
Redis系列(四):Redis的复制机制(主从复制)
2020-04-07 09:41 申城异乡人 阅读(1694) 评论(0) 收藏 举报本篇博客是Redis系列的第4篇,主要讲解下Redis的主从复制机制。
本系列的前3篇可以点击以下链接查看:
Redis系列(三):Redis的持久化机制(RDB、AOF)
Redis的主从复制是面试中经常会被问的,我最近面试的几家公司只要聊到Redis,都会问我主从复制的原理。
1. 为什么需要主从复制?
在本系列的上一篇博客中,我们讲到了Redis的持久化机制,它很好的解决了单台Redis服务器由于意外情况导致Redis服务器进程退出或者Redis服务器宕机而造成的数据丢失问题。
但持久化机制还原数据有个前提:你的Redis服务器得能正常启动。
如果遇到极端的断电情况(虽然概率小,但是有可能),Redis服务器启都启动不了,怎么还原数据?怎么保证它的高可用。
就算Redis服务器能启动了,网络连接也有崩掉的可能,我不信你没看到过电缆被挖断导致的某些服务不可用的新闻。
正是由于有这样的风险,所以生产环境Redis服务器不可能使用单台的,那既然使用多台Redis服务器,多台Redis服务器之间的数据如何同步呢?
这就需要用到Redis的复制机制。
还有个原因就是,虽然Redis的性能很好,但单台毕竟还是有瓶颈的,使用主从复制可以实现读写分离,提高Redis的高可用性,即主服务器用来执行写命令,多个从服务器用来执行读命令,类似于数据库的读写分离。
综上所述,主从复制主要有以下2个使用场景:
- 数据备份
- 读写分离
2. 主从复制实践
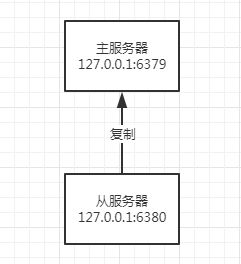
首先,我在本机开启2个Redis实例(也可以搞2台Redis服务器),分别为127.0.0.1:6379、127.0.0.1:6380。
然后,使用redis-cli连接Redis实例127.0.0.1:6380并执行如下命令:
SLAVEOF 127.0.0.1 6379

此时,我们称127.0.0.1:6379为127.0.0.1:6380的主服务器(master),称127.0.0.1:6380为127.0.0.1:6379的从服务器(slave)。
2者之间的关系如下所示:
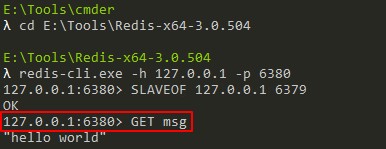
然后,我们在主服务器上执行如下写命令:
SET msg "hello world"
此时,我们不仅能在主服务器上获取到该值,也能在从服务器上获取到该值:

然后,我们在主服务器上执行如下删除命令:
DEL msg
此时,我们会发现不仅主服务器上的msg键被删除,从服务器上的msg也被删除:
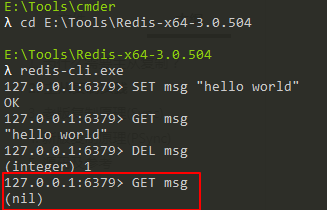
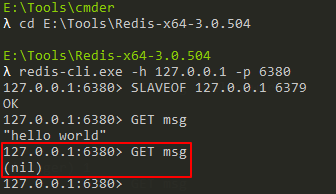
所以说,进行复制中的主从服务器双方的数据库将保存相同的数据。
值得注意的是,从服务器只能执行读命令,执行写命令时会报如下错误:

如果从服务器不想再复制主服务器,可以执行命令:SLAVEOF no one。
3. 旧版复制功能的实现(SYNC)
这里的旧版指的是Redis 2.8以前的版本。
Redis的复制功能分为以下2个操作:
- 同步:用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
- 命令传播:用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态不一致时,让主从服务器的数据库状态重新回到一致状态。
3.1 同步
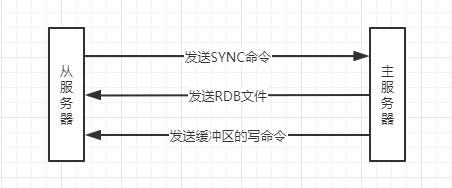
当客户端向从服务器发送SLAVEOF命令,要求从服务器复制主服务器时,从服务器会向主服务器SYNC命令,该命令的执行步骤如下所示:
- 从服务器向主服务器发送
SYNC命令。 - 主服务器收到
SYNC命令后,执行BGSAVE命令,在后台生成RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令。 - 当主服务器的
BGSAVE命令执行完成,主服务器将生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,至此,从服务器的数据库状态和主服务器执行BGSAVE命令时的数据库状态一致。 - 主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器接收并执行这些写命令,至此,从服务器的数据库状态和主服务器当前的数据库状态一致。
SYNC命令执行期间,主从服务器的通信过程如下图所示:
3.2 命令传播
在同步操作执行完毕后,主从服务器的数据库状态达到一致状态,当主服务器执行了客户端发送的写命令时,主服务器的数据库就被修改了,导致主从服务器的数据库状态不再一致。
为了让主从服务器的数据库状态再次回到一致状态,主服务器需要对从服务器执行命令传播操作:主服务器会将自己执行的写命令,发送给从服务器执行,当从服务器执行了相同的写命令后,主从服务器的数据库状态再次回到一致状态。
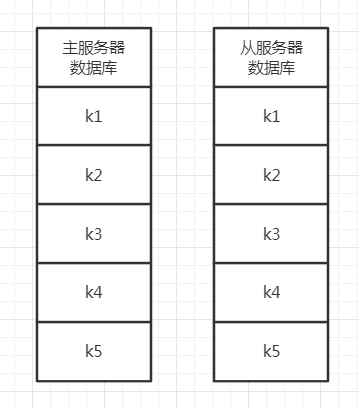
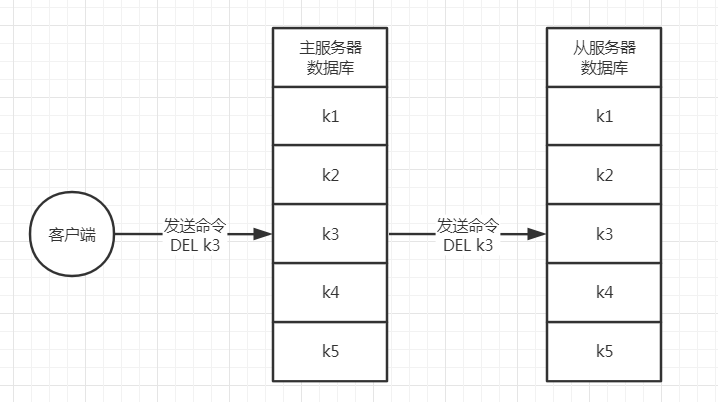
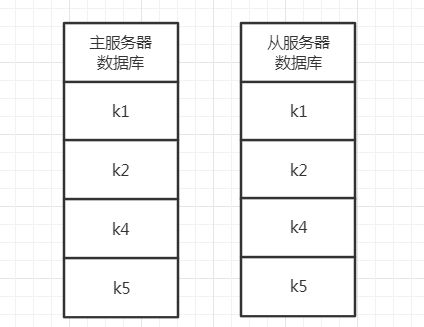
举个具体的例子,比如主从服务器刚开始都拥有k1、k2、k3、k4、k5这5个键,然后客户端往主服务器发送了命令DEL k3,此时主服务器会执行该条命令,并将该条命令传播给从服务器执行,从而使主从服务器的数据库状态保持一致。
整个变化过程如下所示:
4. 旧版复制功能的缺陷
这里的旧版指的是Redis 2.8以前的版本。
在Redis 2.8以前,从服务器对主服务器的复制分为以下2种情况:
-
初次复制
从服务器以前没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同。
-
断线后重复制
处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过重试又重新连上了主服务器,并继续复制主服务器。
旧版复制功能可以很好的完成初次复制,但完成断线后重复制的效率却很低。
举个具体的例子,从服务器B一直在复制着主服务器A,刚开始都是正常的,主服务器A执行的写命令也都通过命令
传播的方式传递给了从服务器B执行,但突然因为网络原因,主服务器A和从服务器B之间中断了复制,在这期间,
假设主服务器又执行了10个写命令,然后从服务器B通过重试又重新连上了主服务器A,继续开始复制,那么它是
怎么复制的呢?
从服务器B会向主服务器A发送SYNC命令,主服务器A接收到命令后会执行BGSAVE命令,BGSAVE命令执行期间的
所有写命令会被记录到缓冲区,待BGSAVE命令执行完毕后,主服务器A会将生成的RDB文件发送给从服务器B,
从服务器B接收并载入这个RDB文件,然后主服务器A将缓冲区里的写命令发送给从服务器B执行,至此,主从
服务器的数据库状态又恢复一致,后续又进入命令传播阶段。
也就是说,每次断线后重复制,都要执行一次SYNC命令来一次全量复制,但其实从服务器B需要的只是断开连接期间主服务器A执行的写命令,按上面的例子,也就是只需要10个写命令即可。
而SYNC命令又是一个非常耗费资源的操作:
- 主服务器需要执行
BGSAVE命令生成RDB文件,这会耗费主服务器大量的CPU、内存和磁盘IO资源。 - 主服务器需要将生成的RDB文件发送给从服务器,这会耗费主从服务器大量的网络资源(带宽和流量)。
- 接收到RDB文件的从服务器需要载入RDB文件,在载入期间,从服务器会阻塞,没办法处理命令请求。
5. 新版复制功能的实现(PSYNC)
这里的新版指的是Redis 2.8以及之后的版本。
从Redis 2.8版本开始,Redis使用PSYNC命令代替SYNC命令来执行复制时的同步操作。
PSYNC命令有以下2种场景:
-
完整重同步
完整重同步用于处理初次复制,执行步骤和
SYNC命令的执行步骤基本一样。 -
部分重同步
部分重同步用于处理断线后重复制,当从服务器在断线后重新连接主服务器时,如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。
仍然用上面举的例子,新版复制,主服务器只需要把断开期间执行的10个写命令发送给从服务器即可,而不用生成并发送整个RDB文件,性能大大提升。
主从服务器在执行部分重同步时的通信过程如下图所示:
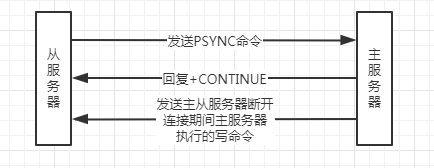
那么部分重同步是如何实现的呢?
部分重同步功能由以下3个部分组成:
- 主服务器和从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 服务器的运行ID
接下来我们一一讲解。
5.1 复制偏移量
执行复制的主服务器和从服务器会分别维护一个复制偏移量:
- 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N。
- 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
举个例子,假设主服务器有3个从服务器,它们的复制偏移量都为10086,如下图所示:
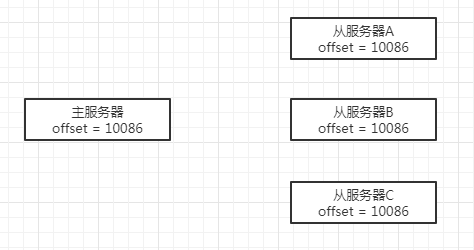
然后,主服务器向3个从服务器传播了长度为33字节的数据,那么主服务器的复制偏移量会加上33,变为10119,
从服务器A在这时刚好断线了,没有接收到数据,所以偏移量仍然为10086,
从服务器B和从服务器C正常接收到了数据,所以偏移量都更新为了10019,如下图所示:

很显然,通过对比主从服务器的复制偏移量,可以很容易地知道主从服务器是否处于一致状态。
然后,从服务器A通过重试又重新连接到了主服务器,然后向主服务器发送PSYNC命令,并报告了自己当前的复制
偏移量为10086,主服务器此时需要处理2个问题:
- 该对从服务器A执行完整重同步还是部分重同步?
- 如果执行部分重同步,主服务器从哪里获取到断线期间从服务器A丢失的数据?
带着这2个问题,我们看下复制积压缓冲区。
5.2 复制积压缓冲区
复制积压缓冲区是主服务器维护的一个固定长度先进先出队列,默认大小为1MB。
当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区,如下图所示:
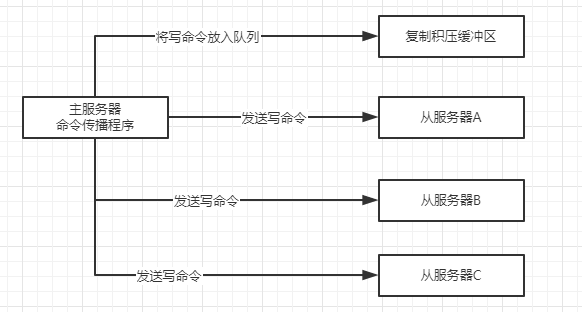
所以,主服务器的复制积压缓冲区会保存着一部分最近传播的写命令,并且为队列中的每个字节记录相应的复制偏移量,如下所示:
| 偏移量 | ... | 10087 | 10088 | 10089 | 10090 | 10091 | ... |
|---|---|---|---|---|---|---|---|
| 字节值 | ... | '*' | 3 | '\r' | '\n' | '$' | ... |
当从服务器重新连接上主服务器时,会通过PSYNC命令将自己的复制偏移量offset发送给主服务器,主服务器会根据以下规则来决定对从服务器执行何种同步操作:
- 如果offset偏移量之后的数据仍然存在于复制积压缓冲区,那么主服务器将对从服务器执行部分重同步操作。
- 如果offset偏移量之后的数据已经不存在于复制积压缓冲区,那么主服务器将对从服务器执行完整重同步操作。
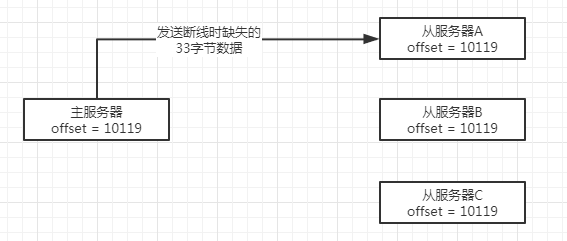
回到之前的例子:
- 从服务器A重新连接上主服务器,向主服务器发送
PSYNC命令,报告自己的复制偏移量为10086。 - 主服务器收到
PSYNC命令以及偏移量10086之后,会检查偏移量10086之后的数据是否存在于复制积压缓冲区,结果发现数据还在,于是主服务器向从服务器A发送+CONTINUE回复,表示数据同步将以部分重同步模式来进行。 - 接着主服务器会将复制积压缓冲区里10086偏移量之后的所有数据(偏移量为10087到10119)都发送给从服务器A。
- 从服务器A接收这33字节的缺失数据,就回到与主服务器一致的状态。
5.3 服务器运行ID
每个Redis服务器,不论主服务器还是从服务器,都会有自己的运行ID,运行ID在服务器启动时自动生成,由40个十六进制字符组成,如下图所示:
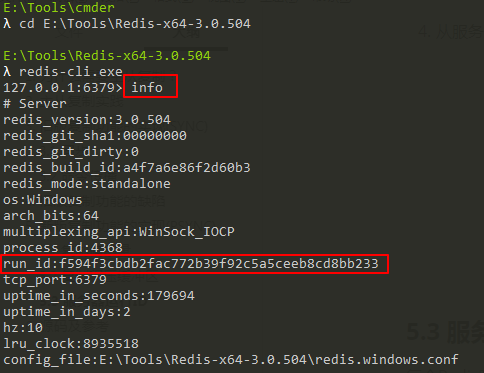
当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,从服务器会将这个运行ID保存起来。
当从服务器断线并重新连接上主服务器时,从服务器会把之前保存的运行ID发送给当前连接的主服务器:
- 如果从服务器之前保存的运行ID和当前连接的主服务器的运行ID相同,说明从服务器断线前后复制的是同一台主服务器,主服务器可以继续尝试执行部分重同步操作。
- 如果从服务器之前保存的运行ID和当前连接的主服务器的运行ID不相同,说明从服务器断线前后复制的不是同一台主服务器,主服务器将对从服务器执行完整重同步操作。
5.4 PSYNC命令执行细节
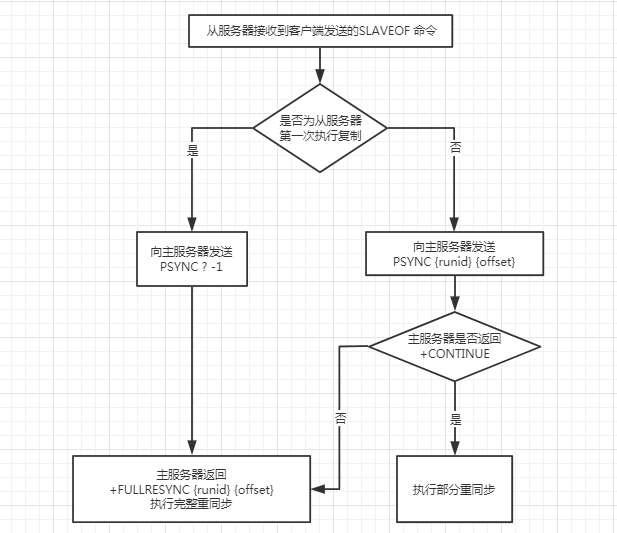
对于从服务器来说,调用PSYNC命令有以下2种情况:
-
如果从服务器以前没有复制过任何主服务器,或者之前执行过
SLAVEOF on one命令,那么从服务器在开始一次新的复制时将向主服务器发送PSYNC ? -1命令,主动请求主服务器进行完整重同步。 -
如果从服务器已经复制过某个主服务器,那么从服务器在开始一次新的复制时将向主服务器发送
PSYNC {runid} {offset}命令,其中runid是上一次复制的主服务器的运行ID,offset是从服务器当前的复制偏移量。
对于主服务器来说,接收到PSYNC命令后会向从服务器返回以下3种回复中的一种:
- 如果主服务器返回
+FULLRESYNC {runid} {offset},表示主服务器将与从服务器执行完整重同步操作,其中runid是主服务器的运行ID,从服务器会将这个ID保存起来,在下一次发送PSYNC命令时使用,offset是主服务器当前的复制偏移量,从服务器会将这个值作为自己的初始化偏移量。 - 如果主服务器返回
+CONTINUE,表示主服务器将与从服务器执行部分重同步操作,主服务器会将从服务器缺少的那部分数据发送给从服务器。 如果主服务器返回-ERROR,表示主服务器的版本低于Redis 2.8,它识别不了PSYNC命令,从服务器将向主服务器发送SYNC命令,并与主服务器执行完整重同步操作。
以上描述流程可以使用以下流程图来表示:
6. 源码及参考
黄健宏 《Redis设计与实现》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号