认为该组合构成了一个词语。
基于统计的分词,一般情况下首先需要建立统计语言模型。然后再对句子进行单词划分,并对划分结果进行概率计算。最终,获得概率最大的分词方式。这里,我们一般会用到隐马可夫,条件随机场等方法。
结巴中文分词
结巴中文分词 就是一款基于统计的分词工具,其基于隐马可夫模型设计,并使用了 Viterbi 动态规划算法。由于结巴非常好用,分词效率很高,在中文分词领域有举足轻重的地位。
接下来,我们就来学习结巴分词的使用方法。结巴分词支持三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
结巴的使用方法非常简单,cut 方法默认为精确模式,并对文本进行分词。
import jieba
seg = "蓝桥云课楼+深度学习实战是一门培养机器学习初级工程师的课程"
seg_list = jieba.cut(seg)
seg_list
结巴分词默认返回迭代器,你可以通过循环或者 .join 方法把分词结果展示出来。
%%time
", ".join(seg_list)

jieba.cut(cut_all=True) 即可使用全模式。
%%time
", ".join(jieba.cut(seg, cut_all=True))

搜索引擎模式,则需要使用 jieba.cut_for_search 方法。
%%time
", ".join(jieba.cut_for_search(seg))

你可以对比三种模式的分词区别。这里,我们通过 %%time Jupyter Notebook 魔术方法打印出三段代码执行的时长,全模式的确速度最快。
对于上面的示例语句,实际上这里的「机器学习」应该被看作一个专有名词,而不应该被分为一般情形下的「机器」和「学习」。结巴分词支持自定义词典,从而可以避免上面这类情况。
如果只需要添加零星的几个自定义词汇,可以直接使用 jieba.add_word。当然,如果生产环境需要识别大量的专业词汇,可以参考 官方示例 制作用户词典。
jieba.add_word('机器学习') # 添加用户词汇
jieba.add_word('楼+')
", ".join(jieba.cut(seg))

英文文本分词
相比于中文文本,英文文本分词要简单很多。原因在于,英文文本词与词之间本来就有空格或者标点符号进行分割。所以,英文文本分词不需要依靠算法或暴力拆分,直接通过空格或者标点来将文本进行分开就可以完成。
'i have a pen'.split() # split 方法默认将字符串按空格拆分

当然,对于日常的英文文本分词,我们可以采用下面的代码。例如,string.punctuation 提供了常用英文标点符号。
import string
string.punctuation
# '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
接下来,删除句子中的标点符号。这里,可以使用 Python 提供了一个名为 translate() 的函数,它可以将一组字符映射到另一组字符。我们可以使用函数 maketrans() 来创建映射表。我们可以创建一个空的映射表,maketrans() 函数的第三个参数允许我们列出在 translate 过程中要删除的所有字符。代码如下:
text = """
[English] is a West Germanic language that was first spoken in early
medieval England and eventually became a global lingua franca.
It is named after the <Angles>, one of the Germanic tribes that
migrated to the area of Great Britain that later took their name,
as England.
"""
words = text.split()
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in words]
print(stripped)
['English', 'is', 'a', 'West', 'Germanic', 'language', 'that', 'was', 'first', 'spoken', 'in', 'early', 'medieval', 'England', 'and', 'eventually', 'became', 'a', 'global', 'lingua', 'franca', 'It', 'is', 'named', 'after', 'the', 'Angles', 'one', 'of', 'the', 'Germanic', 'tribes', 'that', 'migrated', 'to', 'the', 'area', 'of', 'Great', 'Britain', 'that', 'later', 'took', 'their', 'name', 'as', 'England']
我们可以使用上面的代码高效地删除文本中任意想要去掉的字符。
文本特征提取
分词之后的语料数据是无法直接用于分类的,还需要我们从中提取特征,并将这些文本特征变换为数值特征。只有向量化后的数值才能够传入到分类器中训练文本分类模型。
文本特征提取的方法有很多,这里我们介绍比较有代表性,同时较为常用的几个。
词袋模型
词袋模型(英语:Bag-of-words model,简称:BoW)是最最基础的一类特征提取方法,其主要思路是忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档。可以这样理解,我们把整个文档集的所有出现的词都丢进袋子里面,去重后无序排列。这样,就可以按照词语出现的次数来表示文档。
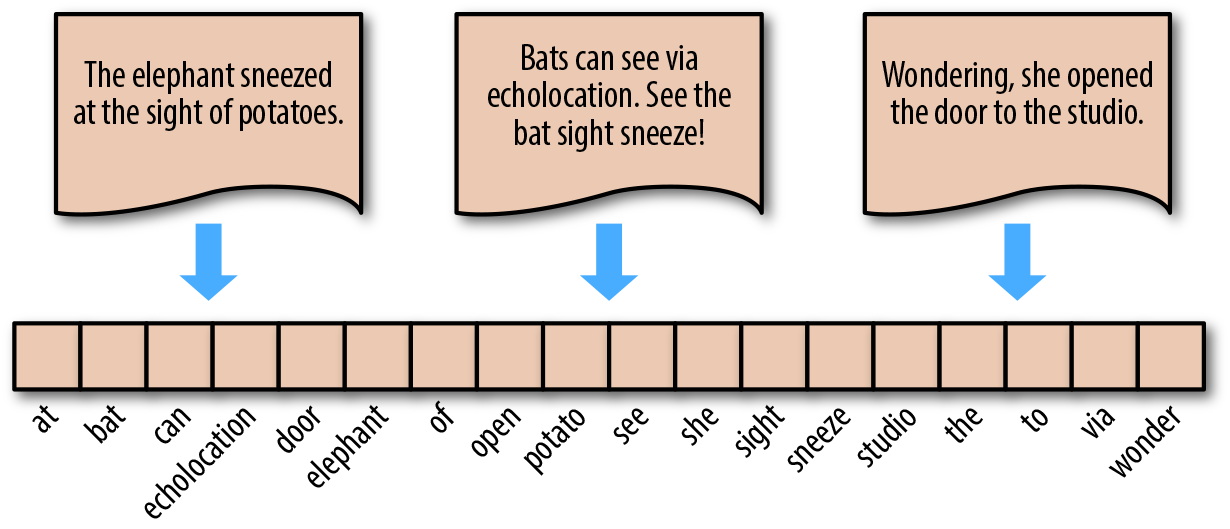
下面,我们来演示词袋模型的步骤。对于如下图所示的 3 个英文句子(中文同理)。
"The elephant sneezed at the sight of potatoes."
"Bats can see via echolocation. See the bat sight sneeze!"
"Wondering, she opened the door to the studio."
首先,完成分词 → 去除多余标点字符 → 去除重复,得到如下图横排的单词,即为词袋。英文中,单复数,时态往往只保留单词原型。
词袋模型的表示方法为,对照词袋,统计原句子中某个单词出现的次数。这样,无论句子的长度如何,均可用等长度的词袋向量进行表示。例如,对于句子 "Bats can see via echolocation. See the bat sight sneeze!",其可以转换为向量。[0,2,1,⋯,0,1,0]。
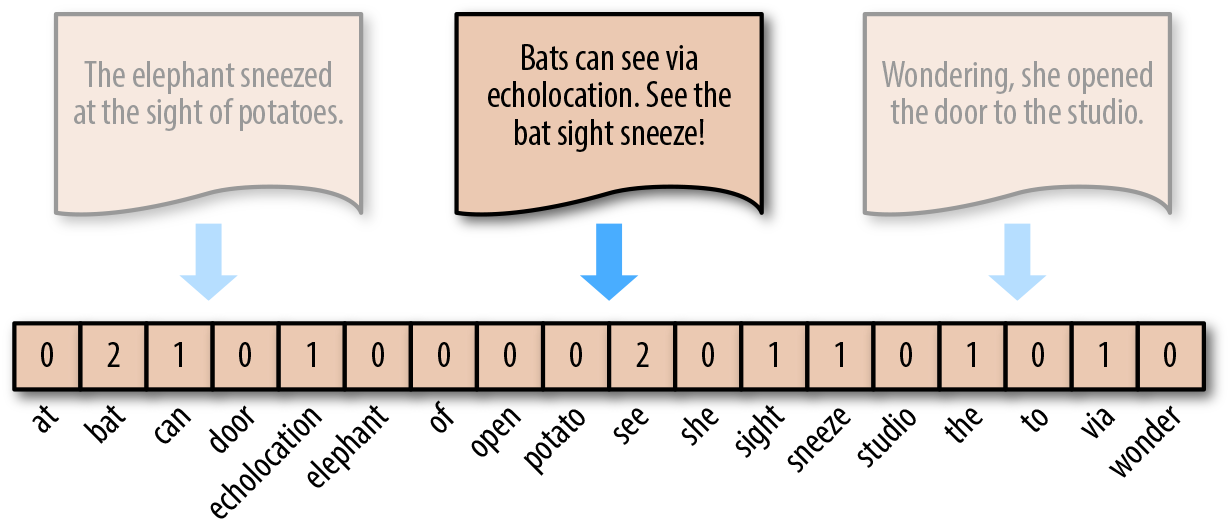
我们可以使用 scikit-learn 提供的 sklearn.feature_extraction.text.CountVectorizer 来构建词袋模型。方法很简单,通过下面的例子就能看明白了。
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
"The elephant sneeze at the sight of potato.",
"Bat can see via echolocation. See the bat sight sneeze!",
"Wonder, she open the door to the studio.",
]
vectorizer = CountVectorizer()
vectors = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names_out()) # 打印出词袋
vectors.toarray() # 打印词向量

上面的例子中,在制作 corpus 时已手动对英语单词中单复数和时态词汇做了处理,全部变为原型。这个过程在实际应用时,可以通过预处理代码来完成。
词袋模型的另一个小变种就是不以单词实际出现的次数表示,而是采取类似独热编码的方式。单词出现即置为 1,未出现即为 0。
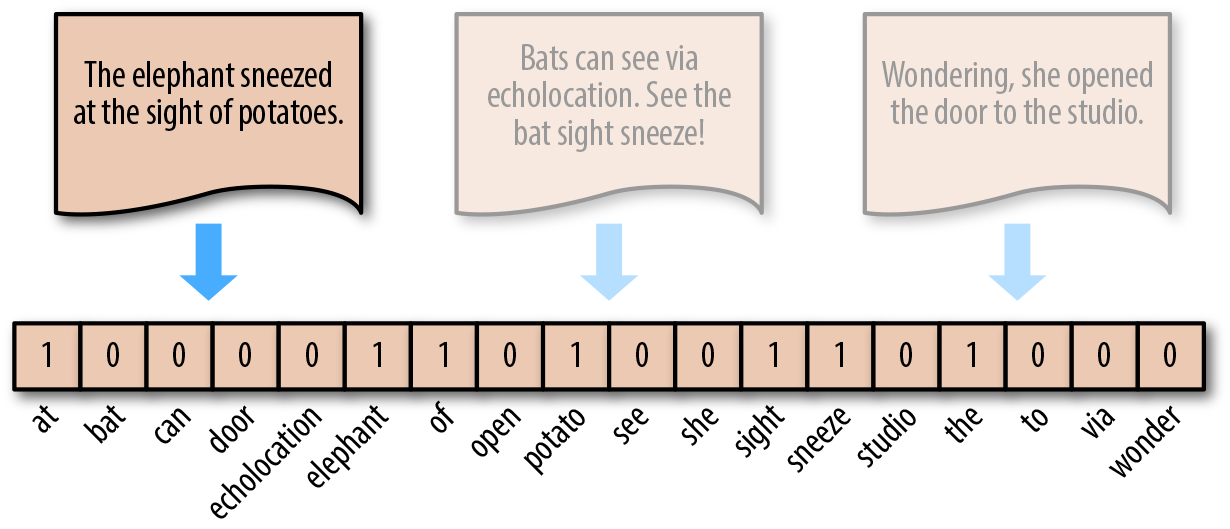
这个过程同样可以使用 scikit-learn 来完成。这里用到了 sklearn.preprocessing.Binarizer 对上面 CountVectorizer 处理结果进行独热编码转换。
from sklearn.preprocessing import Binarizer
freq = CountVectorizer()
corpus_ = freq.fit_transform(corpus)
onehot = Binarizer()
onehot.fit_transform(corpus_.toarray())

TF-IDF 模型
TF-IDF 模型(英语:Term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF 是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF-IDF 由 TF(Term frequency,词频)和 IDF(Inverse document frequency,逆文档频率)两部分组成。计算公式为:
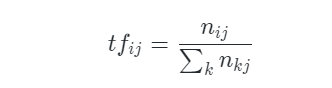
式中,分子 n ij表示词 i 在文档 j 中出现的频次。分母则是所有词频次的总和,也就是所有词的个数。
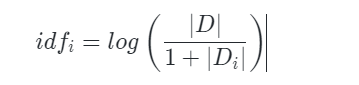
式中,∣D∣ 代表文档的总数,分母部分 ∣Di∣ 则是代表文档集中含有 i 词的文档数。原始公式是分母没有 +1 的,这里 +1 是采用了拉普拉斯平滑,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。
最后,把 TF 和 IDF 两个值相乘就可以得到 TF-IDF 的值。即:
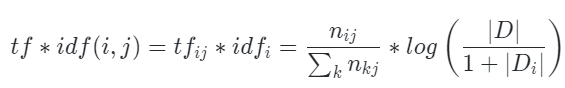
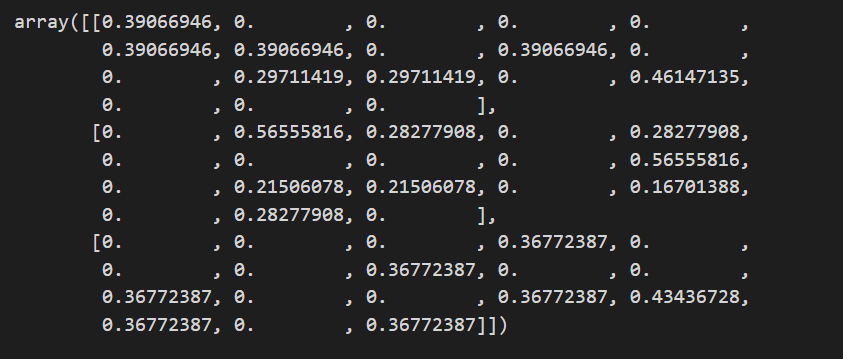
同样,scikit-learn 提供了 sklearn.feature_extraction.text.TfidfVectorizer 可用于 TF-IDF 转换。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
tfidf.toarray()
Word2Vec 模型
Word2Vec 模型 是 Google 团队于 2015 年提出来的一种字词的向量表示法,又被称为「词嵌入」。
无论是词袋模型,还是 TF-IDF 模型,它们均是使用离散化的向量值来表示文本。这些编码是任意的,并未提供有关字词之间可能存在的相关性。将字词表示为唯一的离散值还会导致数据稀疏性,并且通常意味着我们可能需要更多数据才能成功训练统计模型。
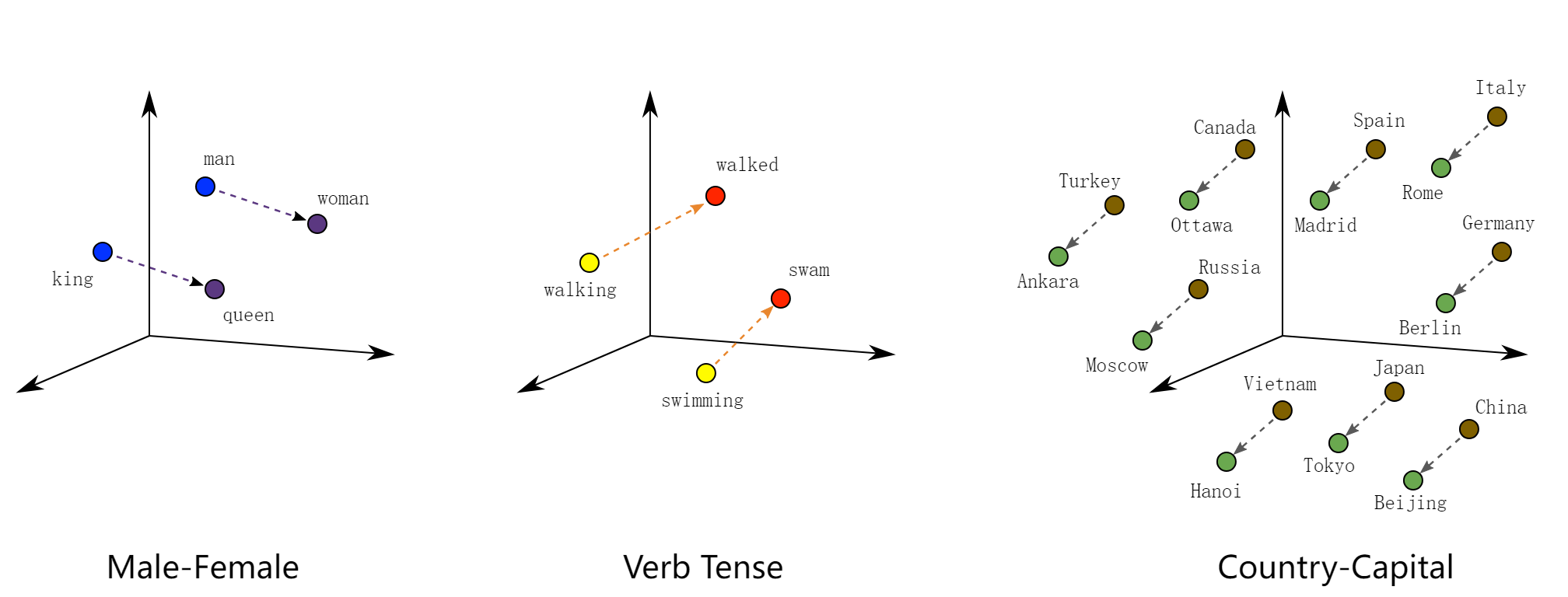
向量空间模型 在连续向量空间中表示(嵌入)字词,其中语义相似的字词会映射到附近的点(在彼此附近嵌入)。向量空间模型在 NLP 方面有着悠久而丰富的历史,但所有方法均以某种方式依赖于分布假设,这种假设指明在相同上下文中显示的字词语义相同。
Word2Vec 是一种计算效率特别高的预测模型,用于学习原始文本中的字词嵌入。它分为两种类型:连续词袋模型(CBOW)和 Skip-Gram 模型。从算法上看,两种模型比较相似,只是 CBOW 从源上下文字词(the cat sits on the)中预测目标字词(例如 mat),而 Skip-Gram 则逆向而行,从目标字词中预测源上下文字词。
根据论文观点,统计学上有助于 CBOW 整理很多分布信息。在大多数情况下,这对于小型数据集来说是很有用的。但是,Skip-Gram 将每个上下文-目标对视为一个新的观察对象,当我们使用大型数据集时,Skip-Gram 似乎能发挥更好的效果。关于 Word2Vec 的具体原理解释比较复杂,大家可以阅读 论文原文 或 其他相关资料。本次实验,我们重点来学习如何使用 Word2Vec。
Word2Vec 词嵌入过程一般常用 Gensim 库来处理。Gensim 是自然语言处理过程中一个比较常用的工具,其提供了封装好的高效 Word2Vec 处理类 gensim.modelsWord2Vec()。其常用参数有:
- size: 词嵌入的维数,表示每个单词嵌入后的向量长度。
- window: 目标字与目标字周围的字之间的最大距离。
- min_count: 训练模型时要考虑的最小字数,出现小于此计数的单词将被忽略。
- sg: 训练算法,CBOW(0)或 Skip-Gram(1)。
接下来,我们使用 Word2Vec 对前面的示例文本进行词嵌入操作。
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
# 分词之后的示例文本
sentences = [['the', 'elephant', 'sneeze', 'at', 'the', 'sight', 'of', 'potato'],
['bat', 'can', 'see', 'via', 'echolocation', 'see', 'the', 'bat', 'sight', 'sneeze'],
['wonder', 'she', 'open', 'the', 'door', 'to', 'the', 'studio']]
# 训练模型
# 训练模型
model = Word2Vec(sentences, vector_size=20, min_count=1)
# 输出该语料库独立不重复词
print(list(model.wv.index_to_key))
# 输出 elephant 单词词嵌入后的向量
model.wv['elephant']

下面,我们可以把 Word2Vec 嵌入后的词在空间中绘制处理。由于上面模型设置了 size=20,所以需要使用 PCA 降维把嵌入后的向量降维为二维才能够在平面中可视化出来。
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
%matplotlib inline
# PCA 降维
X = model.wv[model.wv.key_to_index]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
# 绘制散点图,并将单词标记出来
plt.scatter(result[:, 0], result[:, 1])
words = list(model.wv.key_to_index)
for i, word in enumerate(words):
plt.annotate(word, xy=(result[i, 0], result[i, 1]))
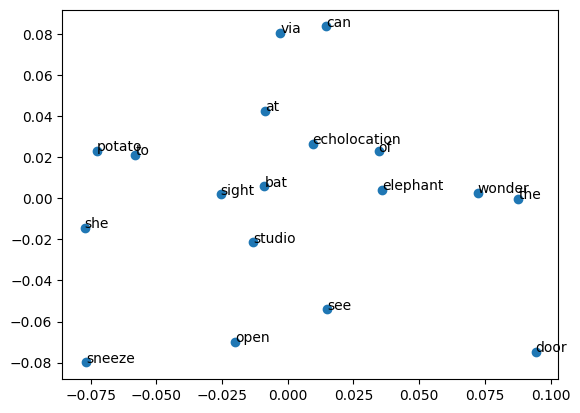
由于我们的语料库较小,其实字词直接的相关性不太明显。如果语料库足够大,你就可以明显看出部分意义相关的词空间距离更近。
训练 Word2Vec 模型往往需要大量的语料和时间,所以在有些时候我们会使用预训练的词嵌入模型。例如,Google 在 Word2Vec Project 上发布了一个预先训练过的 Word2Vec 模型。该模型使用谷歌新闻数据(约 1000 亿字)进行训练,其包含了 300 万个单词和短语,并且使用 300 维词向量表示。由于该预训练词嵌入模型大小为 3.4 GB,这里就不再演示了。你可以在 本地下载 下来,并通过以下代码加载模型。
from gensim.models import KeyedVectors
filename = 'GoogleNews-vectors-negative300.bin'
model = KeyedVectors.load_word2vec_format(filename, binary=True)
当得到每个单词的词嵌入向量后,就可以通过直接求和或者其他加权求和方法得到一段文本的向量特征,从而可以传入分类器进行训练。
假新闻分类任务
接下来通过一个例子完成真实的文本分类任务。
WSDM - Fake News Classification 假新闻分类大赛是 Kaggle 上面的一个比赛。本次实验我们使用其提供的数据集来完成一次文本分类任务。首先,下载实验提供的数据集。
!wget -nc "http://labfile.oss.aliyuncs.com/courses/1233/wsdm_mini.csv"
import pandas as pd
df = pd.read_csv("wsdm_mini.csv")
df.head()

该数据集使用了原比赛提供的训练集,仅保留了中文字段并抽样其中 1.5 万条数据。数据集包含两列特征 title1_zh 和 title2_zh,这是两个新闻标题。而目标值 label 则表示这两则新闻的关系,其中:
- agreed:B 谈到与 A 相同的假新闻。
- disagreed:B 驳斥 A 中的假新闻。
- unrelated:B 与 A 无关
3 个标签的数据各有 5000 条。按照上文中的思路,首先我们需要对文本进行分词处理。在分词之前,首先将 title1_zh 和 title2_zh 合并为一个字段 title_zh。
df['title_zh'] = df[['title1_zh', 'title2_zh']].apply(lambda x: ''.join(x), axis=1) # 合并文本数据列
df_merge = df.drop(df.columns[[0, 1]], axis=1) # 删除原文本列
df_merge.head()
接下来,对 title_zh 执行分词操作。分词过程中另一个比较重要的步骤是「删除停用词」。
通常意义上, 停用词 大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,比如英文中的 the、is、at、which、on,以及中文中的 的、得 等。另一类词包括词汇词,比如大规模语料中的高频词,很多高频词只能带来非常少量的语义信息。删除停用词可以提高后续文本特征提取和分类的性能。这里,我们可以使用蓝桥云课提供的停用词词典,其中包含了一些无意义常用词和中文标点符号。
!wget -nc "http://labfile.oss.aliyuncs.com/courses/1176/stopwords.txt" # 停用词词典
下面,定义一个函数来加载停用词文件中的数据。
def load_stopwords(file_path):
with open(file_path, 'r') as f:
stopwords = [line.strip('\n') for line in f.readlines()]
return stopwords
stopwords = load_stopwords('stopwords.txt')
stopwords

接下来,就是分词和删除停用词的过程。
from tqdm import tqdm
import jieba
corpus = []
for line in tqdm(df['title_zh']):
words = []
seg_list = list(jieba.cut(line)) # 分词
for word in seg_list:
if word in stopwords: # 删除停用词
continue
words.append(word)
corpus.append(words)

接下来,对词语进行 Word2Vec 嵌入,同时将每条数据各单词的向量相加,作为该句子最终的向量表示。
import numpy as np
model = Word2Vec(corpus) # 词嵌入,默认 size=100
def sum_vec(text):
vec = np.zeros(100).reshape((1, 100)) # 初始化一个和 Word2Vec 嵌入等长度的 0 向量
for word in text:
# 得到句子中每个词的词向量并累加在一起
if word in list(model.wv.key_to_index):
vec += model.wv[word].reshape((1, 100))
else:
pass
return vec
# 将词向量保存为 Ndarray
X = np.concatenate([sum_vec(z) for z in tqdm(corpus)])
X.shape

目前,完成了特征提取,就可以开始建立分类器并按照常规思路训练一个文本分类模型。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X_train, X_test, y_train, y_test = train_test_split(X, df.label, test_size=0.2)
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
# 0.656
至此,我们就可以得到文本分类的准确率了。当然,你可能发现结果不太理想。实际上这可能是由于数据量较小,影响了词嵌入的效果。同时,假新闻分类这个比赛通过简单的文本分类并不能取得特别好的效果。
本文来自博客园,作者:Rescal_子轩,转载请注明原文链接:https://www.cnblogs.com/zx-demo/p/18102838

