


C++笔记
-
前言
坚持下去很难,但不坚持永远都无法获得成功~

正文
当前复习进度
31_2_2.中序遍历迭代
经验
答案
1. 如何获得结构成员相对于结构开头的字节偏移量:offsetof(S,x);
2. 浮点数的值如何比较大小?不能直接用是否相等的方式比较两个数是否相等,只能用两个数相减,然后是否符合某个精度。
3. 引用传递和指针传递是不同的:任何对于形参引用的操作都会通过一个间接寻址的方式操作到主调函数中的相关变量。而指针传递的话,即使在被调函数中改变指针地址,也无法应用到主调函数中的相关变量。
4. 动态建立对象:先执行operator new ,在内存中查找一块合适的地址,然后调用类的构造函数构造对象。
5. 调用者如何调用被调函数:使用Call指令调用被调函数,然后将下一条指令压入栈中,待该函数处理完毕,再将这下一条指令进行出栈。
6. C++中提供了explicit关键字,在构造函数声明的时候加上explicit关键字,能够禁止隐式转换。
7. 一个类对象的地址就是类所包含的这一片内存空间的首地址。
8. 所有的函数都是存放在代码区的,不管是全局函数还是成员函数又或者是静态函数。所以,类的大小由成员变量所决定。
9. 静态成员函数与一般成员函数的区别就在于:静态成员函数没有this指针,因此不能访问非静态数据成员。且this指针只能在成员函数中使用,全局函数,静态函数都不能使用this指针。
10. this指针是在成员函数开始执行前创建的,在成员的执行结束后清除。
11. delete的本质:为被释放的内存调用一个或多个析构函数。然后,释放内存。
12. 空类的大小:为了让对象的实例能够相互区别。并且每个实例都是独一无二的,所以空类的大小为1. 其空类的实例的大小也为1.
13. 静态成员不占用类的大小。其存放在静态存储区。
14. 当在类的非静态成员函数访问类的非静态成员时,编译器会自动将对象的地址传给作为隐含参数传递给函数,这个隐含参数就是this指针。
15. 弱引用指针与普通指针的一个比较大的区别就是:弱引用能检测到所管理的对象是否已经被释放,从而避免非法访问内存。
16. RALL(Resource Acquisition is Initialization):资源获取即初始化。也就是在构造函数中申请分配资源,在析构函数中申请释放资源。
17. 即使是同一个值的Integer对象,那么也是生成不同的对象。所以通过 Map 做了映射,不管你 new 多少个 Integer 出来,这多个 Integer 都会被映射为同一个 Integer,从而保证即使超出 Integer 缓存范围时,也只有一把锁。
18. 定义:减少常见的错误,能够更快的定位错误,提升运行性能。
19. 永远不要在用ranged-for的时候修改容器自身。
20. 说不要判断this 为nullptr,这是UB行为。
21. 不要判断对象的引用是nullptr,这是UB行为。永远认为引用所指向的对象是一个存在的对象。
22. 避免在switch语句中使用default
23. 不要返回裸指针,类似于:int *get_value();
24. 优先用栈而不是堆
例题
1. 如何手写shared_ptr?

点击查看代码
#include <iostream>
#include <stdio.h>
#include <mutex>
using namespace std;
class Person
{
public:
Person()
{
cout << "Person" << endl;
};
Person(int age)
{
cout << "--->Person age" << endl;
m_Age = age;
}
int m_Age;
~Person()
{
cout << "~Person" << endl;
}
void run()
{
cout << "--->Person run" << endl;
}
};
template<class T>//类模板
class Shared_Ptr {
public:
Shared_Ptr()
{
cout << "Share_Ptr" << endl;
}
Shared_Ptr(T* ptr)//://下面这四句话,叫做初始化列表,相比在括号里进行初始化,效率更高。
//参考这个:https://www.cnblogs.com/graphics/archive/2010/07/04/1770900.html
//m_ptr(ptr)
//,m_pRefCount(new int(1))
//,m_pMutex(new mutex)
{
m_ptr = ptr;
m_pRefCount = new int(1);
m_pMutex = new mutex;
cout << "-->Shared_ptr"<<endl;
}
~Shared_Ptr()
{
Release();
}
//拷贝构造函数,构造出一个新的智能指针对象后,就可以使用这个在其他地方了。
Shared_Ptr(const Shared_Ptr<T>& p)
{
m_ptr = p.m_ptr;
m_pRefCount = p.m_pRefCount;
m_pMutex = p.m_pMutex;
AddRefCount();//赋值完后,AddRef表示又有一个智能指针指向当前资源了
}
//= 操作符的拷贝赋值函数
Shared_Ptr<T>& operator=(const Shared_Ptr<T>& p)
{
if (m_ptr != p.m_ptr)
{
//要先释放原来的旧资源
Release();
//共享管理新对象的资源,并增加引用计数
m_ptr = p.m_ptr;
m_pRefCount = p.m_pRefCount;
m_pMutex = p.m_pMutex;
AddRefCount();
}
}
//拷贝构造函数是一个对象初始化一块内存区域,这块内存就是新对象的内存区,而赋值函数是对于一个已经被初始化的对象来进行赋值操作。
//所以拷贝构造直接赋值就可以了,赋值函数则要先释放原有的空间,再赋值新的空间。
T& operator*()
{
return *m_ptr;
}
T* operator&()
{
return m_ptr;
}
int UseCount()
{
return m_pRefCount;
}
T* Get()
{
return m_ptr;
}
//增加引用计数的方式
void AddRefCount()
{
m_pMutex->lock();
++(*m_pRefCount);
m_pMutex->unlock();
}
private:
void Release()
{
bool deleteflag = false;
m_pMutex->lock();
if (--(*m_pRefCount) == 0)
{
delete m_pRefCount;
delete m_ptr;
deleteflag = true;
}
m_pMutex->unlock();
if (deleteflag == true)
{
delete m_pMutex;
}
}
T* m_ptr;
int* m_pRefCount;
mutex* m_pMutex;
};
void test01()
{
Shared_Ptr<Person> p(new Person(3));
}
int main()
{
{
cout << 1 << endl;
test01();
cout << 2 << endl;
}
getchar();
return 0;
}
2. 请说出二分查找的实现思路及时空复杂度
答:首先使用二分查找算法的前提是数组是有序数组,接下来,讲一下具体的算法思路:
点击查看代码
>1. 对于该有序数组a,我们可以定义两个变量,一个叫Left,其值为0,一个叫Right,为数组的长度-1。接下来,我们可以确定该有序数组的中间者为[(left+right)/2]。
>2. 接下来,判断a[(left+right)/2]是否等于所要查找的值,若大于所要查找的值,则将left指针指向mid+1((left+right)/2)。若小于所要查找的值,则将right指针指向mid-1。所等于则返回当前Mid值。
>3. 接下来,不断的循环执行该过程。若当right指针指向的位置为left+1的话,则该查找过程结束。表示未在该数组找到该值。
>二分查找的时间复杂度为O(logn) -->N*(1/2)^x = 1--->x = O(LOG(N))
2. 构造函数可以是虚函数吗?
答案
答: 不能.
1. 因为我们在构造一个对象的时候,必须要知道这个对象的类型,而虚函数的特性就是在运行期间确定实际的类型的。
2. 并且,虚函数的执行是依赖于虚函数表的,而在构造对象期间,虚函数表还未初始化。注意:这个虚函数表是存放在**全局/静态数据区**的(全局静态变量,未初始化的放在BSS段,初始化的放在Data段。
3. 虚函数表的创建时机: 虚函数表创建时机是在编译期间。编译期间编译器就为每个类确定好了对应的虚函数表里的内容。所以在程序运行时,编译器会把虚函数表的首地址赋值给虚函数表指针,所以,这个虚函数表指针就有值了.
2.1. C++类有继承时,析构函数必须为虚函数吗?
点击查看代码
若不是虚函数,则派生类调用析构函数释放内存时,有可能调用的是基类的析构函数,导致派生类所申请的内存未正确释放。
2.2 虚函数与纯虚函数的差别是什么?
点击查看代码
1. 纯虚函数只有定义,没有实现;而虚函数不仅有定义,还有实现。
2. 包含纯虚函数的类不能定义其对象,而包含虚函数的可以。
3. 纯虚函数在虚函数表中的表项是空项,值为0,而虚函数在虚函数中的表项是一个具体的值,具体的指针地址。
2.3 纯虚函数实现原理是什么?(通过这个原理,可以达成什么样的目的?)
点击查看代码
虚函数的原理采用虚函数表。
类中含有纯虚函数时,其虚函数表不完全,有个空位。
即“纯虚函数在类的虚函数表中对应的表项被赋值为0。也就是指向一个不存在的函数。由于编译器绝对不允许有调用一个不存在的函数的可能,所以该类不能生成对象。在它的派生类中,除非重写此函数,否则也不能生成对象。”
所以纯虚函数不能实例化。
2.4 虚函数是否可以是内联函数?
点击查看代码
答案:虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
**内联函数的原理?**
在编译期间,对调用内联函数的地方替换成函数代码。
**内联函数的作用?**
对程序中需要频繁使用 和调用的小函数有用。可以减少函数调用所做的花销,提高程序的效率。
**为何在表现多态性不能内联?**
内联是在编译器内联,而虚函数的多态性是在运行期,编译器无法知道运行期调用哪个代码,因为虚函数表示为多态性时不可以内联。
什么情况可以使用inline修饰虚函数?(内联函数何时可以内联?)
答案
//inline virtual 唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如 Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
#include <iostream>
using namespace std;
class Base {
public:
virtual void who() { cout << "I am Base" << std::endl; }
};
class Derived : public Base {
public:
void who() { cout << "I am Derived" << std::endl; }
};
int main() {
// 此处的虚函数who(),是通过类的具体对象来调用的,编译期间就能确定了,所以它可以是内联的。
Base b;
b.who();
// 此处的虚函数是通过指针调用的,需要在运行时期间才能确定,所以不能为内联。
Base* ptr = new Derived();
ptr->who();
return 0;
}
//也就是
class Base
{
inline virtual void who() {..........}
}
class Derived : public Base
{
inline void who() {............}
}
//上面这种情况是可以运行的
2.5 虚函数和虚函数表的存放地址在哪里
点击查看代码
答案:C++中虚函数表位于只读数据段(.rodata),也就是C++内存模型中的常量区;而虚函数则位于代码段(.text),也就是C++内存模型中的代码区。
如何确定虚函数表是位于C++内存模型中的常量区?
1.虚函数表是全局共享的元素,即全局仅有一个.
2.虚函数表类似一个数组,类对象中存储vptr指针,指向虚函数表.即虚函数表不是函数,不是程序代码,不肯能存储在代码段.
3.虚函数表存储虚函数的地址,即虚函数表的元素是指向类成员函数的指针,而类中虚函数的个数在编译时期可以确定,即虚函数表的大小可以确定,即大小是在编译时期确定的,不必动态分配内存空间存储虚函数表,所以不再堆中.
4. 虚函数是针对一个类的,有点像一个类中的static变量,是属于一个类的所有对象的。不属于某一个专门的对象。
根据以上特征,虚函数表类似于类中静态成员变量.静态成员变量也是全局共享,大小确定.

2.6 如何获得虚函数表的地址
答案
在C++的标准规格说明书中说到,编译器必需要保证虚函数表的指针存在于对象实例中最前面的位置(这是为了保证正确取到虚函数的偏移量)。这意味着我们通过对象实例的地址得到这张虚函数表,然后就可以遍历其中函数指针,并调用相应的函数。
取虚表地址和虚函数地址的方式
class Base {
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
void h() { cout << "Base::h" << endl; }
};
typedef void(*Fun)(void); //函数指针
int main()
{
Base b;
// 这里指针操作比较混乱,在此稍微解析下:
// *****printf("虚表地址:%p\n", *(int *)&b); 解析*****:
// 1.&b代表对象b的起始地址
// 2.(int *)&b 强转成int *类型,为了后面取b对象的前四个字节,前四个字节是虚表指针
// 3.*(int *)&b 取前四个字节,即vptr虚表地址
//
// *****printf("第一个虚函数地址:%p\n", *(int *)*(int *)&b);*****:
// 根据上面的解析我们知道*(int *)&b是vptr,即虚表指针.并且虚表是存放虚函数指针的
// 所以虚表中每个元素(虚函数指针)在32位编译器下是4个字节,因此(int *)*(int *)&b
// 这样强转后为了后面的取四个字节.所以*(int *)*(int *)&b就是虚表的第一个元素.
// 即f()的地址.
// 那么接下来的取第二个虚函数地址也就依次类推. 始终记着vptr指向的是一块内存,
// 这块内存存放着虚函数地址,这块内存就是我们所说的虚表.
//
printf("虚表地址:%p\n", *(int *)&b);
printf("第一个虚函数地址:%p\n", *(int *)*(int *)&b);
printf("第二个虚函数地址:%p\n", *((int *)*(int *)(&b) + 1));
Fun pfun = (Fun)*((int *)*(int *)(&b)); //vitural f();
printf("f():%p\n", pfun);
pfun();
pfun = (Fun)(*((int *)*(int *)(&b) + 1)); //vitural g();
printf("g():%p\n", pfun);
pfun();
}
2.7 虚函数表带来的安全性问题有哪些?(两点)
点击查看代码
问题一:通过父类型的指针访问子类自己的虚函数
Base1 *b1 = new Derive();
b1->f1();
//编译出错 这个f1 是子类自己的虚函数
任何妄图使用父类指针想调用子类中的未覆盖父类的成员函数的行为都会被编译器视为非法,所以,这样的程序根本无法编译通过。但在运行时,我们可以通过指针的方式访问虚函数表来达到违反C++语义的行为。
问题二、访问non-public的虚函数
另外,如果父类的虚函数是private或是protected的,但这些非public的虚函数同样会存在于虚函数表中,所以,我们同样可以使用访问虚函数表的方式来访问这些non-public的虚函数,这是很容易做到的。
[参考](https://blog.csdn.net/qq_41375609/article/details/107050911)
2.8 虚函数到底虚在哪?
答案
虚就虚在所谓"推迟联编"或者"动态联编"上,一个类函数的调用并不是在编译时刻被确定的,而是在运行时刻被确定的
2.9、谈谈你对虚函数表结构的理解,在单继承,多继承,虚继承情况下表的结构是怎么样的?

答案
1. 虚表是属于类的,不属于某个对象。同一个类的所有对象共用一个虚表。
2. 对象的虚表指针指向自己所属类的虚表,虚表中的指针会指向其继承的最近的一个类的虚函数。
3. 对于子类来说,这个虚函数表包含父类中所有的虚函数,当子类重写某个虚函数时就会用子类重写后的函数地址替换原来父类中定义的函数地址,同时在子类的虚函数表中还会包含子类独有的虚函数。
4. 解决菱形继承的方法:虚继承。
单继承:
多继承:当出现多继承时,会出现两个虚函数表指针,一个是指向自己的,一个是指向继承的那个虚函数表的。
菱形继承: 会出现最终继承的子类,会有两份最上级父类的成员变量。
5. 虚继承的作用
> 1. 虚继承是多重继承特有的概念,这里需要明确的是,虚继承与虚函数继承是完全不同的概念。
> 2. 虚继承是为解决多重继承(菱形继承)而出现的,可以节省内存空间。
2.10 C++构造函数和析构函数中可以调用虚函数吗?
答案
1. 从语法上讲,调用完全没有问题。但从效果上讲,往往不能达到需要的目的。
**原因**:
1. 在构造函数中调用虚函数,由于当前对象还没有构造完成,此时调用的虚函数指向的是基类的函数实现方式。
2. 在析构函数中调用虚函数,此时调用的是子类的函数实现方式。
2.11 如何让类不被继承?
答案
a. 将类的构造函数声明为private。
b. 二是,将该类虚继承一个父类,但是该父类的构造函数是带private属性的。(其实子类可以继承有private构造函数的父类,那必定是有权限访问父类的private成员,这是通过将子类声明为父类的friend class了。)
关于第二个方法可行的依据是:
1)派生类不能调用父类private属性的构造函数。
2)建立一个对象时,如果这个对象中含有从虚基类继承来的成员,则虚基类的成员是由最远派生类的构造函数通过调用虚基类的构造函数进行初始化的。
c. 使用final关键字,C++11中允许将类标记为final,方法时直接在类名称后面使用关键字final,如此,意味着继承该类会导致编译错误。
2.12为什么纯虚函数一定要被子类继承?
答案
1. 由于纯虚函数在虚函数表项中是为0的,也就是是指向一个不存在的函数的。那么也就意味着,该类是不能被实例化的,因为编译器是不允许去实例化一个有指向不存在函数的类的。
2. 那么就以为着如果子类继承了这个抽象类,那么虚函数表也就也有一个表项是0,指向不存在的函数。如果子类不去实现,覆盖这个表项的话,那么肯定就没办法进行实例化。
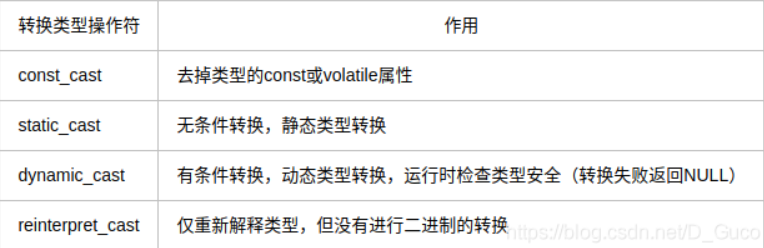
3. C++ 四种强制类型转换
3.0什么叫隐式转换,什么叫显式转换
答案
隐式转换:说白了就是在转换时不给系统提示具体的显示模型,让其自动转换,但是要记住一条编译器一般只支持自下而上的类型转换,例如int 转 float。
显示转换:就是我们在c语言课程中学的,强制转换,是我们可以直接对其赋值的。
3.1 const_cast的作用
答案
>1. 常量指针被转换为非常量的指针,并且仍然指向原来的对象。
>2. 常量应用被转化为非常量的应用,并且仍然指向原来的对象。
>3. 去掉变量的const 或是volatile属性。
3.2 static_cast的作用
答案
>1. 用于类层次结构中父类和子类指针或引用的无条件转换。
>2. 用于基本数据类型之间的转换。
>3. c++ 任何隐式转换都是使用static_cast.
3.3 dynamic_cast的作用
答案
作用:用于子类转父类时的有条件类型转换,会进行类型检查。
关于这个,我目前只了解说在子类转成父类的强制类型转换时可以使用。但其实父类转子类也是可以的。并且dynamic_cast要求操作数必须是多态类型。比如在将整形转为浮点型时。
(1)其他三种都是编译时完成的,dynamic_cast是运行时处理的,运行时要进行类型检查。
(2)不能用于内置的基本数据类型的强制转换。
(3)dynamic_cast转换如果成功的话返回的是指向类的指针或引用,转换失败的话则会返回NULL。
(4)使用dynamic_cast进行转换的,基类中一定要有虚函数,否则编译不通过。
B中需要检测有虚函数的原因:类中存在虚函数,就说明它有想要让基类指针或引用指向派生类对象的情况,此时转换才有意义。
这是由于运行时类型检查需要运行时类型信息,而这个信息存储在类的虚函数表(关于虚函数表的概念,详细可见<Inside c++ object model>)中,
只有定义了虚函数的类才有虚函数表。
(5) dynamic_cast用于类继承层次间的指针或引用转换。主要还是用于执行“安全的向下转型(safe downcasting)”,也即是基类对象的指针或引用转换为同一继承层次的其他指针或引用。至于“先上转型”(即派生类指针或引用类型转换为其基类类型),本身就是安全的,尽管可以使用dynamic_cast进行转换,但这是没必要的, 普通的转换已经可以达到目的,毕竟使用dynamic_cast是需要开销的。也就是说,如果从父类转到子类是安全的,也就是子类没有增加啥其他虚函数,那么转换会成功,倘若增加了其他的虚函数,就会导致转换失败。
dynamic_cast运算符的主要用途
1. 将基类的指针或引用安全地转换成派生类的指针或引用,并用派生类的指针或引用调用非虚函数。
2. 如果是基类指针或引用调用的是虚函数无需转换就能在运行时调用派生类的虚函数。
dynamic_cast怎么保证安全的?
首先,阐述一下使用dynamic_cast的原因:
1. static_cast 强制类型转换时并不具有保证类型安全的功能,而 C++ 提供的 dynamic_cast 却能解决这一问题,它可以在程序运行时检测类型转换是否类型安全。
如何保证的:
1. 本例中是要用基类对象地址去初始化派生类指针,显然是无法保证类型安全的,因此 p 最后得到的返回值是 0。
2. dynamic_cast 的转换规则是:
a. 只允许将指向派生类对象的指针转换为指向基类对象的指针。否则就会返回NULL.
b. 要求所转换的操作数必须包含多态类型。
c. dynamic_cast 的转换规则是:只允许将指向派生类对象的指针转换为指向基类对象的指针。否则的话,则会进行类型检查,确保转换安全。
3.4 reinterpret_cast的作用
答案
1. 用在任意的指针之间的转换。
2. 引用之间的转换。
3. 指针和足够大的int之间的转换。
4. 整数到指针之间的一个转换。
3.5 static_cast与dynamic_cast的区别?
答案
1. 编译时期的不同。static_cast是在编译时期强制转换,dynamic_cast在运行时期转换。
2. 类型检查的不同:static_cast是C的强制类型转换,不做检查。 而dynamic_cast会在运行时检查该转换是否类型安全,只在多态类型是合法。要转的类至少具有一个虚函数。(扩展:dynamic_cast在转换前会检查指针(或引用)所指向对象的实际类型是否与转换的目的类型兼容,如果兼容转换才会发生,才能得到派生类的指针(或引用),否则:如果执行的是指针类型的转换引用,会得到空指针;如果执行的是用引用类型的转换,会抛出异常。)(扩展2:在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的;在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全)
3. 是否可以转换对象:dynamic_cast可以转换指针和和引用(基类到派生类),不能用来转换对象。 而static_cast可以转换对象。
4. vector怎么删除重复的元素
答案
答案:sort->unique->erase
假如是一个数组,存在多个重复的元素。我们可以先用sort进行排序,然后用vector的erase(unique)删除掉重复的元素。unique返回的是重复元素的开始位置。
**注意**
>1. 算法unique能够移除重复的元素。每当在[first, last]内遇到有重复的元素群,它便移除该元素群中第一个以后的所有元素。
>2. unique只移除相邻的重复元素,如果你想要移除所有(包括不相邻的)重复元素,必须先将序列排序,使所有重复元素都相邻。
>3. unique会返回一个迭代器指向新区间的尾端,新区间之内不包含相邻的重复元素。
>4. 事实上unique并不改变元素个数,有一些残余数据会留下来,可以用erase函数去除。
> sort->unique->erase
4.1 vector的底层原理?删除一个元素底层会做什么事情?
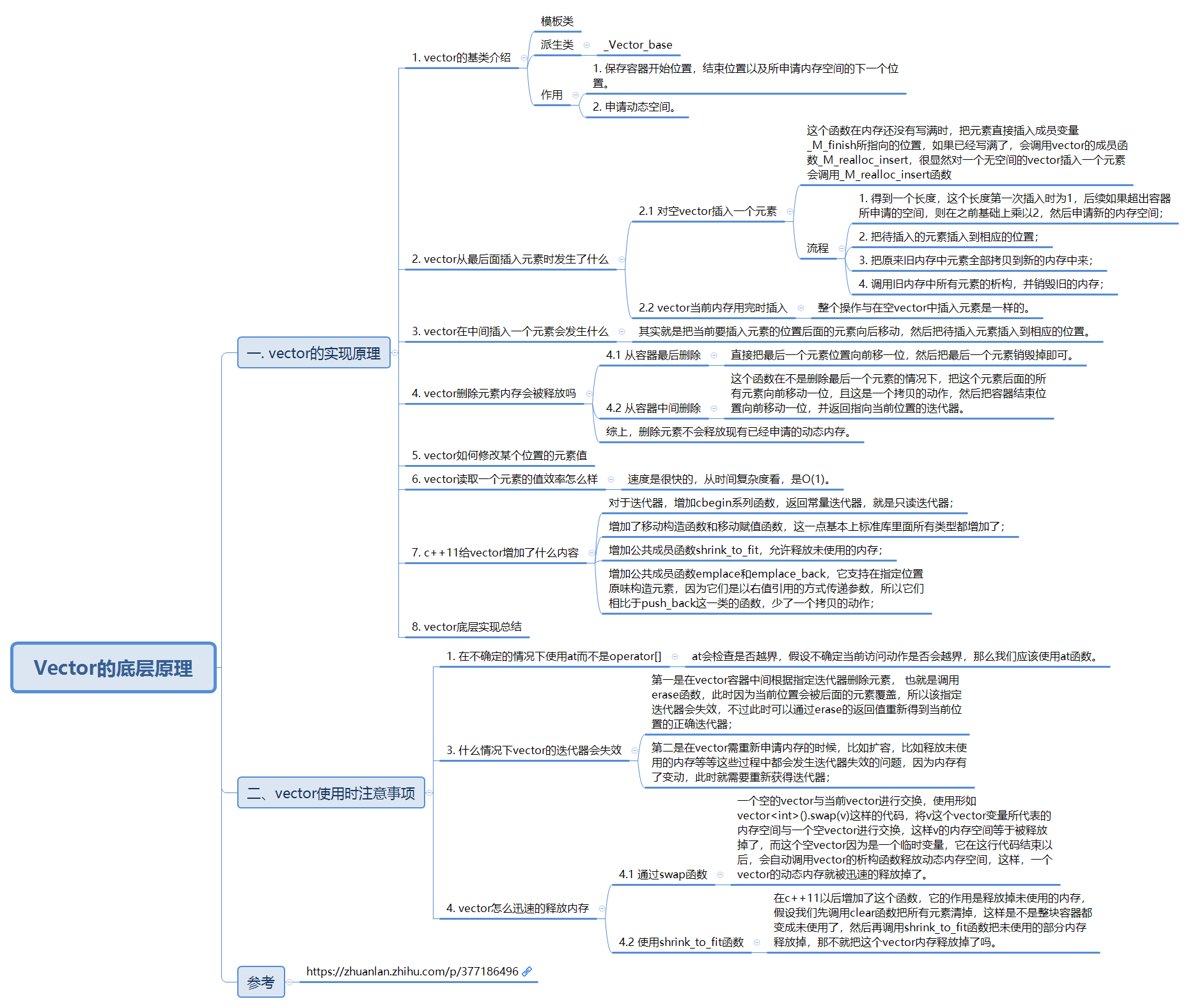
vector的底层源代码
template<class T, class Alloc = alloc>
class vector {
public:
typedef T value_type;
//vector中的迭代器就是一个指针
typedef value_type* iterator;
typedef value_type& reference;
typedef size_t size_type;
protected:
iterator start;
iterator finish;
iterator end_of_storage;
public:
iterator begin() { return start; }
iterator end() { return finish; }
size_type size() const
{
return size_type(end() - begin());
}
size_type capacity() const
{
return size_type(end_of_storage - begin());
}
bool empty() const { return begin() == end(); }
reference operator[](size_type n)
{
return *(begin() + n);
}
reference front() { return *begin(); }
reference back() { return *(end() - 1); }
}
void push_back(const T& x) {
//尚有备用空间
if (finish != end_of_storage) {
construct(finish, x);
++finish:
}
else //已经没有备用空间了
insert_aux(end(), x);
}
template <class T, class Alloc>
void vector<T, Alloc>::insert_aux(iterator position, const T& x) {
if ();
else {
const size_type old_size = size();
//如果原大小为0,则分配1;
//如果原大小不为0,则分配原大小的两倍
//前半段用来放原始数据,后半段准备用来放置新数据
const size_type len = old_size != 0 ? 2 * old_size : 1;
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
try {
//将原vector的内容拷贝到新vector
new_finish = uninitialized_copy(start, position, new_start);
//为新元素设定初值
construct(new_finish, x);
++new_finish;
}
catch (...) {
}
}
}
vector所拥有的变量如下
template <class T, class Alloc = alloc>
class vector
{
protected:
iterator start;
// 目前使用的空间头
iterator finish;
// 目前使用的空间尾 i
iterator end_of_storage; // 目前可用的空间尾
}
答案
底层原理:一段连续线性内存空间。以上定义中迭代器start和finish之间是已经被使用的空间范围,end_of_storage是整块连续空间包括备用空间的尾部。end_of_storage存在的原因是为了降低空间配置的成本,vector实际分配空间大小的时候会比客户端需求的大一些,以便于未来的可能的扩展。
运用start,finish,end_of_storage三个迭代器,便可轻易地提供首尾标示、大小、容量、空容器判断、注标([])运算子、最前端元素值、最后端元素值…等机能:
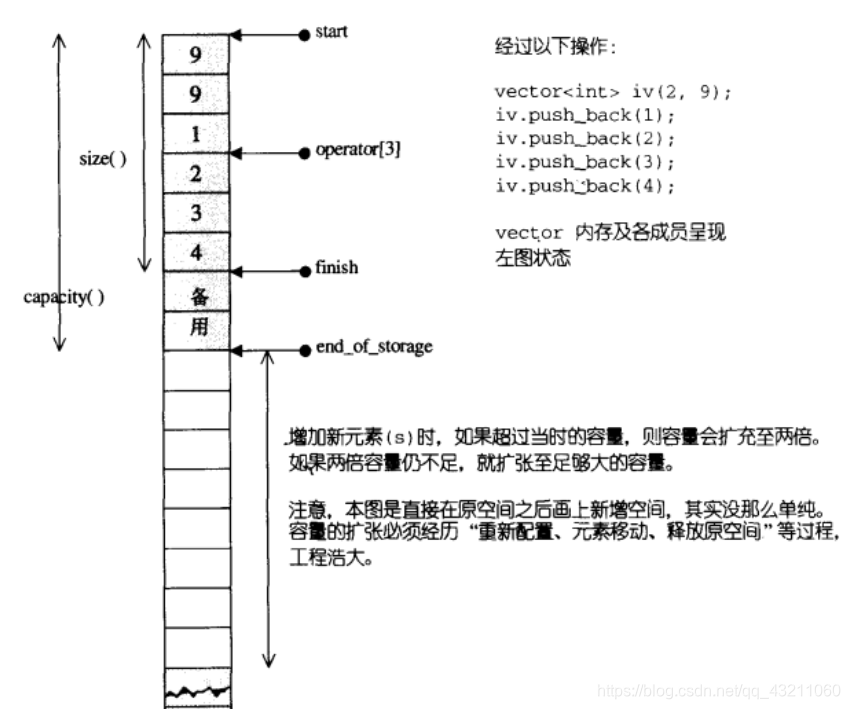
4.2 vector 扩容的本质
答案
**重新申请,移动元素,释放空间**
需经历的步骤如下:
1. 完全弃用现有的内存,重新申请更大的内存空间。
2. 将旧内存空间中的数据,按原有顺序移动到新的内存空间中。
3. 最后将旧的内存空间释放。
4. 不同的编译器实现的扩容方式不一样,VS2015中以1.5倍扩容,GCC以2倍扩容。
4.3 vector的push_back()
源代码
void push_back(const T& x)
{
if(finish!=end_of_storage)
{
construct(finish,x);//把x这个元素放入finish这个位置
++finish;
}
else//如果已经没有备用空间了
{
insert_aux(end(),x);
}
}
template<class T,class Alloc>
void vector<T,Alloc>::insert_aux(iterator position,const T&x)
{
if(finish!=end_of_storage)//尚有备用空间
{
//在备用空间起始处建立一个元素,并以vector最后一个元素值为其初值
construct(finish,*(finish-1));
++finish;//调整水位
T x_copy = x;
copy_backward(position,finish-2,finish-1) ;
*posion = x_copy;
}
else//已无备用空间
{
const size_type old_size = size();
const size_type len = old_size!=0?2*old_size:1;
//以上分配原则,若原大小为0,则分配1.
//若原大小不为0,则分配原大小的两倍。
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
try{
new_finish = uninitialized_copy(start,position,new_start);
construct(new_finish,x);
new_finish = uninitialized_copy(position,finish,new_finish);
}
catch(){
destroy(new_start,new_finish);
data_allocator::dealocate(new_start,len);
throw;
}
destroy(begin(),end());
deallocate();
start = new_start;
finish = new_finish;
end_of_storage = new_start+len;
}
}
4.4 vector的插入,删除
删除
对于序列式容器(vector、deque、list),删除当前的iterator会使后面所有元素的iterator都失效。这是因为vector,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。使用erase方法后,返回的是下一个有效的iterator。例如:
vector<int> val = { 1,2,3,4,5,6 };
vector<int>::iterator iter;
for (iter = val.begin(); iter != val.end(); ){
if (3 == *iter){
iter = val.erase(iter); //返回下一个有效的迭代器
} else {
++ iter;
}
}
vector的erase方法
iterator erase(iterator position){
if(position + 1 != end())
copy(position + 1, finish, position); //后序的元素向前移动
-- finish;
destory(finish);
return position;
}
vector的插入
//往某个位置插入一个元素,则这个位置之后的元素都要后移,因此后面的迭代器都会失效;如果引起内存的重新配置,所有的迭代器都将失效。
vector<int> val = { 1,2,3,4,5,6 };
vector<int>::iterator iter = val.begin();
val.insert(iter, 0);
for (iter = val.begin(); iter != val.end(); iter ++){
cout<<*iter<<" ";
}
}
4.5 emplace_back VS push_back
4.6 扩容会导致效率低下,那如何避免动态扩容呢?
答案
如果在插入之前,可以预估vector存储元素的个数,提前将底层容量开辟好即可。如果插入之前进行reserve,只要空间给足,则插入时不会扩容,如果没有reserve,则会边插入边扩容,效率极其低下。
4.7 为什么以1.5倍或者2倍的方式扩容,而不是使用等长扩容?
答案
计算结论:等长方式扩容后,push_back的时间复杂度为O(N)
以倍数方式进行扩容,push_back的时间复杂度为O(1)
所以选择倍数的方式进行扩容。
4.8 为什么选择以1.5倍或者2倍方式进行扩容?而不是3倍4倍扩容?
答案
1). 使用2倍(k=2)扩容机制扩容时,每次扩容后的新内存大小必定大于前面的总和。
2). 而使用1.5倍(k=1.5)扩容时,在几次扩展以后,可以重用之前的内存空间了。
4.9 vs为什么选择1.5倍,linux为什么选择2倍?
答案
1) vs为什么选择1.5倍
Windows中堆管理系统会对释放的堆块进行合并,因此:vs下的vector扩容机制选择使用1.5倍的方式扩容,这样多次扩容之后,就可以使用之前已经释放的空间。
2) linux为什么选择2倍
由于linux引入伙伴系统为内核分配连续的页,伙伴系统将整个内存区域构建成基本大小的basicSize的 1倍,2倍,4倍等,要求是2的整数次幂,因此,linux选用2倍的方式进行扩容,能快速的找到对应的内存块。
详细的讲解:
a. linux下主要使用glibc的ptmalloc来进行用户空间申请的.如果malloc的空间小于128KB,其内部通过brk()来扩张,如果大于128KB且arena中没有足够的空间时,通过mmap将内存映射到进程地址空间.
b. linux中引入伙伴系统为内核提供了一种用于分配一下连续的页而建立的一种高效的分配策略,对固定分区和动态分区方式的折中,固定分区存在内部碎片,动态分区存在外部碎片,而且动态分区回收时的合并以及分配时的切片是比较耗时的.
c. 伙伴系统是将整个内存区域构建成基本大小basicSize的1倍、2倍、4倍、8倍、16倍等,即要求内存空间分区链均对应2的整次幂倍大小的空间,整齐划一,有规律的而不是乱糟糟的。
d. 在分配和释放空间时,可以通过log2(request/basicSize)向上取整的哈希算法快速找到对应内存块。
e. 通过伙伴系统管理空闲分区的了解,可以看到在伙伴系统中的每条空闲分区链中挂的都是2i的页面大小,通过哈希思想进行空间分配与合并,非常高效。估计可能是这个原因SGI-STL选择以2倍方式进行扩容。
vector在push_back以成倍增长可以在均摊后达到O(1)的时间复杂度,相对于增长指定大小的O(n)时间复杂度更好。
为了防止申请内存的浪费,现在使用较多的有2倍与1.5倍的增长方式,而1.5倍的增长方式可以更好的实现对内存的重复利用。
5.深拷贝和浅拷贝
浅拷贝
浅拷贝:实体相同,值拷贝
**浅拷贝**:称值拷贝,将源对象的值拷贝到目标对象中(就是说对象的地址还是相同)去,本质上来说源对象和目标对象共用一份实体,只是所引用的变量名不同,地址其实还是相同的。
深拷贝
深拷贝:开辟空间,内容拷贝。
**深拷贝**:拷贝的时候先开辟出和源对象大小一样的空间,然后将源对象里的内容拷贝到目标对象中去,这样两个指针就指向了不同的内存位置。并且里面的内容是一样的,这样不但达到了我们想要的目的,还不会出现问题,两个指针先后去调用析构函数,分别释放自己所指向的位置。即为每次增加一个指针,便申请一块新的内存,并让这个指针指向新的内存,深拷贝情况下,不会出现重复释放同一块内存的错误。
6. LRU
LRU的简介、思路、算法逻辑
**简介**
LRU的全称为:Least Recently Used。最近最久未使用算法,它是页面置换算法的一种。
LRU 算法根据数据的历史访问记录来进行淘汰数据,其核心思想是「如果数据最近被访问过,那么将来被访问的几率也更高」。实现的方式还是很难的,如果不会就只能作罢了。
**思路**
map存储数据,实现查找效率为O(logN),双向链表实现算法逻辑。
**算法逻辑**
>1. 新数据会插入到链表的头部
>2. 当缓存数据被访问时,将该缓存数据移到链表的头部。
>3. 当新数据插入时,达到缓存上限了,将尾部数据删除掉,新数据放在头部。
源代码
#include <iostream>
#include <map>
using namespace std;
struct LinkNode
{
int m_key;
int m_value;
ListNode* pre;
ListNode* next;
ListNode(int key, int value)
{
m_key = key;
m_value = value;
pre = NULL;
next = NULL;
}
}//* LRU缓存实现类 双向链表。
class LRUCache
{
public:
LRUCache(int size)
{
m_capacity = size;
phead = NULL;
pTail = NULL;
}
~LRUCache()
{
map<int, ListNode*>::iterator it = mp.begin();
for (; it != mp.end();)
{
delete it->second;
it->second = NULL;
mp.erase(it++);
}
delete phead;
phead = NULL;
delete pTail;
pTail = NULL;
}//** 这里只是移除,并不删除节点
void Remove(ListNode* pNode) {
// 如果是头节点
if (pNode->pPre == NULL)
{
pHead = pNode->pNext;
pHead->pPre = NULL;
}
// 如果是尾节点
if (pNode->pNext == NULL)
{
pTail = pNode->pPre;
pTail->pNext = NULL;
}
else
{
pNode->pPre->pNext = pNode->pNext;
pNode->pNext->pPre = pNode->pPre;
}
}
// 将节点放到头部,最近用过的数据要放在队头。
void SetHead(ListNode* pNode)
{
pNode->pNext = pHead;
pNode->pPre = NULL;
if (pHead == NULL)
{
pHead = pNode;
}
else
{
pHead->pPre = pNode;
pHead = pNode;
}
if (pTail == NULL)
{
pTail = pHead;
}
}
// * 插入数据,如果存在就只更新数据
int Set(int key, int value)
{
map<int, ListNode*>::iterator it = mp.find(key);
if (it != mp.end())
{
ListNode* Node = it->second;
Node->m_value = value;
Remove(Node);
SetHead(Node);
}
else
{
ListNode* NewNode = new ListNode(key, value);
if (mp.size() >= m_capacity)
{
map<int, ListNode*>::iterator it = mp.find(pTail->m_key);
//从链表移除
Remove(pTail);
//删除指针指向的内存
delete it->second;
//删除map元素
mp.erase(it);
}
//放到头部
SetHead(NewNode);
mp[key] = NewNode;
}
}
//获取缓存里的数据
int Get(int key)
{
map<int, ListNode*>::iterator it = mp.find(key);
if (it != mp.end())
{
ListNode* Node = it->second;
Remove(Node);
SetHead(Node);
return Node->m_value;
}
else
{
return -1; //这里不太好,有可能取得值也为-1
}
}
int GetSize()
{
return mp.size();
}
private:
int m_capacity; //缓存容量
ListNode* pHead; //头节点
ListNode* pTail; //尾节点
map<int, ListNode*> mp; //mp用来存数据,达到find为O(logN)级别。
};
7.1 静态多态和动态多态是如何实现的?
静态多态的实现方式:
静态多态性是通过**重载**实现的,在程序编译时系统就可以确定调用哪个函数,因此也称为编译时的多态性.
1. 函数重载: 包括普通函数的重载和成员函数的重载。**重载函数的关键**是函数参数列表——也称函数特征标。包括:**函数的参数数目和类型,以及参数的排列顺序**。所以,重载函数与返回值,参数名无关。
2. (泛型编程)函数模板的使用.函数模板是通用的函数描述,也就是说,使用泛型来定义函数,其中泛型可用具体的类型(int 、double等)替换。通过将类型作为参数,传递给模板,可使编译器生成该类型的函数。
3. 运算符重载。
动态多态是如何实现的?
答案
动态多态性则是通过虚函数实现的,在程序运行时才能决定操作的对象,因此也被称为运行时的多态性。程序运行到动态绑定时,通过该指针所指向的对象类型,通过vtpr找到虚函数表,然后调用相应的方法,即可实现多态。
示例
#include <iostream>
using namespace std;
class Base
{
public:
virtual void Print() = 0;
virtual ~Base();
}
class child_1 :public Base {
public:
void Print()
{
cout << "--->child1";
}
}class child_2 :public Base
{
public:
void Print()
{
cout << "---> child2";
}
}
int main()
{
Base* p = new Child_1();
p->Print();
delete p;
p = new Child_2();
p->Print();
p = NULL;
return 0;
}
编译器如何判断一个函数是否是虚函数?
答案
方法:该函数的最前面有virtual进行声明。就会为其搞一个虚函数表,也就是VTABLE。
VATBLE的介绍:
VTABLE实际上是一个函数指针的数组,每个虚函数占用这个数组的一个slot。一个类只有一个VTABLE,不管它有多少个实例。派生类有自己的VTABLE,但是派生类的VTABLE与基类的VTABLE有相同的函数排列顺序,同名的虚函数被放在两个数组的相同位置上。在创建类实例的时候,编译器还会在每个实例的内存布局中增加一个vptr字段,该字段指向本类的VTABLE。通过这些手段,编译器在看到一个虚函数调用的时候,就会将这个调用改写。
7.1_1 为什么C语言中没有重载呢?
答案
答案:由于C与C++函数在内部对函数名字的不同修饰方式,决定了C语言是没有重载的。
编译器在编译期间创建的一个字符串,用来指明函数的定义或原型。C和C++程序的函数在内部使用不同的名字修饰方式。
**C编译器的函数名修饰规则:**
1. 对于__stdcall调用约定,编译器和链接器会在输出函数名前加上一个下划线前缀,函数名后面加上一个“@”符号和其参数的字节数,例如_functionname@number。
2. __cdecl调用约定仅在输出函数名前加上一个下划线前缀,例如_functionname。
3. __fastcall调用约定在输出函数名前加上一个“@”符号,后面也是一个**“@”符号和其参数的字节
例如@functionname@number。
**C++编译器的函数名修饰规则:**
C++的函数名修饰规则有些复杂,但是信息更充分,通过分析修饰名不仅能够**知道函数的调用方式,返回值类型,参数个数甚至参数类型。
不管 __cdecl,__fastcall还是__stdcall调用方式,函数修饰都是以一个“?”开始,后面紧跟函数的名字,再后面是参数表的开始标识和 按照参数类型代号拼出的参数表。
对于__stdcall方式,参数表的开始标识是“@@YG”,
对于__cdecl方式则是“@@YA”,
对于__fastcall方式则是“@@YI”。参数表的拼写代号如下所示:
7.2 多态性指的是什么?(什么是多态)
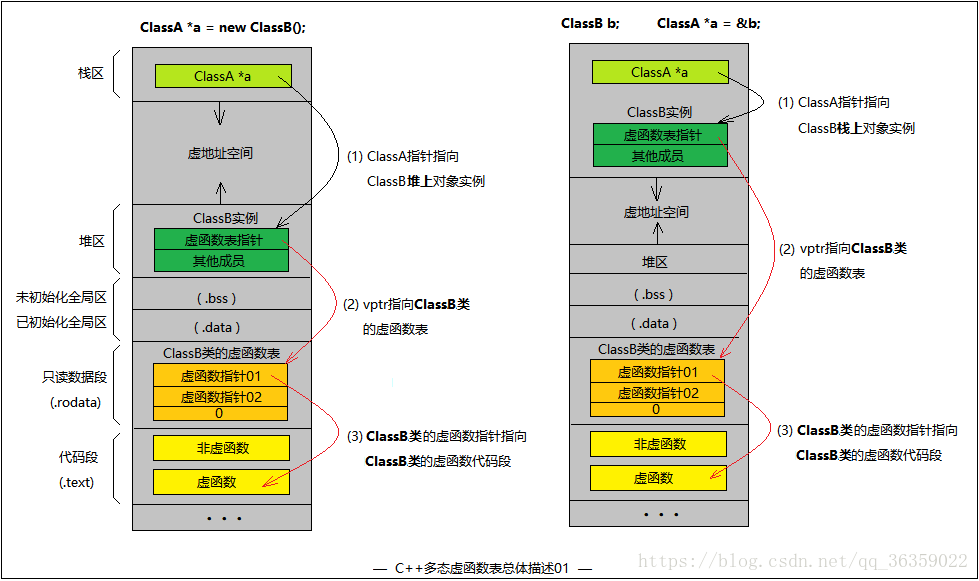
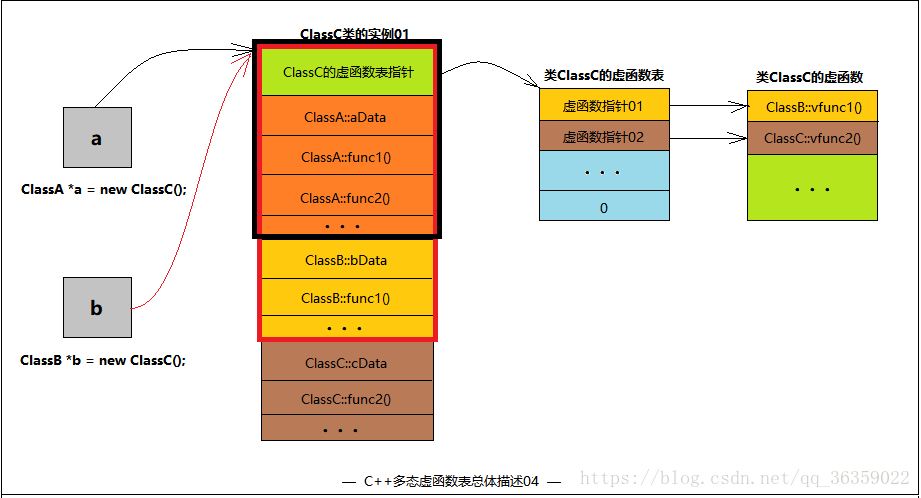
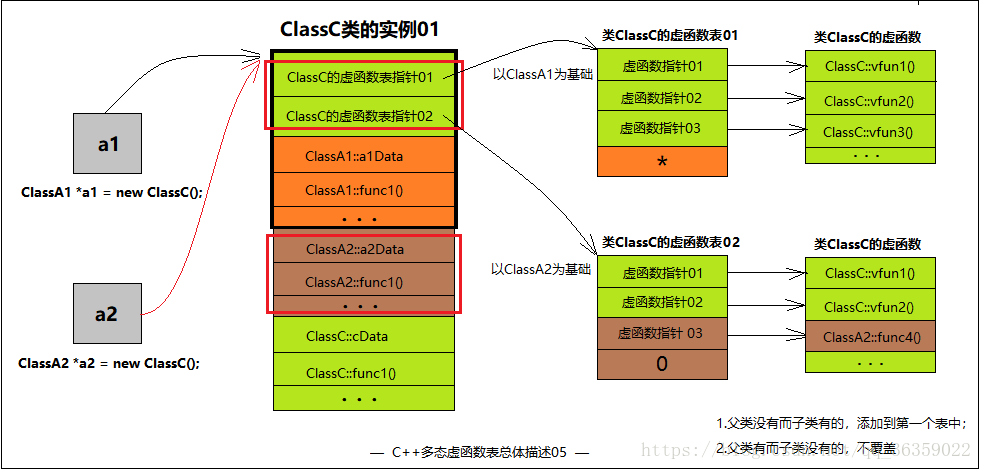
答案
1. 在有继承情况下,只要基类有虚函数,子类不论实现或没实现,都有虚函数表。
2. 在多继承情况下,有多少个基类就有多少个虚函数表指针,前提是基类要有虚函数才算上这个基类。
ClassA* a = new ClassC;
a->func1(); // "ClassA::func1()" 隐藏ClassB::func1()
a->func2(); // "ClassA::func2()" 隐藏ClassC::func2()
a->vfunc1(); // "ClassB::vfunc1()" ClassB把ClassA::vfunc1()覆盖了
a->vfunc2(); // "ClassC::vfunc2()" ClassC把ClassA::vfunc2()覆盖了
ClassB* b = new ClassC;
b->func1(); // "ClassB::func1()" 有权限操作时,子类优先
b->func2(); // "ClassA::func2()" 隐藏ClassC::func2()
b->vfunc1(); // "ClassB::vfunc1()" ClassB把ClassA::vfunc1()覆盖了
b->vfunc2(); // "ClassB::vfunc2()" ClassC把ClassA::vfunc2()覆盖了
答案
答: 其实多态就是在运行时根据对象的实际类型调用相应的函数。
**说法一**:
1. 多态性指的是相同对象在接收不同消息 或 不同对象接收相同消息产生不同的实现动作。
2. 多态支持运行时多态和编译时多态。编译时多态是由子类的重载所实现的,而运行时多态是由虚函数实现的。多态的目的是为了代码模块化和接口重用。
**说法二**:
(运行时多态)在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
**说法三**:
多态按字面来理解就是多种形态。当类之前存在层次结构,并且类之间是通过继承关联的,就会用到多态。C++多态意味着在调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。
7.3 使用多态的过程中应注意什么点?
答案
1. 构造函数中不能使用虚函数。因为我们在创建一个对象时是需要知道该对象的类型的,而虚函数的特性就是在运行时才能确定对象的类型。
2. 析构函数则必须用多态,否则在调用析构函数时,没办法根据调用对象的类型调用相应的析构函数,有写对象的内存有可能不会被释放。
7.4. 讲一下对多态的理解(多态有哪些实现方式?)
答案
**概念**
首先,多态的实现方式分为两种:重载(静态多态),重写(动态多态)。
**重载**是在相同作用域内,函数名相同,**形参个数或类型或顺序**不同的实现方式。这是一种静态多态,即其作用的函数是在编译时就确定了的。
**重写**是在不同的作用域内,即要求一个在父类,而一个在子类,这两个函数的函数名,以及形参个数,类型都必须相同。这是一种动态多态,只有当程序运行的时候,才能确定是哪个函数。
**重定义**是指在不同的作用域内,即一个在父类,一个在子类中,只要不构成重写,则为重定义。换种说法是,子类中重定义的函数在父类也有一个同名的函数,只不过,父类的该函数并不是虚函数。
7.5 C++虚函数的实现原理(底层结构)
答案
答:实现原理是虚函数表。虚函数表是一个存储类成员函数指针的数据结构,因此在运行时,通过该数据结构,来确定要调用的是基类的函数还是子类的函数。
每一个含有虚函数的类都至少有一个与之对应的虚函数表,其中存放着该类所有的虚函数对应的指针。
**实现原理**
1. 当类中存在虚函数时,编译器会再类中自动生成一个**虚函数表。**
2. 虚函数表是一个存储类成员函数指针的数据结构。
3. 虚函数表由表一起自动生成和维护。
4. virtual修饰的成员函数会被编译器放入虚函数表中。
5. 存在虚函数时,编译器会为对象自动生成一个指向虚函数表的指针(通常称为vptr)
**具体的一个实现过程**
1. 父类的fun()是个虚函数,所以编译器会跟父类对象自动添加了一个vptr指针,来指向父类的虚函数表,这个虚函数表存放了父类的fun()函数的指针。
2. 子类的fun()函数是重写了父类的,所以无论写不写virtual,编译器都会给子类对象添加一个virtual和vptr指针,指向子类的虚函数表,这个虚函数表存放了子类fun()函数的函数指针。
3. 指向p->fun()时,编译器会检测到fun()是一个虚函数,所以会**在运行时,动态的根据指向的对象,找到这个对象的vptr,然后找到这个对象的虚函数表,最后调用虚函数表里对应的函数,从而实现多态**
4. 虚函数表存放在可执行文件的.rodata数据段之中。
7.5_1 函数指针与指针函数
函数指针
定义
定义1:
函数指针是指向函数的指针变量,即本质上是一个指针变量。
定义2:
一个函数在编译时被分配一个入口地址,将这个入口地址称为函数的指针,可以用一个指针变量指向该函数指针,然后通过该变量调用函数。
函数指针的声明格式:
函数返回值类型 (*指针变量名)(参数类型列表)
int (*f) (int x); /* 声明一个函数指针 */
f=func; /* 将func函数的首地址赋给指针f */
其实这里不能称为函数名,应该叫做指针的变量名,这个特殊的指针指向函数的地址
int max(int x, int y)
{
return x > y ? x : y;
}
int (* p)(int, int) = & max; // &可以省略,这里的p就是函数指针。
定义3:typedef uint8_t (*func_ptr) (void);
这里是把定义了一个别名叫(*func_ptr) (void) 的吗,显然不对,其含义是:
上面的例子定义func_ptr是一个函数指针, 函数类型是不带形参, 返回参数是uint8_t。
要定义的类型是uint8_t (*)(void),没有输入参数,返回值为uint8_t 的函数指针,定义的别名是func_ptr。
在分析这种形式的定义的时候可以这样看:先去掉typedef和别名, 剩下的就是原变量的类型。去掉typedef和func_ptr以后就剩:uint8_t (*)(void)。
指针函数
答案
类型标识符 *函数名(参数表) int *f(x,y);
指针函数是指带指针的函数,即本质是一个函数.
首先它是一个函数,只不过这个函数的返回值是一个地址值。指针函数一定有函数返回值,而且在主调函数中,函数返回值必须赋给同类型的指针变量。
注意指针函数与函数指针表示方法的不同,千万不要混淆。
最简单的辨别方式
就是看函数名前面的指针*号有没有被括号()包含,如果被包含就是**函数指针**,反之则是**指针函数**。
7.6 虚函数的使用场景
答案
1. 在有继承关系的类中,析构函数最好使用虚函数。
2. 虚函数的作用是在一个类函数的调用无法在编译时刻确定,必须在运行时刻确定时,应该声明其为虚函数。
7.7. 哪些C++成员函数不能用多态
什么样的函数不能被声明为虚函数?
> 1. **普通函数**:不属于成员函数,是不能被继承的。普通函数只能被重载,不能被重写。因此声明为虚函数没有意义。因为编译器会在编译时绑定函数。而多态体是在运行时绑定,通常通过基类指针子类对象实现绑定。
> 2. **友元函数**:不属于类的成员函数,不能被继承,对于没有继承特性的函数没有虚函数的说法。友元函数
> 3. **构造函数**:a.构造函数时用来初始化对象的,例如,子类可以继承基类的构造函数,那么子类对象得到构造将使用基类的构造函数,而基类构造函数并不知道子类有什么成员,所以不能使用继承。b.另一个角度是,多态是通过基类指针指向子类对象来实现多态的,在对象构造之前并没有对象产生,因此无法使用多态,这是矛盾的。
> 4. **内联成员函数**:该函数的作用是为了在代码中直接展开,减少函数调用的代价。也就是内联函数时在编译时展开的。在编译的时候,将这个内联函数的代码副本放置在每个调用该函数的地方。而多态,是在运行时绑定的,所以显然,相互违背。
> 5. **静态成员函数**:该函数理论上是可继承的。但静态成员函数是在编译时确定的,无法动态绑定。不支持多态。
1)static成员不属于任何类对象或类实例,所以即使给此函数加上virtual也是没有任何意义的。
2)静态与非静态成员函数之间有一个主要的区别。那就是静态成员函数没有隐藏的this指针。对于虚函数,它的调用恰恰需要this指针。在有虚函数的类实例中,this指针调用vptr指针,vptr找到vtable(虚函数列表),通过虚函数列表找到需要调用的虚函数的地址。总体来说虚函数的调用关系是:this指针->vptr->vtable ->virtual虚函数。所以说,static静态函数没有this指针,也就无法找到虚函数了
> 6. **成员函数模板**: 不能是虚函数。因为c++ 编译器在解析一个类的时候就要确定虚函数表的大小,如果允许一个虚函数是模板函数,那么compiler就需要在parse这个类之前扫描所有的代码,找出这个模板成员函数的调用(实例化),然后才能确定vtable的大小,而显然这是不可行的,除非改变当前compiler的工作机制。因为类模板中的成员函数在调用的时候才会创建
7.9 可以在C++的成员函数里调用delete this?
答案
1. 在类的成员函数中能调用delete this 吗?
可以,但要注意,在delete this之后,当调用delete this时,类对象的内存空间被释放。不能再涉及这个对象的数据成员和虚函数。
原因是:类对象在声明之后,系统会分配内存空间,这个内存空间中存有的数据是:数据成员和虚函数表指针。
所以,一旦delete this的话,该内存空间被释放,那么就不能再操作数据成员以及调用虚函数了。但按理说是应该程序崩溃的,可实际上,会出现不可告知的情况。因为该内存空间被释放,并不一定会马上被回收。所以,会出现不可预期的情况。
2. 在类的析构函数中调用delete this会发生什么情况?
会出现堆栈溢出的情况,因为delete本身就会去调用析构函数,所以是不断的循环调用该类的析构函数。
7.10 C++的=delete表示的含义是什么?
答案
当我们定义一个类的成员函数时,如果后面使用"=delete"去修饰,那么就表示这个函数被定义为deleted,也就意味着这个成员函数不能再被调用,否则就会出错。
int func(int data)=delete;
在C++11之前,我们不希望一个类被拷贝,就会把构造函数定义为private,但在。
8、问题:const的作用有哪些,谈谈你对const的理解
1. const的相关概念?
1_1. 什么是const?
答案
const是用来修饰常类型的类型修饰符,常类型的对象和变量的值不能更新的。const修饰的值并不是真的常量,它只是告诉编译器该变量不能出现在赋值符号的左边。
1_2. 为什么引入const(const的作用)?
答案
为了替换预处理指令,摒弃其缺点(无法进行类型检查),继承其优点,并发扬光大.
1_3. const修饰的变量的存储位置?
C语言:
答案
1. const全局变量最初在编译器是保存在符号表的,但在第一次使用的时候,为其分配内存,将其保存在只读数据段。不可通过指针对const全局变量进行修改。
2. const局部变量(在函数中定义的const变量) 存储在栈中,代码块结束时释放。可通过指针对const局部变量进行修改。
C++:
答案
**const全局变量**:
1. 若只是简单的替换值,那么就不分配内存空间。 不过若要对其取地址或是使用extern时,就要对其分C++11里面,我们就可以在构造函数后加上=delete来修饰下就可以了配内存。 存储在只读数据段,也是不能修改的。
**const局部变量**:
1. 对于`const int a= 10;`这种,编译器会将其放入符号表中,不分配内存,只有当对其取地址的时候,会分配内存。
2. 若用一个变量来初始化const变量的话,如`const int a = b;`,则会分配内存。一般就是分配在栈中。
1_4. const的作用?
答案
1. 为了替换预处理指令,摒弃其缺点(无法进行类型检查),继承其优点,并发扬光大.
2. 便于类型检查,消除隐患。
3. 可以避免意义模糊的数字出现,同时可以很方便的进行参数的调整和修改。
4. 可以保护被修饰的东西,防止意外的修改。可以修饰常量,变量,函数形参,函数返回值,类等。若const修饰的是对象(常对象),则该对象只能调用const 成员(包括成员函数或成员变量).若const修饰的是引用(常引用),则引用所引用的对象不能被更新。
5. 可以节省内存空间。
6. 可以提高效率。编译器通常不为普通const常量分配存储空间,而是将其保存在符号表中,这使其成为一个编译时期的常量,没有了存储于读内存的操作。
1_5. C语言的const存在的隐患
答案
如果在C语言中,用const定义了一个常量。那么按理说,应该该值是不可更改的,可实际上,是可以通过指向一个变量地址的指针去指向它,然后通过*p1去健个修改b的值。
1_6. const的实战用途
答案
1. 对变量来说:防止一个变量被更改。
2. 对指针来说:可以防止指针被修改,可以防止指针指向的对象被修改。
3. 对函数形参来说: 修饰函数形参,表明它是一个输入参数,在函数内部不能改变其值。
4. 对类的成员函数来说: 若指定该函数为const,则表明其实一个常函数,不能修改类的成员变量。
5. 对成员函数的返回值来说: 若指定返回值为const,则该返回值就不是一个左值。
2. const如何修改
答案
1. 方法一:在const前面加上volatile.
2. 方法二:通过创建一个指针,通过显式类型转换,获取a变量的地址。
3. const常见例子
例子1
1. const int a;//a是一个常整型数
2. int const a;//a是一个常整型数
3. const int *a;//a是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以)
4. int *const a;//a是一个指向整 型数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的)
5. int const *a const;//a是一个指向常整型数的常指针(也就是说,指针指向的整型 数是不可修改的,同时指针也是不可修改的)
例子2
// 类
class A
{
private:
const int a; // 常对象成员,可以使用初始化列表或者类内初始化
public:
// 构造函数
A() : a(0) { };
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数,不得修改类中的任何数据成员的值
};
void function()
{
// 对象
A b; // 普通对象,可以调用全部成员函数
const A a; // 常对象,只能调用常成员函数
const A *p = &a; // 指针变量,指向常对象
const A &q = a; // 指向常对象的引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指针变量,指向字符数组常量(const 后面是 char,说明指向的字符(char)不可改变)
char* const p3 = greeting; // 自身是常量的指针,指向字符数组变量(const 后面是 p3,说明 p3 指针自身不可改变)
const char* const p4 = greeting; // 自身是常量的指针,指向字符数组常量
}
// 函数
void function1(const int Var); // 传递过来的参数在函数内不可变
void function2(const char* Var); // 参数指针所指内容为常量
void function3(char* const Var); // 参数指针为常量
void function4(const int& Var); // 引用参数在函数内为常量
// 函数返回值
const int function5(); // 返回一个常数
const int* function6(); // 返回一个指向常量的指针变量,使用:const int *p = function6();
int* const function7(); // 返回一个指向变量的常指针,使用:int* const p = function7();
9. 宏的相关概念
9_1. define的作用?
答案
1. 避免了意义模糊的数字出现。
2. 便于修改
3. 有了提高程序的运行时效率,减少程序运行时的函数调用,就可以提高程序的运行时效率了。
9_2.#define 宏函数,为什么能够提高性能?
答案
首先,有几个概念:
1.函数调用在编译后程序运行时进行,分配内存空间。函数调用占运行时间
2.宏替换在编译前进行,不分配内存,宏展开不占运行时间,只占编译时间。
也就是我的宏替换,就是做到了上面的两点,所以,我提升了运行效率。
首先,函数调用的功能,宏替换可以实现,例如:
#define S(a,b) a*b
这个就可以代替函数调用了。并且,这个还实现了第二点,所以提高了性能。
但有三个缺点
1. 如果目标代码空间较大的话,不建议使用宏替换,否则空间和时间都获取不到。
2. 不方便调试
3. 宏定义只是简单的值替代,缺乏类型的检测机制。
9_3. typedef和define有什么区别
答案
1. 功能不同。
typedef不是简单的替换,而是起一个类型的别名。
define只是简单的替换,可以定义常量,变量,编译开关等。
2. 作用域不同。
typedef 若在函数外定义,则作用域只有当前文件,若在函数内定义,则作用域只有该函数。
#define,无论是在函数内还是在函数外,作用域都是从定义开始到整个文件结尾。
3. 执行阶段不同。
#define是在预处理阶段进行处理的。
typedef是在编译阶段进行处理的。
4. 对指针的操作不同:这里属于严重不同,要注意,虽然都是用pint 代替int * 但是,但是typedef 相当于是一个别名
typedef int * pint;
#define PINT int *
int i1 = 1, i2 = 2;
const pint p1 = &i1; //p不可更改,p指向的内容可以更改,相当于 int * const p;
const PINT p2 = &i2; //p可以更改,p指向的内容不能更改,相当于 const int *p;或 int const *p;
9_4 do {...} while (0) 在宏定义中的作用
答案
担心这样的宏->#define foo(x) bar(x); baz(x)
这样的宏,如果没手动做一个do while循环,很可能最终的结果与我们期望的结果大相径庭。
do能确保大括号里的逻辑能被执行,而while(0)能确保该逻辑只被执行一次,即与没有循环时一样。
10. 谈一下对static的理解?
10_1. 说一下static的作用(static使用的场所).
答案
1. 隐藏。所有未加static前缀的全局变量和函数都具有全局可见性。加了static,则将该全局变量或函数限制在该文件中,对其他文件不可见。
2. 延长局部变量的生命周期,只初始化一次,直到程序运行结束以后才释放。原因是:静态变量在全局数据区中分配内存,直到程序运行结束,才释放内存.
10_2. static的用法?
答案
1、被 static 修饰的变量属于类变量,可以通过类名.变量名直接引用,而不需要 new 出一个类来。
2. 被 static 修饰的方法属于类方法,可以通过类名.方法名直接引用,而不需要 new 出一个类来
10_3. 静态资源的特性(静态资源与非静态资源之间的相互调用问题)
答案
从类的加载机制的角度讲,静态资源时类初始化的时候加载的,而非静态资源时类实例化对象的时候加载的。
1)静态方法能不能引用非静态资源?不能,实例化对象的时候才会产生的东西,对于初始化后就存在的静态资源来说,根本不认识它。
2)静态方法里面能不能引用静态资源?可以,因为都是类初始化的时候加载的,大家相互都认识。
3)非静态方法里面能不能引用静态资源?可以,非静态方法就是实例方法,那是实例化对象之后才产生的,那么属于类的内容它都认识。
4) 静态数据成员可以实现多个对象之间的数据共享,它是类的所有对象的共享成员。只占用一份内存。
5) 静态数据成员既可以通过类引用,也可以通过对象名引用。
6) 非静态成员函数有 this 指针,而静态成员函数没有 this 指针。
11. C语言中的const和static的比较分析?
答案
1. 修饰局部变量
const修饰的局部变量,其存储位置在栈上。但有个特例:const static修饰的局部变量是存储在只读存储区的。
static修饰的局部变量,会将局部变量由栈转到静态区存储。
2. 修饰全局变量
const修饰的全局变量,其存储位置转移到只读存储区了。且,作用域变了。
static修饰的全局变量,依然存储在静态区,只是,作用域变了。
12. extern函数的作用(请你谈谈你对extern的理解)3点?
答案
引用不在同一个文件中的变量或者函数。这样就不必特意包含某个文件。
1. extern表示后面的变量或函数的定义在别的文件中。提升编译器遇到此变量或函数时,在其他模块寻找其定义。
2. extern "C" 用于C++中,用于将C++的一些代码用C语言的方式编译。
3. extern是声明变量,并不是定义,所以并不会分配空间。
4. 如果在一个文件中需要引用另一个文件中的外部变量,则用extern修饰这个外部变量。
13. c++类内常量定义 static const?
答案
1. static const:
·`static const int SIZE = 10;`int/char/bool等。//类内声明,同时初始化,仅适用整型变量,要想对变量进行取地址,必须在实 现文件中再次声明。
· `static const double pi;`//对于非整型变量,只能声明,不能设定初始值。
2. static:对于类内static变量,仅能在头文件中声明,在实现文件进行初始化。
`static int SIZE;`//仅声明,不能初始化。
3. const:对于const 变量,在类内声明必须初始化。
`const int SIZE2 = 9;`//const类型,声明时必须设定初始值
`const doubel pii = 2.6;`//const类型,声明时必须设定初始值
4. enum:类内使用枚举定义常量,不能对常量取地址。
`enum{SIZE3=10;} // 类内使用枚举定义常量,不能对变量取地址
14. 海量数据处理面试题
- 海量日志数据,提取出某日访问百度次数最多的那个IP
答案
a. IP最多2^32次方。直接存入内存hash。
b. 将所有IP存入一个大文件中。使用%1000的方式。分成1000个小文件。然后对每个小文件进行hash映射。接下来,取每个小文件中出现次数最多的ip再进行一次hash就可以了。
- 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
答案
a. 在O(N)的时间内对所有数据进行hash处理。去掉大部分重复的记录。
b. 然后维护一个10个元素的大顶堆结构,时间复杂度为O(NLOGK).
所以,总的时间复杂度为:O(N)+O(NLOGK).
- 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
答案
a. 先将1G的大文件分解成5000个小文件。这样每个文件大约是200k。如果超过内存限制的话,继续分。
b.然后可以采用hash 。
- 在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
答案
a. 使用2 bit-map。(每个数分配两个bit,00表示不存在,01表示出现一次,10表示出现多次,11无意义)然后,扫描这2.5亿整数,查看其对应的位。
b. 进行%1000. 可以分别存入1000个文件中。
14.1Top(K)一般处理方式
答案
1、直接全部排序(只适用于内存够的情况)
当数据量较小的情况下,内存中可以容纳所有数据。
则最简单也是最容易想到的方法是将数据全部排序,然后取排序后的数据中的前K个。
这种方法对数据量比较敏感,当数据量较大的情况下,内存不能完全容纳全部数据,这种方法便不适应了。即使内存能够满足要求,该方法将全部数据都排序了,而题目只要求找出top K个数据,所以该方法并不十分高效,不建议使用。
2、快速排序的变形 (只使用于内存够的情况)
这是一个基于快速排序的变形,因为第一种方法中说到将所有元素都排序并不十分高效,只需要找出前K个最大的就行。
这种方法类似于快速排序,首
先选择一个划分元,将比这个划分元大的元素放到它的前面,比划分元小的元素放到它的后面,此时完成了一趟排序。
如果此时这个划分元的序号index刚好等于K,那么这个划分元以及它左边的数,刚好就是前K个最大的元素;如果index > K,那么前K大的数据在index的左边,那么就继续递归的从index-1个数中进行一趟排序;如果index < K,那么再从划分元的右边继续进行排序,直到找到序号index刚好等于K为止。
再将前K个数进行排序后,返回Top K个元素。这种方法就避免了对除了Top K个元素以外的数据进行排序所带来的不必要的开销。
3、最小堆法
这是一种局部淘汰法。先读取前K个数,建立一个最小堆。然后将剩余的所有数字依次与最小堆的堆顶进行比较,如果小于或等于堆顶数据,则继续比较下一个;否则,删除堆顶元素,并将新数据插入堆中,重新调整最小堆。当遍历完全部数据后,最小堆中的数据即为最大的K个数。
4、分治法
将全部数据分成N份,前提是每份的数据都可以读到内存中进行处理,找到每份数据中最大的K个数。此时剩下N*K个数据,如果内存不能容纳N*K个数据,则再继续分治处理,分成M份,找出每份数据中最大的K个数,如果M*K个数仍然不能读到内存中,则继续分治处理。直到剩余的数可以读入内存中,那么可以对这些数使用快速排序的变形或者归并排序进行处理。
5、Hash法
如果这些数据中有很多重复的数据,可以先通过hash法,把重复的数去掉。这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间。处理后的数据如果能够读入内存,则可以直接排序;否则可以使用分治法或者最小堆法来处理数据。
14.2海量日志处理,提取出日访问百度次数最多的IP地址
答案
**算法思想:分而治之+hash**
首先,将IP地址%1024。将这些ip地址分别放入1024个小文件中。这样每个小文件就包含有4MB个 IP地址,
14.3 如何从 100 亿 URL 中找出相同的 URL?
题目

答案
1. 50 0000 0000 *64B = 5*64GB = 320GB
2. 遍历文件a。执行`hash(URL) % 1000`。根据计算结果把遍历到的 URL 存储到 a0, a1, a2, ..., a999。
3. 遍历文件b。执行`hash(URL) % 1000`。根据计算结果把遍历到的 URL 存储到b0, b1, b2, ..., b999。
4. 这样所有相同的URL都一定在对应的小文件里面。比如a0->b0
5. 接下来遍历ai。把 URL 存储到一个 HashSet 集合中。然后遍历 bi 中每个 URL,看在 HashSet 集合中是否存在,若存在,说明这就是共同的 URL,可以把这个 URL 保存到一个单独的文件中。
**方法总结**
1. 分而治之,进行哈希取余;
2. 对每个子文件进行 HashSet 统计。
14.4 位图法
答案
位图法就是bitmap的缩写,所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。 通常是用来判断某个数据存不存在的。
1. 海量数据排序
从最简单的情况说起,如果要对90个小于100的不重复的正整数排序。用位图的思想就是先申请一块100bit的空间,第一遍遍历所有的数,将出现的数字在位图中对应的位置置为1;第二遍遍历位图,依次输出值为1的位对应的数字。先且不说这种情况出现的频率不是很高,就仅这种情况,还是有很多其他的排序算法有它们自己的优势(不用额外占用空间之类)。但更进一步,如果我们把数字范围放大,对1000,000,000中的900,000,000个不重复的正整数排序,由于需要的内存非常大,其他算法在不分治的情况下就很难再处理这个问题。而用位图法只需要1000000000/(8*1024*104)=119.2MB空间,对现在的计算机来说没有任何问题。
2. 海量数据去重
看一个比较常见的面试题:在2.5亿个整数中找出不重复的整数,内存不足以放下所有的数。我们可以采用两位的位图法,为每个数分配两位,00表示没有出现,01表示出现一次,10表示出现多次,11没有意义。这样下来总共需要232∗2=1232∗2=1GB(这里没有限定整数的范围,所有把所有32位整数都考虑进去)的内存。接下去扫描着2.5亿个整数,查看位图中相对应的位,如果是00就变为01,如果是01就变为10,其他情况保持不变。扫描完成后仍为01的整数就是需要查找的数。
**总结**
Bitmap适用于数据规模大,但数据状态少的情况。同时Bitmap在存在以下一些不足:
存储离散数据利用率低
Bitmap申请空间时要根据最大的数来决定申请的空间大小,如果数据是离散的,那空间的利用率就会非常低。
不适合多状态
一个bit只能表示两种状态,如果要表示更多的状态,就需要更多的状态位来实现。如果一个数字需要多个状态位来表示的话,Bitmap的优越性也会大打折扣,而且复杂度却在增加。
可读性差
将数据抽象为bit不利于理解,尤其是用多个bit位来表示一个数时。
性能一般
需要维护额外的逻辑,计算速度会受到一定的影响。
15. 解释一下HashMap这个数据结构
答案
1. 首先,hashMap是一个保存(key,value)键值对的一个数据结构,每个键值对叫一个Entry。这些Entry分散存储在一个数组中,这个数组就是HashMap的主干。
2. 新来的Entry节点若和原来的冲突的话,则使用头插法将其插入Entry主节点后。之所以使用头插法是因为发明者认为后面插入的节点更容易会被使用。
3. HashMap的默认初始长度是16,并且每次扩展或手动初始化时,长度必须是2的整数次幂。注意为啥是16呢,是为了符合均匀分布的原则,若长度为其他数字,你会发现,在与改数字做与运算的时候,有些index很容易得到,有些index则较难得到。这就违背了Hash算法均匀分布的原则。
4. index = HashCode(Key) & (Length - 1),从value->index
5. 扩容后,要重新遍历原来的Hash数组,从而让该hash数组均衡分布到新的hash数组之中。
19. 请说一下C/C++ 中指针和引用的区别?
区别
1. 名字的含义:指针指向的是一个具体的空间,而引用只是一个别名。
2. sizeof的含义:sizeof(p)大小依据系统不同,会有所不同,32位的系统,指针的大小为4.而引用的sizeof的大小一般是被引用对象的大小。
3. 初始化:指针可以被初始化为NULL,而引用只能被初始化为一个已有对象的引用。
4. 使用:作为参数传递时,指针需要解引用才可以对对象进行操作,而直接对引用的修改都会更改引用所指向的对象。
5. 可以有const指针,但是没有const引用。
6. 指针在使用过程中,可以指向其他对象,而引用只能是一个对象的引用,不能被改变。
7. 指针可以有多级指针,引用只能有一个引用。
总结:指针传递的本质是值传递复制实参的地址到函数的栈中,然后在形参中对地址取值操作。而引用的形参是给实参起了一个别名,可以直接操控形参从而实现对实参的控制。
名字,sizeof,使用,初始化,引用,const,多级
19.0 C++传参是传指针还是传引用?
答案
1. 传指针的好处
1) 指针可以设置默认参数,某些场合有奇效。
2. 传指针的缺点
1) 可能用户会传入NULL指针。
总结:
1 如果参数跟基本属性有关系,那就使用引用,如果参数跟扩展属性有关系,那就使用指针。
2 在指针的优势没有明显高过引用的地方就使用引用,毕竟指针存在释放危险。
3. 逻辑上如果要处理可能为空的这种情况之外,一般都可以使用引用。
4. 传入的内容会被修改的,用指针。
19.1 引用的底层原理
答案
引用即别名,它并非对象,相反地,它只是一个已经存在的对象所起的另外一个名字。引用存放的就是指针的地址。
引用的大小就是一个指针的大小。 引用同指针一样占有内存空间的,且内存的大小与指针一样,即32系统上是4个字节,64位系统上是8个字节。但是对引用进行sizeof运算得到的是被引用对象的内存大小,并不是其真实所占内存
引用在C++中是通过一个指针常量(就是const修饰的指针是常量)来实现的,即&b=a实际上等价于`int* const b=&a`,而编译器会把&b编译为:&(*b),那么得到的自然就是a的地址,所以我们会看到&a、&b得到的地址是一样的。但是一定要注意,&b并不是b的地址。
指针常量:就是这个指针就是一个常量。
19_2. 什么时候使用指针?什么时候使用引用?什么时候应该按值传递?
1. 传递引用的好处:
答案
1. 传递引用,避免了一次实参到形参的拷贝。
2. 程序员能够修改调用函数中的数据对象。
3. 通过传递引用而不是整个数据对象,可以提高运行速度。
4. 数据对象是类对象则使用引用。
5. 注意,引用传递也是要在堆栈中开辟内存空间的。但存放的是主调函数放进来的实参的值。
2. 使用指针:
答案
1. 如果数据对象是数组则使用指针。
2. 需要改变实参的时候,只能使用指针。
3. 需要遍历数组或频繁引用其元素时,使用指针的效率比使用下标的高。
4. 动态分配空间时,必须使用指针。
5. 传递大型结构并且“只读”其元素的时候,使用指针。因为不然大型结构通过值传递,需要拷贝每个元素,这样效率太低了。
3. 什么时候按值传递?
答案
1. 对于内建的数据类型,如小于4字节的的类型来讲,实际上传递时只需要传递1-4个字节。
2. 从健壮性来讲,值传递是比指针传递要健壮的,因为指针传递随便什么指针都可以传入。只要是void*就可以符合要求。而值传递就会进行类型检查。
引用的一些规则如下:
3. 引用被创建的同时必须被初始化。
4. 引用不能指向NULL,必须与合法的存储单元关联。
5. 一旦引用被初始化,就不能改变引用的关系
4. 总结来说什么情况用哪种?
答案
1. 对于那些函数,它们只使用传递过来的值,而不对值进行修改。
(1)如果数据对象很小,如内置数据类型或小型结构,使用按值传递。
(2)如果数据对象是数组,则使用指向const的指针。
(3)如果数据对象是较大的结构,则使用const指针或者const引用,以提高程序的效率。
(4)如果数据对象是类对象,则使用const引用。因此,传递类对象参数的标准方式是按引用传递。
2. 对于那些函数,它们需要修改传递过来的值。
(1)如果数据对象是内置数据类型,则使用指针。
(2)如果数据对象是数祖,则只能使用指针。
(3)如果数据对象是结构。则使用指针或者引用。
(4)如果数据对象是类对象,则使用引用。
21. 你知道什么树?
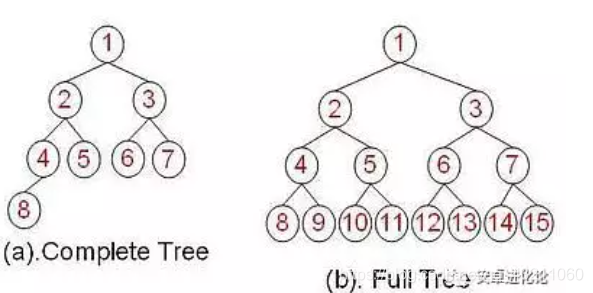
21.1完全二叉树
答案
完全二叉树是一种特殊的二叉树,满足以下要求:
所有叶子节点都出现在 k 或者 k-1 层,而且从 1 到 k-1 层必须达到最大节点数;
第 k 层可以不是满的,但是第 k 层的所有节点必须集中在最左边。
需要注意的是不要把完全二叉树和“满二叉树”搞混了,完全二叉树不要求所有树都有左右子树,但它要求:
任何一个节点不能只有右子树没有左子树
叶子节点出现在最后一层或者倒数第二层,不能再往上
用一张图对比下“完全二叉树”和“满二叉树”:
当我们用数组实现一个完全二叉树时,叶子节点可以按从上到下、从左到右的顺序依次添加到数组中,然后知道一个节点的位置,就可以轻松地算出它的父节点、孩子节点的位置。
以上面图中完全二叉树为例,标号为 2 的节点,它在数组中的位置也是 2,它的父节点就是 (k/2 = 1),它的孩子节点分别是 (2k=4) 和 (2k+1=5),别的节点也是类似。
**完全二叉树使用场景:**
根据前面的学习,我们了解到完全二叉树的特点是:“叶子节点的位置比较规律”。因此在对数据进行排序或者查找时可以用到它,比如堆排序就使用了它,后面学到了再详细介绍。
21.2二叉查找树(二叉排序树)
答案
二叉树的提出其实主要就是为了提高查找效率,比如我们常用的 HashMap 在处理哈希冲突严重时,拉链过长导致查找效率降低,就引入了红黑树。
我们知道,二分查找可以缩短查找的时间,但是它要求 查找的数据必须是有序的。每次查找、操作时都要维护一个有序的数据集,于是有了二叉查找树这个概念。
**二叉查找树(又叫二叉排序树),它是具有下列性质的二叉树:**
若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
左、右子树也分别为二叉排序树。
也就是说,二叉查找树中,左子树都比节点小,右子树都比节点大,递归定义。
根据二叉排序树这个特点我们可以知道:二叉排序树的中序遍历一定是从小到大的。
比如上图,中序遍历结果是:
1 3 4 6 7 8 10 13 14
二叉排序树(二叉查找树)的性能
答案
在最好的情况下,二叉排序树的查找效率比较高,是 O(logn),其访问性能近似于折半查找;
但最差时候会是 O(n),所谓O(n)的含义是算法的运行时间与输入规模呈比例,若输出规模为N,花费时间为T,则若输出规模为2N,则花费时间为2T.比如插入的元素是有序的,生成的二叉排序树就是一个链表,这种情况下,需要遍历全部元素才行(见下图 b)。
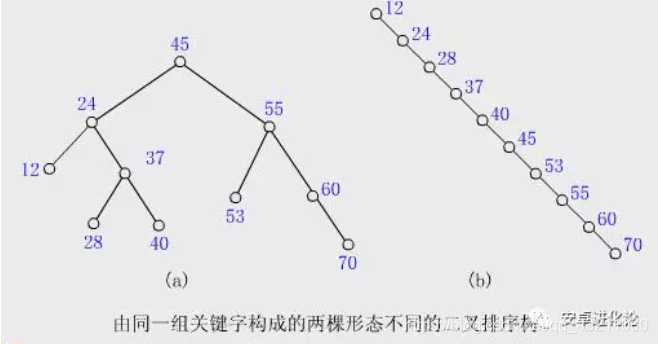
如果我们可以保证二叉排序树不出现上面提到的极端情况(插入的元素是有序的,导致变成一个链表),就可以保证很高的效率了。
但这在插入有序的元素时不太好控制,按二叉排序树的定义,我们无法判断当前的树是否需要调整。
因此就要用到平衡二叉树(AVL 树)了。
21.3平衡二叉树(二叉搜索树)
答案
1. 平衡二叉树提出的原因:
平衡二叉树的提出就是为了保证树不至于太倾斜,尽量保证两边平衡。
2. 平衡二叉树的定义:
平衡二叉树要么是一棵空树
要么保证左右子树的高度之差不大于 1
子树也必须是一颗平衡二叉树
也就是说,树的两个左子树的高度差别不会太大。
3. 示例:
那我们接着看前面的极端情况的二叉排序树,现在用它来构造一棵平衡二叉树。
以 12 为根节点,当添加 24 为它的右子树后,根节点的左右子树高度差为 1,这时还算平衡,这时再添加一个元素 28:
这时根节点 12 觉得不平衡了,我左孩子一个都没有,右边都有俩了,超过了之前说的最大为 1,不行,给我调整!
于是我们就需要调整当前的树结构,让它进行旋转。
因为最后一个节点加到了右子树的右子树,就要想办法给右子树的左子树加点料,因此需要逆时针旋转,将 24 变成根节点,12 右旋成 24 的左子树,就变成了这样(有点丑哈哈):
依次类推,平衡二叉树在添加和删除时需要进行旋转保持整个树的平衡,内部做了这么复杂的工作后,我们在使用它时,插入、查找的时间复杂度都是 O(logn),性能已经相当好了。
21.4 avl树是什么结构,让我说一下怎么插入,插入后怎么旋转。
答案
avl树是平衡二叉树。
**满足以下性质的二叉搜索树:**
> 1、左右子树都是AVL树
> 2、左右子树的高度之差的绝对值不超过1
bf = 右子树的个数-左子树的个数
若bf<0--->右旋转
若bf>0---->左旋转
21. 5 哪两种遍历方式可以唯一确定一棵二叉树?
答案
1. 前序+中序
2. 中序+后序
这两种方式可以唯一确定一棵二叉树。
22. C语言中的strlen与sizeof的区别
答案
1. sizeof与strlen是有着本质的区别,sizeof是求数据类型所占的空间大小,而strlen是求字符串的长度,字符串以/0结尾。
2. sizeof的底层原理:sizeof是运算符,需要操作系统支持。
#define sizeof(type) ((size_t) ((type*)0 + 1))
#define array_sizeof(T) ( (size_t)(&T+1) - (size_t)(&T) )
上面这两句就是其底层原理。
sizeof与strlen的测试代码:
#include <iostream>
#include <stdlib.h>
#include <stdio.h>
#include <cstring>
using namespace std;
int main()
{
//win10 64位系统
int a = 10;
cout<<"--->int1:"<<sizeof(a)<<endl;//4
cout<<"--->int2:"<<sizeof(a++)<<endl;//4
cout<<"--->int3:"<<sizeof(a+1)<<endl;//4
char* pHead = new char[100];
cout<<"--->char*"<<sizeof(pHead)<<endl;//8
string str = "abs";
cout<<"-->string"<<sizeof(str)<<endl;//8
char char2[] = "abcd";
cout<<"--->char2"<<sizeof(char2)<<endl; //5
int a1, b1, c1, d1;
a1 = sizeof("123456789"); //a1为10,而这个还是char 型的数组,9的字符+\0 公共十个字符
b1 = sizeof("123456789"+2); //b1 为8 +2之后,相当于已经被连接成一个char*的指针数组了,所以,不管+多少,都是指针的大小
c1 = strlen("123456789"); //c1为9 strlen算出的字符的长度
d1 = strlen("123456789"+3); //d1为6
cout<<"--->test sizeof1 "<<a1<<endl;
cout<<"--->test sizeof2 "<<b1<<endl;
cout<<"--->test sizeof3 "<<c1<<endl;
cout<<"--->test sizeof4 "<<d1<<endl;
return 0;
}
3. sizeof计算对象的大小
(1)A的大小为4个字节,因为在大部分的情况下计算类的对象大小时只需要计算它的成员变量的大小就可以了,而不需要计算成员函数的大小。
(2)B的大小为8个字节,因为B除了它本身的成员变量大小占4个字节之外,它还有一个虚函数,虚函数需要4个字节去存放虚函数表,所以B的大小为8个字节
(3)C的大小为12字节,是因为它继承了类B,类B的大小为8个字节,再加上它自己的成员变量4个字节,所以有12个字节,注意C的大小不是16个字节,因为子类虽然拥有自己的虚函数,但是与父类共用一张虚表
25. C++ 友元是什么
答案
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
**友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类,在这种情况下,整个类及其所有成员都是友元**。
如果要声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字 friend,如下所示
**优点**
通常对于普通函数来说,要访问类的保护成员是不可能的,如果想这么做那么必须把类的成员都声明成为public(共用的),然而这做带来的问题遍是任何外部函数都可以毫无约束的访问它操作它,c++利用friend修饰符,可以让一些你设定的函数能够对这些保护数据进行操作,避免把类成员全部设置成public,最大限度的保护数据成员的安全。
**缺点**
友元能够使得普通函数直接访问类的保护数据,避免了类成员函数的频繁调用,可以节约处理器开销,提高程序的效率,但所矛盾的是,即使是最大限度大保护,同样也破坏了类的封装特性,这即是友元的缺点,在现在cpu速度越来越快的今天我们并不推荐使用它,但它作为c++一个必要的知识点,一个完整的组成部分,我们还是需要讨论一下的。 在类里声明一个普通数学,在前面加上friend修饰,那么这个函数就成了该类的友元,可以访问该类的一切成员。
29.1 排序算法集合
排序稳定性的概念:排序前相等的两个元素的先后顺序,排序后,是否先后顺序依旧未改变。
1、冒泡排序:
答案
从数组中第一个数开始,依次遍历数组中的每一个数,通过相邻比较交换,每一轮循环下来找出剩余未排序数的中的最大数并“冒泡”至数列的顶端。
稳定性:稳定
平均时间复杂度:O(n ^ 2)
答案
class Solution {
public:
vector<int> sortArray(vector<int>& nums)//冒泡排序
{
int n = nums.size();
for (int i = 0; i < n; i++)
{
bool flag = false;
for (int j = n - 1; j > i; j--)
{
if (nums[j] > nums[j - 1])//不断的比较相邻的两个数,如果比较到i的位置,都还没有出现过一次交换,那么证明已经该数据已经是有序的了,不用再比较了
{
swap(nums[j], nums[j - 1]);
flag = true;
}
}
if (flag == false)
return nums;
}
}
}
2、插入排序:
答案
从待排序的n个记录中的第二个记录开始,依次与前面的记录比较并寻找插入的位置,每次外循环结束后,将当前的数插入到合适的位置。
稳定性:稳定
平均时间复杂度:O(n ^ 2)
代码
class Solution {
public: vector<int> sortArray(vector<int>& nums) {
int n = nums.size();
for (int i = 1; i < n; i++)
{
int cur = nums[i];//这到哪一位,就能将其排到最适合的位置,从而结束这个排序
int index = i - 1;
while (index >= 0 && cur < nums[index])
{
nums[index + 1] = nums[index];
index--;
}
nums[index + 1] = cur;
}
return nums;
}
}; /* 1 4 2 3 5cur = 2;index = 1;num[2] = num[1](4) 1 2 4 3 51 2 3 4 5 */
3、希尔排序(缩小增量排序):
答案
希尔排序法是对相邻指定距离(称为增量)的元素进行比较,并不断把增量缩小至1,完成排序。
希尔排序开始时增量较大,分组较多,每组的记录数目较少,故在各组内采用直接插入排序较快,后来增量di逐渐缩小,分组数减少,各组的记录数增多,但由于已经按di−1分组排序,文件叫接近于有序状态,所以新的一趟排序过程较快。因此希尔 排序在效率上比直接插入排序有较大的改进。
在直接插入排序的基础上,将直接插入排序中的1全部改变成增量d即可,因为希尔排序最后一轮的增量d就为1。
稳定性:不稳定
平均时间复杂度:希尔排序算法的时间复杂度分析比较复杂,实际所需的时间取决于各次排序时增量的个数和增量的取值。时间复杂度在O(n ^ 1.3)到O(n ^ 2)之间。
code
答案
public: vector<int> sortArray(vector<int>& nums) {
int n = nums.size();
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//先划定一个范围
for (int i = gap; i < n; i++)
{
int cur = nums[i];
int index = i - gap;
while (index >= 0 && cur < nums[index])//这个操作可以把nums中把gap作为间隔的地方全部都排好序
{
nums[index + gap] = nums[index];
index = index - gap;
}
nums[index + gap] = cur;
}
}
return nums;
}
4、选择排序:
答案
从所有记录中选出最小的一个数据元素与第一个位置的记录交换;然后在剩下的记录当中再找最小的与第二个位置的记录交换,循环到只剩下最后一个数据元素为止。
稳定性:不稳定
平均时间复杂度:O(n ^ 2)
代码
//selectSort 每次将当前元素替换为后面最小的元素
public static void selectSort(int[] a){
int N = a.length;
for (int i = 0; i < N; i++) {
int min = i;
for (int j = i+1; j < N; j++) {//从i+1到N选一个最小的数,将其idx赋值给min,然后,与原来的a[i]进行数值上的交换
if(a[j]<a[min])
min=j;
}
int t =a[i];
a[i] = a[min];
a[min] = t;
}
}
5、快速排序
答案
1)从待排序的n个记录中任意选取一个记录(通常选取第一个记录)为分区标准;
2)把所有小于该排序列的记录移动到左边,把所有大于该排序码的记录移动到右边,中间放所选记录,称之为第一趟排序;
3)然后对前后两个子序列分别重复上述过程,直到所有记录都排好序。
稳定性:不稳定
平均时间复杂度:O(nlogn)
快速排序
//quickSort 每次选择一个元素并且将整个数组以这个元素分为两部分,小于该元素的放右边,大于该元素的放左边
public void quickSort(int[] arr,int l,int r){
if(l<r){ //跳出递归的条件
//partition就是划分操作,将arr划分成满足条件的两个子表
int pivotpos = partition(arr,l,r);
//依次对左右两个子表进行递归排序
quickSort(arr,l,pivotpos);
quickSort(arr,pivotpos+1,r);
}
}
public int partition(int[] arr,int l,int r){
//以当前数组的最后一个元素作为中枢pivot,进行划分
int pivot = arr[r];
while (l<r){
while (l<r && arr[l]<pivot) l++;
arr[r] = arr[l];//将比中枢值大的移动到右端r处 由于r处为中枢或者该位置值已经被替换到l处,所以直接可以替换
while (l<r && arr[r]>=pivot) r--;
arr[l] = arr[r];//将比中枢值小的移动到左端l处 由于前面l处的值已经换到r处,所以该位置值也可以替换掉
}
//l==r时,重合,这个位置就是中枢的最终位置
arr[l] = pivot;
//返回存放中枢的最终位置
return l;
}
6、堆排序:
答案
堆:
1、完全二叉树或者是近似完全二叉树。
2、大顶堆:父节点不小于子节点键值,小顶堆:父节点不大于子节点键值。左右孩子没有大小的顺序。
堆排序在选择排序的基础上提出的,步骤:
1、建立堆
2、删除堆顶元素,同时交换堆顶元素和最后一个元素,再重新调整堆结构,直至全部删除堆中元素。
稳定性:不稳定
平均时间复杂度:O(nlogn)
核心思想:
将输入分为已排序的和未排序的区域。它通过提取未排序的区域内最大的元素 并将其移到已排序的区域来迭代缩小未排序的区域。其实一种`非稳定排序`.
堆排序的基本思路:
答案
> 1. 将无序序列构建成一个堆,根据升序需求选择大顶堆还是小顶堆。
> 2. 将堆顶元素与末尾元素进行交换,将最大元素沉到数组末端。
> 3. 重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整,交换的操作。
#include <stdio.h>
#include <iostream>
#include <vector>
#include <time.h>
#include <Windows.h>
using namespace std;
//建堆是核心
void Heap_build(int a[],int root,int len)
{
int lchild = root*2+1;
if(lchild<len)
{
int flag = lchild;//flag保存的是根节点的左右节点最大值的下标
int rchild = lchild+1;//根节点的右子节点下标
if(rchild<len)
{
if(a[rchild]>a[flag])//找出左右子节点的最大值
{
flag = rchild;
}
}
if(a[root]<a[flag])
{
swap(a[root],a[flag]);
Heap_build(a,flag,len); //不断更改根节点的位置。
}
}
}
void Heap_sort(int a[],int len)
{
for(int i = len/2;i>=0;i--)//第一遍建堆
{
Heap_build(a,i,len);
}
for(int j = len-1;j>=0;j--)
{
swap(a[0],a[j]);//交换那两个元素
Heap_build(a,0,j); //继续堆排序,不过,排除已经建好堆的数组
}
}
int main()
{
clock_t Start_time = clock();
int a[10] = {12,45,748,12,56,3,89,4,48,2};
Heap_sort(a,10);
for(int j = 0;j<10;j++)
{
cout<<a[j]<<" ";
}
clock_t end_time = clock();
cout<<endl;
cout<<"Total_Running Time"<<static_cast<double>(end_time-Start_time)/CLOCKS_PER_SEC*1000<<" ms"<<endl;
return 0;
}
7、归并排序:
答案
采用分治思想,现将序列分为一个个子序列,对子序列进行排序合并,直至整个序列有序。
稳定性:稳定
平均时间复杂度:O(nlogn)
code
答案
class Solution {
public:
vector<int> sortArray(vector<int>& nums) {//归并排序
int left=0;
int right=nums.size()-1;
MergeSort(nums,left,right);
return nums;
}
void MergeSort(vector<int>&nums,int left,int right)
{
if(left<right)//只要left<right,最终情况是left=right,即数组长度为1,单独一个数,肯定是有序的
{
int mid=(left+right)/2;//取中点
MergeSort(nums,left,mid);//左边块递归排序
MergeSort(nums,mid+1,right);
Merge(nums,left,mid,mid+1,right);//左右块合并
}
}
void Merge(vector<int>&nums,int L1,int R1,int L2,int R2)//L1,R1是第一块的左右索引,L2R2同理,将两个块合并
{
int temp[R2-L1+1];//存放合并后的有序数组(这里没用vector,用了会提示内存不足)
int i=L1;
int j=L2;
int k=0;
while(i<=R1 && j<=R2){
if(nums[i]<nums[j])
{
temp[k++]=nums[i++];
}
else
{
temp[k++]=nums[j++];
}
}//while结束之后若有某块没遍历完(另一块肯定已经遍历完),剩下的数直接赋值
while(i<=R1) temp[k++]=nums[i++];
while(j<=R2) temp[k++]=nums[j++];
for(int i=0;i<k;i++)//合并后的数赋值回原来的数组
nums[L1+i]=temp[i];
}
};
8、计数排序:
答案
思想:如果比元素x小的元素个数有n个,则元素x排序后位置为n+1。
步骤:
1)找出待排序的数组中最大的元素;
2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
稳定性:稳定
时间复杂度:O(n+k),k是待排序数的范围。
9、桶排序:
答案
步骤:
1)设置一个定量的数组当作空桶子; 常见的排序算法及其复杂度:
2)寻访序列,并且把记录一个一个放到对应的桶子去;
3)对每个不是空的桶子进行排序。
4)从不是空的桶子里把项目再放回原来的序列中。
时间复杂度:O(n+C) ,C为桶内排序时间。
桶排序
//radixSort 按位数进行排序,借助桶bucket进行分配与收集
public void radixSort(int[] arr){
int max = 0;
for (int i : arr) {
if(i>max) max = i;
}
int count = (max+"").length();
for (int i = 1; i <= count; i++) {
//分配
int[][] bucket = new int[10][arr.length];
//bucketCount用于统计该桶中元素的数量
int[] bucketCount = new int[10];
for (int value : arr) {
bucket[value % (10 * i)][bucketCount[value % (10 * i)]++] = value;
}
//收集
int k = 0;
for (int j = 0; j < 10; j++) {
//如果桶中有数据,放入数组
if(bucketCount[j]!=0) {
//循环该桶,取出元素到arr中,每取一个元素,桶中元素-1
while (bucketCount[j]!=0) arr[k++] = bucket[j][--bucketCount[j]];
}
}
}
}
29.1 快排(算一下快排复杂度,计算过程)
答案
**快排的思想:**首先,快排是选出一个基准元素,一般选择第一个元素。然后,通过一趟排序,将数组分为两个部分,一部分比该元素小,一部分比该元素大。然后,再按此方法对这两部分分别进行递归。
快速排序算法的时间复杂度为O(nlogn)
答案
int once_quick_sort(vector<int>& data, int left, int right)
{
int key = data[left];
while (left < right)
{
while (left < right && key <= data[right])
{
right--;
}
if (left < right)
{
data[left] = data[right];
left++;
}
while (left < right && key > data[left])
{
left++;
}
if (left < right)
{
data[right] = data[left];
right--;
}
}
data[left] = key;
return left;
}
int quick_sort(vector<int>& data, int left, int right)
{
if (left >= right)
{
return 1;
}
int middle = 0;
middle = once_quick_sort(data, left, right);
quick_sort(data, left, middle - 1);
quick_sort(data, middle + 1, right);
}
快排的优化方式
答案
1. 选择基准的方式
若每次划分都能划分成**等长的两个序列**,那么分治效率将会达到最大。下面介绍三种基准的选取方式
a. 取序列的第一个或最后一个
**这种效率很不好,若数组原本就是有序的,则会导致算法退化成为O(n^2)**
b. 随机选择基准
**可以达到O(Nlogn)**
c. 最佳的是选取序列的中间的值,但这很难得到,所以我们一般选取头,尾,中三数 的中值作为枢纽元。
2. 其他优化方式:
a. 待排序序列的长度分割到一定大小后,使用插入排序.
b. 在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割.
c. 优化递归操作:快排函数在函数尾部有两次递归操作,我们可以对其使用尾递归优化。
**最好的方式是:三数取中+插排+聚集相等元素,它和STL中的Sort函数效率差不多**
尾递归
答案
1. 什么是尾递归?
如果一个函数中所有递归形式的调用都出现在函数的末端,我们称这个递归函数是尾递归。
2. 尾递归和一般的递归不同在对内存的占用,普通递归创建stack累积而后计算收缩,尾递归只会占用恒量的内存(和迭代一样)。
def recsum(x):
if x == 1:
return x
else:
return x + recsum(x - 1)
尾调用的概念非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。尾调用不一定出现在函数尾部,只要是最后一步操作即可。
3. 尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码
29.2 堆排(算一下复杂度)
答案
**堆排的思想**:利用堆进行排序的思想,将待排序的序列构成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点,再将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构建成一个大顶堆,这样就是得到这n个元素序列的次小值,如此反复进行,便能得到一个有序序列。
堆排序的时间复杂度为O(n*log(n)), 非稳定排序,原地排序(空间复杂度O(1))。
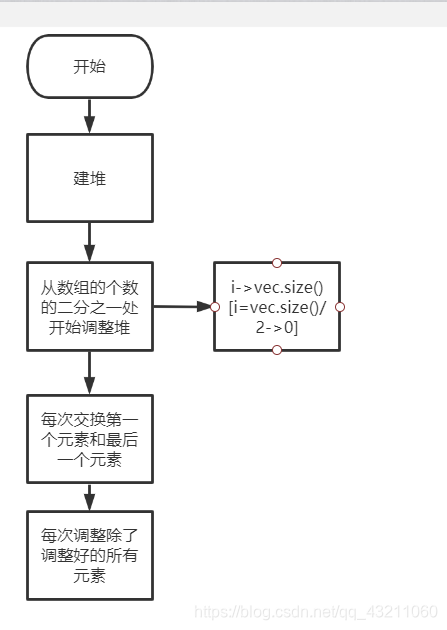
code
答案
#include <cstdio>
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
void adjust(int arr[],int len,int index)
{
int left = 2*index+1;
int right = 2*index+2;
int maxIdx = index;
if(left<len&&arr[left]>arr[maxIdx])
maxIdx = left;
if(right<len&&arr[right]>arr[maxIdx])
maxIdx = right;
if(maxIdx!=index)
{
swap(arr[maxIdx],arr[index]);
adjust(arr,len,maxIdx);//这个是递归调整这个节点下面的所有节点进行排序
}
}
void heapSort(int arr[],int size)
{
for(int i = size/2;i>=0;i++)
adjust(arr,size,i);
for()
}
int main()
{
int array[8] = {8,1,14,3,21,5,7,10};
heapSort(array,8);
for(auto it:array)
{
cout<<it<<endl;
}
return 0;
}
29.3 sort采用的是什么排序?
答案
答案: 用到了快速排序还结合 了插入排序和堆排序。
sort算法逻辑: 数据量大时采用快排,分段归并排序。分段后的数据小于某个门槛,为避免快排的递归调用带来过大的额外负荷,就改用Inserttion Sort插入排序。如果递归层次过深,还会改用堆排。
1. 快速排序递归实现时,怎么解决递归层次过深的问题?
预防堆栈溢出的方法:
(1)避免层次过深的递归调用;
(2)不要使用过多的局部变量,控制局部变量的大小;
(3)避免分配占用空间太大的对象,并及时释放;
(4)实在不行,适当的情景下调用系统API修改线程的堆栈大小;
2. 快速排序的优化
1)中枢值的选取。这个很显然,如果每次都选中实际大小中中间的那个值,那么就能达到最优的排序效果,避免最坏的情况的;
(2)划分的最小数列长度。因为快速排序是对子序列不停递归的一个过程(分治法)。所以如果递归的过多,堆栈带来的性能损失也是不容小视的。还有最重要的一点就是在数据量很小的情况下,插入排序在时间上的性能要比快速排序的性能要好,所以当子序列长度小于某阈值时,调整为插入排序;
(3)对是否交换做标记,如果全过程没有发生交换,直接返回就可以了;
(4)栈的深度。要优先对小的数组进行排序,这样可以减少递归调用栈的深度。
(5) 非递归的方式来实现快速排序或者去掉尾递归也是另外一种思路的优化
31. 二叉树的遍历(前序,中序,后序,递归+迭代 )
31.1 前序遍历
31_1_1. 前序遍历(递归)
答案
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL)
return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
31_1_2.前序遍历(迭代)
code
答案
vector<int> preorder(TreeNode* root)
{
vector<int> res;
if(root==NULL)
return res;
stack<TreeNode*> st;
st.push(root);
while(!st.empty())
{
TreeNode* node = st.top();
res.push(node);
st.pop();
if(node->right)
st.push(node->right);
if(node->left)
st.push(node.left);
}
return result;
}
31.2 中序遍历
31_2_1. 中序遍历递归
递归
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
vec.push_back(cur->val); // 中
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
31_2_2.中序遍历迭代
答案
/* 注意中序遍历的非递归是借助了栈的方式进行遍历的,并且,规则是: 先往左边走,走到最底下,最左下没东西了,开始出栈的元素,然后,往右边走。*/
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur!=NULL||!st.empty())
{
if(cur!=NULL)//将入栈和出栈动作分开
{
st.push(cur);//这里才是第一次入栈,外面未入栈
cur = cur->left;//左
}
else//这个是出栈的动作
{
cur = st.top();
st.pop();
result.push_back(cur->val);//中
cur = cur->right;//右
}
}
return result;
}
};
31.3 后序遍历
31.3.1 后序遍历递归
答案
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
vec.push_back(cur->val); // 中
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
31.3.2 后序遍历迭代
答案
/*如栈就按照头右左,刚好出来的顺序就是左右头。这样就是后序遍历的顺序了。*/
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> res;
if(root==nullptr)
return res;
stack<TreeNode*> st;
st.push(root);
while(!st.empty())
{
TreeNode* node = st.top();
res.push_back(node->val);
st.pop();
if(node->left)
st.push(node->left);
if(node->right)
st.push(node->right);
}
reverse(res.begin(),res.end());
return res;
}
};
32. 红黑树
答案
1)什么是红黑树?
它是一种特殊的二叉查找树,红黑树的每个节点都有存储位表示节点的颜色,可以是红(red)也可以是黑(black).
其实平衡二叉树最大的作用就是查找,**AVL树的查找、插入和删除在平均和最坏情况下都是O(logn)**。AVL树的效率就是高在这个地方。如果在AVL树中插入或删除节点后,使得高度之差大于1。此时,AVL树的平衡状态就被破坏,它就不再是一棵二叉树;为了让它重新维持在一个平衡状态,就需要对其进行旋转处理, 那么创建一颗平衡二叉树的成本其实不小. 这个时候就有人开始思考,并且提出了红黑树的理论,那么红黑树到底比AVL树好在哪里?
32.1 红黑树与AVL树的比较:
答案
1. AVL树的时间复杂度虽然优于红黑树,但是对于现在的计算机,cpu太快,可以忽略性能差异
2. 红黑树的插入删除比AVL树更便于控制操作
3. 红黑树整体性能略优于AVL树(红黑树旋转情况少于AVL树)
4. AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
5. 红黑树插入,删除,查找的时间复杂度都为 O(logn)
32.2 红黑树特性。
答案
红黑树是一棵二叉搜索树,它在每个节点增加了一个存储位,用来记录节点的颜色,可以是红色,也可以是黑色。通过任意一条从根到叶子简单路径上颜色的约束。红黑树可以保证最长路径不超过最短路径的两倍。近似平衡。
具体性质如下:
1. 每个节点颜色不是黑色就是红色。
2. 根节点是黑色。
3. 叶节点也是黑色。
4. 若某节点是红色,那其子节点一定是黑色。
5. 对于每个节点,从该节点到其后代叶节点的简单路径上。均包含相同数目的黑色节点。这个属性很重要这个,保证了上面的最长路径不超过最短路径的两倍的这个特性。
32.3 红黑树查找速度。
答案
红黑树是一种二叉查找树。可以在O(log n)时间内做查找,插入和删除。这里的n 是树中元素的数目。恢复红黑属性需要少量(O(log n))的颜色变更(这在实践中是非常快速的)并且不超过三次树旋转(对于插入是两次)。这允许插入和删除保持为 O(log n) 次,
32.4 红黑树的插入
答案
**红黑树插入节点过程大致分析:**
RBTree为二叉搜索树,我们按照二叉搜索树的方法对其进行节点插入
RBTree有颜色约束性质,因此我们在插入新节点之后要进行颜色调整
**具体步骤如下:**
1.根节点为NULL,直接插入新节点并将其颜色置为黑色
2. 根节点不为NULL,找到要插入新节点的位置
3.插入新节点
3. 判断新插入节点对全树颜色的影响,更新调整颜色
由于插入黑色节点的成本太高,所以,我们选择节点的颜色为红色。但若上一个节点也是红色的话,我们就需要依据情况进行调整 了。
32.5 红黑树与B+树的比较?(B树与B+树的介绍)
1. 简介
答案
我们在MySQL中的数据一般是放在磁盘中的,读取数据的时候肯定会有访问磁盘的操作,磁盘中有两个机械运动的部分,分别是盘片旋转和磁臂移动。盘片旋转就是我们市面上所提到的多少转每分钟,而磁盘移动则是在盘片旋转到指定位置以后,移动磁臂后开始进行数据的读写。那么这就存在一个定位到磁盘中的块的过程,而定位是磁盘的存取中花费时间比较大的一块,毕竟机械运动花费的时候要远远大于电子运动的时间。当大规模数据存储到磁盘中的时候,显然定位是一个非常花费时间的过程,但是我们可以通过B树进行优化,提高磁盘读取时定位的效率。
为什么B类树可以进行优化呢?我们可以根据B类树的特点,构造一个多阶的B类树,然后在尽量多的在结点上存储相关的信息,保证层数尽量的少,以便后面我们可以更快的找到信息,磁盘的I/O操作也少一些,而且B类树是平衡树,每个结点到叶子结点的高度都是相同,这也保证了每个查询是稳定的。
总的来说,B/B+树是为了磁盘或其它存储设备而设计的一种平衡多路查找树(相对于二叉,B树每个内节点有多个分支),与红黑树相比,在相同的的节点的情况下,一颗B/B+树的高度远远小于红黑树的高度(在下面B/B+树的性能分析中会提到)。B/B+树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成,而CPU的速度非常快,所以B树的操作效率取决于访问磁盘的次数,关键字总数相同的情况下B树的高度越小,磁盘I/O所花的时间越少。
B树是为了提高**磁盘或外部存储设备查找效率**而设计的一种多路平衡二叉树。B+树为B树的变形结构,用于大多数数据库或文件系统的存储而设计的。
2. B树的定义:
答案
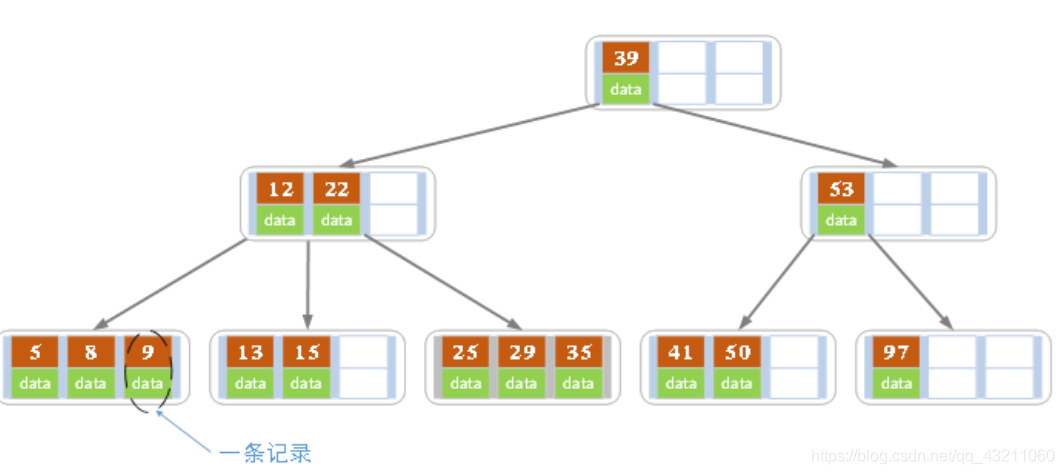
B树也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
一棵m阶的二叉树的定义如下:
a. 每个节点最多有m-1个关键字。
b. 根节点最少可以只有一个关键字。
c. 非根节点至少有math.ceil(m/2)-1个关键字。
d. 每个节点的关键字都按照从小到大的顺序排列,每个关键字的左子树都小于它。而右子树的所有关键字都大于它。
e. 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同。
3. B+树的定义
所谓B+树,就是关键字的个数比孩子节点个数小1.
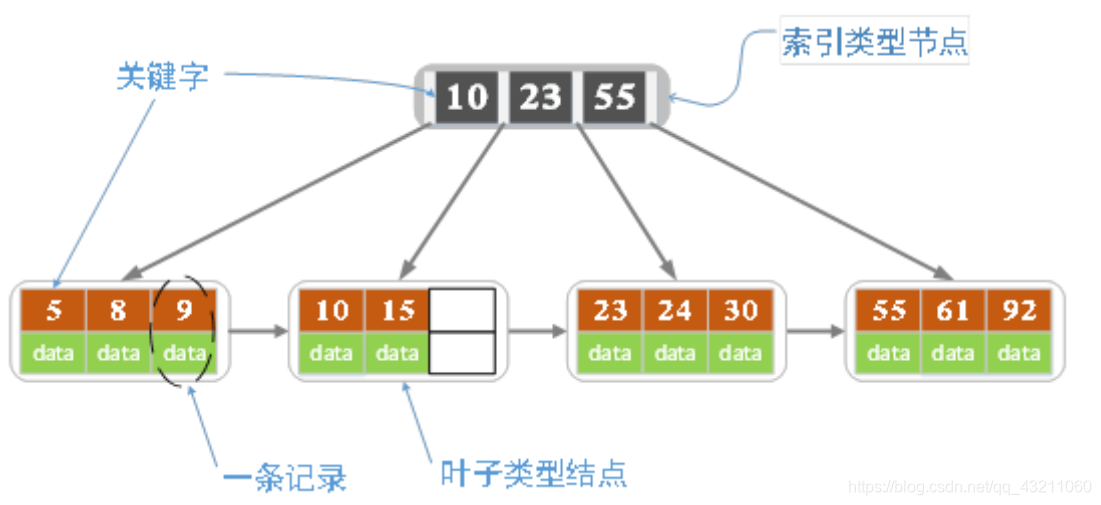
4. B+树的其他要求:
答案
a. B+树包含两种类型的节点:内部节点(索引节点)和叶子节点。根节点本身即可以是内部节点,也可以是叶子节点。根节点的关键字的个数最少可以只有一个。
b. **B+树与B树的不同点在于内部节点不保存数据,只用于索引,所有数据都保存在叶子节点中。**
c. m阶B+树表示了内部结点最多有m-1个关键字(但孩子节点的个数就可以是m)。阶数m同时限制了叶子节点最多存储m-1个记录。
d. 内部结点中的key都要按照从小到大的顺序排列,对于内部结点中的一个key,左树中所有的key都小于它,右树结点的key都大于它。
e.每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
5. B树的缺点(为何要用B+数在数据库的查找上应用)
答案
1.每个节点中既要存索引信息,又要存其对应的数据,如果数据很大,那么当**树的体量很大**时,每次读到内存中的树的信息就会不太够。
2.B树遍历整个树的过程和二叉树本质上是一样的,B树相对二叉树虽然提高了磁盘IO性能,但并没有解决**遍历元素效率**低下的问题。
6.B树和B+树的区别:
答案
1. B+树中只有叶子节点会带有指向记录的指针,而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。
2. B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
7.B+树的优点
答案
1. 非叶子节点不会带上指向记录的指针,这样,一个块中可以容纳更多的索引项,一是可以降低树的高度。二是一个内部节点可以定位更多的叶子节点。**B+树的磁盘读写代价更低。**
2. 叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。具体的来讲,如何想扫描一次所有数据,对于b+树来说,可以从因为他们的叶子结点是连在一起的,所以可以横向的遍历过去。而对于b-树来说,就这能中序遍历了。**B+树的数据信息遍历更加方便**。
3. **B+树的查询效率更加稳定。**
8. B树相对于红黑树的区别:
答案
B树相对于红黑树的差别在大规模 数据存储的时候,红黑树往往由于**深度过大而造成磁盘IO读写过于频繁**,进而导致效率低下的情况。
因为我们知道磁盘IO的代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。所以,根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的高度,B树可以有多个子女,从几十到上千,降低树的高度
9.红黑树 和 b+树的用途有什么区别?
答案
红黑树多用在内部排序,即全放在内存中的,STL的map和set的内部实现就是红黑树。
B+树多用于外存上时,B+也被变成一个磁盘友好的数据结构。
10. B/B+树性能分析
答案
n个节点的平衡二叉树的高度为H(即logn),而n个节点的B/B+树的高度为logt((n+1)/2)+1;
若要作为内存中的查找表,B树却不一定比平衡二叉树好,尤其当m较大时更是如此。因为查找操作CPU的时间在B-树上是O(mlogtn)=O(lgn(m/lgt)),而m/lgt>1;所以m较大时O(mlogtn)比平衡二叉树的操作时间大得多。因此在内存中使用B树必须取较小的m。(通常取最小值m=3,此时B-树中每个内部结点可以有2或3个孩子,这种3阶的B-树称为2-3树)。
11. 为什么说B+树比B树更适合数据库索引?
答案
1. **B+树的磁盘读写代价更低**:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2. **B+树的查询效率更加稳定**:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3. **区间查询更加快速**:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
4. **总结**:他们认为数据库索引采用B+树的主要原因是:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
参考
32.6 红黑树的应用
答案
1. C++的STL中,map与set都是用红黑树实现的。
2. 著名的Linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
3. IO多路复用epoll的实现采用红黑树组织管理sockfd(文件描述符),以支持快速的增删改查.
4. Nginx中用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
5. Java中TreeMap的实现;
32.7 mysql中为何要使用B+树?
答案
1. 索引在mysql数据库中分三类:B+树索引,Hash索引,全文索引。
2. 由于内存的易失性,我们将表的数据和索引保存在磁盘这种外围设备中。而磁盘读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。
3. 为解决平衡二叉树的弊端,我们寻找一种单个节点可以存储多个键值和数据的平衡树。
4. 而B+树种中的非叶子节点是不存储数据的,仅存储键值。之所以这样做是因为在数据库中页的大小是固定的,innodb中页的默认大小是16KB.如果不存储数据,那么就会存储更多的键值,相应的树的阶数就会更大,树就会更矮更胖。这样一来,我们查找数据进行磁盘的IO次数就会再次减少,数据查询的效率也会更高。
5. B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,那么B+树的查找就会变得非常简答。
50.vector的底层工作原理
答案
vector采用简单的**线性连续空间**。以两个迭代器start和end分别指向头尾,并以迭代器end_of_storage指向容量尾端。容量可能比(尾-头)还大,多余即备用空间。
50.1. vector存储的元素为结构体时的注意事项
答案
1. 结构体要是全局变量
2. 结构体内部要重载比较运算符
51. map与unordered_map优点和缺点
答案
**对于map,其底层是基于红黑树实现的,优点如下:**
1)有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作。
2)map的查找、删除、增加等一系列操作时间复杂度稳定,都为O(logN)
**缺点如下:**
1)查找、删除、增加等操作平均时间复杂度较慢,与n相关.
2)空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
**对于unordered_map来说,其底层是一个哈希表,优点如下:**
查找、删除、添加的速度快,时间复杂度为常数级O(c)
缺点如下:
因为unordered_map内部基于哈希表,以(key,value)对的形式存储,因此空间占用率高
Unordered_map的查找、删除、添加的时间复杂度不稳定,平均为O(c),取决于哈希函数。极端情况下可能为O(n).时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。
总结:
1. 内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
2. 但是unordered_map执行效率要比map高很多
3. 对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的
51.1 何时使用map,何时使用HashMap?
答案
1. 删除和插入操作较多的情况下,map比hash_map的性能更好,添加和删除的数据量越大越明显。
2. map的遍历性能高于hash_map,而查找性能则相反,hash_map比map要好,数据量越大查找次数越多,表现就越好。
**总结**:hash_map 查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n)小, hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑hash_map。但若你对内存使用特别严格,希望 程序尽可能少消耗内存,那么一定要小心,hash_map可能会让你陷入尴尬,特别是当你的hash_map对象特别多时,你就更无法控制了,而且 hash_map的构造速度较慢。
权衡三个因素: 查找速度, 数据量, 内存使用
51.2 map中的key如果是结构体应该注意什么?
答案
1. 注意,map中的元素要是有序的,如果只是单纯结构体的元素的话,那么程序是会出错的。
2. 在结构体中要对比较符号进行重定义。比如:
struct Info
{
string name;
int score;
bool operator< (const Info &x) const
{
return score < x.score;
}
};
只有这样,才能对map进行存值。归根到底原因就是map的底层原理是红黑树,人家是有序的,不能让你随随便便就往里面放值。
52.2 hash与map的区别
答案
1. **存储结构**:hash:哈希表,map:红黑树。
2. **查找速度**:hash_map 查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。
52. 对哈希函数的理解
答案
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
**定义**:哈希函数能够将固定长度的输入值,转变成固定程度的值输出,该值成为散列值。
**特点**:
1. Hash的主要原理就是把大范围映射到小范围;所以,你输入的实际值的个数必须和小范围相当或者比它更小。不然冲突就会很多。
2. 由于Hash逼近单向函数;所以,你可以用它来对数据进行加密。
3. 不同的应用对Hash函数有着不同的要求;比如,用于加密的Hash函数主要考虑它和单项函数的差距,而用于查找的Hash函数主要考虑它映射到小范围的冲突率。
52.1 一致性哈希算法的理解
一致性哈希算法,就是在移除或增加一个节点的时候,能够尽可能小的改变已存在key的映射关系。
答案
1. 平衡性:平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
2. 单调性:单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3. 分散性:分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。
4. 负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
53. 如何实现栈?
53.1 如何用队列实现栈?
其实就是两个队列就可以了。
54. Vector,ArrayList 与LinkedList 的区别
答案
Vector 是 Java 早期提供的线程安全的动态数组,如果不需要线程安全,并不建议选择,同步有额外开销,Vector 内部是使用对象数组保存数据,也可以根据需要自动增加容量,当数组已满时,会创建新的数组,并拷贝原数组数据。
ArrayList 是应用更广泛的动态数组,本身不是线程安全的,与 Vector 相似, ArrayList 也是可以根据需要调整容量,不过两者间的调整有区别,Vector 在扩容时提高一倍, ArrayList 则是增加 50%。
LinkedList 是 Java 提供的双向链表,所有它不需要调整容量,它也不是线程安全的。
Vector、 ArrayList、 LinkedList均为线型的数据结构,但是从实现方式与应用场景中又存在差别,可以从下面几个方面总结。
**底层实现方式**
ArrayList内部用数组来实现; LinkedList内部采用双向链表实现; Vector内部用数组实现。
**读写机制**
ArrayList在执行插入元素是超过当前数组预定义的最大值时,数组需要扩容,扩容过程需要调用底层System.arraycopy()方法进行大量的数组复制操作;在删除元素时并不会减少数组的容量 (如果需要缩小数组容量,可以调用trimToSize()方法);在查找元素时要遍历数组,对于非null的元素采取equals的方式寻找。
LinkedList在插入元素时,须创建一个新的Entry对象,并更新相应元素的前后元素的引用;在查找元素时,需遍历链表;在删除元素时,要遍历链表,找到要删除的元素,然后从链表上将此元 素删除即可。
Vector与ArrayList仅在插入元素时容量**扩充机制不一致**。对于Vector,默认创建一个大小为10的Object数组,并将capacityIncrement设置为0;当插入元素数组大小不够时,如 果capacityIncrement大于0,则将Object数组的大小扩大为现有size+capacityIncrement;如果capacityIncrement<=0,则将Object数组的大小扩大为现有大小的2倍。
**读写效率**
ArrayList对元素的增加和删除都会引起数组的内存分配空间动态发生变化。因此,对其进行插入和删除速度较慢,但检索速度很快。
LinkedList由于基于链表方式存放数据,增加和删除元素的速度较快,但是检索速度较慢。
**线程安全性**
ArrayList、 LinkedList为非线程安全;
Vector是基于synchronized实现的线程安全的ArrayList。
单线程应尽量使用ArrayList, Vector因为同步会有性能损耗;即使在多线程环境下,我们可以利用Collections这个类中为我们提供的synchronizedList(List list)方法返回一个 线程安全的同步列表对象。
vector:线程安全,自动增加容量
ArrayList:非线程安全,扩容增加不一致
LinkedList:双向链表
55.解析c++中函数重载的实现原理
倾轧技术
答案
C++函数重载底层实现原理是C++利用倾轧技术,来改名函数名,区分参数不同的同名函数。
**函数倾轧**: 同名不同参函数(重载函数),C++底层如何区分他们,那就是对函数改名,也就是中文翻译的“倾轧”(苦涩难懂的词),改名也是有规律的,不是随便命名,具体参见下面:
**重载的映射机制:作用域+返回类型+函数名+参数列表**
56. const 和 define的区别
编译器、存储方式、类型和安全检查、定义域、数据拷贝
答案
1. **编译器处理不同**宏定义是一个“编译时”概念,在预处理阶段展开,不能对宏定义进行调试,生命周期结束于编译时期。
const变量是一个运行时概念,在程序运行时使用,类似于一个只读行数据。
2. **存储方式不同**:宏定义是直接替换,不会分配内存。const变量是按内存分配。
3. **类型和安全检查不同**
宏定义是字符替换,没有数据类型的区别,同时这种替换没有类型安全检查,可能产生边际效应等错误;
const常量是常量的声明,有类型区别,需要在编译阶段进行类型检查。
4. **定义域不同**
5. **数据拷贝个数**:const定义常量从汇编的角度来看,只是给出 没有了存储与读内存的操作,使得它的效率也很高。
6. "占用的空间不同**:define预处理后,占用代码段空间,const
60. C++11的新特性
答案
1. **auto 关键字**:编译器可以根据初始值自动推导出类型。但是不能用于函数传参以及数组类型的推导。原理使用的是:模板实参推导机制。
2. **decltype关键字**:选择并返回操作数的数据类型。在这,编译器只是分析表达式的数据类型,并不实际计算其表达式。使用在当你指向获取这个表达式的返回值,而不想计算这个表达式时使用。
int func() {return 0}; decltype(func()) sum = 5;
3. **nullptr:**是一种特殊类型的字面值,它可以被转换成任意其他的指针类型。而NULL一般被宏定义为0,在遇到函数重载的时候可能会遇到问题。在C++11中,用nullptr替换了NULL.
4. **智能指针**:C++11新增了std::shared_ptr,std::weaked_ptr等类型的智能指针,用于解决内存管理的问题。
可变参数模板:对参数进行了高度泛化,可以表示任意数目、任意类型的参数,其语法为:在class或typename后面带上省略号”。
5. **右值引用:**

答案
6. **lambda表达式:**利用Lambda表达式,可以方便的定义和创建匿名函数。
Lambda表达式完整的声明格式如下:
[capture list] (params list) mutable exception-> return type { function body }
各项具体含义如下:
>1. capture list:捕获外部变量列表
>2. params list:形参列表
>3. mutable指示符:用来说用是否可以修改捕获的变量
>4. exception:异常设定
>5. return type:返回类型
>6. function body:函数体
**Lambda表达式的使用场景**:
7. 在某个小函数是可以独立出来的时候,并且,在整个工程中只会使用一次的话。那么这个时候我们就考虑使用下Lambda表达式。
8. 省略取函数名字这个麻烦的操作。
9. 可以将Lambda表达式认为是匿名内联函数。
sort(lbvec.begin(), lbvec.end(), [](int a, int b) -> bool { return a < b; });

60.1 智能指针
60.1_1 智能指针的作用
答案
**说法一**:C++程序设计中使用堆内存是非常频繁的操作,堆内存的申请和释放都由程序员自己管理。程序员自己管理堆内存可以提高了程序的效率,但是整体来说堆内存的管理是麻烦的,C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。**自动释放**
**说法二**:智能指针的作用就是为了保证在使用堆上对象时,对象一定会被释放,但只能释放一次,并且释放后指向该对象的指针应该马上归0.
60.1_2 智能指针的理解
答案
1. 从较浅的层面看,智能指针是利用了一种叫做RAII(资源获取即初始化)的技术对普通的指针进行封装,这使得智能指针实质是一个对象,行为表现的却像一个指针。
2. 智能指针的作用是防止忘记调用delete释放内存和程序异常的进入catch块忘记释放内存。另外指针的释放时机也是非常有考究的,多次释放同一个指针会造成程序崩溃,这些都可以通过智能指针来解决。
3. 智能指针还有一个作用是把值语义转换成引用语义。C++和Java有一处最大的区别在于语义不同,在Java里面下列代码:
Animal a = new Animal();
Animal b = a;
你当然知道,这里其实只生成了一个对象,a和b仅仅是把持对象的引用而已。但在C++中不是这样,
Animal a;
Animal b = a;
这里却是就是生成了两个对象。
聊一聊RAII原理
RAII(Resource Acquisition Is Initialization):使用局部对象来管理资源的技术称为资源获取即初始化。
1. RAII的步骤:
a.设计一个类封装资源。
b. 在构造函数中初始化。
c. 在析构函数中执行销毁操作。
d. 使用时声明一个该对象的类。
60.1_3 智能指针的使用
一、auto_ptr
答案
1. **缺点**:当发生对象拷贝 ,或者赋值时,他会悬空前者(即,释放掉了前者的资源)。
2. **作用**:主要是为了解决“有异常抛出时发生内存泄漏的问题”,抛出异常,将导致指针p所指向的空间得不到释放而导致内存泄漏。
3. 由于auto_ptr对象析构时会删除它所拥有的指针,所以使用时避免多个auto_ptr对象管理同一个指针。
4. Auto_ptr内部实现,析构函数中删除对象用的是delete而不是delete[],所以auto_ptr不能管理数组;
5. auto_ptr支持所拥有的指针类型之间的隐式类型转换。
6. 可以通过*和->运算符对auto_ptr所有用的指针进行提领操作;
7. T* get(),获得auto_ptr所拥有的指针;T* release(),释放auto_ptr的所有权,并将所有用的指针返回。
二、shared_ptr
- 简要介绍
答案
1. shared_ptr多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。
2. std::shared_ptr确定最后一个引用它的对象何时被释放的基本想法是:对被管理的资源进行引用计数,当一个shared_ptr对象要共享这个资源的时候,该资源的引用计数加1,当这个对象生命期结束的时候,再把该引用技术减少1。这样当最后一个引用它的对象被释放的时候,资源的引用计数减少到0,此时释放该资源。
3. 初始化。智能指针是个模板类,可以指定类型,传入指针通过构造函数初始化。也可以使用make_shared函数初始化。不能将指针直接赋值给一个智能指针,一个是类,一个是指针。例如std::shared_ptr<int> p4 = new int(1);的写法是错误的。
4. 拷贝和赋值。拷贝使得对象的引用计数增加1,赋值使得原对象引用计数减1,当计数为0时,自动释放内存。后来指向的对象引用计数加1,指向后来的对象。
5. get函数获取原始指针。注意不要用一个原始指针初始化多个shared_ptr,否则会造成二次释放同一内存,注意避免循环引用,shared_ptr的一个最大的陷阱是循环引用,循环,循环引用会导致堆内存无法正确释放,导致内存泄漏。循环引用在weak_ptr中介绍。
- shared_ptr的初始化
答案
//初始化方式1
std::shared_ptr<int> sp1(new int(123));
//初始化方式2
std::shared_ptr<int> sp2;
sp2.reset(new int(123));
//初始化方式3
std::shared_ptr<int> sp3;
sp3 = std::make_shared<int>(123);
三、weak_ptr
为了解决shared_ptr相互引用的问题,导致资源无法释放的问题。
- weak_ptr的特点:
答案
1) 一个对象被多个shared_ptr类所指向时,就会拥有多个引用计数,但是当weak_ptr指向一个shared_ptr类所指向的对象时,该对象的引用计数不会增加.
2) 因此,当最后一个对象的最后一个shared_ptr类被释放时,该对象会被释放。即使此时仍有weak_ptr指向该对象,该对象的内存仍然会被释放
3) 标准库提供了weak_ptr,允许“共享但不拥有”某对象。
一旦最后一个对象释放掉以后,所有的weak pointer都将为空,因此,除了默认和复制构造函数之外,weak_ptr只提供接受一个shared_ptr的构造函数。
4) weak_ptr虽然是一个模板类,但是不能用来直接定义指向原始指针的对象。
5)weak_ptr接受shared_ptr类型的变量赋值,但是反过来是行不通的,需要使用lock函数。
6) 由于不知道什么之后weak_ptr所指向的对象就会被析构掉,所以使用之前请先使用expired函数检测一下。
- 如何使用weak_ptr
我们需要使用一个shared_ptr类来初始化weak_ptr类
答案
auto p=make_shared<int>(42); //初始化一个shared_ptr对象
weak_ptr<int> wp(p); //用p初始化wp,wp弱共享p
//wp只是指向p所指的对象,p的引用计数没有改变,并且p所指对象的释放也与wp无关
- weak_ptr的源码实现
weak_ptr的源码实现
- 解决循环引用的示例
答案
#include <iostream>
#include <stdio.h>
#include <string>
using namespace std;
class B;
class A
{
public:
A()
{
cout << "---->A" << endl;
}
~A()
{
cout << "--->~A" << endl;
}
shared_ptr<B> m_Aptr;
};
class B
{
public:
B()
{
cout << "--->B" << endl;
}
~B()
{
cout << "--->~B"<< endl;
}
weak_ptr<A> m_Bptr;
};
int main()
{
shared_ptr<B> p1(new B());
shared_ptr<A> p2(new A());
p1->m_Bptr = p2;
p2->m_Aptr = p1;
cout << p1.use_count() << endl;
cout << p2.use_count() << endl;
return 0;
}
四、unique_ptr
答案
强调一个资源只能被一个智能指针所引用。
1. 简单介绍一下unique_ptr指针
unique_ptr指针是一个原生指针独一无二的拥有者和管理者,当一个unique离开其作用域时,其管理的原生指针会被自动销毁。
2. 源码分析
1).
// file: <memory>
template<class _Tp, class _Dp = default_delete<_Tp> >
class unique_ptr {
public:
typedef _Tp element_type;
typedef _Dp deleter_type;
typedef typename __pointer_type<_Tp, deleter_type>::type pointer;
private:
__compressed_pair<pointer, deleter_type> __ptr_;
// ...
};
unique_ptr的声明包含两个模板参数,第一个参数_Tp显然就是原生指针的类型。第二个模板参数_Dp是一个deleter(deleter其实就是一个自定义的匿名函数)
五、shared_ptr和weak_ptr的使用
答案
1. couter的计数器类
class Counter
{
public:
Counter():sCount(0),wCount(0){};
int sCount;//s
int wCount;
}
2. 简单实现以下shared_ptr
template<class T> class WeakPtr;//为了用weak_ptr的lock (),来生成shared_ptr用
template<class T>
class SharedPtr
{
public:
SharePtr(T* p=0)
:_ptr(p){
cnt=new Counter();
if(p)
cnt->s=1;
cout<<"in construct "<<cnt->s<<endl;
}
~SharePtr()
{
release();
}
SharePtr(SharePtr<T> const &s)
{
cout<<"in copy con"<<endl;
_ptr=s._ptr;
(s.cnt)->s++;
cout<<"copy construct"<<(s.cnt)->s<<endl;
cnt=s.cnt;
}
SharePtr(WeakPtr<T> const &w)//为了用weak_ptr的lock(),来生成share_ptr用,需要拷贝构造用
{
cout<<"in w copy con "<<endl;
_ptr=w._ptr;
(w.cnt)->s++;
cout<<"copy w construct"<<(w.cnt)->s<<endl;
cnt=w.cnt;
}
SharePtr<T>& operator=(SharePtr<T> &s)
{
if(this != &s)
{
release();
(s.cnt)->s++;
cout<<"assign construct "<<(s.cnt)->s<<endl;
cnt=s.cnt;
_ptr=s._ptr;
}
return *this;
}
T& operator *()
{
return *_ptr;
}
T* operator ->()
{
return _ptr;
}
friend class WeakPtr<T>; //方便weak_ptr与share_ptr设置引用计数和赋值。
private:
void release()
{
cnt->s--;
cout<<"release "<<cnt->s<<endl;
if(cnt->s <1)
{
delete _ptr;
if(cnt->w <1)
{
delete cnt;
cnt=NULL;
}
}
}
T* _ptr;
Counter* cnt;
}
3. weak_ptr的实现
template<class T>
class WeakPtr
{
public:
//默认构造函数
WeakPtr()
{
_ptr = 0;
cnt = 0;
}
//拷贝构造函数
WeakPtr(SharedPtr<T> &s):_ptr(s.ptr),cnt(s.cnt)
{
cout<<"w con s"<<endl;
cnt->w++;
}
WeakPtr(WeakPtr<T> & w):_ptr(w.ptr),cnt(w.cnt)
{
cnt->w++;
}
~WeakPtr()
{
release();
}
//赋值构造函数
WeakPtr<T> &operator=(WeakPtr<T> &w)
{
if(this!=&w)
{
release();
cnt = w.cnt;
cnt->w++;
_ptr = w.ptr;
}
return *this;
}
WeakPtr<T> &operator=(SharedPtr<T> &s)
{
cout<<"w=s"<<endl;
release();
cnt = s.cnt;
cnt->w++;
_ptr = s._ptr;
return *this;
}
SharedPtr<T> lock()
{
return SharedPtr<T>(*this);
}
bool expired()
{
if(cnt)
{
if(cnt->s>0)
{
cout<<"empty"<<cnt->s<<endl;
return false;
}
}
return true;
}
friend class SharedPtr<T>;
private:
void release()
{
if(cnt)
{
cnt->w--;
cout<<"weakptr release"<<cnt->w<<endl;
if(cnt->w<1&&cnt->s<1)
{
cnt = NULL;
}
}
}
T *_ptr;
Counter* cnt;
}
4. 测试代码如下:
class parent;
class child;
class parent
{
public:
// SharePtr<child> ch;
WeakPtr<child> ch;
};
class child
{
public:
SharePtr<parent> pt;
};
int main()
{
//SharePtr<parent> ft(new parent());
//SharePtr<child> son(new child());
//ft->ch=son;
//son->pt=ft;
//SharePtr<child> son2=(ft->ch).lock();
SharePtr<int> i;
WeakPtr<int> wi(i);
cout<<wi.expired()<<endl;
return 0;
}
60.1_4 智能指针存在相互引用的问题,如何解决?
答案
1. 当只剩下最后一个引用的时候需要手动打破循环引用释放对象。
2. 当A的生存期超过B的生存期的时候,B改为使用一个普通指针指向A。
3. 使用弱引用的智能指针打破这种循环引用。
虽然这三种方法都可行,但方法1和方法2都需要程序员手动控制,麻烦且容易出错。我们一般使用第三种方法:弱引用的智能指针weak_ptr。
60.1_5 智能指针的本质?
答案
本质是存放在栈的模板对象,只是在栈内部包了一层指针。而栈在其声明周期结束的时候,其中的指针指向的堆内存也自然被释放了。
60.1_6 智能指针如何进行强制类型转换(Qt的智能指针类型转换)
答案
1. shared_ptr提供的转型函数:
static_pointer_cast<T>()、
const_pointer_cast<T>()、
dynamic_pointer_cast<T>()
std::reinterpret_pointer_cast<T>()
2. Qt的智能指针类型转换
qSharedPointerCast
qSharedPointerDynamicCast
qSharedPointerConstCast
qWeakPointerCast
61. c++源文件从文本到可执行文件经历的过程(gcc编译的过程)
答案
1. 预处理阶段:---->变成.i文件。
>1. 打开头文件,插入到我们本身的程序之中。
>2. 把程序中所有的宏替换。
>3. 删除注释
>4. #ifdef 0的那一部分,机器也不会看到。
2. 编译阶段---->变成.s文件
`过程`:词法分析->语法分析->语义分析->优化->目标代码生成->目标代码优化
>1. 将程序编程汇编语言。
>2. 检查一下程序是否有语法错误。
3. 汇编阶段------->变成.o文件
>1. 将汇编程序变.o文件。
>2. 将汇编程序变为机器代码
4. 链接阶段------>变成可执行文件。
>1.使用动态链接或静态链接,链接一些需要的文件。
62.请你回答一下malloc的原理,另外brk系统调用和mmap系统调用的作用分别是什么?
答案
1. malloc 实现方案说法一:Malloc函数用于动态分配内存。为了减少内存碎片和系统调用的开销,malloc采用内存池的方式。先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位。当用户申请内存时,直接从堆区分配一块合适的空闲块。
并且,Malloc采用隐式链表结构将堆区分成连续的,大小不一的块,包含已分配块和未分配块。用显式链表结构来管理所有的空闲块,即使用一个双向链表将空闲块连接起来。每一个空闲块记录了一个连续的,未分配的地址。
Malloc在申请内存时,一般会通过brk或者mmap系统调用进行申请。其中当申请内存小于128K时,会使用系统函数brk在堆区中分配;而当申请内存大于128K时,会使用系统函数mmap在映射区分配。
2. malloc实现方案说法二:malloc 函数的实质是它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。 调用 malloc()函数时,它沿着连接表寻找一个大到足以满足用户请求所需要的内存块。 然后,将该内存块一分为二(一块的大小与用户申请的大小相等,另一块的大小就是剩下来的字节)。 接下来,将分配给用户的那块内存存储区域传给用户,并将剩下的那块(如果有的话)返回到连接表上。 调用 free 函数时,它将用户释放的内存块连接到空闲链表上。 到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段, 那么空闲链表上可能没有可以满足用户要求的片段了。于是,malloc()函数请求延时,并开始在空闲链表上检查各内存片段,对它们进行内存整理,将相邻的小空闲块合并成较大的内存块。
62.1 new和malloc的区别
答案
1. **申请的内存的区域是不同的。**
new申请内存的区域一般是在自由存储区,而malloc申请的区域一般是在堆区。c语言使用malloc从堆上分配内存,使用free释放已分配的内存。
2. **返回类型安全性**
new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无需进行类型转换,而malloc内存分配成功后,返回的是void *。需要我们自身将其强制类型转换成为我们需要的类型。
3. **内存分配失败时的返回值**
new内存分配失败时,会抛出bac_alloc异常,它不会返回NULL;malloc分配内存失败时返回NULL。所以,使用New的话,应该使用try catch捕捉异常。
4. **是否需要指定内存大小**
用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的尺寸。
5. **是否调用构造函数/析构函数**
使用new操作符来分配对象内存时会经历三个步骤:
第一步:调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
第三部:对象构造完成后,返回一个指向该对象的指针。
使用delete操作符来释放对象内存时会经历两个步骤:
第一步:调用对象的析构函数。
第二步:编译器调用operator delete(或operator delete[])函数释放内存空间。
总之来说,new/delete会调用对象的构造函数/析构函数以完成对象的构造/析构。而malloc则不会。
6. **对数组的处理**
C++提供了new[]与delete[]来专门处理数组类型:
`A * ptr = new A[10];//分配10个A对象`
使用new[]分配的内存必须使用delete[]进行释放:
delete [] ptr;
new对数组的支持体现在它会分别调用构造函数函数初始化每一个数组元素,释放对象时为每个对象调用析构函数。注意delete[]要与new[]配套使用,不然会找出数组对象部分释放的现象,造成内存泄漏。
至于malloc,它并知道你在这块内存上要放的数组还是啥别的东西,反正它就给你一块原始的内存,在给你个内存的地址就完事。所以如果要动态分配一个数组的内存,还需要我们手动自定数组的大小:
int * ptr = (int *) malloc( sizeof(int) );//分配一个10个int元素的数组
7. **new与malloc是否可以相互调用**
operator new /operator delete的实现可以基于malloc,而malloc的实现不可以去调用new。
8. **是否可以被重载**
opeartor new /operator delete可以被重载。标准库是定义了operator new函数和operator delete函数的8个重载版本.
而malloc/free并不允许重载。
9. **能够直观地重新分配内存**
使用malloc分配的内存后,如果在使用过程中发现内存不足,可以使用realloc函数进行内存重新分配实现内存的扩充。realloc先判断当前的指针所指内存是否有足够的连续空间,如果有,原地扩大可分配的内存地址,并且返回原来的地址指针;如果空间不够,先按照新指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来的内存区域。
10. **客户处理内存分配不足**
在operator new抛出异常以反映一个未获得满足的需求之前,它会先调用一个用户指定的错误处理函数,这就是new-handler。new_handler是一个指针类型:
`namespace std{ typedef void (*new_handler)();}`
指向了一个没有参数没有返回值的函数,即为错误处理函数。为了指定错误处理函数,客户需要调用set_new_handler,这是一个声明于的一个标准库函数:
`namespace std{ new_handler set_new_handler(new_handler p ) throw();}`
set_new_handler的参数为new_handler指针,指向了operator new 无法分配足够内存时该调用的函数。其返回值也是个指针,指向set_new_handler被调用前正在执行(但马上就要发生替换)的那个new_handler函数。
对于malloc,客户并不能够去编程决定内存不足以分配时要干什么事,只能看着malloc返回NULL。
11. new所做的三大步骤:
1)调用operator new函数分配一块足够大的,原始的空间
2)编译器运行相应的构造函数以构造对象,并传入初值
3) 构造完对象后,就返回一个指向该对象的指针。
62.2 new的底层实现
答案
创建新对象时,new做了两件事:底层调用malloc函数分配内存、 调用构造函数。
**new在底层**调用operator new全局函数来申请空间;其实就是调用malloc函数分配内存。若申请失败,则抛出bad_alloc异常,再用try catch进行捕捉就可以了。
**delete在底层**通过operator delete全局函数来释放空间;实际是通过free来释放空间的
62.2_1 new和delete的实现原理, delete是如何知道释放内存的大小的?
答案
1. new简单类型直接调用operator new分配内存.而对于复杂结构,先调用operator new分配内存,然后在分配的内存上调用构造函数;
2. 对于简单类型,new[]计算好大小后调用operator new;对于复杂数据结构,new[]先调用operator new[]分配内存,然后在p的前四个字节写入数组大小n,然后调用n次构造函数,针对复杂类型,new[]会额外存储数组大小;
原理:
答案
1. new表达式调用一个名为operator new(operator new[])函数,分配一块足够大的、原始的、未命名的内存空间;
2. 编译器运行相应的构造函数以构造这些对象,并为其传入初始值;
3. 对象被分配了空间并构造完成,返回一个指向该对象的指针。
delete的原理:
答案
delete简单数据类型默认只是调用free函数;复杂数据类型先调用析构函数再调用operator delete;针对简单类型,delete和delete[]等同。假设指针p指向new[]分配的内存。因为要4字节存储数组大小,实际分配的内存地址为[p-4],系统记录的也是这个地址。delete[]实际释放的就是p-4指向的内存。而delete会直接释放p指向的内存,这个内存根本没有被系统记录,所以会崩溃。
delete 怎么知道释放内存的大小?(free如何知道要回收的数据的大小)
答案
需要在 new [] 一个对象数组时,需要保存数组的维度,C++ 的做法是在分配数组空间时多分配了 4 个字节的大小,专门保存数组的大小,在 delete [] 时就可以取出这个保存的数,就知道了需要调用析构函数多少次了。
一般的操作是:一个比较常见的实现,是在 malloc 的时候多分配 sizeof(size_t) 的内存,在这个 size_t 里面保存实际尺寸,并且在返回的时候,把地址向右偏移 sizeof(size_t)。free 的时候,先把入参地址向左偏移 sizeof(size_t),就得到了实际分配地址,而此处解引用就能得到实际尺寸。于是这块内存就可以回收到管理结构中了。
malloc 返回给用户态的内存起始地址比进程的堆空间起始地址多了 16 字节吗.这个多出来的 16 字节就是保存了该内存块的描述信息,比如有该内存块的大小。

62.2_2、new分配的内存是虚拟内存还是物理内存
答案
1. 无论Malloc使用brk还是mmap分配内存,分配到的都是虚拟内存。而且还是虚拟内存的页号,只是代表当前页是可以使用的而已。
2. 动态内存申请的一些规则:
1. malloc在动态申请内存时,小于128k的使用brk函数。大于128k的使用mmap系统调用。
2.将虚拟地址空间映射到物理地址空间称为内存映射。映射关系存储在一个叫页表的结构中。由MMU进行管理。MMU规定内存映射的最小单位为4K.
2. 使用malloc或new申请较大的内存空间时(未初始化)。是并没有分配物理内存空间的。只有当应用程序访问到到虚拟地址空间时,才会触发缺页异常。才会导致内核实际去分配物理内存。
62.2_3 被free回收的内存是立即返还给操作系统吗?
这个需要看具体的源码。
一般来说,回收的内存会首先被ptmalloc使用双链表保存起来,当用户下次申请的时候,会尝试从这些内存中寻找合适的返回。这样就避免了频繁的系统调用,占用过多的系统资源。同时ptmalloc也会尝试对小块内存进行合并,避免过多的内存碎片。
62.3 mmap了解过吗?
答案
mmap是一种内存映射文件的方法,即将一个文件或其他对象映射到进程的地址空间。实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对应关系。实现这种的映射后,进程就可以使用指针的方式读写这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反应用户空间,从而实现不同进程间的文件共享。
**映射的三个阶段**
1. 进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域。
2. 调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系。
3. 进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝。
**mmap和常规文件操作的区别**:
1. 常规文件系统操作:
>a. 进程发起读文件请求。
>b. 内核通过查找进程文件符表,定位到内核已打开文件集上的文件信息,从而找到此文件的inode。
>c. inode在address_space 上查找要请求的文件页是否已缓存在页缓存中。如果存在,则直接返回这片文件页的 内容。
>d. 若不存在,则通过inode定位到文件磁盘地址,将数据从磁盘拷贝到页缓存中,之后再次发起读页面过程。进而将页缓存的数据发给用户进程。
2. 使用mmap后的操作:
而使用mmap操作文件中, a:创建新的虚拟内存区域,b:建立文件磁盘地址和虚拟内存映射这两步。没有任何文件拷贝操作。
而之后访问数据发现内存中并无数据而引起的缺页异常过程,可以通过已经建立好的映射关系,只使用一次拷贝,就从磁盘中将数据传入用户空间。
总而言之,常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。
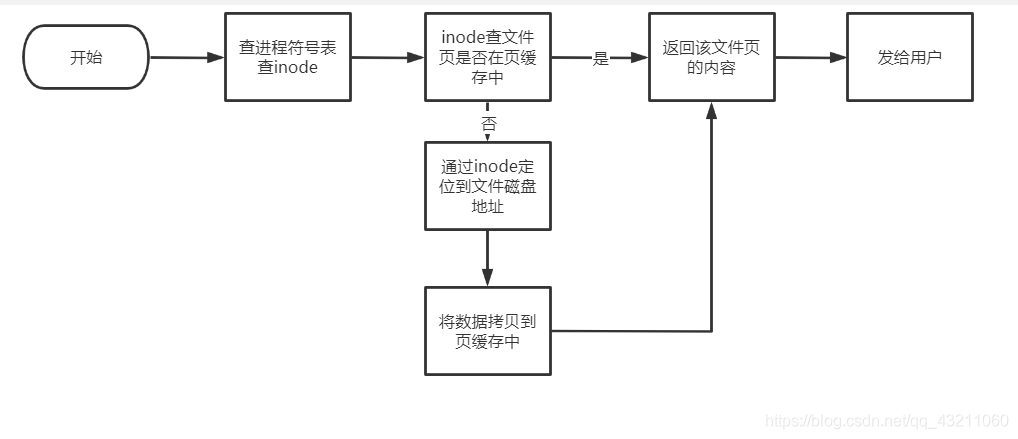
63.树的储存
双亲表示法、孩子表示法、孩子兄弟表示法 。
64. 在有继承关系的父子类中,构建和析构一个子类对象时,父子构造函数和析构函数的执行顺序分别是怎样的?
答案
1. 无论如何继承,指针如何指向,构造函数都以最终实例化为准,顺序始终是先父类后子类
2. 析构函数遵从类的多态性,非虚析构函数则以指针类型为准,虚析构函数则以最终实例为准,存在继承关系时顺序是先子类后父类
3. 虚析构函数与普通虚函数还是有不同的,普通虚函数仅按最终实例执行一次,而虚析构函数按最终实例执行后仍会依次向上逐个执行其父类析构函数
4. 可以通过"父类::函数名"来在子类中访问父类的函数,此时不论该函数是否虚函数,都会直接调用父类对应的函数
65. 在有继承关系的类体系中,父类的构造函数和析构函数一定要申明为 virtual 吗?如果不申明为 virtual 会怎样?
答案
1. C++类有继承时,析构函数必须为虚函数。如果不是虚函数,则使用时可能存在内在泄漏的问题。若析构函数是虚函数(即加上virtual关键词),delete时基类和子类都会被释放;
若析构函数不是虚函数(即不加virtual关键词),delete时只释放基类,不释放子类;
2. 构造函数不能声明为virtual ,无法正确创造对象。原因有两点:第一:调用构造函数创建对象时,必须要知道具体的对象类型,而虚函数的特性就是在运行时才你那个确定具体的对象类型。
第二:构造函数为虚函数的话,在调用构造函数的时候,虚函数表还未初始化。
3. 补充:虚函数表的创建时机: 虚函数表创建时机是在编译期间。编译期间编译器就为每个类确定好了对应的虚函数表里的内容。所以在程序运行时,编译器会把虚函数表的首地址赋值给虚函数表指针,所以,这个虚函数表指针就有值了.
66. C++ 空类默认产生的类成员函数
答案
C++的空类有哪些成员函数:
. 缺省构造函数。
. 缺省拷贝构造函数。
. 缺省析构函数。
. 缺省赋值运算符。
. 缺省取址运算符。
. 缺省取址运算符 const。
注意:有些书上只是简单的介绍了前四个函数。没有提及后面这两个函数。但后面这两个函数也是空类的默认函数。另外需要注意的是,只有当实际使用这些函数的时候,编译器才会去定义它们。
答案
//C++ 空类默认产生的类成员函数:缺省构造函数,拷贝构造函数,析构函数,赋值运算符,取址运算符,取址运算符 const
#include<iostream>
using namespace std;
class class1
{
public:
class1(){}//缺省构造函数
class1(const class1&){}//拷贝构造函数
~class1(){}//析构函数
class1&operator=(const class1&){}//赋值运算符
class1*operator&(){}//取址运算符
const class1*operator&()const{}//取址运算符 const
};
//空类class2会产生class1一样的成员函数
class class2
{
};
void main()
{
class2 obj1;//缺省构造函数
class2 obj2;
obj1=obj2;//赋值运算符
&obj2;//取址运算符
class2 obj3(obj1);//拷贝构造函数
class2 const obj4;
&obj4;//取址运算符 const
}
66.1 C++空类的大小,加一个函数呢?加一个虚函数呢?
答案
1.C++标准指出,不允许一个对象(当然包括类对象)的大小为0,不同的对象不能具有相同的地址。这是由于:
new需要分配不同的内存地址,不能分配内存大小为0的空间
避免除以 sizeof(T)时得到除以0错误
故使用一个字节来区分空类。
下面为测试代码:
#include <iostream>
using namespace std;
class NoMembers
{
};
int main()
{
NoMembers n; // Object of type NoMembers.
cout << "The size of an object of empty class is: "
<< sizeof(n) << endl;
}
值得注意的是,这并不代表一个空的基类也需要加一个字节到子类中去。这种情况下,空类并不是独立的,它附属于子类。子类继承空类后,子类如果有自己的数据成员,而空基类的一个字节并不会加到子类中去。例如,
class Empty {};
struct D : public Empty {int a;};
sizeof(D)为4。
再来看另一种情况,一个类包含一个空类对象数据成员。
class Empty {};
class HoldsAnInt {
int x;
Empty e;
};
在大多数编译器中,你会发现 sizeof(HoldsAnInt) 输出为8。这是由于,Empty类的大小虽然为1,然而为了内存对齐,编译器会为HoldsAnInt额外加上一些字节,使得HoldsAnInt被放大到足够又可以存放一个int。
2. C语言的struct的sizeof为0,而C++的空类为什么是1?
在 C 语言是 0 ,而在C++中是 1 ( VS 不允许 C 语言定义空 struct , GCC 允许,同学们最好自己也验证一下), C++ 中用类定义 的都是对象,是对象就需要调用构造函数来构造,构造就得先有内存,因为构造函数有一个形参this 需 要你传一个内存地址进来,没地址没办法构造对象的,你既然是个空类,那就给你内存的最小寻址单位 1个字节,占位,表示对象存在过; C 语言的结构体定义的是变量,只需要分配内存,没有构造这一说,因此你如过是空 struct,那么就是 0 个字节。
**总结**
>1.空类的大小占1个字节。因为不允许一个对象的大小为0。所以,用一个字节来表示对象的一些信息。
>
>2. 空类加一个普通的函数的大小:1个字节。因为普通的函数跟类的实例是没有关系的。所以不改变实例的大小。
> 3.内存会对齐到类内定义的最大的那个数据类型的size上,类内所有的变量根据定义顺序占的内存都会按照那个size对齐。
>3. static成员变量是不在类里占内存的。(计算sizeof时,忽略static变量)
>4. 若空类加一个虚函数表,则其将会占用8个字节。这8个字节是一个指向虚函数表的指针。
66.1拷贝构造和移动构造
答案
C++11之前,对象的拷贝控制由三个函数决定:拷贝构造,拷贝赋值,析构函数。
C++11之后,增加了两个移动构造函数,移动赋值函数。
构造函数与赋值运算符的区别是,构造函数在创建或初始化对象的时候调用,而赋值运算符在更新一个对象的值时调用。
移动语义的出现使得大对象可以避免频繁拷贝造成的性能下降,特别是对于临时对象,移动语义是传递它们的最佳方式。
66.2 什么情况下必须使用拷贝构造函数 ?string类的拷贝构造函数
答案
C++默认的拷贝构造函数和赋值构造函数都是浅拷贝,所以当遇到类成员中有指针变量时,就得自己实现深拷贝。
**什么情况必须使用拷贝构造?**
1. 当某个函数的入参是类对象时,拷贝构造函数会被调用。
2. 当我们基于一个已有的对象去生成一个新的对象时,拷贝构造函数会被调用。
string类的重写
答案
class String
{
public:
String(const char* str = NULL);//普通的构造函数
String(const String &other);//拷贝构造函数,要使用引用传递
~String(void);//析构函数
String &operator = (const String &other);
private:
char *m_data;//用于保存字符串
}
String::String(const char* str)//普通构造函数
{
if(str==NULL)
{
m_data = new char[1];
if(m_data)
*m_data='\0';
}
else
{
int length = strlen(str);
m_data = new char[length+1];
strcpy(m_data,str);
}
}
QSring::~String(void)
{
delete [] m_data;
}
String::String(const String&other)//拷贝构造函数
{
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data,other.m_data);
}
String & String::operate=(const String&other)//赋值函数
{
if(this==&other)
return *this;
delete [] m_data;
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data,other.m_data);
return *this;
}
66.3 拷贝构造函数
答案
拷贝构造函数必须以引用的方式传递参数。这是因为,在值传递的方式传递给一个函数的时候,会调用拷贝构造函数生成函数的实参。如果拷贝构造函数的参数仍然是以值的方式,就会无限循环的调用下去,直到函数的栈溢出。
66.3 左值与右值的区别
答案
0. 左值是一般指表达式结束后依然存在的持久化对象,右值指表达式结束时就不再存在的临时对象。
1. 能出现在赋值号左边的表达式称为“左值”,不能出现在赋值号左边的表达式称为“右值”。一般来说,左值是可以取地址的,右值则不可以。
非 const 的变量都是左值。函数调用的返回值若不是引用,则该函数调用就是右值。一般的“引用”都是引用变量的,而变量是左值,因此它们都是“左值引用”。
C++11 新增了一种引用,可以引用右值,因而称为“右值引用”。无名的临时变量不能出现在赋值号左边,因而是右值。右值引用就可以引用无名的临时变量。定义右值引用的格式如下:
类型 && 引用名 = 右值表达式;
2. 不能取地址的都是右值
对于a++
1. a++首先产生一个临时变量,记录a的值
2. 然后将a+1
3. 接着返回临时变量
根据这个过程我们知道 int a = 0;int c = a++; 的值应该是c为0;而a变为了1,
所以a++此时将临时变量返回给了c,那么这个临时变量我们是不能获取地址的,也就
是使用“&”。所以结论就是a++为右值。
对于++b
1. 进行了b = b + 1
2. 返回变量b
++b是左值。能使用取地址符号的是左值。
67. STL的基本组件
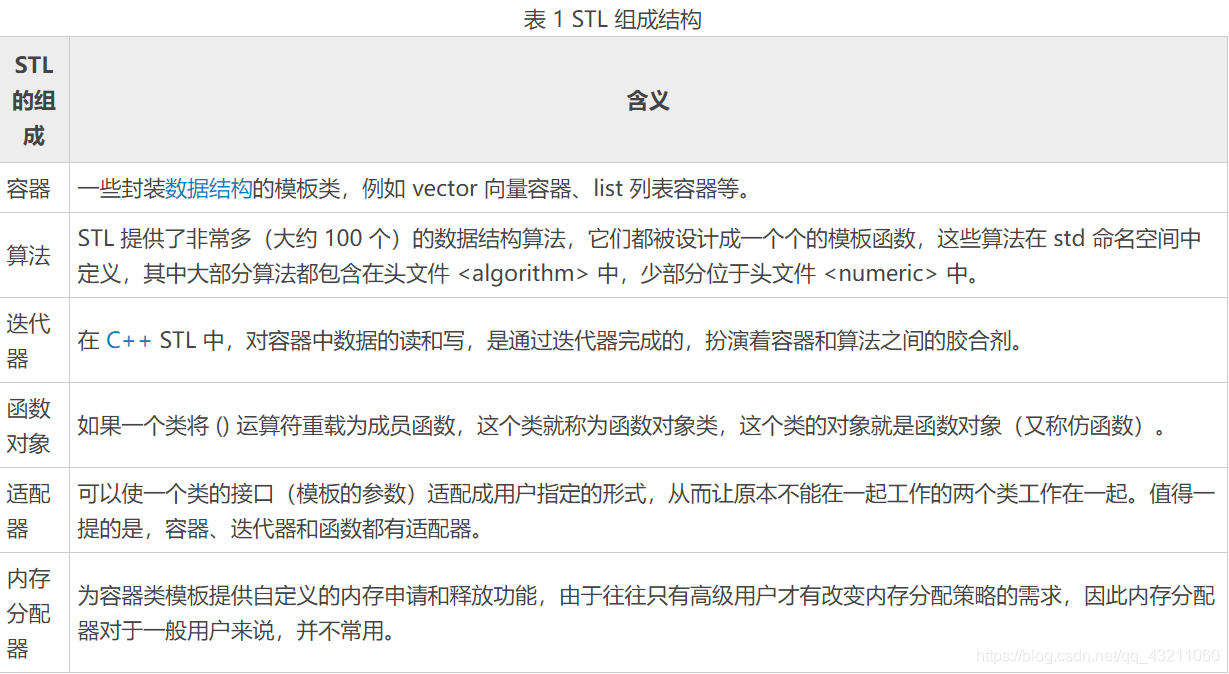
deque是唯一一个“在迭代器失效时不会使它的指针和引用失效”的标准STL容器
67.1 一个空类占用的内存大小是多少?
答案
实际上,这是类结构体实例化的原因,空的类或结构体同样可以被实例化,如果定义对空的类或者结构体取sizeof()的值为0,那么该空的类或结构体实例化出很多实例时,在内存地址上就不能区分该类实例化出的实例,所以,为了实现每个实例在内存中都有一个独一无二的地址,编译器往往会给一个空类隐含的加一个字节,这样空类在实例化后在内存得到了独一无二的地址,所以空类所占的内存大小是1个字节。
68. 递归太深有什么影响?
答案
递归算法的代码很简洁。但同时也存在缺点。
递归由于函数要调用自身,而函数调用是有时间和空间的消耗的。每一次函数调用,都需要在内存栈中分配空间以保存参数、返回地址及临时变量,而且往栈里压入数据和弹出数据都需要时间。
递归有可能很多计算都是重复的,从而对性能带来很大的负面影响。递归的本质是把一个问题分解成两个或者多个小问题。如果小问题有重叠的部分,那么就存在重复的计算。
除了效率外,递归还可能存在调用栈溢出的问题。前面提到的每一次函数调用在内存栈中分配空间,而每个进程的栈容量是有限的。当递归调用的层级太多时,就会超出栈的容量,从而导致调用栈溢出。
69. 请你谈谈 C++内存模型
答案
内存模型所要表达的内容主要是这么描述: 一个内存操作的效果,在其他线程中的可见性问题。我们知道,对计算机来说,通常内存的写操作相对于读操作是昂贵很多很多的,因此对写操作的优化是提升性能的关键,而这些对写操作的种种优化,导致了一个很普遍的现象出现:写操作通常会在 CPU 内部的 cache 中缓存起来。这就导致了在一个 CPU 里执行一个写操作之后,该操作导致的内存变化却不一定会马上就被另一个 CPU 所看到。
69.1 内存的分配方式
答案
1)从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量。
2)在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
3)从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
70. 堆内存和栈内存的区别?
答案
1. 数据结构中的堆和栈。
栈:是一种连续储存的数据结构,具有先进后出的性质。通常的操作有入栈(圧栈)、出栈和栈顶元素。想要读取栈中的某个元素,就要将其之前的所有元素出栈才能完成。类比现实中的箱子一样。
堆:是一种非连续的树形储存数据结构,每个节点有一个值,整棵树是经过排序的。特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。常用来实现优先队列,存取随意。
2. 内存中的栈区与堆区:
栈内存:由程序自动向操作系统申请分配以及回收,速度快,使用方便,但程序员无法控制。若分配失败,则提示栈溢出错误。注意,const局部变量也储存在栈区内,栈区向地址减小的方向增长。
堆内存:程序员向操作系统申请一块内存,当系统收到程序的申请时,会遍历一个记录空闲内存地址的链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。分配的速度较慢,地址不连续,容易碎片化。此外,由程序员申请,同时也必须由程序员负责销毁,否则则导致内存泄露。在堆区后一个开辟的空间的地址不一定比前面先开辟空间的地址大,因为可能后开辟空间的地址是在前面释放的空间上开辟的地址。
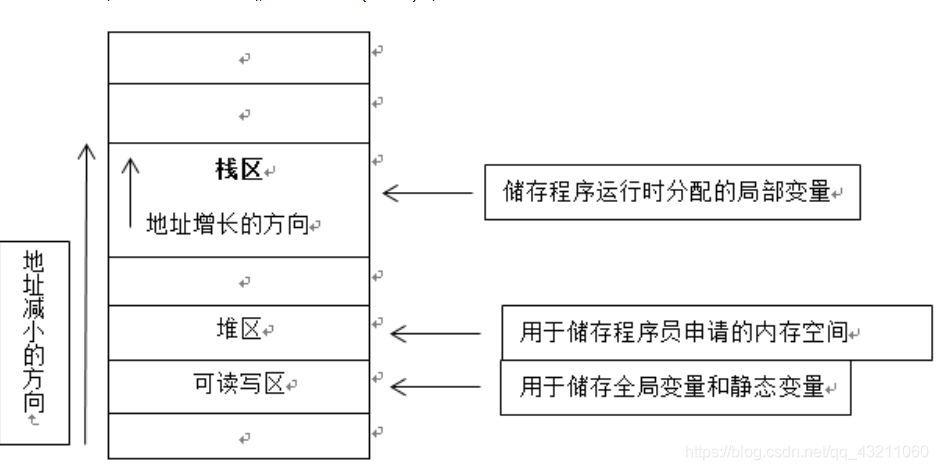
71. 重载和重写的区别
答案
重载:函数名相同,函数的参数个数、参数类型或参数顺序三者中必须至少有一种不同。函数返回值的类型可以相同,也可以不相同。发生在一个类内部,不能跨作用域。
重定义:也叫做隐藏,子类重新定义父类中有相同名称的非虚函数 ( 参数列表可以不同 ) ,指派生类的函数屏蔽了与其同名的基类函数。可以理解成发生在继承中的重载。
重写:也叫做覆盖,一般发生在子类和父类继承关系之间。子类重新定义父类中有相同名称和参数的虚函数。(override)
如果一个派生类,存在重定义的函数,那么,这个类将会隐藏其父类的方法,除非你在调用的时候,强制转换为父类类型,才能调用到父类方法。否则试图对子类和父类做类似重载的调用是不能成功的。
重写需要注意:
1、 被重写的函数不能是static的。必须是virtual的,如果不是virtual 的话,就是重定义了。
2 、重写函数必须有相同的类型,名称和参数列表
3 、重写函数的访问修饰符可以不同。
重定义规则如下:
a 、如果派生类的函数和基类的函数同名,但是参数不同,此时,不管有无virtual,基类的函数被隐藏。
b 、如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有vitual关键字,此时,基类的函数被隐藏(如果相同有Virtual就是重写覆盖了)。
73. DFS和BFS算法
DFS:深度优先算法
步骤:递归下去,回溯上来.不撞南墙不回头。 先一条路走到底,直到达到目标。这里称为递归下去。
code
答案
void dfs(int x,int y)
{
field[x][y] = '*';
for(int dx=-1;dx<=1;dx++)
{
for(int dy = -1;dy<=1;dy++)
{
int nx = x+dx,ny=y+dy;
if(0<nx&&nx<n&&0<ny&&ny<m&&field[nx][ny]=='W')
dfs(nx,ny);
}
}
}
BFS:广度优先算法
答案
BFS是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。
如果所有节点均被访问,则算法中止。
BFS同样属于盲目搜索。
一般用队列数据结构来辅助实现BFS算法。
76 IO多路复用的相关知识?
76.1 什么是IO多路复用?
答案
IO多路复用是一种同步文件描述符,实现在一个线程中监控多个文件描述符,一旦某个文件句柄就绪就能够去通知相应的应用程序进行读写操作,没有文件句柄就绪时就会阻塞应用程序,交出CPU。
76.2 说出你所知道的IO多路复用模型,并解释为什么IO多路复用效率高?
答案
select,poll,epoll都是IO多路复用的一种机制,就是通过一种机制可以监控多个文件描述符,一旦某个文件描述符就绪,就能够通知进程进行相应的读写操作。
效率高的原因:
也就是使用了IO多路复用之后,一个线程可以监控多个文件描述符,减少了线程的切换消耗以及CPU轮询损耗。
76.3 请你详细聊聊select?
答案
1. select的本质:
通过设置或者检查存放fd标志位的数据结构来进行下一步操作。
2. select的缺点有哪些?
1)单个进程可监视的fd数量被限制,即能监听端口的数量有限。(32位一般是1024,64位一般为2048)
2)对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低.所以,每次都得轮询一遍,很耗时间,要是能给套接字注册个回调函数,当他们活跃时,就自动完成相关操作。而这正是epoll与kquque所做的。
3) 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递数据结构时复制开销大。
3. select的底层原理:
select会循环遍历它所监测的fd_set内的所有文件描述符对应的驱动程序的poll函数。
驱动程序提供的poll函数首先会将调用select的用户进程插入到该设备驱动对应资源的等待队列(如读/写等待队列),然后返回一个bitmask告诉select当前资源哪些可用。
76.4 请你详细聊聊poll?
答案
poll的本质:
将用户传入的数组拷贝到内核空间,然后查询每个fd的状态,若设备就绪,则在设备等待队列中加入一项并继续遍历。若遍历完所有的fd都没有就绪设备,则挂起当前进程,直到设备就绪或主动超时,被唤醒后,它又要再次遍历fd。
poll相比select的优点:
1)poll是基于链表的,基本没有最大连接数的限制。
poll的缺点:
1)大量的fd会被整体复制于用户态和内核地址空间之间,存在大量的性能损耗。
2)poll还有一个特点是 水平触发 。若报告了之后,该fd没有被处理。那么下次再次报告的时候,会再通知这个fd。(水平触发的含义是只要处于水平状态就会一直触发)
76.4 请你详细聊聊epoll?
答案
1. epoll的本质:
使用 事件 的 就绪通知机制。通过epoll_ctl 注册fd,一旦该fd就绪,内核就会采用类似于回调的机制通知应用程序进行处理。
2. epoll的优点:
1) epoll支持 水平触发 和 边缘触发 。它只会告诉进程一次,哪些fd刚刚变成了就绪态。
2) epoll使用事件通知的机制,就不用再像select与poll一样进行轮询了。
3) epoll的最大连接数被大大扩大了,上限远大于1024.
4) epoll通过mmap文件映射内存,加速了用户态与内核态之间的信息传递。
3. epoll的底层原理:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
函数功能: create会生成一个红黑树和一个就绪链表。红黑树主要存储所监控的fd。就绪链表主要存储就绪的fd。当有fd的数据到来时,就会触发ctl.此时ctl会将该节点放入就绪链表中。wait也会收到信息,并将数据拷贝到用户空间,并清空链表。
4. epoll的水平触发(LT)和边缘触发(ET)的含义:
1)水平触发模式:一个事件只要有,就会一直触发;类比于Socket的数据,只要数据没有读取结束,那么就会一直触发,只有读取结束,才会结束触发。
2)边缘触发模式:只有一个事件从无到有才会触发。而这个的类比是,只有新的数据到来时,才会有触发。
5. epoll的底层为什么使用红黑树而不使用哈希表?
1). 如果只是单纯的查找功能而已,当然用哈希表会比较好,但事实上不是,epoll的底层还需要对文件描述符进行添加,删除,那么就要选择时间复杂度最优的方式,所以,选择了红黑树,。
2). 红黑树占用的内存更少(仅需要为其存在的节点分配内存),而哈希函数事先就需要分配足够的内存存储散列表。
3). 哈希表在元素较多的时候,很容易冲突,有可能会导致查找速度下降。
6. epoll为什么不使用AVL树而使用红黑树?
1). 整体的旋转次数用红黑树较少:
a. 首先,AVL树与红黑树一样,在插入一个节点时,也是需要两次旋转。
b. 区别在于,在删除某个节点的时候,最坏情况下,AVL树需要维护从被删节点到根节点这条路径上所有node的平衡,因此需要旋转的量级O(logN),而红黑树只需要三次旋转。
2). AVL相比RB-Tree较为平衡,在插入删除的时候,更容易引起rebalance.
3). map的实现只在查找,插入,删除方面做了折中。
76.5 select和epoll区别?它们算同步还是异步io,同步异步区别在哪里?
答案
1) 通知机制
select 基于轮训机制
epoll基于操作系统支持的I/O通知机制 epoll支持水平触发和边沿触发两种模式
2) 都是同步io。
3) 同步io需要在读写事件就绪后,自己负责读写,而异步IO无需进行读写,它只负责发起事件具体的实现由别的完成。
相关图片:
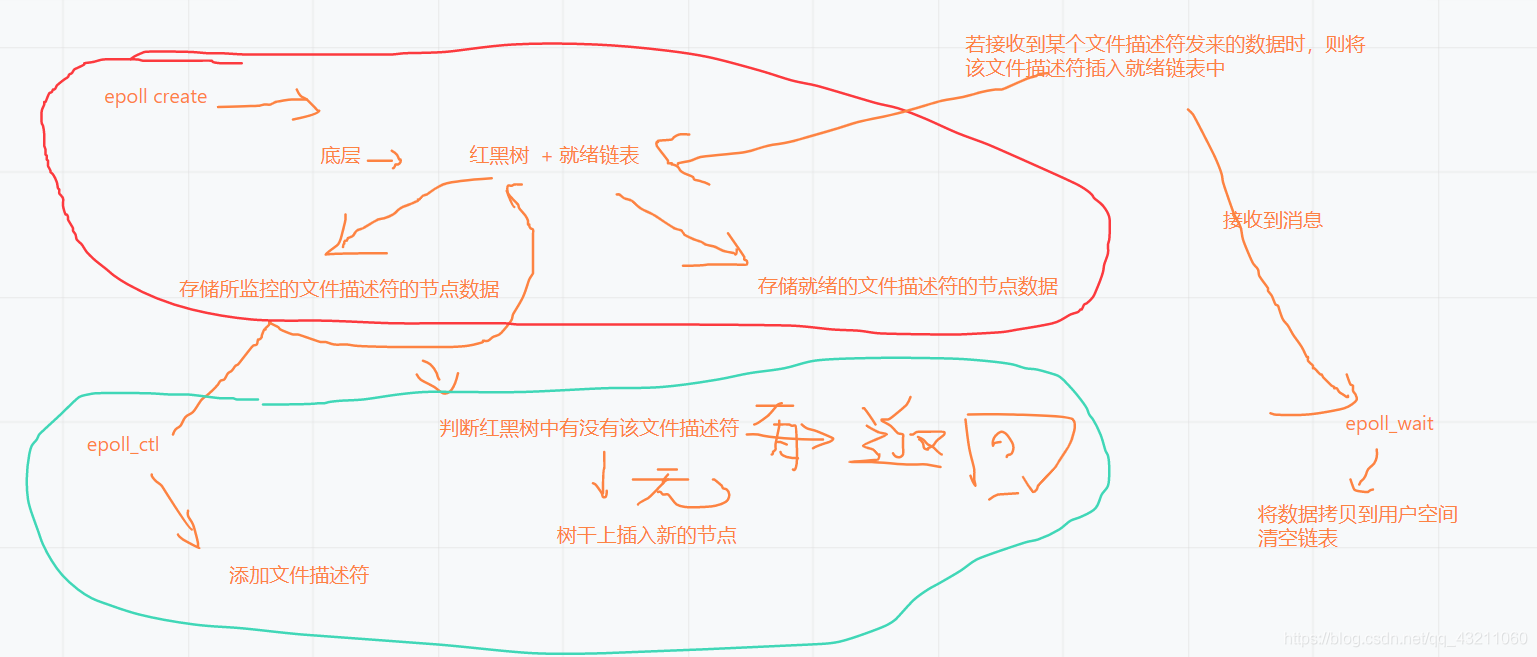

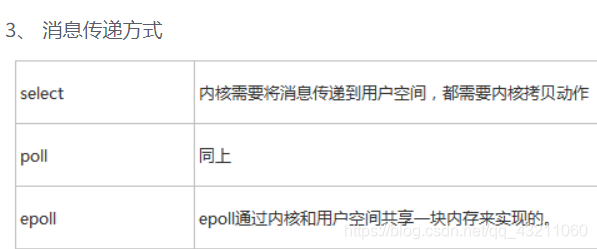
78. HashMap的面试题。
78.1 如何自己实现一个Hash?
答案
用一个数组加一个链表。其实,数组本身就可以作为一个hash表,下标作为key ,value就是数组的值。HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体。 只是在JDK1.8中,链表长度大于8的时候,链表会转成红黑树! 为什么用数组+链表? 数组是用来确定桶的位置,利用元素的key的hash值对数组长度取模得到. 链表是用来解决hash冲突问题,当出现hash值一样的情形,就在数组上的对应位置形成一条链表。
78.2 你看过hashmap的源码吗?
数组加链表的方式就是其底层原理。
78.3 hash冲突你还知道哪些解决办法?
散列法,拉链法
线性探测,再频繁,伪随机,再哈希,公共溢出区域法
装填因子(装填因子=数据总数 / 哈希表长)
(1)开放定址法
答案
1)线性探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上往后加一个单位,直至不发生哈希冲突。
2)再平方探测
顺序决定值时,如果某数据的值已经存在,则在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
3)伪随机探测
按顺序决定值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来值的基础上加上随机数,直至不发生哈希冲突。
(2)链地址法
答案
对于相同的值,使用链表进行连接。使用数组存储每一个链表。
**优点:**
1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
**缺点:**
指针占用较大空间时,会造成空间浪费,若空间用于增大散列表规模进而提高开放地址法的效率。
(3)再哈希法
答案
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
(4)公共溢出区域法
答案
建立公共溢出区存储所有哈希冲突的数据。
78.4 为什么HashMap不用LinkedList,而选用数组?
答案
因为用数组效率最高! 在HashMap中,定位桶的位置是利用元素的key的哈希值对数组长度取模得到。此时,我们已得到桶的位置。显然数组的查找效率比LinkedList大。
78.5 那ArrayList,底层也是数组,查找也快啊,为啥不用ArrayList?
答案
因为采用基本数组结构,扩容机制可以自己定义,HashMap中数组扩容刚好是2的次幂,在做取模运算的效率高。 而ArrayList的扩容机制是1.5倍扩容,那ArrayList为什么是1.5倍扩容这就不在本文说明了。
78.6 为什么hashmap的在链表元素数量超过8时改为红黑树?
答案
因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。 当元素小于8个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于8个的时候,此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
78.7 HashMap在并发编程环境下有什么问题啊?
答案
(1)多线程扩容,引起的死循环问题
(2)多线程put的时候可能导致元素丢失
(3)put非null元素后get出来的却是null
79 说一个你熟悉的设计模式
设计模式的好处:
- 可重用代码
- 保证代码可靠性
3.使代码更易于被他人理解。
单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
适配器模式:
79.1 单例模式
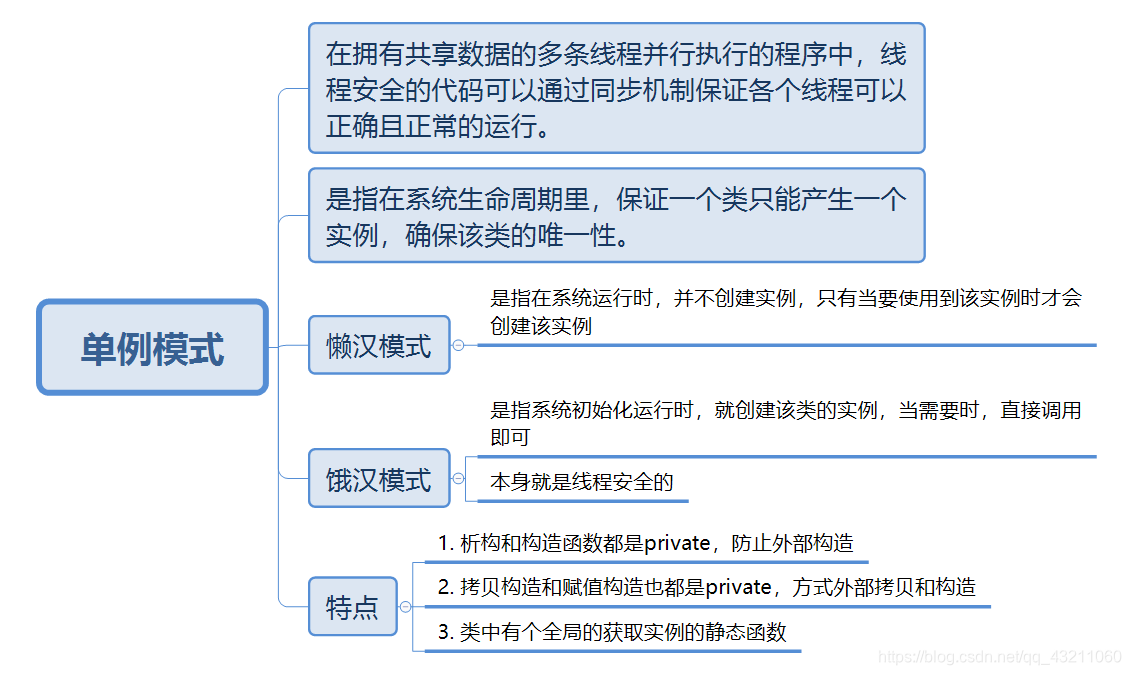
其意图是保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。单例模式分为懒汉式和饿汉式。
懒汉式是在指系统运行中,实例并不存在,只有当需要该实例时,才创建该实例。但注意,懒汉式并不是线程安全的,若要达到线程安全,则一个进行加锁。
代码
#include <iostream>
#include <mutex>
#include <pthread.h>
using namespace std;
classs SignleInstance
{
public:
//获取单例对象
static SingleInstance *GetInstance();
//释放单例,进程退出时调用
static void deleteInstance();
//打印单例地址
void Print();
private:
//将其构造和析构函数都变成私有的,精致外部构造和析构
SingleInstance();
~SingleInstance();
//将拷贝构造和赋值构造成为私有函数,禁止外部拷贝和赋值
SingleInstance(const SingleInstance &signal);//拷贝构造
const SingleInstance &operator=(const SingleInstance &signal);//const 防止对实参的意外修改
//使用引用的原因
// 因为实参是通过按值传递机制传递的。在可以传递对象cigar之前,编译器需要安排创建该对象的副本。因此,编译器为了处理复制构造函数的这条调用语句,需要调用复制构造函数来创建实参的副本。但是,由于是按值传递,第二次调用同样需要创建实参的副本,因此还得调用复制构造函数,就这样持续不休。最终得到的是对复制构造函数的无穷调用。(其实就是创建副本也是需要调用复制构造函数的)
//所以解决办法先是要将形参改为引用形参:
private:
//唯一实例对象指针
static SingleInstance *m_SingleInstance;
static mutex m_Mutex;
};
//初始化静态成员变量
SingleInstance *SingleInstance::m_SingleInstance = NULL;
mutex SingeInstance::m_Mutex;
SingleInstance* SingleInstance::GetInstance()
{
//使用双检锁的方式 ,判断对象为空再进行加锁
if(m_SingleInstance ==NULLL)
{
unique_lock<mutex> lock<m_Mutex>;
if(m_SingleInstance ==NULLL)
m_SingleInstance = new (std::nothrow) SingleInstance;//线程并发的话有可能创建多个实例,非线程安全
}
return m_SingleInstance;
}
void SingleInstance::deleteInstance()
{
unique_lock<mutex> lock<m_Mutex>
if(m_SingleInstance)
{
delete m_SingleInstance;
m_SingleInsance = NULL;//若没有置空,容易出现野指针。
}
}
void SingleInstance::Print()
{
std::cout<<"我的实例内存地址是"<<this<<std::endl;
}
SingleInstance::SingleInstance()
{
std::cout << "构造函数" << std::endl;
}
SingleInstance::~SingleInstance()
{
std::cout << "析构函数" << std::endl;
}
//普通懒汉式实现---线程不安全
void *PrintHello(void *threadid)
{
}
int main(void)
{
pthread_t threads[NUM_THREADS] = {0};
int indexes[NUM_THREADS] = {0}; // 用数组来保存i的值
int ret = 0;
int i = 0;
std::cout << "main() : 开始 ... " << std::endl;
for (i = 0; i < NUM_THREADS; i++)
{
std::cout << "main() : 创建线程:[" << i << "]" << std::endl;
indexes[i] = i; //先保存i的值
// 传入的时候必须强制转换为void* 类型,即无类型指针
ret = pthread_create(&threads[i], NULL, PrintHello, (void *)&(indexes[i]));
if (ret)
{
std::cout << "Error:无法创建线程," << ret << std::endl;
exit(-1);
}
}
// 手动释放单实例的资源
SingleInstance::deleteInstance();
std::cout << "main() : 结束! " << std::endl;
return 0;
}
饿汉式是指系统一运行,就初始化创建实例,当需要时,直接调用即可。
饿汉式
//初始化静态成员变量
#if 0 懒汉模式
SingleInstance *SingleInstance::m_SingleInstance = NULL;
#endif
#if 0 饿汉模式
SingleInstance *SingleInstance::m_SingleInstance = new(nothrow) SingleInstance;
#endif
mutex SingeInstance::m_Mutex;
SingleInstance* SingleInstance::GetInstance()
{
#if 0 懒汉模式
//使用双检锁的方式 ,判断对象为空再进行加锁
if(m_SingleInstance ==NULLL)
{
unique_lock<mutex> lock<m_Mutex>;
if(m_SingleInstance ==NULLL)
m_SingleInstance = new (std::nothrow) SingleInstance;//线程并发的话有可能创建多个实例,非线程安全
}
#endif
#if 0 饿汉模式
return m_SingleInstance;//get方法,就直接返回即可。
#endif
}
1.小林设计模式
79.1_1. 单例模式中的懒汉式与饿汉式的区别
答案
1. 加锁与否的区别:懒汉式需要加锁,执行效率会较低。饿汉式不需要加锁,执行效率相对较高。
2. 初始化:饿汉式在初始化时就创建对象,容易产生不用的对象,浪费内存。懒汉式则没有这个问题。
总结:
懒汉式是以时间换空间(懒汉式需要加锁,饿汉式不需要加锁,加锁会降低程序的运行效率。但初始化时就创建对象容易产生无用的对象,浪费空间) 。所以懒汉式适用于访问量较小的场所,代码量相对较少。
饿汉式是以空间换时间(与上面的原因是相同的),适用于访问量较大的情况下,或者线程比较多的情况下。
79.1_2 单例模式怎么处理多线程
1、饿汉式是线程安全的,懒汉式是非现场安全的。
2、确保一个类只有一个实例,并为整个系统提供一个全局访问点。
3、单例有三大重要要素:
1、私有的构造方法。
2、指向自己实例的私有静态引用。
3、以自己实例为返回值的静态的公有方法。
4、单例模式的两种经典实现:
1、立即加载: 在类加载初始化的时候,就主动创建实例。
2、延迟加载: 等到真正使用的时候才去创建实例,不用时,不去主动创建。
5、为什么说饿汉式单例天生就是线程安全的?
类加载的方式是按需加载,且只加载一次。因此,在上述单例类被加载时,就会实例化一个对象并交给自己的引用,供系统使用。换句话说,在线程访问单例对象之前就已经创建好了。再加上,由于一个类在整个生命周期中只会被加载一次,因此该单例类只会创建一个实例,也就是说,线程每次都只能也必定只可以拿到这个唯一的对象。因此就说,饿汉式单例天生就是线程安全的。
6、传统的懒汉式单例为什么是非线程安全的?
会有多个线程同时进入 if (singleton2 == null) {…} 语句块的情形发生。当这种这种情形发生后,该单例类就会创建出多个实例,违背单例模式的初衷。因此,传统的懒汉式单例是非线程安全的。
7、怎么修改传统的懒汉式单例,使其线程变得安全?
使用加锁的方式:
static Ptr get_instance(){
// "double checked lock"
if(m_instance_ptr==nullptr){
std::lock_guard<std::mutex> lk(m_mutex);
if(m_instance_ptr == nullptr){
m_instance_ptr = std::shared_ptr<Singleton>(new Singleton);
}
}
return m_instance_ptr;
}
- 基于 shared_ptr, 用了C++比较倡导的 RAII思想,用对象管理资源,当 shared_ptr 析构的时候,new 出来的对象也会被 delete掉。以此避免内存泄漏。
- 加了锁,使用互斥量来达到线程安全。这里使用了两个 if判断语句的技术称为双检锁;好处是,只有判断指针为空的时候才加锁,避免每次调用 get_instance的方法都加锁,锁的开销毕竟还是有点大的。
8、线程安全的单例的实现还有哪些,怎么实现?
9、最推荐的懒汉式单例:
#include <iostream>
class Singleton
{
public:
~Singleton(){
std::cout<<"destructor called!"<<std::endl;
}
Singleton(const Singleton&)=delete;
Singleton& operator=(const Singleton&)=delete;
static Singleton& get_instance(){
static Singleton instance;
return instance;
}
private:
Singleton(){
std::cout<<"constructor called!"<<std::endl;
}
};
int main(int argc, char *argv[])
{
Singleton& instance_1 = Singleton::get_instance();
Singleton& instance_2 = Singleton::get_instance();
return 0;
}
参考: C++ 单例模式总结与剖析
79.1_3 单例模式的更好的写法
#include <iostream>
#include <memory> // shared_ptr
#include <mutex> // mutex
// version 2:
// with problems below fixed:
// 1. thread is safe now
// 2. memory doesn't leak
class Singleton{
public:
typedef std::shared_ptr<Singleton> Ptr;
~Singleton(){
std::cout<<"destructor called!"<<std::endl;
}
Singleton(Singleton&)=delete;
Singleton& operator=(const Singleton&)=delete;
static Ptr get_instance(){
// "double checked lock"
if(m_instance_ptr==nullptr){
std::lock_guard<std::mutex> lk(m_mutex);
if(m_instance_ptr == nullptr){
m_instance_ptr = std::shared_ptr<Singleton>(new Singleton);
}
}
return m_instance_ptr;
}
private:
Singleton(){
std::cout<<"constructor called!"<<std::endl;
}
static Ptr m_instance_ptr;
static std::mutex m_mutex;
};
// initialization static variables out of class
Singleton::Ptr Singleton::m_instance_ptr = nullptr;
std::mutex Singleton::m_mutex;
int main(){
Singleton::Ptr instance = Singleton::get_instance();
Singleton::Ptr instance2 = Singleton::get_instance();
return 0;
}
79.2 工厂模式
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
工厂模式主要是为创建对象提供了接口。主要分为三类:
- 简单工厂模式。通过传入参数,控制生成的类为哪种。调用的时候,用父类的指针指向该函数即可。
- 工厂方法模式
- 抽象工厂模式
1. 简单工厂模式
答案
简单工厂模式(Simple Factory Pattern)属于类的创新型模式,又叫静态工厂方法模式(Static FactoryMethod Pattern),是通过专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。一个工厂,多个产品。产品需要有一个虚基类。通过传入参数,生成具体产品对象,并利用基类指针指向此对象。通过工厂获取此虚基类指针,通过运行时多态,调用子类实现。
简单工厂模式的核心思想就是:**有一个专门的类来负责创建实例的过程。**方法(type)根据type去new不同的对象。
-
工厂方法模式:
答案
```c 工厂方法模式定义了一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到子类。把简单工厂模式中的工厂类抽象出一个接口,这个接口只有一个方法,就是创建抽象产品的工厂方法。然后所有的要生产具体类的工厂,就去实现这个接口,这样,一个简单工厂模式的工厂类,就变成了一个工厂抽象接口和多个具体生成对象的工厂。**连type都是由工厂方法去创建的。** ```- 抽象工厂模式:抽象工厂模式是提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
81. extern“C”{}有什么用?
答案
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,**会指示编译器这部分代码按C语言的进行编译**,而不是C++的。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般之包括函数名。
>这个功能主要用在下面的情况:
>1、C++代码调用C语言代码
>2、在C++的头文件中使用
>3、在多个人协同开发时,可能有的人比较擅长C语言,而有的人擅长C++,这样的情况下也会有用到
83. static的作用
https://www.cnblogs.com/-believe-me/p/11603860.html
答案
**一. 作用于函数内部的局部变量**
局部作用域静态变量的特点:当一个函数返回后,下一次再调用时,该变量还会保持上一回的值,函数内部的静态变量只开辟一次空间,且不会因为多次调用产生副本,也不会因为函数返回而失效。也就是修饰的该变量被所有实例所共享,也就是说当某个实例修改了该变量的时候,其修改值为该类的所有实例所见。
**二. 作用于类的成员,解决同一个类的不同对象之间数据和函数共享问题**
**三. 加了static的全局变量与不加static的全局变量的作用范围不同。**
>a. 非静态全局变量的作用域是整个源程序,当一个源程序为多个cpp文件组成时,非静态的全局变量在各个cpp文件中都是有效的。
>b. 而静态全局变量则限制了其作用域,其只在定义该变量的源文件中有效,在同一源程序中的其他cpp文件是不能使用的。
85.vector和list区别,resize和reserve区别,erase底层
vector和list区别
答案
>List封装了链表,Vector封装了数组, list和vector得最主要的区别在于vector使用连续内存存储的,他支持[]运算符,而list是以链表形式实现的,不支持[]。
>Vector对于随机访问的速度很快,但是对于插入尤其是在头部插入元素速度很慢,在尾部插入速度很快。List对于随机访问速度慢得多,因为可能要遍历整个链表才能做到,但是对于插入就快的多了,不需要拷贝和移动数据,只需要改变指针的指向就可以了。另外对于新添加的元素,Vector有一套算法扩容,而List可以任意加入。
>Map,Set属于标准关联容器,使用了非常高效的平衡检索二叉树:红黑树,他的插入删除效率比其他序列容器高是因为不需要做内存拷贝和内存移动,而直接替换指向节点的指针即可。
>Set和Vector的区别在于Set不包含重复的数据。Set和Map的区别在于Set只含有Key,而Map有一个Key和Key所对应的Value两个元素。
>Map和Hash_Map的区别是Hash_Map使用了Hash算法来加快查找过程,但是需要更多的内存来存放这些Hash桶元素,因此可以算得上是采用空间来换取时间策略。
resize和reserve区别
答案
reserve是容器预留空间,但并不真正创建元素对象,在创建对象之前,不能引用容器内的元素,因此当加入新的元素时,需要用push_back()/insert()函数。
resize是改变容器的大小,并且创建对象,因此,调用这个函数之后,就可以引用容器内的对象了,因此当加入新的元素时,用operator[]操作符,或者用迭代器来引用元素对象。
再者,两个函数的形式是有区别的,reserve函数之后一个参数,即需要预留的容器的空间;resize函数可以有两个参数,第一个参数是容器新的大小,第二个参数是要加入容器中的新元素,如果这个参数被省略,那么就调用元素对象的默认构造函数。下面是这两个函数使用例子:
补充:ICMP协议是一种面向无连接的协议,用于传输出错报告控制信息。 ... 它是TCP/IP协议族的一个子协议,属于网络层协议,主要用于在主机与路由器之间传递控制信息,包括报告错误、交换受限控制和状态信息等。
erase的底层
erase和remove的区别
答案
vector中remove的作用是把元素放到vector的末尾,但并不减少vector的size。
vector中erase的作用是删除掉某个位置的position或一段区域(begin,end)中的元素,减少其size。
list中remove的函数原型是`void remove (const value_type& val)`,其作用是删除list中与val相同的节点,释放该节点的资源。
list容器中erase成员函数,其函数原型是`iterator erase(iterator position),其作用是删除position位置的节点。这也是与remove所不同的地方。
对于set来说,只有erase Api 没有remove Api . erase 的作用是把符合要求的元素都删掉。
(1) void erase (iterator position);
(2) size_type erase (const value_type& val);
(3) void erase (iterator first, iterator last);
85.1 vector/list/map/deque的底层实现,增删改查复杂度
答案
`1. Vector`
**底层实现**
使用数组实现。
**增**:O(1),**删**:O(N),**改**:O(1),**查**:O(1)
**vector**是可以快速地在最后添加删除元素,并可以快速地访问任意元素
`2. list`
**底层实现**
双向链表
**list**是可以快速地在所有地方添加删除元素,但是只能快速地访问最开始与最后的元素
`3. map`
**底层实现**
红黑树
`4. deque`
deque在开始和最后添加元素都一样快,并提供了随机访问方法,像vector一样使用[]访问任意元素,但是随机访问速度比不上vector快,因为它要内部处理堆跳转。deque也有保留空间.另外,由于deque不要求连续空间,所以可以保存的元素比vector更大,这点也要注意一下.还有就是在前面和后面添加元素时都不需要移动其它块的元素,所以性能也很高。
deque 的最大任务就是在这些分段的连续空间上,维护其整体连续的假象,并提供随机存取的接口。deque为了维持整体连续的假象,设计一个中控器,其用来记录deque内部每一段连续空间的地址。大体上可以理解为deque中的每一段连续空间分布在内存的不连续空间上,然后用一个所谓的map作为主控,记录每一段内存空间的入口,从而做到整体连续的假象。
88.程序编译和链接了解吗,有什么作用?

88.1 静态链接和动态链接的差别
静态链接方式:
答案
在程序执行之前完成所有的组装工作,生成一个可执行的目标文件(EXE文件)。
动态链接方式:
答案
在程序已经为了执行被装入内存之后完成链接工作,并且在内存中一般只保留该编译单元的一份拷贝。
静态链接库与动态链接库都是共享代码的方式,如果采用静态链接库,则无论你愿不愿意,lib中的指令都被直接包含在最终生成的EXE文件中了。但是若使用DLL,该DLL不必被包含在最终的EXE文件中,EXE文件执行时可以“动态”地引用和卸载这个与EXE独立的DLL文件。
采用动态链接库的优点:(1)更加节省内存;(2)DLL文件与EXE文件独立,只要输出接口不变,更换DLL文件不会对EXE文件造成任何影响,因而极大地提高了可维护性和可扩展性。
动态链接是相对于静态链接而言的。所谓静态链接是指把要调用的函数或者过程链接到可执行文件中,成为可执行文件的一部分。换句话说,函数和过程的代码就在程序的exe文件中,该文件包含了运行时所需的全部代码。当多个程序都调用相同函数时,内存中就会存在这个函数的多个拷贝,这样就浪费了宝贵的内存资源。而动态链接所调用的函数代码并没有被拷贝到应用程序的可执行文件中去,而是仅仅在其中加入了所调用函数的描述信息(往往是一些重定位信息)。仅当应用程序被装入内存开始运行时,在Windows的管理下,才在应用程序与相应的DLL之间建立链接关系。当要执行所调用DLL中的函数时,根据链接产生的重定位信息,Windows才转去执行DLL中相应的函数代码。一般情况下,如果一个应用程序使用了动态链接库,Win32系统保证内存中只有DLL的一份复制品
88.2 动态链接库的两种链接方法
答案
(1) 装载时动态链接(Load-time Dynamic Linking):这种用法的前提是在编译之前已经明确知道要调用DLL中的哪几个函数,编译时在目标文件中只保留必要的链接信息,而不含DLL函数的代码;当程序执行时,调用函数的时候利用链接信息加载DLL函数代码并在内存中将其链接入调用程序的执行空间中(全部函数加载进内存),其主要目的是便于代码共享。(动态加载程序,处在加载阶段,主要为了共享代码,共享代码内存)
(2) 运行时动态链接(Run-time Dynamic Linking):这种方式是指在编译之前并不知道将会调用哪些DLL函数,完全是在运行过程中根据需要决定应调用哪个函数,将其加载到内存中(只加载调用的函数进内存),并标识内存地址,其他程序也可以使用该程序,并用LoadLibrary和GetProcAddress动态获得DLL函数的入口地址。(dll在内存中只存在一份,处在运行阶段)
上述的区别主要在于阶段不同,编译器是否知道进程要调用的dll函数。动态加载在编译时知道所调用的函数,而在运行态时则必须不知道。
**共享库**(shared library):是致力于解决静态库缺陷的一个现代创新产物。共享库是一个目标模块,在运行或加载时,可以加载到任意的内存地址,并和一个在内存中的程序链接起来。
91. 移动语义的相关概念?
答案
1. 出现的原因:
为了解决拷贝构造函数的缺点,也就是每一次都要进行数据的拷贝。即使我们再也不用被拷贝的那个数据。
2. 概念
所谓移动语义,指的就是以移动而非深拷贝的方式初始化含有指针成员的类对象。简单的理解,移动语义指的就是将其他对象(通常是临时对象)拥有的内存资源“移为已用”。
3. 使用场景
事实上,对于程序执行过程中产生的临时对象,往往只用于传递数据(没有其它的用处),并且会很快会被销毁。因此在使用临时对象初始化新对象时,我们可以将其包含的指针成员指向的内存资源直接移给新对象所有,无需再新拷贝一份,这大大提高了初始化的执行效率。
4. 移动构造函数
Test(Test && t): arr(t.arr) {
cout << "move constructor" << endl;
t.arr = nullptr;
}
注意:
1.const reference可以绑定所有的值,而其他类型的引用只能绑定自己类型的值。
2. gcc 要使用这样的编译语句:`g++ -std=c++11 -fno-elide-constructors test.cpp # for instance`
3. 若想直接调用移动构造,可以使用std::move函数。
92. 完美转发的相关概念
答案
1. 完美转发的定义:
概念一:它指的是函数模板可以将自己的参数“完美”地转发给内部调用的其它函数。完美,表示能保证被转发参数的左、右值属性不变。
概念二:所谓完美转发:是指std::forward会将输入的参数原封不动地传递到下一个函数中,这个“原封不动”指的是,如果输入的参数是左值,那么传递给下一个函数的参数的也是左值;如果输入的参数是右值,那么传递给下一个函数的参数的也是右值。
概念三:lvalue 是“loactor value”的缩写,可意为存储在内存中、有明确存储地址(可寻址)的数据,而 rvalue 译为 "read value",指的是那些可以提供数据值的数据(不一定可以寻址,例如存储于寄存器中的数据)。
2. 完美转发的实现方式:
右值引用+引用折叠+std::forward
//实现完美转发的函数模板
template <typename T>
void function(T&& t) {//既可以接受左值,又可以接受右值
otherdef(forward<T>(t)); //将函数模板接收到的形参连同其左、右值属性,一起传递给被调用的函数
}
3. 注意:
std::forward<T>()与std::move()相区别的是,move()会无条件的将一个参数转换成右值,而forward()则会保留参数的左右值类型。
4. 使用场景:
C++98/03 标准中几乎不会用到,但 C++11 标准为 C++ 引入了右值引用和移动语义,因此很多场景中是否实现完美转发,直接决定了该参数的传递过程使用的是拷贝语义(调用拷贝构造函数)还是移动语义(调用移动构造函数)。
4. C++11 提出了新的模板匹配规则,即引用折叠规则:
T& & –> T&.
T&& & –> T&.
T& && –>T&.
T&& && –> T&&.
92. 通用引用的概念
答案
构成通用引用的条件:
1.必须满足T&&这种形式。
2.类型T必须是通过推断得到的。
所以构成通用引用有几种可能:
1. 函数模板参数:
template <typename T>
void f(T&& param);
2. auto声明(auto declaration)
`auto &&var = ..`;
3. typedef 声明
4. decltype声明
引用类型合成
a.T& & => T&
b.T&& & => T&
c.T& && => T&
d.T&& && => T&&
92. C++多重继承会带来什么问题?(菱形继承)
菱形继承是这个样子:

B和C从A中继承,而D多重继承于B,C。那就意味着D中会有A中的两个拷贝。因为成员函数不体现在类的内存大小上,所以实际上可以看到的情况是D的内存分布中含有2组A的成员变量。
92.1 所以菱形继承的解决方案是啥?

答案
一种通过作用域访问符::来明确调用。
一种是引入虚拟继承。虚继承的特点是,在任何派生类中的virtual基类总用同一个(共享)对象表示
虚拟继承还要有一个指针,指向基类对象。这个指针叫虚类指针。
答案
由于有了间接性和共享性两个特征,所以决定了虚继承体系下的对象在访问时必然会在时间和空间上与一般情况有较大不同。
2.1时间:在通过继承类对象访问虚基类对象中的成员(包括数据成员和函数成员)时,都必须通过某种间接引用来完成,这样会增加引用寻址时间(就和虚函数一样),其实就是调整this指针以指向虚基类对象,只不过这个调整是运行时间接完成的。
2.2空间:由于共享所以不必要在对象内存中保存多份虚基类子对象的拷贝,这样较之 多继承节省空间。虚拟继承与普通继承不同的是,虚拟继承可以防止出现diamond继承时,一个派生类中同时出现了两个基类的子对象。也就是说,为了保证 这一点,在虚拟继承情况下,基类子对象的布局是不同于普通继承的。因此,它需要多出一个指向基类子对象的指针。
97. 结构体和类的区别(struct与class的区别)?
答案
1. 结构体是很多数据的结构,里面不能有对这些数据的操作,而类class是数据以及对这些数据的操作的封装,是面向对象的基础。
2. class对成员变量有访问控制权限的控制,而struct是没有的,而在struct外可以访问结构体任何一个变量,而在类外,是不可以访问private的成员变量。
3. 最终的一个差别是访问控制权限:struct的访问控制权限默认是public,而类的默认访问控制权限是private,
4. 根本区别:class 是引用类型。struct是值类型。
5. class 可以定义析构器,struct不可以。
6. class 有显式的无参构造函数,struct没有。
7. class 不需要初始化所有的字段,而struct要。
8. struct在声明的时候,不能对实例字段进行赋值。
9. class 在使用前,一定要使用new关键字进行实例化,struct不需要。
97.1 struct 和 union区别
答案
>1. struct:
分配空间的区别:在存储多个成员信息的时候,编译器会自动struct第几个成员分配存储空间,struct可以存储多个成员信息。sizeof(struct)是内存对齐后所有成员长度的加和。而union中每个成员共用一个存储空间,一般其大小是最大的元素的空间,若有分匹配值,则只存储最后一个成员的信息。分配给union的内存size 由类型最大的元素 size 来确定
>2. 对于Union的不同成员赋值,将会对其他成员重写,原来成员的值就不存在了,而对于struct 的不同成员赋值 是互不影响的。
97.2 struct中的字节对齐机制
答案
复合数据类型,如union,struct,class的对齐方式为成员中对齐方式最大的成员的对齐方式。
32的C++采用8位对界来提高运行速度,所以编译器会尽量把数据放在它的对界上以提高内存命中率。对界是可以更改的,使用#pragma pack(x)宏可以改变编译器的对界方式,默认是8。C++固有类型的对界取编译器对界方式与自身大小中较小的一个。
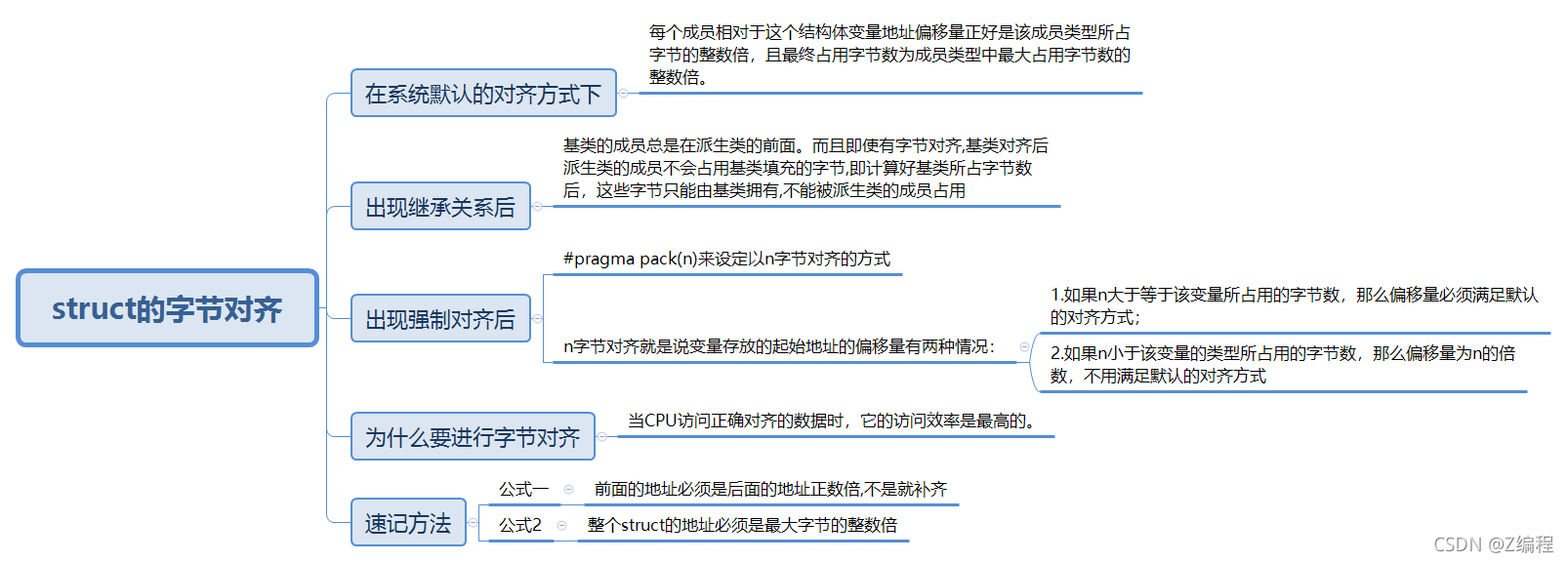
编译器对齐机制
答案
1. 数据类型自身的对齐值:对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,单位字节。
2. 结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值
3. 指定对齐值:#pragma pack (value)时的指定对齐值value
4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
**对齐机制**
>pragma pack () /*取消指定对齐,恢复缺省对齐*/
>pragma pack (1) /*指定按1字节对齐*/
97.3 C和C++中结构体的不同
答案
1. C语言中的结构体不能为空。要求至少有一个结构或联合至少有一个成员。
2. C语言中的结构体是将数据与算法分开的。也就是说C语言中的结构体只能定义成员变量,不能定义成员函数。
3. 在C语言中结构体定义变量的时候,若为struct 结构体名 变量名定义的时候,struct不能省略。但是在C++之中则可以省略struct。
4. C中的结构体是不允许继承的。
5. C中的结构体的访问控制权限只能是public。而C++的结构体的访问控制权限是private,protected,public.这三种。
97_4、如何计算结构体的长度?
答案
1. 结构体中成员的偏移量应该是成员大小的倍数。
2. 结构体的大小是结构体最大成员的倍数。
98. 哈希算法原理?
答案
散列表是根据关键码值而直接进行访问的数据结构,也就是说,它通过把关键码值映射到一个位置来访问记录,从而加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
常见的解决冲突的几种方法:
1. 线性探查法。
2. 双散列函数法。
常见的构造散列函数的方法:
1. 直接寻址法。
2. 数字分析法。
3. 平方取中法。
4. 折叠法。
5. 随机数法。
6. 除留余数法。
99. mutable和volatile是啥呀?
mutable
在类中声明变量时加入mutable关键字,可以在const成员函数中修改该类的数据成员。
在C++中,mutable是为了**突破const的限制**而设置的。被mutable修饰的变量,将永远处于可变的状态,即使在一个const函数中,甚至结构体变量或者类对象为const,其mutable成员也可以被修改。
mutable在类中只能够修饰非静态数据成员。mutable 数据成员的使用看上去像是骗术,因为它能够使const函数修改对象的数据成员。然而,明智地使用 mutable 关键字可以提高代码质量,因为它能够让你向用户隐藏实现细节,而无须使用不确定的东西。我们知道,如果类的成员函数不会改变对象的状态,那么这个成员函数一般会声明成const的。但是,有些时候,我们需要在const的函数里面修改一些跟类状态无关的数据成员,那么这个数据成员就应该被mutalbe来修饰。
const承诺的是一旦某个变量被其修饰,那么只要不使用强制转换(const_cast),在任何情况下该变量的值都不会被改变,无论有意还是无意,而被const修饰的函数也一样,一旦某个函数被const修饰,那么它便不能直接或间接改变任何函数体以外的变量的值,即使是调用一个可能造成这种改变的函数都不行。这种承诺在语法上也作出严格的保证,任何可能违反这种承诺的行为都会被编译器检查出来。
保护类的成员变量不在成员函数中被修改,是为了保证模型的逻辑正确,通过用const关键字来避免在函数中错误的修改了类对象的状态。并且在所有使用该成员函数的地方都可以更准确的预测到使用该成员函数的带来的影响。而mutable则是为了能突破const的封锁线,让类的一些次要的或者是辅助性的成员变量随时可以被更改。没有使用const和mutable关键字当然没有错,const和mutable关键字只是给了建模工具更多的设计约束和设计灵活性,而且程序员也可以把更多的逻辑检查问题交给编译器和建模工具去做,从而减轻程序员的负担。
volatile
1. 遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
2. 象const一样,volatile是一个类型修饰符。volatile修饰的数据,编译器不可对其进行执行期寄存于寄存器的优化。这种特性,是为了满足多线程同步、中断、硬件编程等特殊需要。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的直接访问。
3. volatile原意是“易变的”,但这种解释简直有点误导人,应该解释为“直接存取原始内存地址”比较合适。“易变”是相对与普通变量而言其值存在编译器(优化功能)未知的改变情况(即不是通过执行代码赋值改变其值的情况),而是因外在因素引起的,如多线程,中断等。编译器进行优化时,它有时会取一些值的时候,直接从寄存器里进行存取,而不是从内存中获取,这种优化在单线程的程序中没有问题,但到了多线程程序中,由于多个线程是并发运行的,就有可能一个线程把某个公共的变量已经改变了,这时其余线程中寄存器的值已经过时,但这个线程本身还不知道,以为没有改变,仍从寄存器里获取,就导致程序运行会出现未定义的行为。并不是因为用volatile修饰了的变量就是“易变”了,假如没有外因,即使用volatile定义,它也不会变化。而加了volatile修饰的变量,编译器将不对其相关代码执行优化,而是生成对应代码直接存取原始内存地址。
4. volatile可以保证对特殊地址的稳定访问。
volatile的使用场景
1、中断服务程序中修改的供其它程序检测的变量需要加volatile;
2、多任务环境下各任务间共享的标志应该加volatile;
3、存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能有不同意义;
示例
volatile int i=10;
int a = i;
int b = i; //其他代码,并未明确告诉编译器,对i进行过操作
volatile 指出 i是随时可能发生变化的,每次使用它的时候必须从i的地址中读取,因而编译器生成的汇编代码会重新从i的地址读取数据放在b中。而优化做法是,由于编译器发现两次从i读数据的代码之间的代码没有对i进行过操作,它会自动把上次读的数据(即10)放在b中,而不是重新从i里面读。这样以来,如果i是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile可以保证对特殊地址的直接访问。
100. vector的resize和reserve有什么不同啊?
答案
std::vector的reserve和resize的区别
1. reserve: 分配空间,更改capacity但不改变size
2. resize: 分配空间,更改capacity也改变size
如果知道vector的大小,resize一下可以当数组来用,不会分配多余的内存。
reserve是容器预留空间,但并不真正创建元素对象,在创建对象之前,不能引用容器内的元素,因此当加入新的元素时,需要用push_back()/insert()函数。
resize是改变容器的大小,并且创建对象,因此,调用这个函数之后,就可以引用容器内的对象了,因此当加入新的元素时,用operator[]操作符,或者用迭代器来引用元素对象。
再者,两个函数的形式是有区别的,reserve函数之后一个参数,即需要预留的容器的空间;resize函数可以有两个参数,第一个参数是容器新的大小,第二个参数是要加入容器中的新元素,如果这个参数被省略,那么就调用元素对象的默认构造函数。
101. malloc是如何实现的(malloc的底层实现原理)?
101.0 内存相关图例


101.1 内存的管理方式
答案
可以基于伙伴系统实现,也可以使用基于链表的实现
1. 将所有空闲内存块连成链表,每个节点记录空闲内存块的地址、大小等信息
2. 分配内存时,找到大小合适的块,切成两份,一分给用户,一份放回空闲链表
3. free时,直接把内存块返回链表
4. 解决外部碎片:将能够合并的内存块进行合并
101.2 在Linux下是如何使用malloc的?
答案
1. 若申请分配的内存小于128k。调用brk函数,其主要移动_enddata指针(该指针指向的是堆段的末尾地址,而不是数据段的末尾地址)。
1)malloc分配了这块内存,然后如果从不去访问它,那么物理页是不会被分配的。
2)当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作。
3)malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
2. 开辟的空间大于 128K 时,mmap()系统调用函数来在虚拟地址空间中堆和栈中间,称为“文件映射区域”的地方)找一块空间来开辟。malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
3. 为何小于128k可以用brk,而大于128k则用mmap? brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,因为只有一个_edata 指针,这就是内存碎片产生的原因,什么时候紧缩看高地址),而mmap分配的内存可以单独释放。所以做了这样的规定,尽量减小内存碎片的大小。
4. 为什么不全部使用 mmap 来分配内存?
1) 因为向操作系统申请内存,是要通过系统调用的,执行系统调用是要进入内核态的,然后在回到用户态,运行态的切换会耗费不少时间。
2) mmap 分配的内存每次释放的时候,都会归还给操作系统,于是每次 mmap 分配的虚拟地址都是缺页状态的,然后在第一次访问该虚拟地址的时候,就会触发缺页中断。
也就是说,频繁通过 mmap 分配的内存话,不仅每次都会发生运行态的切换,还会发生缺页中断(在第一次访问虚拟地址后),这样会导致 CPU 消耗较大。
5. 使用brk分配内存的好处?
1)malloc 通过 brk() 系统调用在堆空间申请内存的时候,由于堆空间是连续的,所以直接预分配更大的内存来作为内存池,当内存释放的时候,就缓存在内存池中。等下次在申请内存的时候,就直接从内存池取出对应的内存块就行了
2) 而且可能这个内存块的虚拟地址与物理地址的映射关系还存在,这样不仅减少了系统调用的次数,也减少了缺页中断的次数,这将大大降低 CPU 的消耗。
6. 既然 brk 那么牛逼,为什么不全部使用 brk 来分配?
随着系统频繁地 malloc 和 free ,尤其对于小块内存,堆内将产生越来越多不可用的碎片,导致“内存泄露”。而这种“泄露”现象使用 valgrind 是无法检测出来的。
101. 3 malloc管理内存的方式
答案
malloc函数用于动态分配内存。为了减少内存碎片和系统调用的开销,malloc其采用**内存池**的方式,先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位。当用户申请内存时,直接从堆区分配一块合适的空闲块。Malloc采用**隐式链表结构**将堆区分成连续的、大小不一的块,包含已分配块和未分配块;同时malloc采用**显式链表结构**来管理所有的空闲块,即使用一个双向链表将空闲块连接起来,每一个空闲块记录了一个连续的、未分配的地址。
当进行内存分配时,Malloc会通过隐式链表遍历所有的空闲块,选择满足要求的块进行分配;当进行内存合并时,malloc采用边界标记法,根据每个块的前后块是否已经分配来决定是否进行块合并。
1、空闲存储空间以空闲链表的方式组织(地址递增),每个块包含一个长度、一个指向下一块的指针以及一个指向自身存储空间的指针。( 因为程序中的某些地方可能不通过malloc调用申请,因此malloc管理的空间不一定连续。)
2、当有申请请求时,malloc会扫描空闲链表,直到找到一个足够大的块为止(首次适应)(因此每次调用malloc时并不是花费了完全相同的时间)。
3、如果该块恰好与请求的大小相符,则将其从链表中移走并返回给用户。如果该块太大,则将其分为两部分,尾部的部分分给用户,剩下的部分留在空闲链表中(更改头部信息)。因此malloc分配的是一块连续的内存。
4、释放时,首先搜索空闲链表,找到可以插入被释放块的合适位置。如果与被释放块相邻的任一边是一个空闲块,则将这两个块合为一个更大的块,以减少内存碎片。
因为brk、sbrk、mmap都属于系统调用,若每次申请内存,都调用这三个,那么每次都会产生系统调用,影响性能;其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果高地址的内存没有被释放,低地址的内存就不能被回收。
所以malloc采用的是内存池的管理方式(ptmalloc),Ptmalloc 采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理。为了内存分配函数malloc的高效性,ptmalloc会预先向操作系统申请一块内存供用户使用,当我们申请和释放内存的时候,ptmalloc会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。这样做的最大好处就是,使用户申请和释放内存的时候更加高效,避免产生过多的内存碎片。
107. 智能指针中的强指针和弱指针。
答案
一个强引用当被引用的对象活着的话,这个引用也存在(就是说,当至少有一个强引用,那么这个对象就不能被释放)。share_ptr就是强引用。相对而言,弱引用当引用的对象活着的时候不一定存在。仅仅是当它存在的时候的一个引用。弱引用并不修改该对象的引用计数,这意味这弱引用它并不对对象的内存进行管理,在功能上类似于普通指针,然而一个比较大的区别是,弱引用能检测到所管理的对象是否已经被释放,从而避免访问非法内存。
**std::shared_ptr**:shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,删除所指向的堆内存。shared_ptr内部的引用计数是安全的,但是对象的读取需要加锁。
但还不够,因为使用 std::shared_ptr 仍然需要使用 new 来调用,这使得代码出现了某种程度上的不对称。
std::make_shared 就能够用来消除显式的使用 new,所以std::make_shared 会分配创建传入参数中的对象, 并返回这个对象类型的std::shared_ptr指针。
std::unique_ptr 是一种独占的智能指针,它禁止其他智能指针与其共享同一个对象,从而保证代码的安全:
108. Qt的智能指针
- QSharedPointer
答案
1. 作用: 对拥有的资源数进行计数,当计数为0时,自动释放指向的资源。QSharedPointer 内部维持着对拥有的内存资源的引用计数。QSharedPointer 是线程安全的,因此即使有多个线程同时修改 QSharedPointer 对象也不需要加锁。这里要特别说明一下,虽然 QSharedPointer 是线程安全的,但是 QSharedPointer 指向的内存区域可不一定是线程安全的。所以多个线程同时修改 QSharedPointer 指向的数据时还要应该考虑加锁的。
2. 构造函数:
a. QSharedPointer();//构造一个空的QSharedPointer
b. QSharedPointer(T *ptr);//通过一个普通指针来构造一个QSharedPointer
c. QSharedPointer(T *ptr,Delete deleter);
d. QSharedPointer(std::nullptr_t);
e. QSharedPointer(std::nullptr_t ,Deleter d);
f. QSharedPointer(const QSharedPointer<T> &other);//用另一个QSharedPointer来构造一个QSharedPointer
g. QSharedPointer(const QWeakPointer<T> &other);//用一个QWeakPointer来构造一个QSharedPointer
3. QSharedPointer的使用
static void doDeleteLater(Myobject *obj)
{
obj->deleteLater();
}
void otherFunction()
{
QSharedPointer<Myobject> obj = QSharedPointer<Myobject>(new MyObject,doDeleteLater);
obj.clear();
}
4. QSharedPointer的不足
QSharedPointer不支持指向一个数组。
- QPointer
答案
1)功能: QPointer 与其他的智能指针有很大的不同。其他的智能指针都是为了自动释放内存资源而设计的。 QPointer 智能用于指向 QObject 及派生类的对象。当一个 QObject 或派生类对象被删除后,QPointer 能自动把其内部的指针设为 0。这样我们在使用这个 QPointer 之前就可以判断一下是否有效了。**这个能尽量避免产生野指针(悬挂指针)**。
2)使用
QPointer<QLabel> label = new QLabel;
label->setText("wuf");
..
if(label)
label->show();
3)注意点: 当一个 QPointer 对象超出作用域时,并不会删除它指向的内存对象。这和其他的智能指针是不同的
- QSharedDataPointer
答案
1)功能: 解决隐式共享类的问题。Qt中大量使用的隐式共享和写时拷贝的技术。
比如:
QString str1 = "abcdefg";
QString str2 = str1;
QString str2[2] = 'X';
第二行执行完后,str2 和 str1 指向的同一片内存数据。当第三句执行时,Qt 会为 str2 的内部数据重新分配内存。这样做的好处是可以有效的减少大片数据拷贝的次数,提高程序的运行效率。
2)
- QWeakPointer
答案
1). 功能: 解决QSharedPointer循环引用的问题。QWeakPointer不能用于直接取消引用指针,但它可用于验证指针是否已在另一个上下文中被删除。并且QWeakPointer对象只能通过QSharedPointer的赋值来创建。QWeakPointer不提供自动转换操作符来防止错误发生。即使QWeakPointer跟踪指针,也不应将其视为指针本身,因为它不能保证指向的对象保持有效。
- QScopedPointer
答案
1)功能: 类似于 C++ 11 中的 unique_ptr。当我们的内存数据只在一处被使用,用完就可以安全的释放时就可以使用 QScopedPointer。
2) 使用
void myFunction(bool useSubClass)
{
QScopedPointer<MyClass> = p(useSubClass ? new MyClass():new MySubClass);
QScopedPointer<QIODevice> device<handsOverOWnership>;
if(m_value>3)
return;
process(device);
}
- QSharedDataPointer
答案
1) 功能: 这个类是帮我们实现数据的隐式共享的。我们知道 Qt 中大量的采用了隐式共享和写时拷贝技术。Qt 中隐式共享和写时拷贝就是利用 QSharedDataPointer 和 QSharedData 这两个类来实现的。如果对象将要被改变并且其引用计数大于1,隐式共享会自动的从共享块中分离该对象。(这经常被称为写时复制)。隐式共享类可以控制它自己的内部数据。在它的要修改数据的成员函数中,它会在修改数据之前自动的分离。
- QScopedArrayPointer
答案
1) 功能: 假如我们指向的是一个内存数据是一个数组的话。
2) 使用
void foo()
{
QScopedArrayPointer<int> i(new int[10]);
i[2] = 42;
...
return;
}
110.1 指针数组的使用?
答案
主函数传参
指针数组常用在主函数传参,在写主函数时,参数有两个,一个确定参数个数,一个是用指针数组用来接收每个参数(字符串)的地址。
int main(int argc, char *argv[])
此时可以想象内存映像图,主函数的栈区有一个叫argv的数组,这个数组的元素是你输入的参数的地址,指向着只读数据区。
111.c语言函数参数的入栈顺序为从右向左的原因?
可动态变换参数个数
答案
C方式参数入栈顺序(从右至左)的好处就是可以动态变化参数个数。通过栈堆分析可知,自左向右的入栈方式,最前面的参数被压在栈底。除非知道参数个数,否则是无法通过栈指针的相对位移求得最左边的参数。这样就变成了左边参数的个数不确定,正好和动态参数个数的方向相反。
113.函数的调用栈是怎么实现的?
主函数中调用该函数的下一个命令入栈->参数从右向左入栈->局部变量入栈
答案
入栈顺序:
1. 主函数中函数调用后的下一个指令。
2. 然后是函数的各个参数。在大多数的C编译器中,参数都是从右向左入栈的。
3. 然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
115. 32位和64位指的是一个什么样的概念
答案
> CPU在单位时间内能一次处理的二进制数的位数
> 通用寄存器的位数
**区别一**:
>32位CPU --- 指的是该CPU在单位时间内能一次处理的二进制数的位数为32位,即一次处理4个字节。
>64位CPU --- 指的是该CPU在单位时间内能一次处理的二进制数的位数为64位,即一次处理8个字节。
**区别二**:
目前32位和64位是指CPU的通用寄存器位宽(数据总线的位宽),所以64位的CPU数据处理位宽是32位CPU的2倍;
118.数据结构中数组和链表的区别
数组基于索引,链表基于引用
操作的优势不同
分配内存的时间点不同
答案
数组 和 链表 之间的主要区别在于它们的结构。数组是基于索引的数据结构,其中每个元素与索引相关联。另一方面,链表 依赖于引用,其中每个节点由数据和对前一个和下一个元素的引用组成。
数组是数据结构,包含类似类型数据元素的集合,而链表被视为非基元数据结构,包含称为节点的无序链接元素的集合。
在数组中元素属于索引,即,如果要进入第四个元素,则必须在方括号内写入变量名称及其索引或位置。但是,在链接列表中,您必须从头开始并一直工作,直到达到第四个元素。
虽然访问元素数组很快,而链接列表需要线性时间,但速度要慢得多。
数组中插入和删除等操作会占用大量时间。另一方面,链接列表中这些操作的性能很快。
数组具有固定大小。相比之下,链接列表是动态和灵活的,可以扩展和缩小其大小。
在数组中,在编译期间分配内存,而在链接列表中,在执行或运行时分配内存。
元素连续存储在数组中,而它随机存储在链接列表中。
由于实际数据存储在数组中的索引中,因此对内存的要求较少。相反,由于存储了额外的下一个和前一个引用元素,因此链接列表中需要更多内存。
此外,阵列中的内存利用效率低下。相反,内存利用率在阵列中是有效的。
129. C++ move用法
唯一的功能:将左值强制转化为右值引用。继而可以通过右值引用使用该值,以用于移动语义。使用std::move几乎没有任何代价,只是转换了资源的所有权。它实际上将左值变成右值引用,然后应用移动语义,调用移动构造函数,就避免了拷贝,提高了程序性能。如果一个对象内部有较大的对内存或者动态数组时,很有必要写move语义的拷贝构造函数和赋值函数,避免无谓的深拷贝,以提高性能。
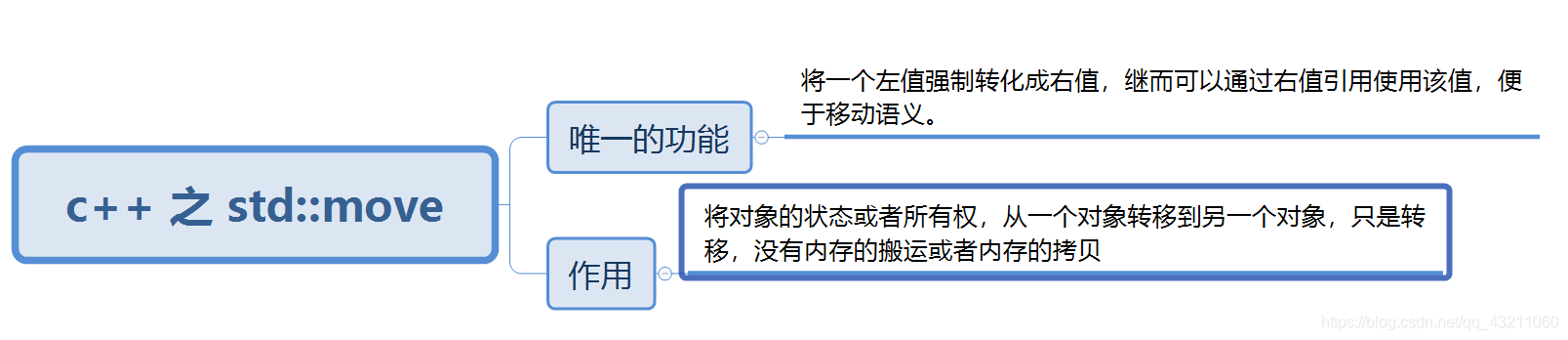
左值右值的概念
经典的用法
code
答案
//摘自https://zh.cppreference.com/w/cpp/utility/move
#include <iostream>
#include <utility>
#include <vector>
#include <string>
int main()
{
std::string str = "Hello";
std::vector<std::string> v;
//调用常规的拷贝构造函数,新建字符数组,拷贝数据
v.push_back(str);
std::cout << "After copy, str is \"" << str << "\"\n";
//调用移动构造函数,掏空str,掏空后,最好不要使用str
v.push_back(std::move(str));
std::cout << "After move, str is \"" << str << "\"\n";
std::cout << "The contents of the vector are \"" << v[0]
<< "\", \"" << v[1] << "\"\n";
}
右值引用:
答案
字面理解:以引用传递的方式使用C++右值。左值被称为lvalue(loactor value) ->可意为存储在内存中,有明确存储地址的数据,而rvalue(read value),指 的是那些可以提供数据值的 数据(不一定可以寻址,例如存储于寄存器中的数据).
1. 什么是右值引用?
选定了 2 个 '&' 表示右值引用。
2. 注意事项:
1)和声明左值引用一样,右值引用也必须立即进行初始化操作,且只能使用右值进行初始化:
int num = 10;
//int && a = num; //右值引用不能初始化为左值
int && a = 10;
2) 和常量左值引用不同的是,右值引用还可以对右值进行修改
int && a = 10;
a = 100;
cout << a << endl;
3.几种引用的使用场景:
1)非常量左值引用 无特殊使用场景
2)常量左值引用 常用于类中构建拷贝构造函数
3)非常量右值引用 移动语义与完美转发
4) 常量右值引用 无实际用途
4. 几种返回值的情况
1) 返回值是基础类型a时,
在返回的时候,编译器会在内存中创建一个临时变量并将a的值拷贝给临时变量。当返回到主函数后,临时变量的值再拷给对应的变量。
int a = getAA1(); //正确 返回值
int &a = getAA1(); //错误 非常量引用的初始值必须为左值,getAA1()返回的是常数,常数是不可以初始化引用的
2) 返回值是引用时
不会产生临时变量(副本),而是直接将a(全局变量)返回给主函数
3)返回值是static变量/全局变量
若返回静态或全局变量时,可以成为其他引用的初始值,既可以作右值,也可作左值使用
5. 用引用传递函数参数的作用
1)引用本身是目标变量或对象的别名,对引用的操作实际上是对目标变量或对象的操作,因此能使用引用时尽量用引用而非指针。
2)用引用传递函数的参数,能保证参数在传递的过程中不产生临时变量(副本),从而提高传递效率,同时通过const的使用,还可以保证参数在传递过程中的安全性
6. 右值引用主要解决的问题:
1) 第一个问题就是临时对象非必要的昂贵的拷贝操作。
2) 第二个问题是在模板函数中如何按照参数的实际类型进行转发。
答案
>1. 可位于赋值号(=)左侧的表达式就是左值;反之,只能位于赋值号右侧的表达式就是右值。
>2. 有名称的、可以获取到存储地址的表达式即为左值;反之则是右值
右值分为纯右值和将亡值
答案
1. 纯右值:指的是临时变量和不跟对象关联的字面量值。
2. 将亡值:表达式,表达式通常是需要被移动的对象。可理解为:通过“盗取”其他变量内存空间的方式获取到的值。在确保其他变量不再被使用、或即将被销毁时,通过“盗取”的方式可以避免内存空间的释放和分配,能够延长变量值的生命期。
129.1 std::move的底层原理
答案
函数原型:
template <typename T>
typename remove_reference<T>::type&& move(T&& t)
{
return static_cast<typename remove_reference<T>::type&&>(t);
}
首先,函数参数T&&是一个指向模板类型参数的右值引用,通过引用折叠,此参数可以与任何类型的实参匹配(可以传递左值或右值,这是std::move主要使用的两种场景.
std::move实现,首先,通过右值引用传递模板实现,利用引用折叠原理将右值经过T&&传递类型保持不变还是右值,而左值经过T&&变为普通的左值引用,以保证模板可以传递任意实参,且保持类型不变。然后我们通过static_cast<>进行强制类型转换返回T&&右值引用,而static_cast<T>之所以能使用类型转换,是通过remove_refrence<T>::type模板移除T&&,T&的引用,获取具体类型T。
130. 移动语义和完美转发
主要就是避免有些地方其实就是使用简单的一个临时内存,却劳心费力的又复制了一大堆内存。使用移动语义,也就是移动构造函数,也就是将内存的所有权从一个对象转移到另一个对象。注意,原来的对象的值应该进行置空。不然,容易出现悬挂指针的问题。
悬挂指针: 如果一个地方指针既不为空,也没有指向一个已知的对象,这样的指针称为悬挂指针。它指向了一块没有分配给用户使用的内存。
移动构造函数的写法
答案
MyString(MyString&& str) noexcept
: _data(str._data), _len(str._len) {
std::cout << "MyString(&&)" << std::endl;
str._len = 0;
str._data = NULL;
}
完美转发
指的是函数模板可以将自己的参数"完美”的转发给内部调用的其他函数。所谓完美,即不仅能完美的转发参数的值,还能保住转发参数的左右属性不改变。
参考1-值得再看一看,难理解
131.结构体对齐方式、意义
意义:
- 因为硬件对存储空间的处理,也就是取地址的方式有可能不同。2. 会对CPU的存储效率产生影响。
答案
1. 各个硬件平台对存储空间的处理不尽相同,比如一些CPU访问特定的变量必须从特定的地址进行读取,所以在这种架构下就必须进行字节对齐了,要不然读取不到数据或者读取到的数据是错误的。
2. 会对CPU的存取效率产生影响:比如有些平台CPU从内存中偶数地址开始读取数据,如果数据起始地址正好为偶数,则1个读取周期就可以读出一个int类型的值,而如果数据其实地址为奇数,那我们就需要2个读取周期读出数据,并对高地址和低地址进行拼凑,这在读取效率上显然已经落后了很多了。
3. 与第二点类似:CPU访问内存时,并不是按照字节访问,而是以字长访问的。比如32位的CPU,字长为4个字节。那么CPU访问内存的单位也是4字节。这么做事减少CPU访问内存的次数,加大CPU访问内存的吞吐量。

问题
答案
1. 内存对齐在提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,而这个填充实际上是没有存储任何值的。所以占用的内存会更大一点。这也是典型的空间换时间的例子。
2. 有可能在对数据进行强制类型转换时,由于字节对齐的对齐。导致取到的数据是越界的数据。出现错误。
3. 若处理器是通过消息(也就是C/C++中的结构体进行通讯的时候),需要注意字节对齐以及字节序的问题。在不同的编译平台或处理器上,字节对齐会造成消息结构长度的变化。编译器为了使字节对齐,可能会对消息结构体进行填充,不同编译平台可能填充为不同的形式,大大增加数据处理的风险。
**最好的安排方式**
数据结构的成员位置要兼顾成员之间的关系、数据访问效率和空间利用率。
顺序安排原则是:四字节的放在最前面,两字节的紧接最后一个四字节成员,一字节的紧接最后一个两字节成员,填充字节放在最后。
typedef struct tag_t_MSG{
long ParaA;
long ParaB;
short ParaC;
char ParaD;
char Pad;//填充字节
}T_MSG;
135.常量指针和指针常量区别
答案
**常量指针**:是指指针指向的是常量。即,它指向的内容不能改变,不能通过指针来修改它指向的内容。但是指针自身不是常量,它自身的值是可以改变的,可以指向其他常量。`const int * p`
**指针常量**:指针本身是常量,它指向的地址是不可改变的,但地址里的内容可以通过指针改变。`int * const p=&a;`
const后面是*,则修饰的值是常量。若*在const的前面,则指针是常量。
136.typedef和define区别
答案
1. **执行时间不同**:typedef在编译阶段有效,由于是在编译阶段,因此typedef有类型检测的功能。#define则是宏定义,发生在预处理阶段,也就是编译之前,只是进行简单而机械的字符串替换,而不进行类型检查。
2. **功能差异**:typedef用来定义类型的别名,定义与平台无关的数据类型,与struct的结合使用。#define不只是可以为类型取别名,还可以定义常量,变量,编译开关等。
3. **作用域不同**:#define没有作用域的限制,只要是之前定义过的宏,在以后的程序中都可以使用。而typedef有自己的作用域。
137. 为何要用typedef修饰函数指针
答案
语法:
typedef <返回类型> (*<函数类型名>)(参数表)
typedef <返回类型> (<类名>::*<函数类型名>)(参数表)
用途
1、可以用来定义该函数类型的函数指针,就不用每次使用函数指针都要写一次函数原型了;
2、有了类型名,就可以使用在容器里面,譬如map<int, 类型名>,用于实现灵活的函数调用。
typedef 声明函数的格式:
// 方式一 --> 表示一个返回值为 int 类型, 参数为两个 int 的函数
// 赋值时可以这样写: Func = 函数名
typedef int(Func)(int, int);
// 方式二 --> 表示一个返回值为 int 类型, 参数为两个 int 的函数
// 赋值时可以这样写: Func_P = 函数名
typedef int(*Func_P)(int, int);
关于上面的函数,调用时的语法如下:
Func *func = 函数名1;
int res = func(1, 2); // 这里 1 和 2 可以换成其它 int 类型参数
int res2 = (*func)(1, 2); // 效果和上面相同
Func_P = 函数名2;
int res = func_p(1, 2); // 这里 1 和 2 可以换成其它 int 类型参数
int res2 = (*func_p)(1, 2); // 效果和上面相同
指向外部函数的指针可如下声明:
void (*pf)(char *, const char *);
void strcpy(char * dest, const char * source);
pf=strcpy;
3. typedef uint8_t (*func_ptr) (void);
typedef定义的函数指针类型是比较方便和明了的,因为typedef实际上就是定义一个新的数据类型,typedef有这样的一个作用,就可以用它来定义函数指针类型,这个定义的函数指针类型是能够指向返回值是uint8_t的,并且函数的参数是void类型。
这里定义的typedef uint8_t (*func_ptr) (void);;就相当于把uint8_t (*) (void); 定义成了另一个别名 func_ptr了。这个func_ptr就表示了函数指针类型。
注意:这里的uint8_t (*) (void);实际上不存在这样的写法,只是为了方便理解,这样的写法是不允许的,也是错误的!这样的写法并不代表是一个类型!
137.1 使用typedef的好处
答案
1. 可以让代码更加清晰简洁。在定义结构体时可以省去struct.
2. 增加代码的可移植性。
#ifdef PIC_16
typedef unsigned long U32
#else
typedef unsigned int U32
#endif
注意事项:
1. typedef是一个存储类关键字,不能与auto、register、static、extern这些进行混用。在修饰一个变量时,不能同时使用一个以上的存储类关键字,否则编译会报错。
2. typedef 的作用域是遵循代码块作用域与文件作用域的。
3. register的作用:为了提高某些自动类变量或函数参数的处理速度。若使用register修饰存储类标识代码块内的变量,编译器就会将变量缓存于处理器内的寄存器内,此情况不能对该变量或其成员变量进行取地址的操作,因为&只能获取内存空间中的地址。
140. string的底层原理
code
* A string looks like this:
*
* @code
* [_Rep]
* _M_length
* [basic_string<char_type>] _M_capacity
* _M_dataplus _M_refcount
* _M_p ----------------> unnamed array of char_type
* @endcode
从起始地址出开始,_M_length表示字符串的长度、_M_capacity是最大容量、_M_refcount是引用计数,_M_p指向实际的数据。
根据上图推测,一个空string,没有数据,内部开辟的内存应该是83=24字节,而sizeof(string)的值似乎为84=32字节,因为需要存储四个变量的值。而实际上并不是这样。_M_p是指向实际数据的指针,当调用string::data()或者string::c_str()时返回的也是该值。因此sizeof(string)的大小为8,等于该指针的大小,而不是之前猜测的32字节。
copy-on-write机制
答案
//copy-on-write顾名思义,就是写时复制。大多数的string对象拷贝都是用于只读,每次都拷贝内存是没有必要的,而且也很消耗性能,这就有了写时复制机制,也就是把内存复制//延迟到写操作时,请看如下代码:
string s = "Fuck the code.";
string s1 = s; // 读操作,不实际拷贝内存
cout << s1 << endl; // 读操作,不实际拷贝内存
s1 += "I want it."; // 写操作,拷贝内存
1. 首先,要实现写时复制。对象拷贝的时候浅拷贝,即只复制地址指针,在所有的写操作里面重新开辟空间并拷贝内存,在新的内存空间做修改;
2. 其次,多对象共享一段内存,必然涉及到内存的释放时机,就需要一个引用计数,当引用计数减为0时释放内存;
3. 最后,要满足多线程安全性。c++要求所有内建类型具有相同级别的线程安全性,即多线程读同一对象时是安全的,多线程写同一类型的不同对象时时安全的。第一个条件很容易理解。第二个条件似乎有点多此一举,既然是不同对象,多线程读写都应该是安全的吧?对于int、float等类型确实如此,但是对于带引用计数的string则不然,因为不同的string对象可能共享同一个引用计数,而write操作会修改该引用计数,如果不加任何保护,必然会造成多线程不一致性。要解决这个问题很简单,引用计数用原子操作即可,加互斥锁当然也可以,但效率会低很多。
140_1 QString 与string的差别
答案
1. QString 不用再考虑内存分配以及'\0'的问题。
2. QString 中间是可以包含'\0'的。
3. 重新实现std::string的话,可以 优化一下程序在开辟内存的问题,也就是限制一下,一开始就给到指定的字节数,减少重新分配的次数。
147.STL数据结构集合
map, set, multimap, and multiset
答案
>上述四种容器采用红黑树实现,红黑树是平衡二叉树的一种。不同操作的时间复杂度近似为:
>插入: O(logN)
>查看:O(logN)
>删除:O(logN)
hash_map, hash_set, hash_multimap, and hash_multiset
答案
>上述四种容器采用哈希表实现,不同操作的时间复杂度为:
>插入:O(1),最坏情况O(N)。
>查看:O(1),最坏情况O(N)。
>删除:O(1),最坏情况O(N)。
>记住,如果你采用合适的哈希函数,你可能永远不会看到最坏情况。但是记住这一点是有必要的。
148. C语言如何实现面向对象编程(如何用C语言实现封装、继承、多态)
答案
**封装**:将函数指针与数据封装在结构体中。
struct直接封装。class 和 struct 最本质的区别 : class 是引用类型,它在堆中分配空间,栈中保存的只是引用;而 struct 是值类型,它在栈中分配空间。由于结构是值类型,并且直接存储数据,因此在一个对象的主要成员为数据且数据量不大的情况下,使用结构会带来更好的性能.
**继承**:使用组合的方式,在新类中定义已有类的对象,就可以实现继承。
在常见用C语言实现继承的机制中,多半是用结构体组合实现的,同样利用struct,我们来创建一个Bird结构,同时继承结构体Bird.
**多态**:可以通过传入函数指针,实现多态。
对要调用父类的指针进行强制类型转换就可以了。
149. alloca ,malloc,calloc,realloc,free
答案
malloc与calloc的区别为1块与n块的区别:
**alloca**:是向栈申请内存,因此无需释放. malloc分配的内存是位于堆中的,并且没有初始化内存的内容,因此基本上malloc之后,调用函数memset来初始化这部分的内存空间.
**malloc调用形式为(类型*)malloc(size):**在内存的动态存储区中分配一块长度为“size”字节的连续区域,返回该区域的首地址。
**calloc调用形式为(类型*)calloc(n,size):**在内存的动态存储区中分配n块长度为“size”字节的连续区域,返回首地址。calloc则将初始化这部分的内存,设置为0. 而realloc则对malloc申请的内存进行大小的调整.申请的内存最终需要通过函数free来释放. 而sbrk则是增加数据段的大小;
**realloc调用形式为(类型*)realloc(ptr,size):**将ptr内存大小增大到size。
**free的调用形式为free(voidptr):**释放ptr所指向的一块内存空间。
150.stdcall和cdecl的区别?
答案
1. **__stdcall:**是函数自己恢复堆栈,只有在函数代码的结尾出现一次恢复堆栈的代码;在编译时就规定了参数个数,无法实现不定个数的参数调用;
2. **__cdecl:**cdecl是调用者恢复堆栈,假设有100个函数调用函数a,那么内存中就有100端恢复堆栈的代码;可以不定参数个数;每一个调用它的函数都包含清空堆栈的代码,所以产生的可执行文件大小会比调用stacall函数大。
151. 迭代器失效的几种情况
1. 序列式容器 vector deque
答案
因为 vetor、deque 使用了连续分配的内存,erase操作删除一个元素导致后面所有的元素都会向前移动一个位置,这些元素的地址发生了变化,所以当前位置到容器末尾元素的所有迭代器全部失效。 所以,如果还想获取迭代器新的元素位置的话,就在使用erase的时候,返回迭代器。
2. 链表式容器 list
答案
对于链表式容器(如 list),删除当前的 iterator,仅仅会使当前的 iterator 失效,这是因为 list 之类的容器,使用了链表来实现,插入、删除一个结点不会对其他结点造成影响。只要在 erase 时,递增当前 iterator 即可,并且 erase 方法可以返回下一个有效的 iterator。
3. 关联式容器
答案
对于关联容器(如 map, set,multimap,multiset),删除当前的 iterator,仅仅会使当前的 iterator 失效,只要在 erase 时,递增当前 iterator 即可。这是因为 map 之类的容器,使用了红黑树来实现,插入、删除一个结点不会对其他结点造成影响。erase 迭代器只是被删元素的迭代器失效,但是返回值为 void,所以要采用erase(iter++)的方式删除迭代器。
152. 布隆过滤器的作用
答案
布隆过滤器其实是一个很长的二进制向量和一系列随意映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中
优点: 可以高效地进行查询,可以用来告诉你“某样东西一定不存在或者可能存在.
>1.哈希函数是哈希表以及布隆过滤器的基础。
2. 布隆过滤器其实就是一个很长的向量数组。
3. 其原理是:将某个元素,通过多个哈希函数映射到向量表上。将对应的位标志成1.那么也就意味着存在一定的误判。如果要查询某个元素的话,将该元素通过哈希函数进行映射,如果对应的位存在0的话,则代表该元素不在已存储的数组之中。反之,则证明该元素只是有可能存在于该数组之中。
153. 空指针的深入了解
答案
1. 如果仅仅声明一个指针,而没有任何赋值,那么这个指针是野指针,可能会指向系统的任何地方,碰到异常操作,比如对只读区域进行操作,就会引起硬件中断产生core,也就是通常的段错误。
2. 永远不能对一个空指针进行解引用。
3. 如果将0赋给一个指针,绝对不能使用该指针指向的内容。
4. 空指针在概念上不同于未初始化的指针,空指针可以确保不指向任何对象或函数,而未初始化的指针有可能指向任何地方。
154. STL源码中的traits
155. 模板
1. 模板的声明只能在全局,命名空间或类范围内。
155_1. 函数模板与类模板的区别
答案
1. 函数模板允许显式调用和隐式调用。而类模板只允许显式调用。
2. **模板声明下面是函数就是函数模板,如果是类就叫类模板**。
3. 类模板不支持函数自动推导。而函数模板是支持的。
4. 类模板在模板参数列表可以有默认参数。(调用类模板的使用可以不写int)
template <class TypeName, class TypeAge = int>
class Person
156. extern与static的区别
答案
1. **前言**:变量的声明可以有多次,但定义只能有一次。
2. **extern的作用**:
>a . 声明一个全局变量。 extern的作用范围是整个工程。也就是说,如果我们在.h文件中写了某个变量,链接的时候,链接器会去找其他cpp文件找有没有该变量的定义。
>b. extern "c"。作用是告诉编译器用C的编译规则去解析extern “C”后面的内容。最常见的差别就是C++支持函数重载,而标准C是不支持的。如果不指明extern “C”,C++编译器会根据自己的规则在编译函数时为函数名加上特定的后缀以区别不同的重载版本,而如果是按C的标准来编译的话,则不需要。
3. **static的作用**
>a. static在修饰全局变量的时候,其“全局”的范围其实只有其本身的cpp文件和.h文件。
157. 声明和定义的区别
声明的概念
概念一:将一个名称引入程序。
概念二:只是声明这个符号的存在,即告诉编译器,这个符号是在其他文件中定义的,我这里先用着,你链接的时候再到别的地方去找找看它到底是什么吧。声明的时候就只需要写出这个符号的原型了.
概念三:而声明只是像编译器介绍名字和标识符。它只是告诉编译器,这个函数或变量在某处可找到,它的模样像什么。
概念四:从编译原理上来看,声明只是告诉编译器,有某个类型的变量会被使用,但编译器并不会为它分配任何内存,而定义则会为其分配内存。
定义的概念
概念一:定义提供了一个实体在程序中的唯一描述,涉及到内存空间的分配以及初始值的设定。
概念二:把一个符号完完整整地描述出来:它是变量还是函数,返回什么类型,需要什么参数等等。定义的时候要按 C++ 语法完整地定义一个符号(变量或者函数)
概念三:定义是需要建立存储空间的。向编译器说明“在这里建立变量”或是“在这里建立函数”。定义就是编译器创建一个对象,并为这个对象分配一个内存,并为它取上一个名字。
注意事项:
1. 定义也是声明,extern声明不是定义,即不分配存储空间。
2. 如果使用extern关键字时,对变量进行了初始化,那就是定义。`extern int b = 20; //是定义`
函数的声明和定义
声明:一般在头文件中,对编译器说,这里我有一个函数叫function()让编译器知道这个函数的存在。
定义:一般在源文件中,具体就是函数的实现过程,写明函数体。
158. STL集锦
158_1. priority_queue
答案
1. 名字叫`优先队列`。底层是由堆实现的。
2. 数据结构的声明:
>priority_queue<int,vector<int>> :默认是大顶堆 ====>等同于priority_queue<int,vector<int>,less<int>>
>priority_queue<int,vector<int>,greater<int>> :这样是小顶堆
>[参考](https://blog.csdn.net/weixin_36888577/article/details/79937886)
3. 本质上也跟队列是一致的。只是增加了判断是否有序的功能。top,push,pop.
4. 默认是最大堆。也就是堆顶元素是最大的。priority_queue<int,vector<int>,less<int>>:也就是出队列的话,该序列为降序队列。
priority_queue<int,vector<int>,greater<int>>:也就是出队列的话,该序列为升序队列。
5. 最好使用重写仿函数:
struct tmp2
{
bool operator()(tmp1 a,tmp1 b)
{
a.x<b.x
}
}
159. 重写C函数
159_1.重写strcpy函数
答案
原型声明:extern char *strcpy(char dest[],const char *src);
头文件:#include <string.h>
功能:把从src地址开始且含有NULL结束符的字符串复制到以dest开始的地址空间
说明:src和dest所指内存区域不可以重叠且dest必须有足够的空间来容纳src的字符串。
返回指向dest的指针。
方法一
答案
#include <assert.h>
#include <iostream.h>
using namespace std;
char * strcpy(char* strDest,const char* strSrc)
{
assert((strDest!=NULL)&&(strSrc!=NULL));
char *strDestCopy = strDest;
while((*strDest++=*strSrc++)!='\0');
return strDestCopy;
}
int main()
{
char a[20],c[]="i am teacher!";
strcpy(a,c);
cout<<a<<endl;
}
方法二:
答案
/********************************************************************
*strcpy(char *dest, const char *src)函数:
*dest和src需要有空间,即dest和src需要是字符串数组或者动态分配了空间
********************************************************************/
void Strcpy(char *dest, const char *src) {
if(dest==NULL||src==NULL)
return ;
int length = 0;
int i = 0;
length = strlen(src);
while('\0' != src[i]) {
dest[i] = src[i];
i ++;
}
dest[i] = '\0';
}
方法三:考虑一下内存重叠的问题
char* mymemcpy(char *dst, const char *src, int cnt){
assert(dst != NULL);
assert(src != NULL);
char *ret = dst;
if (dst >= src && dst <= src+cnt-1){ // src<=dst<=src+strlen(src)
dst = dst + cnt -1;
src = src + cnt -1;
while (cnt--){ //从高地址开始赋值
*dst-- = *src--;
}
}else{
while (cnt--){ //普通情况,低地址开始赋值
*dst++ = *src++;
}
}
return ret;
}
char * mycpy(char *dst, const char * src){
assert(dst != NULL);
assert(src != NULL);
char *ret = dst;
// while ((*dst++ = *src++) != '\0');
mymemcpy(dst,src,strlen(src)+1); // strlen(src)+1 是因为要把'\0'考虑在内
return ret;
}
- 重写strncpy()
答案
void Strncpy(char *dest, const char *src, size_t n) {
if(dest==NULL||src==NULL)
return;
int length = strlen(src);
if(n >= length) {
Strcpy(dest, src);
return ;
}
int i = 0;
while(('\0' != src[i]) && (i < n)) {
dest[i] = src[i];
i ++;
}
dest[n] = '\0';
}
assert的作用
答案
ASSERT ()是一个调试程序时经常使用的宏,在程序运行时它计算括号内的表达式,如果表达式为FALSE (0), 程序将报告错误,并终止执行。 如果表达式不为0,则继续执行后面的语句。 这个宏通常原来判断程序中是否出现了明显非法的数据,如果出现了终止程序以免导致严重后果,同时也便于查找错误。
159_2. memcpy的重写(提升memcpy复制效率的写法)
strcpy与memcpy不同
159_2_1. strcpy和memcpy主要有以下3方面的区别。
答案
1、复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
2、复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
3、用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy
159_2_2. 如何重写memcpy提升其效率
如何重写memcpy提升其效率
//若按之前的方法一个字节一个自己的赋值性能太低,原因是:
//a. 地址总线一般是32位,能搬运4字节,一次一个肯定慢的不行;
//b. 其二,当内存区域重叠时会出现混乱情况。
//首先要求速度,根据位宽进行复制
void *Memcpy1(void *dst,const void *src,size_t num)
{
if (dst == NULL || src == NULL || n <= 0)
return NULL;
int nchunks = num/sizeof(dst);//按照cpu位宽,分成多少个块
cout<<"sizeof(dst)是:"<<sizeof(dst)<<endl;
int slice = num%sizeof(dst);//看一下那些整块整块的读取完后,还剩几个字节
unsigned long *s = (unsigned long*)src;//因为待会要动指针,所以把这个地址赋给另一个指针,待会直接返回就可以了
unsigned long *d = (unsigned long*)dst;
while(nchunks--)
{
*d++ = *s++;//一个位宽一个位宽的复制
}
while(slice--)
{
*((char*)d++) = *((char*)s++);
}
return dst;
}
//下面的方法能够规避内存重叠的bug
void *Memcpy2(void *dst,const void *src,size_t count)
{
if (dst == NULL || src == NULL || n <= 0)
return NULL;
char *d;
const char *s;
if((int)dst>((int)src+count)||(dst<src))//若内存不重叠的话,直接从头部开始就可以了
{
d = (char*)dst;
s = (char*) src;
while(count--)//这个依然还是按照一个字节一个字节的复制
{
*d++=*s++;
}
}
else//在内存重叠的情况下
{
d = (char*)((int)dst+count-1);//指针位置从末端开始,注意偏置
s = (char*)((int)src+count-1);
while(count--)
*d-- = *s--;
}
return dst;
}
//下面的方法既能规避内存重叠又能提升复制的效率
void *Memcpy(void *dst,const void *src,size_t count)
{
if (dst == NULL || src == NULL || n <= 0)
return NULL;
cout<<"sizeof(dst) 是:"<<sizeof(dst)<<endl;
int chunks = count/sizeof(dst);//按CPU位宽去划分块
int slice = count%sizeof(dst);//划分完后,剩下来的块是有多少个字节
unsigned int* d = (unsigned int*)dst;
unsigned int* s = (unsigned int*)src;
if(((int)dst>(int)src+counr||dst<src)
{
while(chunks--)
*d++=*s++;//此时加的幅度是unsigned int个字节
while(slice--)
*(char*)d++ = *(char*)s++;
}
else
{
d = (unsigned int*)((unsigned int)dst+count-sizeof(dst));
s = (unsigned int*)((unsigned int)src+count-sizeof(dst));
while(chunks--)
*d-- = *s--;//减到末端后
d++;//再往上走一步
s++;
char *d1 = (char*)d;
char *s1 = (char*)s;
d1--;
s1--;
while(slice--)
*(char*)d1-- = *(char*)s1--;
}
return dst;
}
//答案2
//该函数是逐字节逐字节的进行拷贝
void *MyMemcpy(void *dst,const void * src,int n)
{
if(dst==NULL||src==NULL||n<=0)
return NULL;
char *pdst = (char*)dst;
char *psrc = (char*)src;
if(pdst>psrc&&pdst<psrc+n)//内存有重叠的情况下,就要从最后面往前面复制
{
pdst = pdst+n;
psrc = psrc+n-1;
while(n--){
*pdst-- = *psrc--;
}
}
else
{
while(n--)
*pdst++ = *psrc++;
}
return dst;
}
//该函数是按照CPU位宽进行拷贝的
void MY::*MyMemcpy2(void *dst,const void *src,int n)
{
if(dst==NULL||src==NULL||n<=0)
return;
int *pdst = (int*)dst;
int *psrc = (int*)src;
char *tmp1 = NULL;
char *tmp2 = NULL;
int c1 = n/sizeof(dst);
int c2 = n%sizeof(dst);
if(pdst>psrc&&pdst<(psrc+n))
{
tmp1 = (char*)pdst+n-1;
tmp2 = (char*)psrc+n-1;
while(c2--)
*tmp1-- = *tmp2--;
pdst = (int*)tmp1;
psrc = (int*)tmp2;
while(c1--)
*pdst-- = *psrc--;
}
else
{
while(c1--)
*pdst++ = *psrc++;
tmp1 = (char*)pdst;
tmp2 = (char*)src;
while(c2--)
*tmp1++ = *tmp2++;
}
return dst;
}
159_3 strcpy的重写
strcpy的重写
//void * :可以被赋值为任意类型指针对象,但不能做类似 ++、-- 等操作,需要类型转换才可以
void *my_memcpy(void *src,const void *src,int n)
{
if(dst==NULL||src==NULL||n<=0)
return NULL;
char *pdst = static_cast<char *> dst;
char *psrc = static_cast<char *> src;
if(pdst>psrc&&pdst<psrc+n)//这里是考虑到目标地址在起始地址的范围之内
{
pdst = pdst+n-1;
psrc = psrc+n-1;
while(n--)
*pdst-- = *psrc--;
}
else//如果两个范围没有任何关系
{
while(n--)
*pdst++ = *psrc++;
}
}
159_4 memset的实现
答案
//memset的实现
void *memset(void *s,int c,size_t n)
{
if(src==NULL)
return;
char* psrc = (char*)src;
while(n--)
{
*psrc++ = (char)c;
}
return src;
}
159_5. strncpy的实现
答案
//strncpy的实现
char* strncpy(char* dst,const char* src,size_t n)
{
if(dst==NULL||src==NULL)//判空肯定要判的
return NULL;
if(src<dst&&src+n>dst)//若出现内存覆盖的问题
{
int m = strlen(src)<n?strlen(src):n;
char* pdst = dst+m;
*pdst-- = '\0';
src = src+m-1;
while(m--){
*pdst-- = *src--;
}
}
else
{
char* pdst = dst;
int i = 0;
while(i++<n&&(*pdst++=*src++)!='\0');
if(*(pdst-1)!='\0')
*pdst='\0';
}
return dst;
}
159_5. strcmp的实现
答案
//strcmp的实现
//① str1小于str2,返回负值或者-1(VC返回-1);
//② str1等于str2,返回0;
//③ str1大于str2,返回正值或者1(VC返回1);
int strcmp(const char* s1,const char* s2)
{
if(s1==NULL&&s2!=NULL)
return -1;
if(s2==NULL)
return 1;
while(s1&&s2&&*s1==*s2){
s1++;
s2++;
}
return *s1-*s2;
}
159_6 strlen的实现
答案
//strlen的实现
size_t strlen(const char* src)
{
if(str==NULL)
return 0;
size_t ret = 0;
while(*src++!='\0')
ret++;
return ret;
}
160. 阻塞与非阻塞的区别
答案
阻塞就是干不完不准回来,
非阻塞就是你先干,我现看看有其他事没有,完了告诉我一声
161. 请你谈谈内联函数?
答案
1)内联函数的作用?
内联函数被引入作为对宏机制的改进和补充。编译器会在每处调用内联函数的地方将内联函数的内容展开,这样既避免了函数调用的开销又没有宏定义机制的缺陷。
2) 内联函数何时不进行展开?
A. 内联函数不允许使用循环语句和开关语句(switch 语句)。
B. 递归函数也不能被用来当做内联函数。
C. 使用函数指针来调用内联函数
3) 宏定义与内联函数的区别?
a. 宏定义时在预处理阶段进行代码替换,而内联函数是在编译阶段插入代码。
b. 宏定义没有类型检查,内联函数有类型检查。
c. 宏定义肯定会被展开,而inline修饰的内联函数却不一定会被展开。
4) 内联函数与普通函数区别?
a. 最大区别:在于内部的实现,普通函数在被调用后,系统首先要跳跃到函数的入口地址,执行函数体,执行完后,再返回函数调用的地方,函数始终只有一个复制。
而内联函数则不需要进行一个寻址过程,当执行内联函数时,此函数展开,如果在N处调用 了此内联函数,则此函数则会有N个代码段的复制。
b. 内联后,调用函数与被调用函数连成一大块代码,编译器对代码的优化可以做的很好。若没有内联,执行到被调用函数时,需要跳到包含被调用函数的内存页面中执行,而被调用函数所属的页面极有可能当时不在物理内存中,意味着内联后,“缺页”的 几率会降低。
5) 补充知识点
一个程序的唯一入口main()函数肯定不会被内联化。另外编译器合成的默认构造函数、拷贝构造函数、析构函数以及赋值运算符一般都被内联化。
162. 大端模式与小端模式

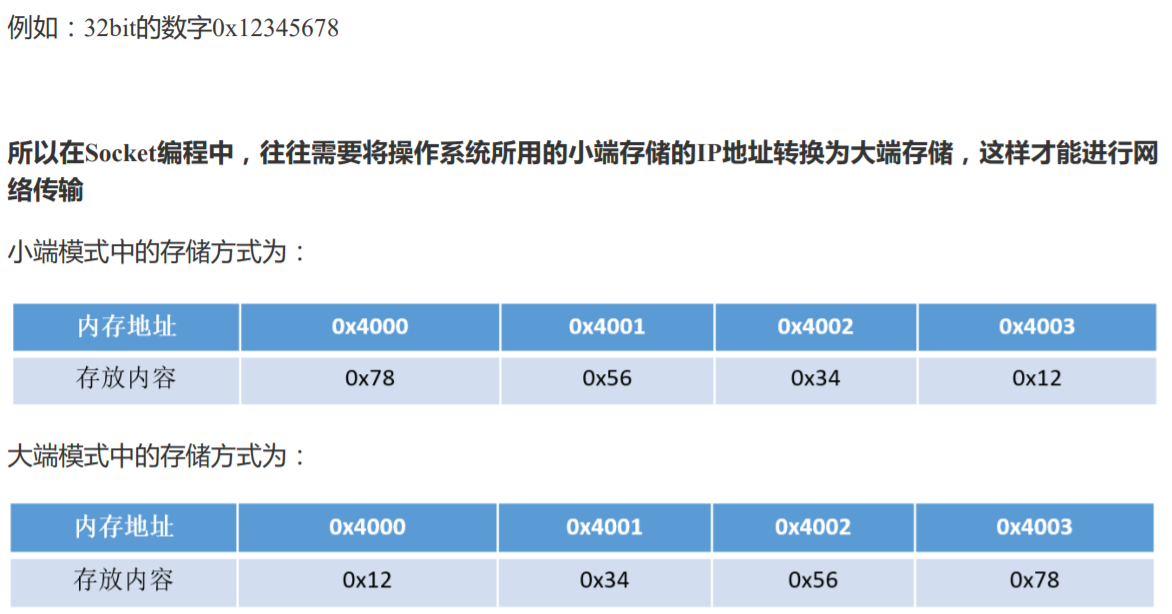
方法一:如何判断为大端存储还是小端存储

163.volatile、mutable和explicit关键字的用法
- volatile
答案
1. 该关键字是一种类型修饰符,遇到该关键字修饰的变量,编译器则不再进行优化,从而提供对特殊地址进行访问。
2. 注意该修饰符修饰的变量是易变的,每次要用到这个变量的值时都要重新读取这个变量的值,而不是去读寄存器中的备份。
3. 使用场景:多线程中被几个任务所共享的变量需要修饰为volatile.
4. 作用:防止编译器对该共享变量进行优化,将该变量装入CPU寄存器中。
- mutable
答案
作用:为了突破const的变量,由于const修饰的函数里是不能修改成员变量的状态的。但有时,我们需要在const函数里面修改一些与类状态无关的数据成员。
mutable int m_B;
- explicit
作用
1. 表明只能使用该函数声明的这种方式进行传参,不做任何缺省的转换操作。
2. explicit关键字的作用就是防止类构造函数的隐式自动转换.因为:在C++中, 如果的构造函数只有一个参数时, 那么在编译的时候就会有一个缺省的转换操作:将该构造函数对应数据类型的数据转换为该类对象.
3. explicit关键字只对有一个参数的类构造函数有效, 如果类构造函数参数大于或等于两个时, 是不会产生隐式转换的, 所以explicit关键字也就无效了
局限:
1. 只能用于类内部的 构造函数声明上。
2. 作用于单个参数的构造函数。
164. static的作用
答案
1. **隐藏**。static可以将某全局变量只隐藏在本文件之中,而不是对多个文件都可见。
2. **保持变量内容的持久化**。
3. **初始值均为0.**
165. const关键字的作用
答案
1. 阻止变量被改变。
2. 在函数传参中,可以用const修饰形参,表明它是一个输入参数,在函数内部无法更改值。
3. const若用来修饰成员函数,则表明无法在该函数内修改成员变量。
4. const对象只能调用const函数。
166. new的工作原理
答案
1. new遇到复杂结构,先调用operator new 分配内存,然后在分配的内存上调用构造函数。
2. newp[]遇到简单类型,new[]计算好大小后,调用opertor new。
3. 针对复杂结构,new[] 先调用operator new[]分配内存,然后在p的前四个字节写入数组的大小n. 然后调用n次构造函数,所以,针对复杂类型,new[]会存储数组的大小。
167.delete的工作原理
答案
1. delete 简单数据类型默认就直接调用free函数进行释放内存。
2. 复杂数据类型:先调用析构函数再调用operator delete。
3. 针对简单类型,delete和delete[]等同。假设指针p指向new[]分配的内存。因为要4字节存储数组大小,实际分配的内存地址为[p-4],系统记录的也是这个地址。delete[]实际释放的就是p-4指向的内存。而delete会直接释放p指向的内存,这个内存根本没有被系统记录,所以会崩溃。
168. malloc的实现原理
答案
malloc实现的底层原理其实是brk,mmap,munmap这些系统调用实现的。
1. brk 是数据段(.data)的最高地址指针。 分配内存时,将将_edata往高地址向上推。
2. mmap是在进程的虚拟地址空间中找一块空闲的虚拟内存。
`上面的两种方式都没有分配实际的物理内存,都是分配虚拟内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立物理内存与虚拟内存之间的关系。`
3. 在需分配的内存小于128k时,使用brk分配内存,将_edata往高处推。 在需分配的内存大于128k的时候,使用mmap分配内存。在堆和栈之间找一块空闲区域。
4. malloc是从堆里面申请内存,也就是说函数返回的指针是指向堆里面的一块内存。操作系统中有一个记录空闲内存地址的链表。当操作系统收到程序的申请时,就会遍历该链表,然后就寻找第一个空间大于所申请空间的堆结点,然后就将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
169. malloc、realloc、calloc的区别
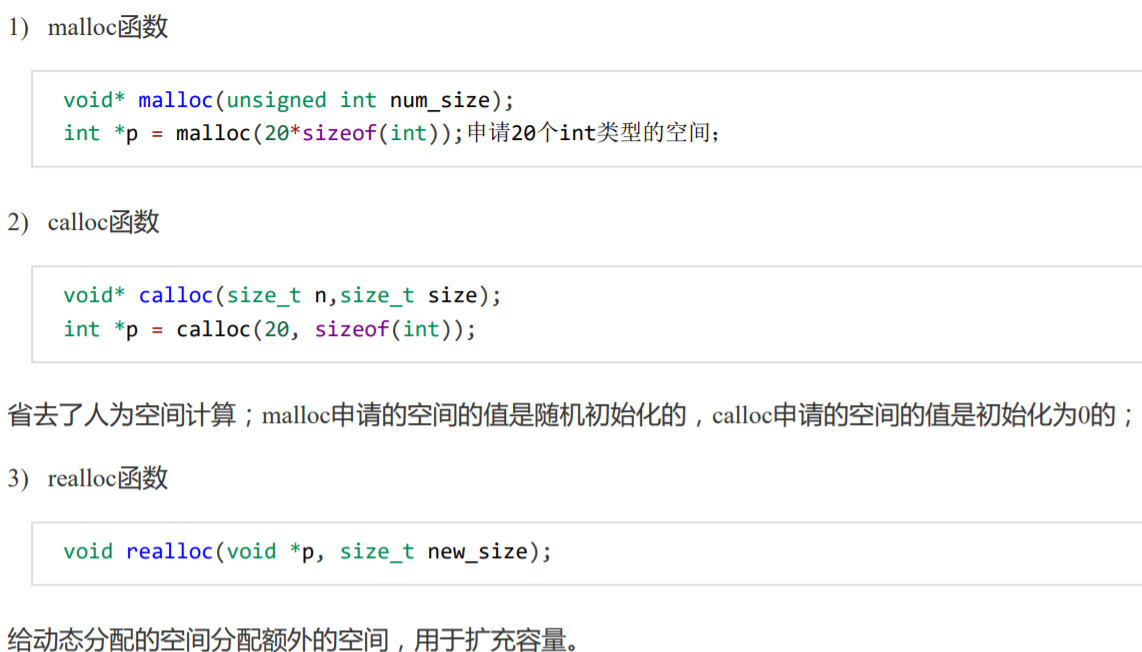
170. 函数体内初始化与函数列表初始化的区别
答案
函数体内初始化时在所有变量分配完内存才进行初始化操作的。
而列表初始化则是在分配内存的时候 就进行初始化了。
171. 对象复用 和零拷贝技术
答案
对象复用:通过将对象存储在“对象池”中实现对象的重复利用,这样可以避免多次创建重复对象的开销。
零拷贝技术:避免CPU将数据从一块内存拷贝到另一块内存中。
172. 函数参数的压栈顺序
从右向左的压榨顺序。
173. C++中将临时变量作为返回值时的处理过程
答案
首先需要明白一件事情,临时变量,在函数调用过程中是被压到程序进程的栈中的,当函数退出时,临时变量出栈,即临时变量已经被销毁,临时变量占用的内存空间没有被清空,但是可以被分配给其他变量,所以有可能在函数退出时,该内存已经被修改了,对于临时变量来说已经是没有意义的值了。
C语言里规定:16bit程序中,返回值保存在ax寄存器中,32bit程序中,返回值保持在eax寄存器中,如果是64bit返回值,edx寄存器保存高32bit,eax寄存器保存低32bit。由此可见,函数调用结束后,返回值被临时存储到寄存器中,并没有放到堆或栈中,也就是说与内存没有关系了。当退出函数的时候,临时变量可能被销毁,但是返回值却被放到寄存器中与临时变量的生命周期没有关系如果我们需要返回值,一般使用赋值语句就可以了。
174. const char* 与char* 与string的相互转化
174_1. string转const char*
答案
string s = "abc";
const char* c_s = s.c_str();
174_2. const char* 转string,直接赋值即可
答案
const char* c_s = "abs";
string s(c_s);
174_3. string 转char*
答案
string s = "abs";
char* c;
const int len = s.length();
c = new char[len+1];
strcpy(c,s.c_str());
174_4. char* 转string
答案
char* c = "abc";
string s(c);
174_5. const char* 转char*
答案
const char*cpc = "abc";
char* pc = new char[strlen(cpc)+1];
strcpy(pc,cpc);
174_6. char* 转const char*,直接赋值即可
答案
char* pc = "abc";
const char* cpc = pc;
174.7 描述char,const char,char* const,const char* const的区别?
答案
char*:普通的字符指针
const char*:表示不能修改其指向的内容。
char* const: 表示不能修改其指针
const char* const:即不能修改指针,也不能修改其指向的内容。
175. 类对象的大小受哪些因素影响?
答案
1. 非静态成员的大小。静态成员不占用类的大小,成员函数也不占用类的大小。
2. 内存对齐另外分配的空间。
3. 若有虚函数的话,则类的大小应加上vptr这个指针的大小。
4. 如果该类有继承了基类的话,那么基类的非静态成员的大小也在子类的大小中。
176. C++中的new、operator new与placement new
new operator/delete operator 就是new和delete操作符。
operator new /operator delete 是函数。
new operator
1. 调用operator new分配足够的空间,并调用相关对象的构造函数。
2. 不可以重载。
operator new
1. 只分配所要求的空间,不调用相关对象的构造函数。当无法满足所要分配的空间时,
2. 可以被重载。
3. 重载时,返回类型必须被声明为void *.
4. 重载时,第一个参数类型必须为表达要求分配空间的大小(字节),类型为size_t
5. 重载时,可以带其它参数
placement new
Placement new的返回值是这个被构造对象的地址(比如括号中的传递参数)。placement new主要适用于:在对时间要求非常高的应用程序中,因为这些程序分配的时间是确定的(因为如果用new的话,则会增加一个寻找合适内存空间的时间);长时间运行而不被打断的程序;以及执行一个垃圾收集器 (garbage collector)。
**作用**:若在预分配的内存上创建对象,用缺省的new操作符是行不通的。可以用placement new 来分配内存,它允许你创建一个新对象到预分配的内存上。
注意
new operator与delete operator的行为是不能够也不应该被改变,这是C++标准作出的承诺。而operator new与operator delete和C语言中的malloc与free对应,只负责分配及释放空间。
177. 内存管理相关笔记
答案
1. 内存管家上任之后做了以下几件事情:
a. 给每个进程分配完全独立的虚拟空间,每个进程终于有只属于自己的活动场地了
b. 进程使用的虚拟空间最终还要落到物理内存上,因此设置了一套完善的虚拟地址和物理地址的映射机制
c. 引入缺页异常机制实现内存的惰性分配,啥时候用啥时候再给
d. 引入swap机制把不活跃的数据换到磁盘上,让每块内存都用在刀刃上
e. 引入OOM机制在内存紧张的情况下干掉那些内存杀手
2. 每个进程都会有自己的页表Page Table,页表存储了进程中虚拟地址到物理地址的映射关系,所以,这就相当于一张地图,MMU收到CPU的虚拟地址之后开始查询页表,确定是否存在映射以及读写权限是否正常。
3. 多级页表也是一把双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。
4. MMU引用了人称快表的TLB.当CPU给MMU传新虚拟地址之后,MMU先去问TLB那边有没有,如果有就直接拿到物理地址发到总线给内存,齐活。
5. 进程访问的内存地址越界访问,又比如对空指针解引用内核就会报segment fault错误中断进程直接挂掉。
6. .text段:存储的是当前运行进程的二进制代码。所以,被称为代码段。
7. 在用户态层面,进程使用库函数malloc分配的是虚拟内存,并且系统是延迟分配物理内存的,由缺页中断来完成分配
8. 在内核态层面,内核也需要物理内存,并且使用了另外一套不同于用户态的分配机制和系统调用函数
9. 伙伴系统和slab属于内核级别的内存分配器,同时为内核层面内存分配和用户侧面内存分配提供服务,算是终极boss的赶脚。内存分配器分为两大类:用户态和内核态,用户态分配和释放内存最终还是通过内核态来实现的,用户态分配器更加贴合进程需求,有种社区居委会的感觉。
10. 分配器响应进程的内存分配请求,向操作系统申请内存,找到合适的内存后返回给用户程序,当进程非常多或者频繁内存分配释放时,每次都找内核老大哥要内存/归还内存,可以说十分麻烦。分配器一般都会预先分配一块大于用户请求的内存,然后管理这块内存。进程释放的内存并不会立即返回给操作系统,分配器会管理这些释放掉的内存从而快速响应后续的请求。
11.mmap和munmap是一对函数,一个负责申请,一个负责释放。mmap有两个功能:实现文件映射到内存区域 和 分配匿名内存区域,在malloc中使用的就是匿名内存分配,从而为程序存放数据开辟空间。
void *mmap(void *addr, size\_t length, int prot, int flags, int fd, off\_t offset);
int munmap(void *addr, size_t length);
12. 对于通过mmap生成的用于存放程序数据而非文件数据的内存页称为匿名页。
13. 文件页:有外部的文件介质形成映射关系。 匿名页:没有外部的文件形成映射关系
14. 正向映射是通过虚拟地址根据页表找到物理内存,反向映射就是通过物理地址找到哪些虚拟地址使用它,也就是当我们在决定page frame是否可以回收时,需要使用反向映射来查看哪些进程被映射到这块物理页了,进一步判断是否可以回收。
15. 匿名页在进程中是非常普遍的,动态分配的堆内存都可以说是匿名页,Linux为回收匿名页,特地开辟了swap space来存储内存上的数据。回收匿名页意味着将数据放到了低速设备,一旦被访问性能损耗也很大,因此现在大内存的物理机器经常关闭swap来提高性能。
178. 前置声明和include 的区别与作用
答案
a. 避免重复定义变量;
b. 避免引入函数定义/声明文件,从而函数文件发生更改时不会重新编译依赖文件。
c. 解决循环依赖问题。解决类A包含类B,类B包含类A的问题。
d. 前置声明加指针的组合能解决循环引用问题.
e. 使用前置声明的类,不能直接定义一个对象,因为编译器为其分配内存空间的时候必须知道d的大小,必须包含定义Date类的Date.h文件。此时,应用指针进行替代。所以,在头文件时可以先用前置声明,然后,在cpp文件中再引入类的头文件就可以去new该对象了。
f. 原来是因为当你在头文件声明成员变量或成员函数时,如果只需要用到某个类的指针而不需要用到类的对象,那么就可以直接只是声明一下这个类,不用include,这样可以避免编译时include编译这个类。
179. 头文件中应该写什么?
答案
规则:定义只能有一个。 头文件中应该只放变量和函数的声明,而不能放他们的定义。
1. 只能在头文件中写形如:extern int a; 和 void f(); 的句子。这些才是声明。
2. 如果写上 inta;或者 void f() {} 这样的句子,那么一旦这个头文件被两个或两个以上的 .cpp 文件包含的话,编译器会立马报错。
但上面的规则有四个例外:
1. 头文件中可以写 const 对象的.
因为全局的 const 对象默认是没有 extern 的声明的,所以它只在当前文件中有效。
2. 头文件中可以写static对象的。
因为全局的 static 对象默认是没有 extern 的声明的,所以它只在当前文件中有效。
3. 头文件中可以写内联函数(inline)的定义。
因为inline函数是需要编译器在遇到它的地方根据它的定义把它内联展开的,而并非是普通函数那样可以先声明再链接的(内联函数不会链接),所以编译器就需要在编译时看到内联函数的完整定义才行。
4. 头文件中可以写类(class)的定义。
数据成员是要等到具体的对象被创建时才会被定义(分配空间),但函数成员却是需要在一开始就被定义的,这也就是我们通常所说的类的实现。
头文件包含有可能出现的问题:
若头文件出现上面四种情况,且被同一个cpp文件包含多次的话,则编译也会报错。因为上面的四个元素,只能在源文件中出现一次。
头文件中双引号和尖括号的区别
1. 系统自带的头文件用尖括号括起来,这样编译器会在系统文件目录下查找。
2. 用户自定义的文件用双引号括起来,编译器首先会在用户目录下查找,然后在到 C++ 安装目录(比如 VC 中可以指定和修改库文件查找路径,Unix 和 Linux 中可以通过环境变量来设定)中查找,最后在系统文件中查找。
180. 一个函数,如何让它在main函数之前执行?
C语言中:
答案
#include <stdio.h>
__attribute((constructor)) void before_main()
{
printf("%s/n",__FUNCTION__);
}
__attribute((destructor)) void after_main()
{
printf("%s/n",__FUNCTION__);
}
int main( int argc, char ** argv )
{
printf("%s/n",__FUNCTION__);
return 0;
}
C++中:
答案
//C++中,利用全局变量和构造函数的特性。
//将该函数封装在类中的构造函数,然后,定义一个全局变量,声明一下这个类,
#include <iostream>
using namespace std;
class CTest
{
public:
CTest()
{
cout << "构造函数..." << endl;
}
~CTest()
{
cout << "析构函数..." << endl;
}
};
CTest t;
int main()
{
cout<<"--->main"<<endl;
return 0;
}
所以:
1. 全局对象的构造函数会在main 函数之前执行,
2. 全局对象的析构函数会在main函数之后执行;
181. 请你聊聊回调函数?
答案
1. 回调函数的本质是“你想让别人的代码执行你的代码,而别人的代码你又不能动”这种需求下产生的。
2. 回调函数的缺点:
回调函数是函数指针的一种用法,如果多个类都关注某个类的状态变化,此时需要维护一个列表,以存放多个回调函数的地址。对于每一个被关注的类,都需要做类似的工作,因此这种做法效率低,不灵活。
182. 请你自己实现一下读写锁
答案
class readWriteLock{
private:
std::mutex readMtx;
std::mutex writeMtx;
int readCnt;//已加读锁个数
public:
readWriteLock():readCnt(0){}
void readLock()//加读锁
{
readMtx.lock();//先锁住
if(++readCnt==1) //当时第一次加锁时,加一个写锁,防止读的过程中被更改
{
writeMtx.lock();
}
readMtx.unlock();//然后,就可以释放这个锁了。
}
void readUnlock()//释放读锁的时候
{
readMtx.lock();
if(--readCnt==0)//也要判断一下,这个是不是最后加的一个锁,如果是最后一个就把写锁给解开。
{
writeMtx.unlock();
}
readMtx.unlock();
}
void writeLock()//写锁的话,就直接加就可以了
{
writeMtx.lock();
}
void writeUnlock()//写锁的时候,如果要解锁,就直接解锁就可以了。
{
writeMtx.unlock();
}
};
183. 一个函数的各个变量的存放方式
答案
//main.cpp
int a = 0; //全局初始化区
int a = 0; //全局初始化区
char *p1; //全局未初始化区
int main() {
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //123456\0在常量区,p3在栈上。
static int c = 0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); //123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
184. Socket通讯流程
- socket 简便流程
答案
listenfd = socket(); // 打开一个网络通信端口
bind(listenfd); // 绑定
listen(listenfd); // 监听
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}

- socket详细流程
答案
1. 每个进程在PCB(Process Control Block)中保存着一份文件描述符表,文件描述符就是这个表的索引,每个表项都有一个指向已打开文件的指针。
2. socket函数:
A. int socket (int protofamily,int type,int protocol);
1)protofamily:协议族,常见的协议族有AF_INET,AF_INET6,AF_LOCAL,AF_ROUTE.
2)type: socket类型,SOCK_STREAM,SOCK_DFRAM,SOCK_RAW,SOCK_PACKET,SOCK_SEQPACKET
3) protocol:指定协议,IPPROTO_TCP.IPPTOTO_UDP,IPPROTO_SCTP.
B. int bind(int sockfd,const struct *addr,socklen_t addlen);
1)sockfd,即socket描述字
2)addr:指向要绑定给sockfd的协议地址,
a. ipv4对应的是:
struct sockaddr_in{
sa_family_t sin_familt;/* address family: AF_INET */
int_port_t sin_port;/* port in network byte order */
struct in_addr sin_addr;/* internet address */
};
/* Internet address. */
struct in_addr {
uint32_t s_addr; /* address in network byte order */
};
b. ipv6对应的是:
struct sockaddr_in6 {
sa_family_t sin6_family; /* AF_INET6 */
in_port_t sin6_port; /* port number */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* Scope ID (new in 2.4) */
};
struct in6_addr {
unsigned char s6_addr[16]; /* IPv6 address */
};
c. Unix域对应的是:
#define UNIX_PATH_MAX 108
struct sockaddr_un {
sa_family_t sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* pathname */
};
C. int listen(int sockfd, int backlog);
listen函数的第一个参数即为要监听的socket描述字,第二个参数为相应socket可以排队的最大连接个数。socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
D. int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
connect函数的第一个参数即为客户端的socket描述字,第二参数为服务器的socket地址,第三个参数为socket地址的长度。客户端通过调用connect函数来建立与TCP服务器的连接。
E. int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); //返回连接connect_fd
参数sockfd
参数sockfd就是上面解释中的监听套接字,这个套接字用来监听一个端口,当有一个客户与服务器连接时,它使用这个一个端口号,而此时这个端口号正与这个套接字关联。当然客户不知道套接字这些细节,它只知道一个地址和一个端口号。
参数addr
这是一个结果参数,它用来接受一个返回值,这返回值指定客户端的地址,当然这个地址是通过某个地址结构来描述的,用户应该知道这一个什么样的地址结构。如果对客户的地址不感兴趣,那么可以把这个值设置为NULL。
参数len
如同大家所认为的,它也是结果的参数,用来接受上述addr的结构的大小的,它指明addr结构所占有的字节个数。同样的,它也可以被设置为NULL。
如果accept成功返回,则服务器与客户已经正确建立连接了,此时服务器通过accept返回的套接字来完成与客户的通信。
F.int close(int fd);
close一个TCP socket的缺省行为时把该socket标记为以关闭,然后立即返回到调用进程。该描述字不能再由调用进程使用,也就是说不能再作为read或write的第一个参数。
注意:close操作只是使相应socket描述字的引用计数-1,只有当引用计数为0的时候,才会触发TCP客户端向服务器发送终止连接请求。
socket编程实例:
服务端:
/* File Name: server.c */
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define DEFAULT_PORT 8000
#define MAXLINE 4096
int main(int argc, char** argv)
{
int socket_fd, connect_fd;
struct sockaddr_in servaddr;
char buff[4096];
int n;
//初始化Socket
if( (socket_fd = socket(AF_INET, SOCK_STREAM, 0)) == -1 ){
printf("create socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
//初始化
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);//IP地址设置成INADDR_ANY,让系统自动获取本机的IP地址。
servaddr.sin_port = htons(DEFAULT_PORT);//设置的端口为DEFAULT_PORT
//将本地地址绑定到所创建的套接字上
if( bind(socket_fd, (struct sockaddr*)&servaddr, sizeof(servaddr)) == -1){
printf("bind socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
//开始监听是否有客户端连接
if( listen(socket_fd, 10) == -1){
printf("listen socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("======waiting for client's request======\n");
while(1){
//阻塞直到有客户端连接,不然多浪费CPU资源。
if( (connect_fd = accept(socket_fd, (struct sockaddr*)NULL, NULL)) == -1){
printf("accept socket error: %s(errno: %d)",strerror(errno),errno);
continue;
}
//接受客户端传过来的数据
n = recv(connect_fd, buff, MAXLINE, 0);
//向客户端发送回应数据
if(!fork()){ /*紫禁城*/
if(send(connect_fd, "Hello,you are connected!\n", 26,0) == -1)
perror("send error");
close(connect_fd);
exit(0);
}
buff[n] = '\0';
printf("recv msg from client: %s\n", buff);
close(connect_fd);
}
close(socket_fd);
}
客户端:
/* File Name: client.c */
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define MAXLINE 4096
int main(int argc, char** argv)
{
int sockfd, n,rec_len;
char recvline[4096], sendline[4096];
char buf[MAXLINE];
struct sockaddr_in servaddr;
if( argc != 2){
printf("usage: ./client <ipaddress>\n");
exit(0);
}
if( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0){
printf("create socket error: %s(errno: %d)\n", strerror(errno),errno);
exit(0);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8000);
if( inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0){
printf("inet_pton error for %s\n",argv[1]);
exit(0);
}//将点分十进制的Ip转成二进制的
if( connect(sockfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) < 0){
printf("connect error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("send msg to server: \n");
fgets(sendline, 4096, stdin);
if( send(sockfd, sendline, strlen(sendline), 0) < 0)
{
printf("send msg error: %s(errno: %d)\n", strerror(errno), errno);
exit(0);
}
if((rec_len = recv(sockfd, buf, MAXLINE,0)) == -1) {
perror("recv error");
exit(1);
}
buf[rec_len] = '\0';
printf("Received : %s ",buf);
close(sockfd);
exit(0);
}
185. 互斥锁的实现原理?
答案
其实锁就是一块内存,当这个空间被赋予1的时候表示被加锁了,被赋值为0的时候表示解锁了。可以用一条“无法继续分割的”汇编指令实现判断变量值,并依据是否为0进行置位。
1. X86平台中CMPXCHG(加上Lock prefix) ,能够完成atomic的compare and swap(CAS). 指令中加了Lock前缀,意味着锁定总线实现atomicity.
2. linux上是实现futex。OS需要一些全局数据结构来记录被挂起线程和对应的锁之间的关系。
186. 如何让类对象只在栈或堆上分配空间?
答案
在C++中,类的对象建立分为两种,一种是静态建立,如A a;另一种是动态建立,如A* ptr=new A;
1、静态建立类对象:是由编译器为对象在栈空间中分配内存,是通过直接移动栈顶指针,挪出适当的空间,然后在这片内存空间上调用构造函数形成一个栈对象。使用这种方法,直接调用类的构造函数。
2、动态建立类对象:是使用new运算符将对象建立在堆空间中。这个过程分为两步,第一步是执行operator new()函数,在堆空间中搜索合适的内存并进行分配;第二步是调用构造函数构造对象,初始化这片内存空间。这种方法,间接调用类的构造函数。
187. 封装、继承、多态的概念?
答案
1、封装
1) 结合性: 将数据和操作数据的方法进行结合。
2)信息隐蔽性:利用接口机制隐藏内部实现细节,只留下接口给外界调用。
3)实现代码重用。
2、继承
指的是从已有类产生新类的过程。
3、多态
简单概况就是“一个接口,多种方法",使用同一个接口,但效果各不相同。多态还有静态多态和动态多态之分。
188. 面向过程和面向对象的区别
答案
1、面向过程:分析出解决问题的步骤,然后用函数将这些步骤一步一步实现,使用的时候一个一个调用即可。
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展
2、面向对象: 把问题的事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述整个解决问题的步骤中的行为。
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护
缺点:性能比面向过程低
189. O0、O1、O2、O3优化
答案
1、O0: 不做任何优化。
2、O1: 主要对代码的分支、常量、表达式进行优化,减少代码的尺寸,缩短执行周期。
3、O2: 在O1打开的基础上,尝试更多寄存器级的优化以及指令级的优化。
4、O3: 在O2的基础上,例如使用伪寄存器网络,普通函数的内联。
190. 如何定义一个只能在堆上(栈上)生成对象的类?
答案
1、在c++中,建立对象有两种方式,分为静态建立和动态建立:
//静态建立
A a;
//动态建立
A *a = new A;
1)静态建立对象:由编译器自动在栈中分配内存,直接移动栈顶指针,腾出适当的空间,然后再在这片空间上调用构造函数生成对象,这种静态建立是直接调用类的构造函数。
2)动态建立对象:程序员使用new运算符在堆中建立。过程分两步,第一步是调用Operator new函数在堆空间搜索出来适当的内存并进行分配;第二部是调用构造函数生成对象,初始化这片内存空间,间接调用构造函数。
2、只能在堆上生成对象的类:
1)只能在堆上也就意味着不能再栈上,在栈上是编译器分配内存空间,构造函数来构造栈对象。在栈上当对象周期完成,编译器会调用析构函数来释放栈对象所占的空间,也就是说编译器管理了对象的整个生命周期。
2)编译器在调用构造函数为类的对象分配空间时,会先检查析构函数的访问性,不光是析构函数,编译器会检查所有非静态函数的访问性。
3)因此,如果类的析构函数是私有的,编译器不会为对象在栈上分配内存空间。
所以比较合适的是这种方式:
class A {
protected:
A() { cout << "constructor" << endl; }
~A() { cout << "destructor" << endl; }
public:
static A * create()
{
return new A();
}
void destory()
{
delete this;
}
};
A * p1 = A::create();
cout << &(*p1) << endl;
p1->destory();
把构造函数,析构函数都弄为protected.自己是可以调用的,也保证了自己的子类也是可以调用的。但是防止了编译器的调用。这样就可以实现只能在堆上建立对象了。
3、只能在栈上生成对象:
只有使用New运算符,对象才会建立在堆上,因此禁用new就可实现。将operator new()重载设为私有即可。
class D{
private:
void *operator new(size_t){}
void operator delete(void *ptr){}
public:
D(){}
~D(){}
}
//error:函数不可访问
D *P4 = new D;
191. 什么不能被继承?
答案
1、构造函数不能被继承
1)
192. 内存泄漏相关知识
1、内存泄漏的原因?
答案
1、malloc/new 和delete/free没有匹配。
2、new[]和delete[]也没有匹配。
3、没有将父类的析构函数定义为虚函数,当父类的指针指向子类对象时,delete该对象不会调用子类的析构函数。
2、检测手段
答案
1、良好的程序设计能力,将new都放在构造函数中,将delete都放在析构函数中。保证任何资源的释放都在析构函数中进行。
2、智能指针。
3、valgrind,这个可以打印出发生内存泄漏的代码。
4、linux使用swap命令观察还有多少可以用的交换空间,两三分钟内执行三四次,肉眼观察是否变小了。 `free -m`查看swap的大小。
5、使用netstat、vmstat等。如果发现波段中有内存被分配且没有被释放,有可能进程出现了内存泄漏。
`netstat -natp`
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
3、ValGrind的使用
193、什么是原子操作?
答案
所谓的原子操作,取的就是“原子是最小的、不可分割的最小个体”的意义,它表示在多个线程访问同一个全局资源的时候,能够确保所有其他的线程都不在同一时间内访问相同的资源。也就是他确保了在同一时刻只有唯一的线程对这个资源进行访问。这有点类似互斥对象对共享资源的访问的保护,但是原子操作更加接近底层,因而效率更高。
互斥对象的使用,保证了同一时刻只有唯一的一个线程对这个共享进行访问,从执行的结果来看,互斥对象保证了结果的正确性,但是也有非常大的性能损失
在以往的C++标准中并没有对原子操作进行规定,我们往往是使用汇编语言,或者是借助第三方的线程库,例如intel的pthread来实现。在新标准C++11,引入了原子操作的概念,并通过这个新的头文件提供了多种原子操作数据类型,例如,atomic_bool,atomic_int等等,如果我们在多个线程中对这些类型的共享资源进行操作,编译器将保证这些操作都是原子性的,也就是说,确保任意时刻只有一个线程对这个资源进行访问,编译器将保证,多个线程访问这个共享资源的正确性。从而避免了锁的使用,提高了效率。
194、Qt信号槽实现的底层原理
1、moc预编译在干嘛
1、moc的全称是:Meta-Object-Compile “元对象编译器”。当我们编译C++文件时,如果类中函数Q_OBJECT 的话,则会生成另一个c++源文件,也就是我们经常看到的moc_xxx文件。
2、moc预编译帮助我们构建了信号槽回调的开头(信号函数体)和结尾(qt_static_metacall回调函数),中间的回调过程Qt已经在QOjbect函数中实现。
2、signals和slots关键字产生的理由
1、当编译器检测到signals这个关键时,就知道我们是在定义信号,它帮助我们实现了信号的实现体。同样,slots关键词也是这么个道理。
2、signals和slots就是为了方便moc解析我们的C++文件,从中解析出信号和槽
3、信号槽连接方式有什么区别
- Qt::AutoConnection 自动连接,根据sender和receiver是否在一个线程里来决定使用哪种连接方式,同一个线程使用直连,否则使用队列连接
- Qt::DirectConnection 直连
- Qt::QueuedConnection 队列连接:使用该类型,槽函数的执行是通过抛出QMetaCallEvent事件,经过Qt的事件循环达到异步的效果
- Qt::BlockingQueuedConnection 阻塞队列连接,顾名思义,虽然是跨线程的,但是还是希望槽执行完之后,才能执行信号的下一步代码
- Qt::UniqueConnection 唯一连接
4、信号和槽函数有什么区别
1、信号和槽本质上是一样的,但是对于使用者来说,信号只需要声明,moc帮你实现,槽函数声明和实现都需要自己写
5、connect到底干了什么
1、构造了一个Connection来存储“发送者、发送者信号索引、接收者、槽函数”。
2、信号槽连接后在内存中以QObjectConnectionListVector对象存储,这是一个数组,Qt巧妙的借用了数组快速访问指定元素的方式,把信号所在的索引作为下标来索引他连接的Connection对象。
3、connect方法就是把发送者、信号、接受者和槽存储起来,供后续执行信号时查找
6、信号触发原理
信号触发就是一系列函数回调

195、找出数组中次数最多的数
#include <unodered_map>
#include <queue>
vector<int> topKFrequent(vector<int>& nums, int k)
{
//<unordered_map>
//key-value == 数组值-频率
unordered_map<int, int> map;
for (int num : nums)//简单的循环方法
{
map[num]++;//求出每一个数的出现的频率value,类比灰度分布图
}
vector<int> res;
//<queue>
// pair<first, second>: first is frequency, second is number
priority_queue<pair<int, int>> pq;
for (auto it = map.begin(); it != map.end(); it++)
{
pq.push(make_pair(it->second, it->first));//按频率进行排序即it->second
if (pq.size() > (int)map.size() - k)//找到前k个频率最大的数
{
res.push_back(pq.top().second);
pq.pop();
}
}
return res;
}
总结
本篇文章是自己在平常阅读八股文时所做的笔记。毕竟这也是一条通往大厂的必经之路。文章中的大部分都是来源于网络中搜索的答案。如果有记得加参考的话,就有加。不记得的话,就可能只是摘抄过来,请见谅,若实在介意,请留言,一定马上删掉。希望这篇文章能帮到大家~可以的话帮我点个赞噢!! 你的Star是作者坚持下去的最大动力!!!

参考
- const修饰符总结
- C++ 类内常量定义 static const
- 单继承、多继承、菱形继承的虚函数表
- [C++中函数调用时的三种参数传递方式详解](https://blog.csdn.net/ccblogger/article/details/77752659]()
- C++八股文
- 引用的本质

 浙公网安备 33010602011771号
浙公网安备 33010602011771号