
Hadoop
一、简介
Hadoop是目前最流行的大数据软件框架之一,它能利用简单的高级程序对大型数据集进行分布式存储和处理。
Hadoop是阿帕奇(Apache)软件基金会发布的一个开源项目,它可以安装在服务器集群上,通过服务器之间的通信和协同工作来存储和处理大型数据集。因为能够高效地处理大数据,Hadoop近几年获得了巨大的成功。它使得公司可以将所有数据存储在一个系统中,并对这些数据进行分析,而这种规模的大数据分析用传统解决方案是无法实现或实现起来代价巨大的。
以Hadoop为基础开发的大量工具提供了各种各样的功能,Hadoop还出色地集成了许多辅助系统和实用程序,使得工作更简单高效。这些组件共同构成了Hadoop生态系统。
Hadoop可以被视为一个大数据操作系统,它能在所有大型数据集上运行不同类型的工作负载,包括脱机批处理、机器学习乃至实时流处理。
您可以访问http://hadoop.apache.org网站获取有关该项目的更多信息和详细文档。
您可以从http://hadoop.apache.org获取代码(推荐使用该方法)来安装Hadoop,或者选择Hadoop商业发行版。最常用的三个商业版有Cloudera(CDH)、Hortonworks(HDP)和MapR。这些商业版都基于Hadoop的框架基础,将一些组件进行了打包和增强,以实现较好的集成和兼容。此外,这些商业版还提供了管理和监控平台的(开源或专有的)工具。
二、Hadoop发挥着什么样的作用?
在传统思维中,程序的运行只占用运行程序主机的计算资源,例如CPU和内存;文件只占用所在主机的磁盘存储。而Hadoop可以利用多台机器组成集群,从而提供「分布式计算和分布式存储的能力」。
三、组件
Hadoop有两个核心组件:
- HDFS:分布式文件系统
- YARN:集群资源管理技术
许多执行框架运行在YARN之上,每个框架都针对特定的用例进行调优。下文将在“YARN应用程序”中重点讨论。
我们来看看它们的架构,了解一下它们是如何合作的。
HDFS(Hadoop Distributed File System)
HDFS是Hadoop分布式文件系统。
它可以在许多服务器上运行,根据需要,HDFS可以轻松扩展到数千个节点和乃至PB(Petabytes 10的15次方字节)量级的数据。
HDFS设置容量越大,某些磁盘、服务器或网络交换机出故障的概率就越大。
HDFS通过在多个服务器上复制数据来修复这些故障。
HDFS会自动检测给定组件是否发生故障,并采取一种对用户透明的方式进行必要的恢复操作。
HDFS是为存储数百兆字节或千兆字节的大型文件而设计的,它提供高吞吐量的流式数据访问,一次写入多次读取。因此对于大型文件而言,HDFS工作起来是非常有魅力的。但是,如果您需要存储大量具有随机读写访问权限的小文件,那么RDBMS和Apache HBASE等其他系统可能更好些。
注:HDFS不允许修改文件的内容。只支持在文件末尾追加数据。不过,Hadoop将HDFS设计成其许多可插拔的存储选件之一。例如:专用文件系统MapR-Fs的文件就是完全可读写的。其他HDFS替代品包括Amazon S3、Google Cloud Storage和IBM GPFS等。
与HDFS交互
HDFS提供了一个简单的类似POSIX的接口来处理数据。使用HDFS DFS命令执行文件系统操作。
要开始使用Hadoop,您不必经历设置整个集群的过程。Hadoop可以在一台机器上以
所谓的伪分布式模式运行。您可以下载sandbox虚拟机,它自带所有HDFS组件,使您可以随时开始使用Hadoop!只需按照以下链接之一的步骤:
- http://mapr.com/products/mapr-sandbox-hadoop
- hortonworks.eom/products/hortonworks-sandbox/#install
- http://cloudera.com/downloads/quickstart_vms/5-12.html
HDFS用户可以按照以下步骤执行典型操作:
- 列出主目录的内容: $ hdfs dfs -ls /user/adam
- 将文件从本地文件系统加载到HDFS: $ hdfs dfs -put songs.txt /user/adam
- 从HDFS读取文件内容: $ hdfs dfs -cat /user/adam/songs.txt
- 更改文件的权限: $ hdfs dfs -chmod 700 /user/adam/songs.txt
- 将文件的复制因子设置为4: $ hdfs dfs -setrep -w 4 /user/adam/songs.txt
- 检查文件的大小: '$ hdfs dfs -du -h /user/adam/songs.txt Create a subdirectory in your home directory. $ hdfs dfs -mkdir songs
注意,相对路径总是引用执行命令的用户的主目录。HDFS上没有“当前”目录的概念(换句话说,没有“CD”命令):
- 将文件移到新创建的子目录: $ hdfs dfs -mv songs.txt songs
- 从HDFS中删除一个目录: $ hdfs dfs -rm -r songs
注:删除的文件和目录被移动到trash中 (HDFS上主目录中的.trash),并保留一天才被永久删除。只需将它们从.Trash复制或移动到原始位置即可恢复它们。
您可以在没有任何参数的情况下键入HDFS DFS以获得可用命令的完整列表。
如果您更喜欢使用图形界面与HDFS交互,您可以查看免费的开源HUE (Hadoop用户体验)。它包含一个方便的“文件浏览器”组件,允许您浏览HDFS文件和目录并执行基本操作。
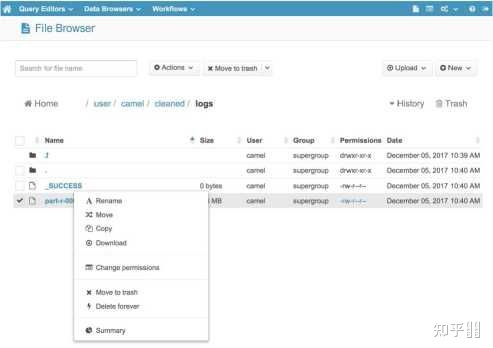
您也可以使用HUE的“上传”按钮,直接从您的计算机上传文件到HDFS。
YARN
YARN (另一个资源协商器)负责管理Hadoop集群上的资源,并允许运行各种分布式应用程序来处理存储在HDFS上的数据。
YARN类似于HDFS,遵循主从设计,ResourceManager进程充当主程序,多个NodeManager充当工作人员。它们的职责如下:
ResourceManager
- 跟踪集群中每个服务器上的LiveNodeManager和可用计算资源的数量。
- 为应用程序分配可用资源。
- 监视Hadoop集群上所有应用程序的执行情况。
NodeManager
- 管理Hadoop集群中单个节点上的计算资源(RAM和CPU)。
- 运行各种应用程序的任务,并强制它们在限定的计算资源范围之内。
YARN以资源容器的形式将集群资源分配给各种应用程序,这些资源容器代表RAM数量和CPU核数的组合。
在YARN集群上执行的每个应用程序都有自己的ApplicationMaster进程。当应用程序被安排在集群上并协调此应用程序中所有任务的执行时,此过程就开始了。
HADOOP = HDFS + YARN
在同一个集群上运行的HDFS和YARN为我们提供了一个存储和处理大型数据集的强大平台。
DataNode和NodeManager进程配置在相同的节点上,以启用本地数据。这种设计允许在存储数据的机器上执行计算,从而将通过网络发送大量数据的必要性降到最低,使得执行时间更快。
YARN 应用程序
YARN仅仅是一个资源管理器,它知道如何将分布式计算资源分配给运行在Hadoop集群上的各种应用程序。换句话说,YARN本身不提供任何处理逻辑来分析HDFS中的数据。因此,各种处理框架必须与YARN集成(通过提供ApplicationMaster实现),以便在Hadoop集群上运行,并处理来自HDFS的数据。
下面介绍几个最流行的分布式计算框架,这些框架都可以在由YARN驱动的Hadoop集群上运行。
- MapReduce:Hadoop的最传统和古老的处理框架,它将计算表示为一系列映射和归约的任务。它目前正在被更快的引擎,如Spark或Flink所取代。
- Apache Spark:用于处理大规模数据的快速通用引擎,它通过在内存中缓存数据来优化计算(下文将详细介绍)。
- Apache Flink:一个高吞吐量、低延迟的批处理和流处理引擎。它以其强大的实时处理大数据流的能力脱颖而出。下面这篇综述文章介绍了Spark和Flink之间的区别:http://dzone.com/ports/apache-Hadoop-vs-apache-smash
- Apache Tez:一个旨在加速使用Hive执行SQL查询的引擎。它可在Hortonworks数据平台上使用,在该平台中,它将MapReduce替换为Hive.k的执行引擎。
监控YARN应用程序
使用ResourceManager WebUI可以跟踪运行在Hadoop集群上的所有应用程序的执行情况,默认情况下,它在端口8088。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号