一、神经网络
1、神经网络

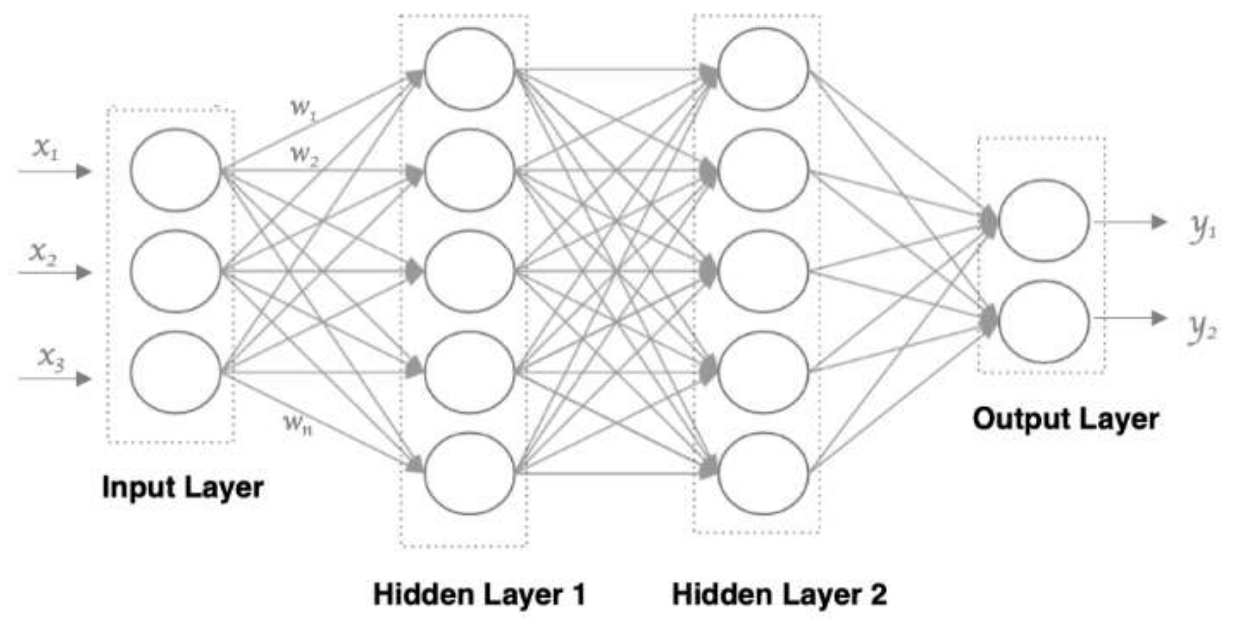
1. 输入层: 即输入 x 的那一层
2. 输出层: 即输出 y 的那一层
3. 隐藏层: 输入层和输出层之间都是隐藏层
神经网络络是什么?
• 第 N 层的每个神经元和第 N-1层 的所有神经元相连(这就是full connected的含义),这就是全连接神经网络。
• 第N-1层神经元的输出就是第N层神经元的输入。
• 每个连接都有一个权重值(w系数和b系数)。
2、激活函数
激活函数用于对每层的输出数据进行变换, 进而为整个网络注入了非线性因素。此时, 神经网络就可以拟合各种曲线。
2. 通过给网络输出增加激活函数, 实现引入非线性因素, 使得网络模型可以逼*任意函数, 提升网络对复杂问题的拟合能力.
如果不使用激活函数,整个网络虽然看起来复杂,其本质还相当于一种线性模型,如下公式所示:
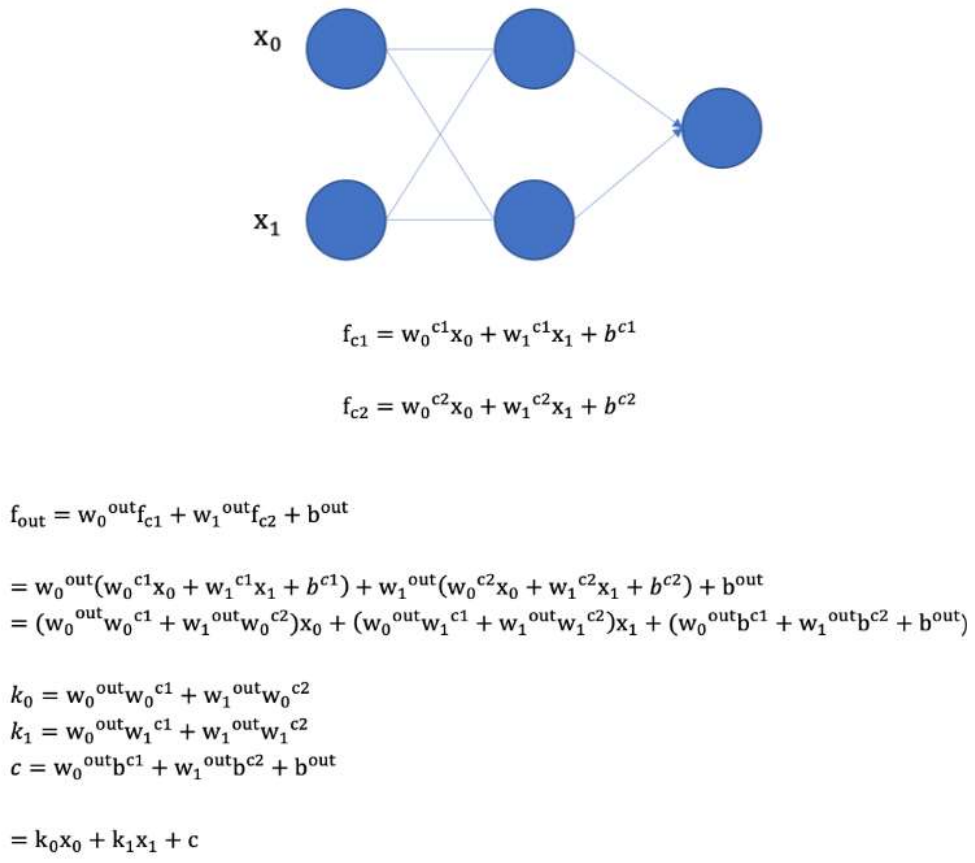 、
、
常见的激活函数-sigmoid 激活函数
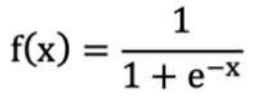

导数图像如下:
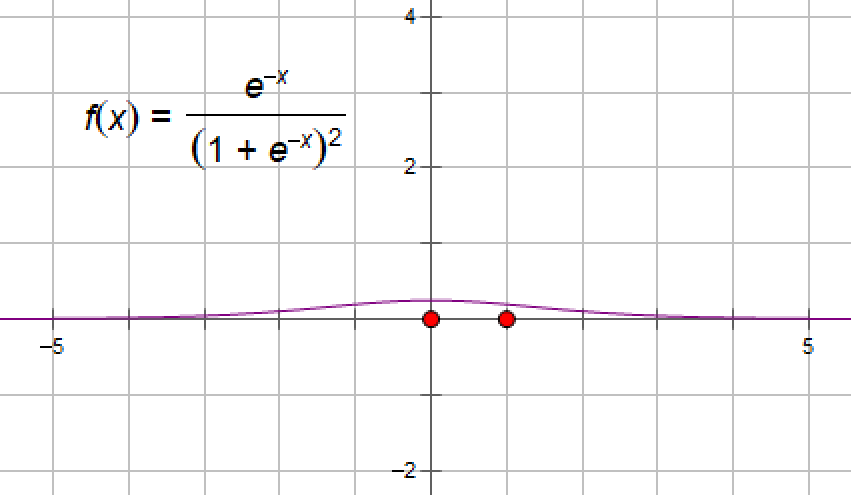
⚫ 对于 sigmoid 函数而言,输入值在 [-6, 6] 之间输出值才会有明显差异,输入值在 [-3, 3] 之间才会有比较好的效果。
⚫ 通过上述导数图像,我们发现导数数值范围是 (0, 0.25),当输入 <-6 或者 >6 时,sigmoid 激活函数图像的导数接*为 0,此时网络参数将更新极其缓慢,或者无法更新。
⚫ 一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
使用pytorch画sigmoid函数及其导函数的图像
import torch import matplotlib.pyplot as plt # 创建画布和坐标轴 _, axes = plt.subplots(1, 2) # 允许我们在一个图形窗口中创建多个子图。创建一个包含1行2列子图的图形 # 函数图像 x = torch.linspace(-20, 20, 1000) # 将[-20,20]范围分割成1000段 # 输入值x通过sigmoid函数转换成激活值y y = torch.sigmoid(x) axes[0].plot(x, y) # 在第一个轴上画图 axes[0].grid() # 在坐标轴上添加网格线 axes[0].set_title('Sigmoid 函数图像') # 导数图像 #在调用.backward()之前,你需要确保相关张量的requires_grad属性为True,否则它们不会跟踪梯度信息。 x = torch.linspace(-20, 20, 1000, requires_grad=True) torch.sigmoid(x).sum().backward() # 计算sigmoid函数之后对结果求和,然后执行反向传播计算梯度。 # x.detach():输入值x的数值 # x.grad:计算梯度,求导 axes[1].plot(x.detach(), x.grad) # 使用detach()创建一个新的张量,但不参与梯度计算 axes[1].grid() # 在坐标轴上添加网格线 axes[1].set_title('Sigmoid 导数图像') plt.show()
结果:
常见的激活函数 -tanh 激活函数

或者 tanh(x)=(ex - e-x) / (ex + e-x)
tanh'(x)=[(ex - e-x)'(ex + e-x) - (ex - e-x)(ex + e-x)']/(ex + e-x)2 =[(ex + e-x)2 - (ex - e-x)2] / (ex + e-x)2 =4/ (ex + e-x)2 = 4e2x /(ex + e-x)2 e2x = 4e2x/(e2x+1)2


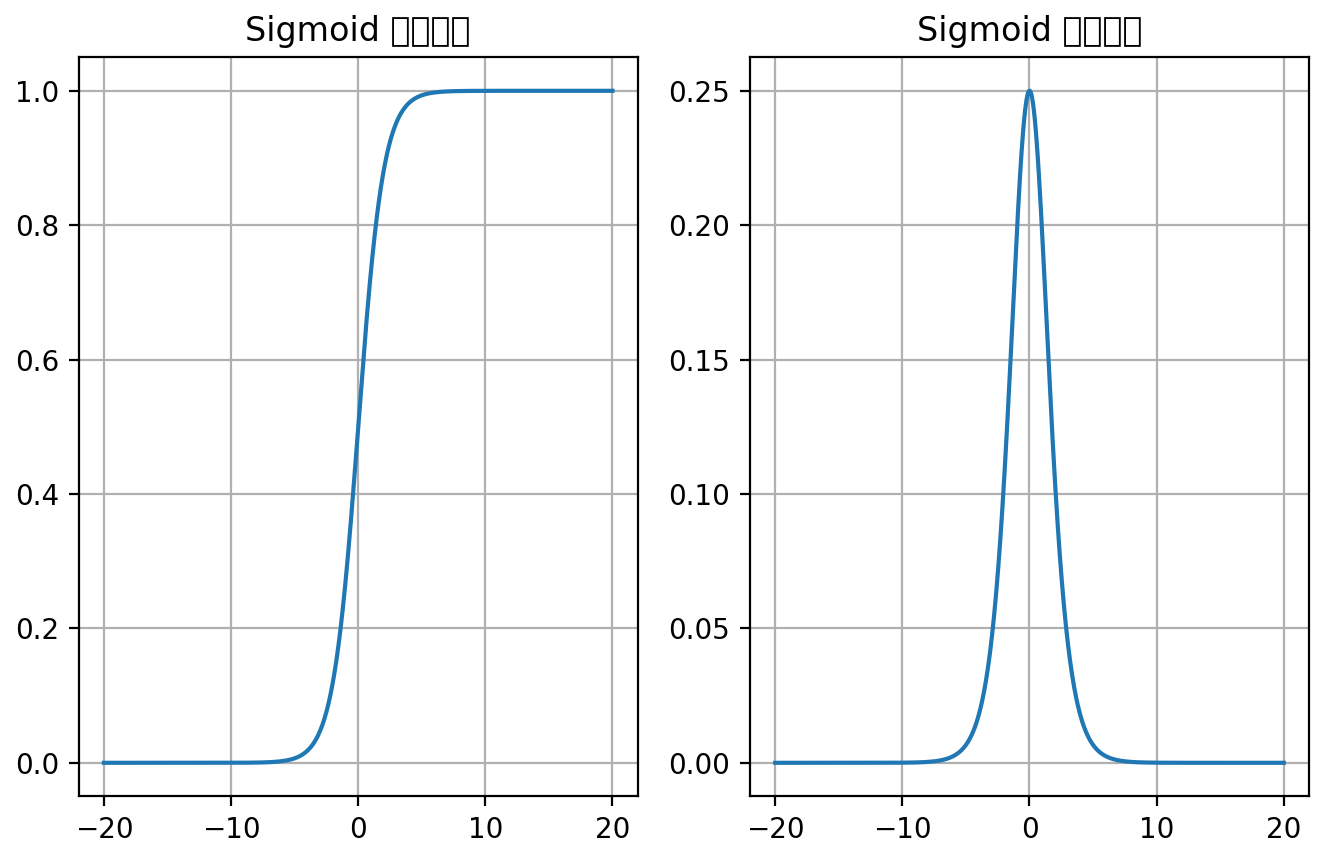
⚫ Tanh 函数将输入映射到 (-1, 1) 之间,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者>3 时将被映射为 -1 或者 1。其导数值范围 (0, 1),当输入的值大概 <-3 或者 > 3 时,其导数*似 0。
⚫ 与 Sigmoid 相比,它是以 0 为中心的,且梯度相对于sigmoid大,使得其收敛速度要比Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失。
⚫ 若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数。
import torch import matplotlib.pyplot as plt # 创建画布和坐标轴 _, axes = plt.subplots(1, 2) # 函数图像 x = torch.linspace(-20, 20, 1000) y = torch.tanh(x) axes[0].plot(x, y) axes[0].grid() axes[0].set_title('Tanh 函数图像') # 导数图像 x = torch.linspace(-20, 20, 1000, requires_grad=True) torch.tanh(x).sum().backward() # 相当于y.sum().backward() axes[1].plot(x.detach(), x.grad) axes[1].grid() axes[1].set_title('Tanh 导数图像') plt.show()
注意:一元函数的导数图像就是梯度图像
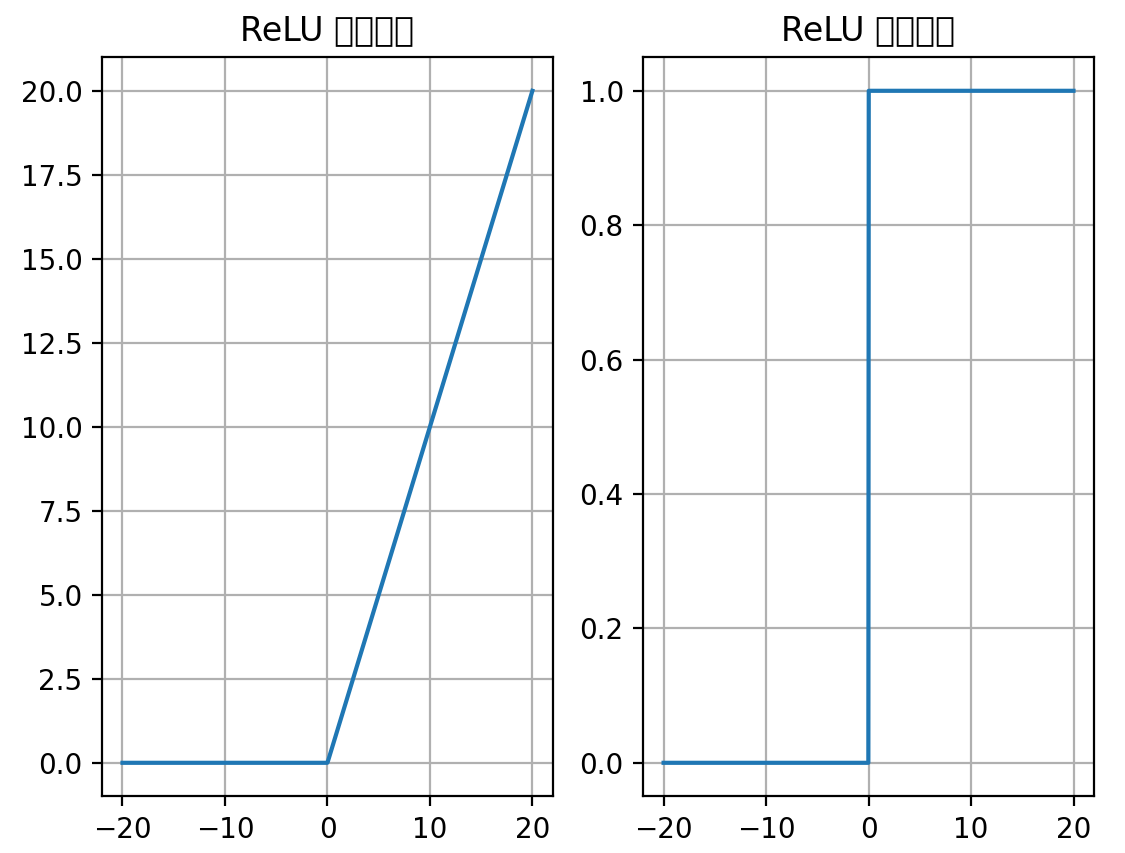
常用的激活函数-ReLU 激活函数

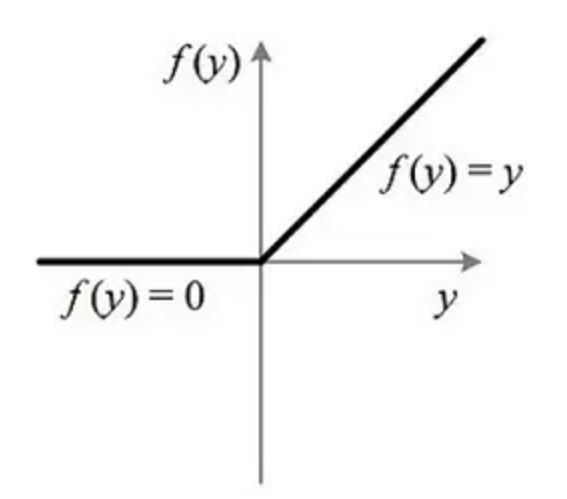
ReLU 的函数图像
ReLU 的导函数图像
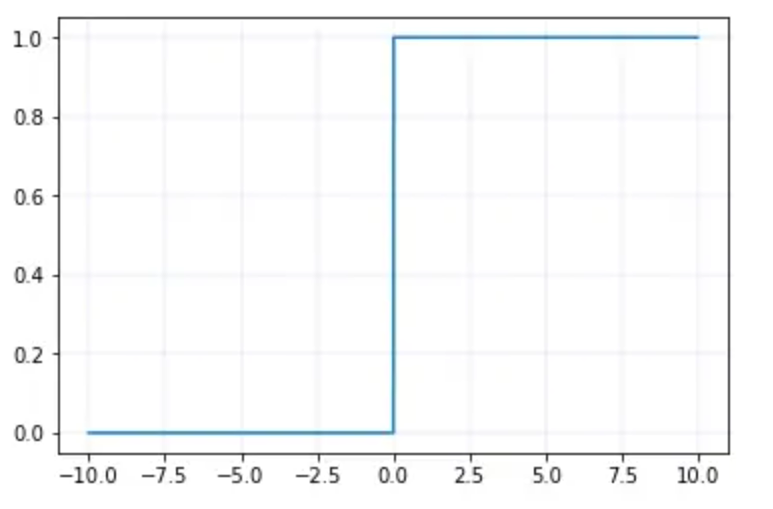
⚫ ReLU 激活函数将小于 0 的值映射为 0,而大于 0 的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。
⚫ ReLU是目前最常用的激活函数。
import torch import matplotlib.pyplot as plt # 创建画布和坐标轴 _, axes = plt.subplots(1, 2) # 函数图像 x = torch.linspace(-20, 20, 1000) y = torch.relu(x) axes[0].plot(x, y) axes[0].grid() axes[0].set_title('ReLU 函数图像') # 导数图像 x = torch.linspace(-20, 20, 1000, requires_grad=True) torch.relu(x).sum().backward() axes[1].plot(x.detach(), x.grad) axes[1].grid() axes[1].set_title('ReLU 导数图像') plt.show()
常用的激活函数-SoftMax 激活函数

import torch scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75]) # dim = 0,按行计算 probabilities = torch.softmax(scores, dim=0) print(probabilities)
结果:
tensor([0.0212, 0.0177, 0.0202, 0.0202, 0.0638, 0.0287, 0.0185, 0.0522, 0.0183,0.7392])
其他常见的激活函数

对于隐藏层:
1. 优先选择ReLU激活函数
2. 如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等。
3. 如果你使用了ReLU, 需要注意一下Dead ReLU问题, 避免出现大的梯度从而导致过多的神经元死亡。
4. 少用使用sigmoid激活函数,可以尝试使用tanh激活函数
对于输出层:
1. 二分类问题选择sigmoid激活函数
2. 多分类问题选择softmax激活函数
3. 回归问题选择identity激活函数
隐藏层和输出层如下所示:
3、参数初始化
先了解一下线性变换

在许多实际问题中,会遇到一组变量由另一组变量线性表示的问题,如变量y1,y2,…,ym可由变量x1,x2…,xn线性表示,即

称这种由变量x1,x2…,xn到变量y1,y2,…,ym的变换为线性变换,它的系数构成的矩阵(aij)mxn(称为系数矩阵)是确定的;反之,如果给出了一个矩阵是线性变换的系数矩阵,则线性变换也就确定了,从这个意义上讲,线性变换与矩阵之间存在着一一对应的关系,因此可以利用矩阵来研究线性变换.
再了解一下nn.Linear()线性层(全连接层)
nn.Linear() 是 PyTorch 中定义全连接层(也称为线性层、全连接层或密集层)的函数。它的作用是对输入数据进行线性变换,也就是矩阵乘法操作。具体地说,它的作用是对输入向量进行线性变换并加上偏置,从而输出一个新的向量。
用法:
torch.nn.Linear(in_features, out_features, bias=True)
参数说明
(1)、in_features:输入特征的维度,即输入张量的最后一维的大小。它表示输入向量的长度。例如:如果输入是形状为 (batch_size, in_features) 的张量,则 in_features 指定为这个输入张量的特征数。
(2)、out_features:输出特征的维度,即输出张量的最后一维的大小。它表示线性层将输入向量转换后的长度。例如:如果我们希望将输入的 in_features 维度变为 out_features 维度,则这个参数指定为输出向量的长度。
(3)、bias:布尔值,默认为 True。如果 bias=True,则该层会有一个偏置向量(bias term),否则没有。bias 会对输出结果加上一个偏置项,通常用于提升模型表现。如果 bias=False,则该线性层只进行矩阵乘法。
工作原理
nn.Linear 层实际上实现了线性变换: y1=x1ω1 +x2ω2 +...+ xnωn +b 其中:
xi 是输入向量,大小为 in_features。ωi是权重矩阵(系数矩阵),大小为 (out_features, in_features)。b 是偏置向量,大小为 out_features,只有在 bias=True 时存在。yi 是输出向量,大小为 out_features。
这个线性变换相当于对输入的向量进行一次仿射变换:先通过矩阵进行变换,再加上偏置 b。
权重和偏置
nn.Linear 层中有两个可学习的参数:权重 w 和偏置b(如果有)。
linear.weight 是权重矩阵(系数矩阵),形状为 (out_features, in_features)。
linear.bias 是偏置向量,形状为 (out_features,),在 bias=True 的情况下存在。
可以通过访问这些参数来查看或者修改它们:
print(linear.weight) # 输出权重矩阵
print(linear.bias) # 输出偏置向量
假设我们有一个输入的维度是 5,输出的维度是 3,且有偏置项。我们可以定义一个线性层:
import torch import torch.nn as nn # 定义线性层:输入维度为5,输出维度为3 linear = nn.Linear(5, 3) print("系数矩阵为3x5:%s" % linear.weight.data) print("系数矩阵的转置为5x3:%s" % torch.transpose(linear.weight.data,0, 1)) # 创建输入张量,假设输入是一个 batch 为的 3 个样本,每个样本维度为 5 input_data = torch.randn(3, 5) print("输入的值为3x5:%s"%input_data) # 前向传播 output_data = linear(input_data) print("输出的值为3x3:%s"%output_data) # 输出的形状是 (3, 3),即 batch 中每个样本经过线性层后变成 3 维 print(output_data.shape) # torch.Size([3, 3])
结果:
系数矩阵为3x5:tensor([[-0.0643, -0.4263, 0.1986, -0.3825, 0.3112], [ 0.4012, -0.1941, 0.2609, -0.1460, 0.0917], [ 0.2478, 0.1781, -0.3442, 0.1878, -0.2529]]) 系数矩阵的转置为5x3:tensor([[-0.0643, 0.4012, 0.2478], [-0.4263, -0.1941, 0.1781], [ 0.1986, 0.2609, -0.3442], [-0.3825, -0.1460, 0.1878], [ 0.3112, 0.0917, -0.2529]]) 输入的值为3x5:tensor([[ 0.3692, -0.1686, -1.7771, 0.3930, 1.4494], [-1.1002, 1.1312, -1.1391, -1.6094, -0.1350], [ 0.0428, -1.4014, 1.4762, -1.3100, -1.0988]]) 输出的值为3x3:tensor([[-0.4106, -0.4513, 0.3558], [-0.4707, -0.9796, 0.0283], [ 0.6403, 0.5207, -0.7395]], grad_fn=<AddmmBackward0>) torch.Size([3, 3])
常见的初始化方式:
⚫ 均匀分布(uniform distribution)初始化
import torch.nn as nn # 1. 均匀分布随机初始化 def test01(): # 生成3行5列的系数矩阵,即输入为x1,x2,x3,x4,x5,输出为y1,y2,y3 linear = nn.Linear(5, 3) # 输入是5维,输出为3维 # 从0-1均匀分布产生参数 nn.init.uniform_(linear.weight) # linear.weight为系数矩阵 print(linear.weight.data) test01()
结果:
tensor([[0.5608, 0.2303, 0.2630, 0.4498, 0.3695], [0.9475, 0.0243, 0.9951, 0.8658, 0.4501], [0.6221, 0.8824, 0.8459, 0.9517, 0.0021]])
⚫ 正态分布初始化
import torch.nn as nn def test05(): linear = nn.Linear(5, 3) # 生成3行5列的系数矩阵 nn.init.normal_(linear.weight, mean=0, std=1) print(linear.weight.data) test05()
结果:
tensor([[-0.1945, 0.8580, 1.5982, 0.3063, 0.7515], [ 0.7433, 0.7109, 0.7537, -1.2637, -0.1360], [-0.4342, -0.8861, 1.0508, 1.3114, -0.7210]])
⚫ 全0初始化
import torch.nn as nn def test03(): linear = nn.Linear(5, 3) nn.init.zeros_(linear.weight) print(linear.weight.data) test03()
结果:
tensor([[0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]])
⚫ 全1初始化
import torch.nn as nn def test04(): # 生成3行5列的系数矩阵 linear = nn.Linear(5, 3) # 输入是5维,输出为3维 ,即输入为x1,x2,x3,x4,x5,输出为y1,y2,y3 nn.init.ones_(linear.weight) print(linear.weight.data) test04()
结果:
tensor([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]])
⚫ 固定值初始化
import torch.nn as nn def test02(): # 生成3行5列的系数矩阵 linear = nn.Linear(5, 3) # 输入是5维,输出为3维 ,即输入为x1,x2,x3,x4,x5,输出为y1,y2,y3 nn.init.constant_(linear.weight, 5) # 所有权重参数初始化为固定值5 print(linear.weight.data) test02()
结果:
tensor([[5., 5., 5., 5., 5.], [5., 5., 5., 5., 5.], [5., 5., 5., 5., 5.]])
⚫ kaiming 初始化,也叫做 HE 初始化
import torch.nn as nn def test06(): # kaiming 正态分布初始化 linear = nn.Linear(5, 3) nn.init.kaiming_normal_(linear.weight) print(linear.weight.data) # kaiming 均匀分布初始化 linear = nn.Linear(5, 3) nn.init.kaiming_uniform_(linear.weight) print(linear.weight.data) test06()
结果:
tensor([[ 0.3059, -0.2192, 0.2156, -0.1627, -0.1264], [-0.0445, -0.2646, 0.5539, 0.1186, -0.1296], [-0.4080, -1.1075, 0.4408, 0.1472, -1.0545]]) tensor([[ 0.0995, 1.0829, 0.9764, -0.5304, 0.8665], [-0.5849, -0.0530, 0.3772, 0.5027, -0.3848], [-0.4380, 0.1394, 0.6933, 0.3591, -0.9588]])
⚫ xavier 初始化,也叫做 Glorot初始化
import torch.nn as nn def test07(): # xavier 正态分布初始化 linear = nn.Linear(5, 3) nn.init.xavier_normal_(linear.weight) print(linear.weight.data) # xavier 均匀分布初始化 linear = nn.Linear(5, 3) nn.init.xavier_uniform_(linear.weight) print(linear.weight.data) test07()
结果:
tensor([[ 6.8918e-01, 4.8521e-04, -4.3255e-01, -7.6819e-01, 4.4149e-01], [-7.0423e-01, -3.2921e-01, -6.2667e-01, 9.5050e-01, -3.2161e-01], [-2.4098e-02, -6.7649e-01, 8.5349e-01, -7.8167e-02, 2.4719e-01]]) tensor([[ 0.8504, -0.0513, 0.1473, 0.1830, -0.7708], [-0.8542, 0.0146, -0.6093, 0.6367, 0.2319], [-0.0902, -0.4682, 0.8398, 0.6463, 0.2259]])
初始化方法的选择
4、神经网络搭建和参数计算
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自nn.Module,实现两个方法:
⚫ __init__方法中定义网络中的层结构,主要是全连接层,并进行初始化
⚫ forward方法,在实例化模型的时候,底层会自动调用该函数。该函数中可以定义学习率,为初始化定义的layer传入数据等。
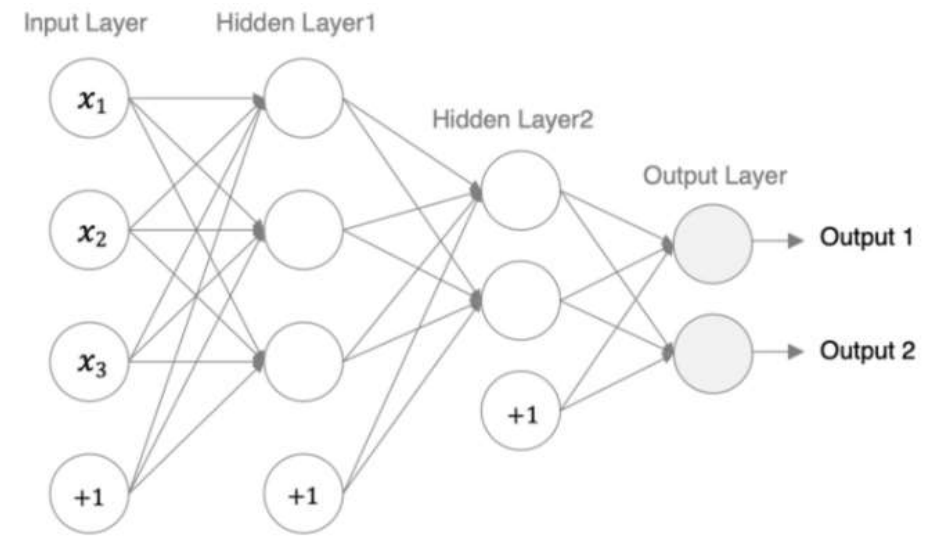
1. 第1个隐藏层:权重初始化采用标准化的xavier初始化 激活函数使用sigmoid。
2. 第2个隐藏层:权重初始化采用标准化的He初始化 激活函数采用relu。
3. out输出层线性层 假若二分类,采用softmax做数据归一化。
神经网络的搭建方法
• 定义继承自nn.Module的模型类
• 在__init__方法中定义网络中的层结构
• 在forward方法中定义数据传输方式
2、网络参数量的统计方法
• 统计每一层中的权重w和偏置b的数量
import torch import torch.nn as nn from torchsummary import summary # 计算模型参数,查看模型结构, pip install torchsummary # 创建神经网络模型类 class Model(nn.Module): # 初始化属性值 def __init__(self): # 在 创建⼀个对象后默认会被调⽤,不需要⼿动调⽤ super(Model, self).__init__() # 调用父类的初始化属性值 self.linear1 = nn.Linear(3, 3) # 创建第一个隐藏层模型, 3个输入特征,3个输出特征 nn.init.xavier_normal_(self.linear1.weight) # xavier 正态分布初始化 初始化权 print("系数矩阵为3x3:%s" % self.linear1.weight.data) print("系数矩阵的转置为3x3:%s" % torch.transpose(self.linear1.weight.data,0, 1)) # 创建第二个隐藏层模型, 3个输入特征(上一层的输出特征),2个输出特征 self.linear2 = nn.Linear(3, 2) # kaiming 正态分布初始化 初始化权重 nn.init.kaiming_normal_(self.linear2.weight) print("系数矩阵为2x3:%s" % self.linear2.weight.data) print("系数矩阵的转置为3x2:%s" % torch.transpose(self.linear2.weight.data, 0, 1)) # 创建输出层模型 self.out = nn.Linear(2, 2) # 2个输入特征,2个输出特征 # 创建前向传播方法,自动执行forward()方法 def forward(self, x): # 数据经过第一个线性层 x = self.linear1(x) # 使用sigmoid激活函数 x = torch.sigmoid(x) # 数据经过第二个线性层 x = self.linear2(x) # 使用relu激活函数 x = torch.relu(x) # 数据经过输出层 x = self.out(x) # 使用softmax激活函数 # dim=-1:每一维度行数据相加为1 x = torch.softmax(x, dim=-1) return x if __name__ == "__main__": # 实例化model对象 ,会调用__init__方法 my_model = Model() # 随机产生数据 my_data = torch.randn(5, 3) # 创建5行3列的随机张量 print("创建5行3列的随机张量mydata:", my_data) print("mydata shape", my_data.shape) # 数据经过神经网络模型训练 output = my_model(my_data) # 将数据送入模型中 print("输出的数据:", output) print("output shape-->", output.shape) # 计算模型参数 # 计算每层每个神经元的w和b个数总和 summary(my_model, input_size=(3,), batch_size=5) # 查看模型参数 print("======查看模型参数w和b======") for name, parameter in my_model.named_parameters(): print(name, parameter)
结果:
系数矩阵为3x3:tensor([[ 0.1320, -0.8633, -1.1555], [-0.1903, 1.3952, -0.3996], [-0.1657, -0.2539, -0.1380]]) 系数矩阵的转置为3x3:tensor([[ 0.1320, -0.1903, -0.1657], [-0.8633, 1.3952, -0.2539], [-1.1555, -0.3996, -0.1380]]) 系数矩阵为2x3:tensor([[-0.3031, -0.4540, -0.7005], [-0.1841, -1.8217, -0.7680]]) 系数矩阵的转置为3x2:tensor([[-0.3031, -0.1841], [-0.4540, -1.8217], [-0.7005, -0.7680]]) Parameter containing: tensor([[-0.1704, 0.3324], [-0.7001, -0.6032]], requires_grad=True) 创建5行3列的随机张量mydata: tensor([[ 0.2675, -0.6613, -1.1060], [-0.2184, -0.8750, -0.9619], [ 0.0134, 0.1127, 0.9470], [-0.4881, -2.5110, -0.1654], [-0.2357, 1.0016, 0.4640]]) mydata shape torch.Size([5, 3]) 输出的数据: tensor([[0.5125, 0.4875], [0.5125, 0.4875], [0.5125, 0.4875], [0.5125, 0.4875], [0.5125, 0.4875]], grad_fn=<SoftmaxBackward0>) output shape--> torch.Size([5, 2]) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Linear-1 [5, 3] 12 Linear-2 [5, 2] 8 Linear-3 [5, 2] 6 ================================================================ Total params: 26 Trainable params: 26 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.00 Estimated Total Size (MB): 0.00 ---------------------------------------------------------------- ======查看模型参数w和b====== linear1.weight Parameter containing: tensor([[ 0.1320, -0.8633, -1.1555], [-0.1903, 1.3952, -0.3996], [-0.1657, -0.2539, -0.1380]], requires_grad=True) linear1.bias Parameter containing: tensor([ 0.0843, 0.1890, -0.4314], requires_grad=True) linear2.weight Parameter containing: tensor([[-0.3031, -0.4540, -0.7005], [-0.1841, -1.8217, -0.7680]], requires_grad=True) linear2.bias Parameter containing: tensor([-0.4206, 0.2988], requires_grad=True) out.weight Parameter containing: tensor([[-0.1704, 0.3324], [-0.7001, -0.6032]], requires_grad=True) out.bias Parameter containing: tensor([-0.5671, -0.6172], requires_grad=True)
⚫ 神经网络的输入数据是为[batch_size, in_features]的张量经过网络处理后获取了[batch_size, out_features]的输出张量。
⚫ 在上述例子中,batchsize=5, infeatures=3,out_features=2,结果如下所示:
模型参数的计算:
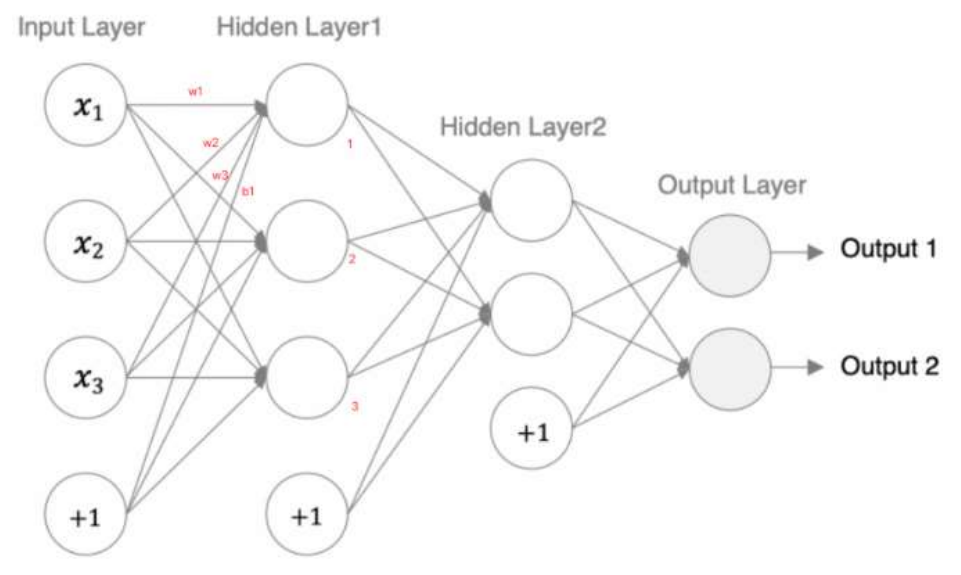
上面的计算过程,我们手动计算如下:
import torch data1 = torch.tensor([[ 0.2675, -0.6613, -1.1060], [-0.2184, -0.8750, -0.9619], [ 0.0134, 0.1127, 0.9470], [-0.4881, -2.5110, -0.1654], [-0.2357, 1.0016, 0.4640]]) data2 = torch.tensor([[ 0.1320, -0.1903, -0.1657], [-0.8633, 1.3952, -0.2539], [-1.1555, -0.3996, -0.1380]]) data3 = data1 @ data2 print("data3-->", data3) # 分别加偏置 tensor([ 0.0843, 0.1890, -0.4314], requires_grad=True) # 即第一列加上0.0843,第二列加上0.1890,第三列加上-0.4314 data3b = torch.tensor([[ 1.9685, -0.3426, -0.1552], [ 1.9223, -0.6059, 0.0403], [-1.1055, -0.0347, -0.5929], [ 2.3787, -3.1554, 0.3098], [-1.3476, 1.4459, -0.7107]]) y = torch.sigmoid(data3b) print("sigmoid第一次激活函数计算之后的值:", y) y1= torch.tensor([[0.8774, 0.4152, 0.4613], [0.8724, 0.3530, 0.5101], [0.2487, 0.4913, 0.3560], [0.9152, 0.0409, 0.5768], [0.2063, 0.8094, 0.3294]]) # 此时y1作为输入,data4作为权重矩阵 data4 = torch.tensor([[-0.3031, -0.1841], [-0.4540, -1.8217], [-0.7005, -0.7680]]) data5 = y1 @ data4 print("data5-->", data5) # data5加上偏置tensor([-0.4206, 0.2988], requires_grad=True) data5b= torch.tensor([[-1.1982, -0.9734], [-1.2026, -0.8966], [-0.9684, -0.9154], [-1.1206, -0.3872], [-1.0813, -1.4666]]) y2 = torch.relu(data5b) print("relu第二次激活函数计算之后的值:", y2) data6= torch.tensor([[-0.1704, 0.3324], [-0.7001, -0.6032]]) data7 = y2 @ data6 print("data7-->", data7) # data7加上输出层的偏置tensor([-0.5671, -0.6172], requires_grad=True) data7b = torch.tensor([[-0.5671, -0.6172], [-0.5671, -0.6172], [-0.5671, -0.6172], [-0.5671, -0.6172], [-0.5671, -0.6172]]) out = torch.softmax(data7b, dim=-1) print("前向传播输出结果-->",out)
结果如下:
data3--> tensor([[ 1.8842, -0.5316, 0.2762], [ 1.8380, -0.7949, 0.3911], [-1.1898, -0.2237, -0.1615], [ 2.2944, -3.3444, 0.7412], [-1.4319, 1.2569, -0.2793]]) sigmoid第一次激活函数计算之后的值: tensor([[0.8774, 0.4152, 0.4613], [0.8724, 0.3530, 0.5101], [0.2487, 0.4913, 0.3560], [0.9152, 0.0409, 0.5768], [0.2063, 0.8094, 0.3294]]) data5--> tensor([[-0.7776, -1.2722], [-0.7820, -1.1954], [-0.5478, -1.2142], [-0.7000, -0.6860], [-0.6607, -1.7654]]) relu第二次激活函数计算之后的值: tensor([[0., 0.], [0., 0.], [0., 0.], [0., 0.], [0., 0.]]) data7--> tensor([[0., 0.], [0., 0.], [0., 0.], [0., 0.], [0., 0.]]) 前向传播输出结果--> tensor([[0.5125, 0.4875], [0.5125, 0.4875], [0.5125, 0.4875], [0.5125, 0.4875], [0.5125, 0.4875]])
发现最后的输出结果与前面的输出结果是一样的。
1.优点
2.缺点
二、损失函数


损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度(损失值)的运算函数,它是一个非负实值函数。
损失函数仅用于模型训练阶段,得到损失值后,通过反向传播来更新参数,从而降低预测值与真实值之间的损失值,从而提升模型性能。
整个模型训练的过程,就是在通过不断更新参数,使得损失函数不断逼*全局最优点(全局最小值)。
1. 分类任务的损失函数
2. 回归任务的损失函数
1、多分类任务损失函数

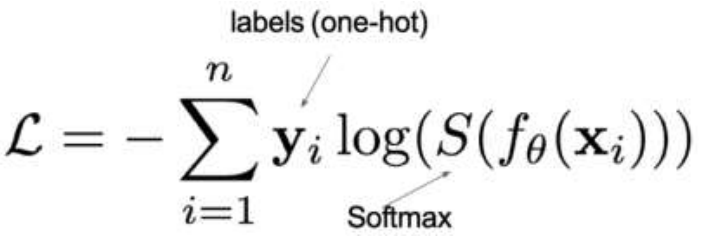
其中:
1. y是样本x属于某一个类别的真实概率
2. 而f(x)是样本属于某一类别的预测分数
3. S是softmax激活函数,将属于某一类别的预测分数转换成概率
4. L用来衡量真实值y和预测值f(x)之间差异性的损失结果
One-hot表示:将正确解标签表示为1,其他标签表示为0;几分类表示几维
MNIST:共计10个数字(0-9)
one-hot表示“1”→[0, 1, 0,0, 0, 0, 0, 0, 0, 0]
one-hot表示“2”→[0,0,1, 0,0, 0, 0, 0,0, 0]
one-hot表示“9”→[0,0,0,0,0,0,0,0,0, 1]交叉熵损失只计算对应正确解标签的输出的自然对数。
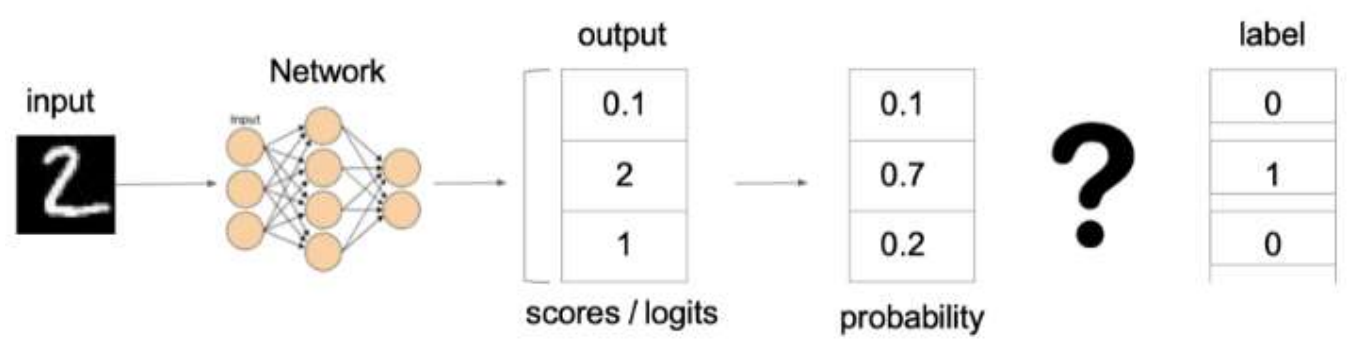
将神经网络输出的预测分数[0.1, 2, 1]通过softmax激活函数转换成概率
import torch scores = torch.tensor([0.1, 2, 1]) # dim = 0,按行计算 probabilities = torch.softmax(scores, dim=0) print(probabilities)
结果:tensor([0.0986, 0.6590, 0.2424])
![]()
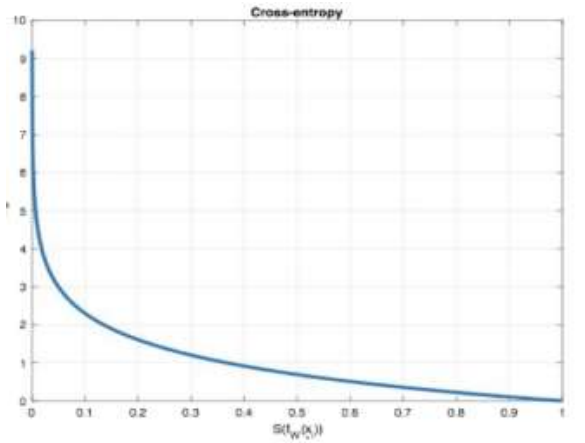
x越接*1,y越接*0,x=1时,y=0。x越接*0,y越大。
import torch import torch.nn as nn # 分类损失函数:交叉熵损失使用nn.CrossEntropyLoss()实现。nn.CrossEntropyLoss()=softmax + 损失计算 def test(): # 设置真实值: 可以是热编码后的结果也可以不进行热编码 # y_true = torch.tensor([[0, 1, 0], [0, 0, 1]], dtype=torch.float32) # 注意的类型必须是64位整型数据 y_true = torch.tensor([1, 2], dtype=torch.int64) y_pred = torch.tensor([[0.2, 0.6, 0.2], [0.1, 0.8, 0.1]], dtype=torch.float32) # 实例化交叉熵损失 loss = nn.CrossEntropyLoss() # 计算损失结果 my_loss = loss(y_pred, y_true).numpy() print('loss:', my_loss) test()
结果:loss: 1.1200755
下面详解计算过程:
交叉熵损失的计算步骤如下:
(1)、Softmax 函数:
对 logits 进行 softmax 操作,将其转换为概率分布:
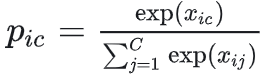
其中 pic 表示第 i 个样本属于第 c 类别的预测概率。
import torch scores = torch.tensor([[0.2, 0.6, 0.2], [0.1, 0.8, 0.1]]) # dim = 0,按行计算 probabilities = torch.softmax(scores, dim=1) print(probabilities)
结果:
tensor([[0.2864, 0.4272, 0.2864], [0.2491, 0.5017, 0.2491]])
(2)、负对数似然(Negative Log-Likelihood)
-(0*log(0.2864) + 1*log(0.4272) + 0*log(0.2864) ) = - log(0.4272) = 0.8505
-(0*log(0.2491) + 0*log(0.5017) + 1*log(0.2491) )= - log(0.2491) = 1.3899
reduction 参数默认为 'mean'):1/2(0.8505 + 1.3899 ) = 1.1202
2、二分类任务损失函数
![]()
对于二分类问题,交叉熵损失可以定义为:

其中:
1. y是样本x属于某一个类别的真实概率
2. 而y^是样本属于某一类别的预测概率
3. L用来衡量真实值y与预测值y^之间差异性的损失结果。
在pytorch中实现时使用nn.BCELoss() ,如下所示:
import torch import torch.nn as nn def test2(): # 1 设置真实值和预测值 # 预测值是sigmoid输出的结果 y_pred = torch.tensor([0.6901, 0.5459, 0.2469], requires_grad=True) y_true = torch.tensor([0, 1, 0], dtype=torch.float32) # 2 实例化二分类交叉熵损失 criterion = nn.BCELoss() # 3 计算损失 my_loss = criterion(y_pred, y_true).detach().numpy() print('loss:', my_loss) test2()
结果:loss: 0.6867941
下面详解计算过程:
(1)、sigmoid计算
import torch logits = torch.tensor([0.6901, 0.5459, 0.2469]) probabilities = torch.sigmoid(logits) print(probabilities)
结果:tensor([0.6660, 0.6332, 0.5614])
(2)、计算*均值
当模型输出其为负类的概率为0.6660时,交叉熵损失为:loss =-(0*log(0.6660)+1*log(1-0.6660))=1.1715
当模型输出其为正类的概率为 0.6332时,交叉熵损失为:loss =-(1*log( 0.6332)+0*log(1- 0.6332))=0.2835
当模型输出其为负类的概率为 0.5614时,交叉熵损失为:loss =-(0*log( 0.5614)+1*log(1- 0.5614))=0.6053
*均值为:1/3(1.1715 + 0.2835 + 0.6053)= 0.6867
3、回归任务损失函数-MAE损失函数

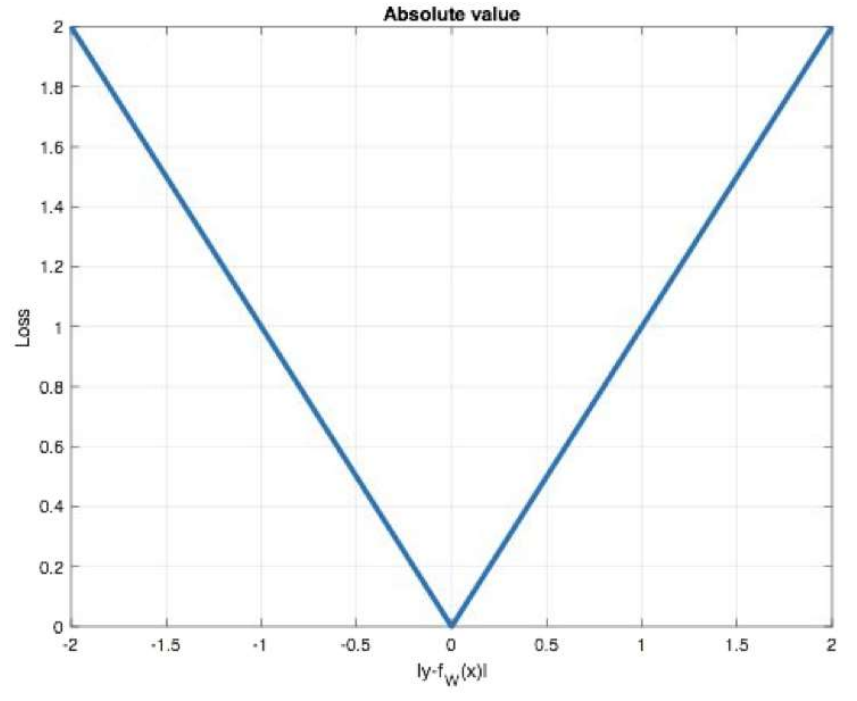
特点是:
1. 由于L1 loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他loss中作为约束。
2. L1 loss的最大问题是梯度在零点不*滑,导致会跳过极小值。
import torch import torch.nn as nn # 计算算inputs与target之差的绝对值 def test3(): # 1 设置真实值和预测值 y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True) y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float32) # 2 实例MAE损失对象 loss = nn.L1Loss() # 3 计算损失 my_loss = loss(y_pred, y_true).detach().numpy() print('loss:', my_loss) test3()
结果:loss: 0.7
计算过程如下:1/3[(2-1)+ (2-1)+ (2-1.9)]=1/3*2.1=0.7
4、回归任务损失函数-MSE损失函数
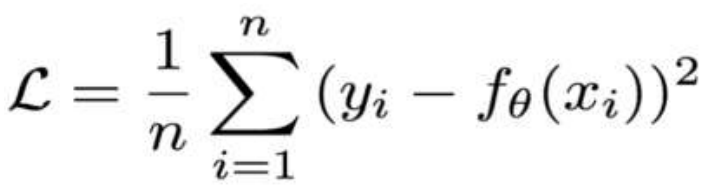

特点是:
1. L2 loss也常常作为正则项。
2. 当预测值与目标值相差很大时, 梯度容易爆炸。
import torch import torch.nn as nn def test4(): # 1 设置真实值和预测值 y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True) y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float32) # 2 实例MSE损失对象 loss = nn.MSELoss() # 3 计算损失 my_loss = loss(y_pred, y_true).detach().numpy() print('myloss:', my_loss) test4()
结果:myloss: 0.67
计算过程:1/3[(2-1)2 + (2-1)2 + (2-1.9)2 ] = 0.67
5、回归任务损失函数-smooth L1损失函数
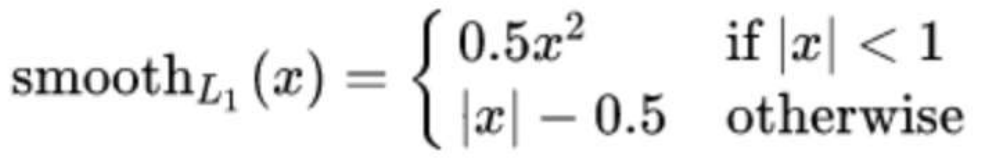
其中:𝑥=f(x)−y 为真实值和预测值的差值。
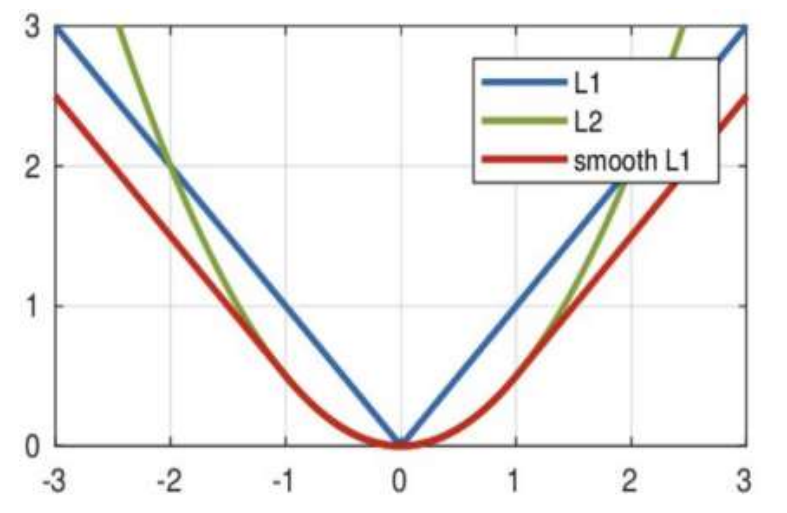
从右图中可以看出,该函数实际上就是一个分段函数
1. 在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑问题
2. 在[-1,1]区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
import torch import torch.nn as nn def test5(): # 1 设置真实值和预测值 y_true = torch.tensor([0, 3]) y_pred = torch.tensor ([0.6, 0.4], requires_grad=True) # 2 实例smmothL1损失对象 loss = nn.SmoothL1Loss() # 3 计算损失 my_loss = loss(y_pred, y_true).detach().numpy() print('loss:', my_loss) test5()
结果:loss: 1.14
三、网络优化方法
optimizer.step()是pytorch中优化器对象的一个方法,用于更新模型的参数。 在训练深度神经网络的过程中,optimizer.step()方法通过梯度和学习率等超参数来更新模型的参数,以最小化损失函数。具体来说,该方法会根据每个参数的梯度信息来调整模型的权重和偏置,从而优化模型的性能。
在PyTorch中,使用optimizer.step()方法通常遵循以下步骤:
(1)、清零梯度:在每次调用step()之前,需要使用.zero_grad()方法将梯度清零,以避免梯度累加。
(2)、计算梯度:通过loss.backward()计算损失函数的梯度。
(3)、更新参数:最后调用optimizer.step()进行参数更新。
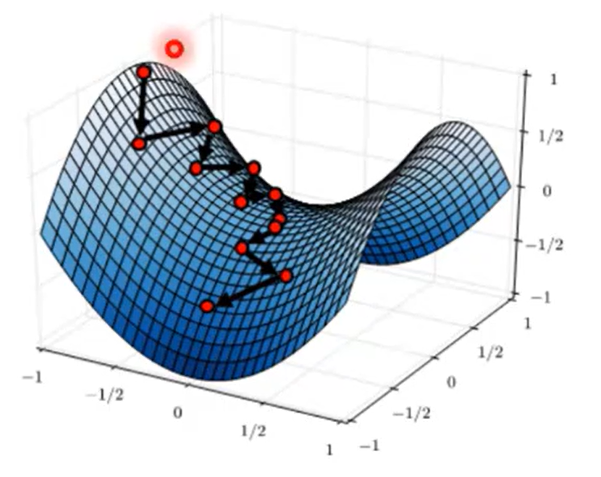
1、梯度下降算法回顾

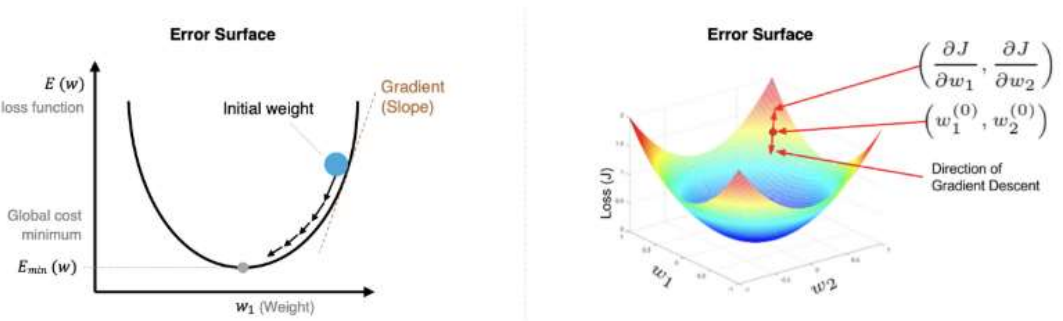
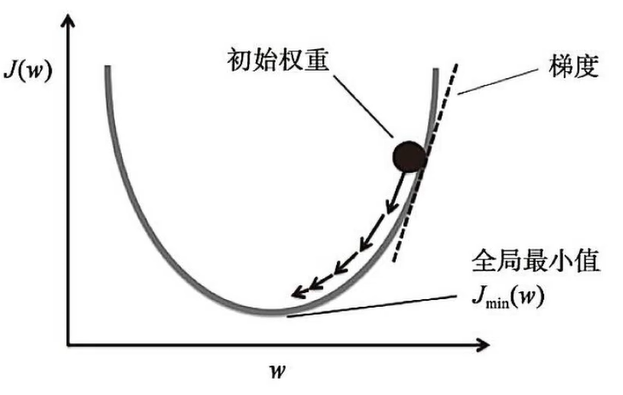
理解梯度下降:这里w轴只表示一个变量,但是不管是几个维度,道理是一样的,我们这里看二维的比较容易理解。w就是我们要优化的参数,J(w)就是损失函数,函数有最小值,说明函数是可优化的,那么w取什么值时,损失函数最小?由于参数特别多,很难计算出来。在AI领域,使用优化的方法,即先随便给一个值,然后沿负梯度方向变化w,让损失函数逐渐变小。只要沿着负梯度方向,每次一小步一小步的变化,损失函数最终总会变小,但是步长不能太大,如果太大可能一不小心跨过最小值的位置。学习率决定了每次更新参数的步长,学习率过大可能导致震荡甚至不收敛(越过极值点),学习率过小则收敛速度慢。常见的做法是通过实验选择合适的学习率(常见的范围是0.1-0.0001)。
找到最优的参数值,使得损失函数最小,
在进行模型训练时,有三个基础的概念:
1. Epoch: 使用全部数据对模型进行一次完整训练,训练轮次
2. Batch_size: 使用训练集中的小部分样本对模型权重进行一次反向传播的参数更新,每次训练每批次样本数量。
3. Iteration: 使用一个 Batch 数据对模型进行一次参数更新的过程
在模型训练过程中,我们不会一次性的将全部数据送到模型里,我们把所有的数据(full batch)分成若干个mini batch,然后每次送入一个batch,来进行学习,没学习完一个batch的数据,我们叫完成了一个iteration,当全部batch的数据都被学习完之后,我们就完成了一个Epoch。
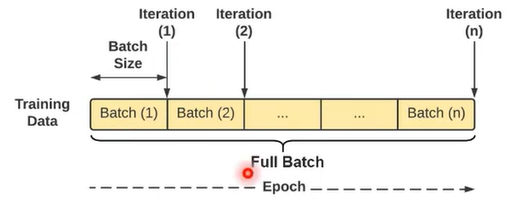
在每一个Epoch之后,即在full batch中所有的数据来计算梯度,然后更新参数。但是这样做有以下问题:
(1)、最显著的问题就是计算代价比较高,因为梯度是在整个batch上去计算的,数据通常非常多,计算的复杂度就比较高。
(2)、第二个问题就是鞍点问题,在损失函数复杂的高维空间中,梯度可能停留在鞍点的位置,鞍点就是非局部极值点的驻点,梯度下降算法更新到这个位置的时候就不会再进行更新,显然这个点并不是一个极值点。
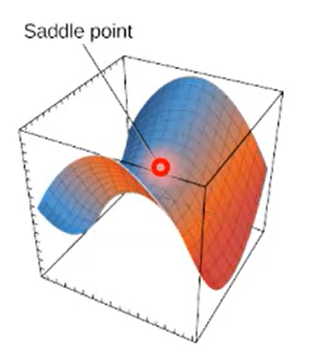
(3)、梯度下降算法可能会将梯度停留在局部极值点,在复杂的图形中,可能有多个极值点,一旦到了某一个极值点,梯度为0就停止更新了,所以会很容易陷入局部极值,
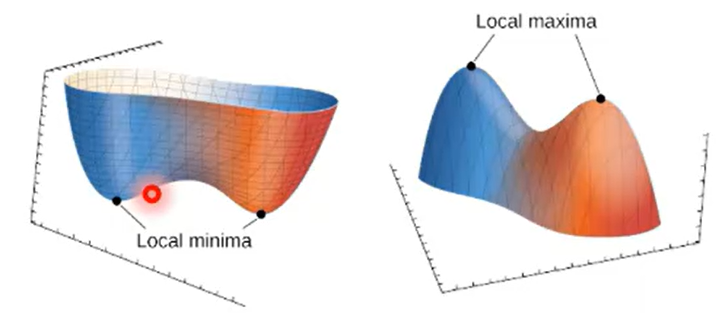
(4)、学习率大小的选择直接影响学习的效果。
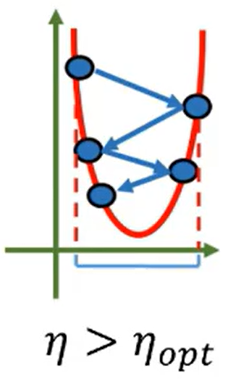
如果学习率是最优学习率的话,一步就能达到极小值。如下图所示:

如果学习率比最优学习率小,那么要迭代多次达到最小值

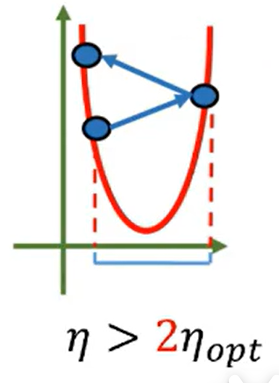
如果学习率比最优学习率大,但是比2倍的最优学习率小,则会产生振荡,但最终会收敛最小值
比较糟糕的情况是学习率过大,则会网上走,那就无法找到最小值
那么如何调整学习率呢?在学习的开始学习率要大一些来探索不同地形,当学习进行到后面的阶段,应该减小学习率,在局部位置去找到最优的那个点,也就是说学习率在整个学习过程中不应该是一成不变的,应该有一个衰减,学习率衰减的技术就叫learning rate decay
假设数据集有 50000 个训练样本,现在选择 Batch Size = 256 对模型进行训练。
每个 Epoch 要训练的图片数量:50000
训练集具有的 Batch 个数:50000/256+1=196
每个 Epoch 具有的 Iteration 个数:196
10个 Epoch 具有的 Iteration 个数:1960
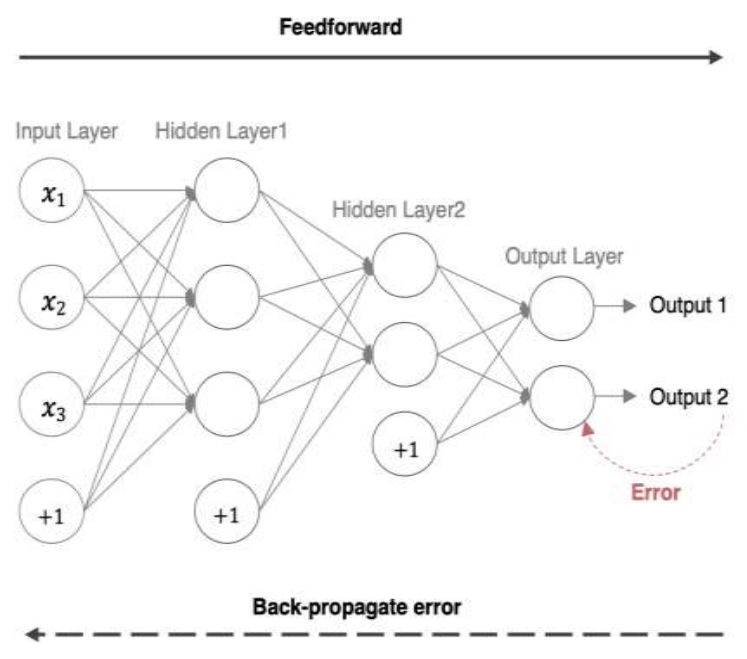
2、反向传播(BP算法)[了解]
前向传播:指的是数据输入的神经网络中,逐层向前传输,一直到运算到输出层为止。
反向传播(Back Propagation):利用损失函数 ERROR,从后往前,结合梯度下降算法,依次求各个参数的偏导,并进行参数更新。
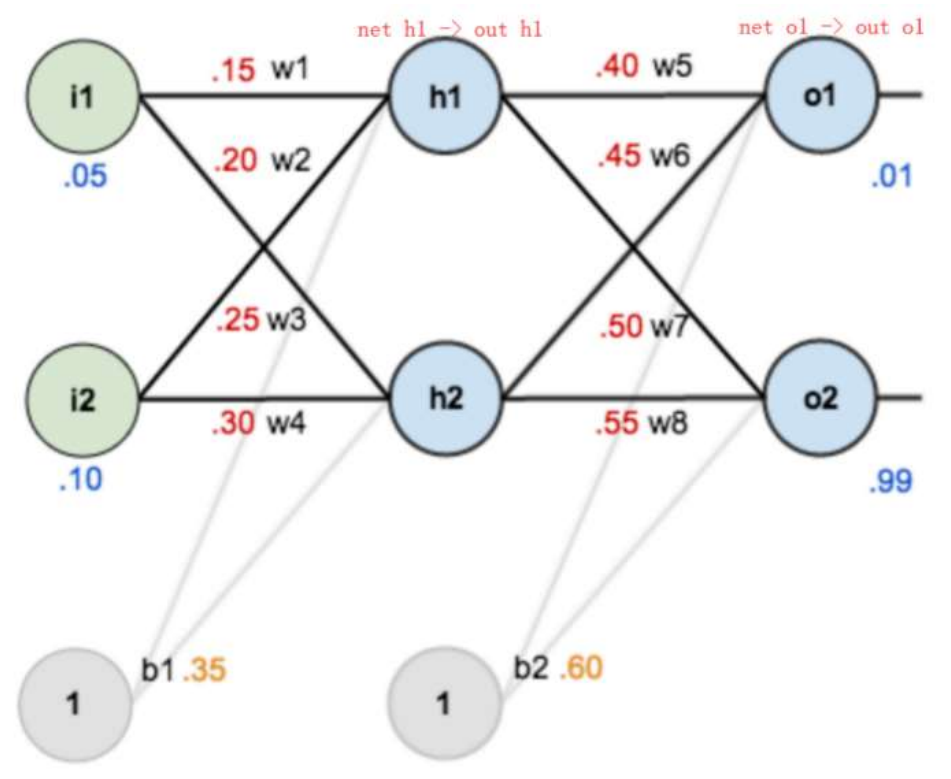

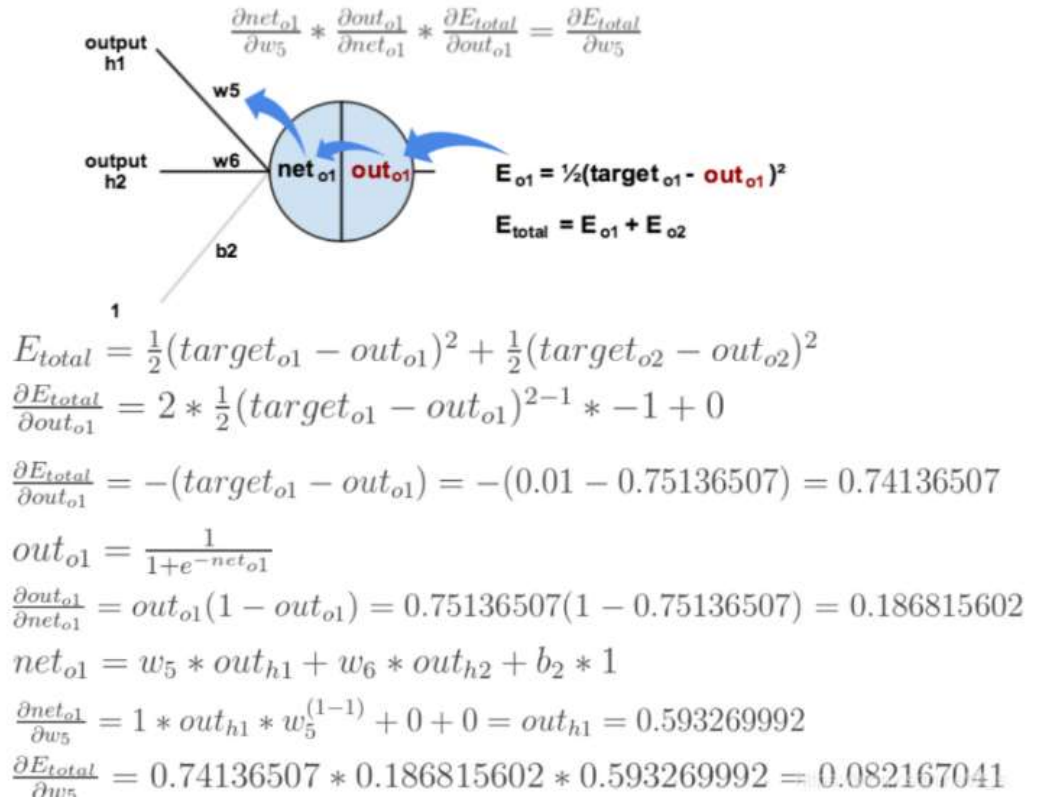

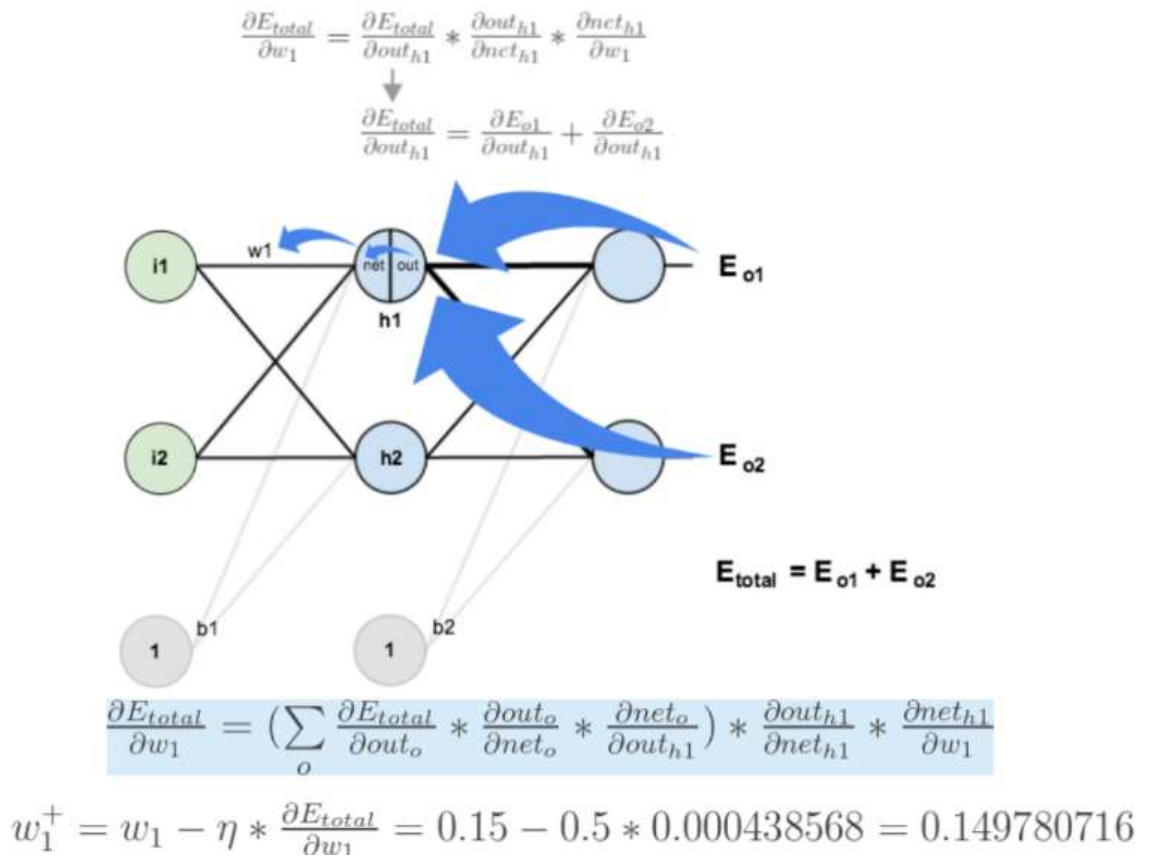
import torch from torch import nn from torch import optim # 创建神经网络类 class Model(nn.Module): # 初始化参数 def __init__(self): # 调用父类方法 super(Model, self).__init__() # 创建网络层 self.linear1 = nn.Linear(2, 2) self.linear2 = nn.Linear(2, 2) # 初始化神经网络参数 self.linear1.weight.data = torch.tensor([[0.15, 0.20], [0.25, 0.30]]) self.linear2.weight.data = torch.tensor([[0.40, 0.45], [0.50, 0.55]]) self.linear1.bias.data = torch.tensor([0.35, 0.35]) self.linear2.bias.data = torch.tensor([0.60, 0.60]) # 前向传播方法 def forward(self, x): # 数据经过第一层隐藏层 x = self.linear1(x) # 计算第一层激活值 x = torch.sigmoid(x) # 数据经过第二层隐藏层 x = self.linear2(x) # 计算第二层激活值 x = torch.sigmoid(x) return x if __name__ == '__main__': # 定义网络输入值和目标值 inputs = torch.tensor([[0.05, 0.10]]) target = torch.tensor([[0.01, 0.99]]) # 实例化神经网络对象 model = Model() output = model(inputs) print("output-->", output) loss = torch.sum((output - target) ** 2) / 2 # 计算误差 print("loss-->", loss) # 优化方法和反向传播算法 optimizer = optim.SGD(model.parameters(), lr=0.5) optimizer.zero_grad() loss.backward() print("w1,w2,w3,w4-->", model.linear1.weight.grad.data) print("w5,w6,w7,w8-->", model.linear2.weight.grad.data) optimizer.step() # 参数更新 # 打印神经网络参数 print(model.state_dict())
结果:
output--> tensor([[0.7514, 0.7729]], grad_fn=<SigmoidBackward0>) loss--> tensor(0.2984, grad_fn=<DivBackward0>) w1,w2,w3,w4--> tensor([[0.0004, 0.0009], [0.0005, 0.0010]]) w5,w6,w7,w8--> tensor([[ 0.0822, 0.0827], [-0.0226, -0.0227]]) OrderedDict([('linear1.weight', tensor([[0.1498, 0.1996], [0.2498, 0.2995]])), ('linear1.bias', tensor([0.3456, 0.3450])), ('linear2.weight', tensor([[0.3589, 0.4087], [0.5113, 0.5614]])), ('linear2.bias', tensor([0.5308, 0.6190]))])
3、梯度下降的优化方法
梯度下降算法优化的目的?
梯度下降优化算法中,可能会碰到*缓区域,“鞍点”等问题
梯度下降算法的优化有哪些?
梯度下降优化算法中,可能会碰到以下情况:
1. 碰到*缓区域,梯度值较小,参数优化变慢
2. 碰到 “鞍点” ,梯度为 0,参数无法优化
3. 碰到局部最小值,参数不是最优

(1)、梯度下降的优化方法-指数加权*均
指数移动加权*均(exponential moving average)则是参考各数值,并且各数值的权重都不同,距离越远的数字对*均数计算的贡献就越小(权重较小),距离越*则对*均数的计算贡献就越大(权重越大)。
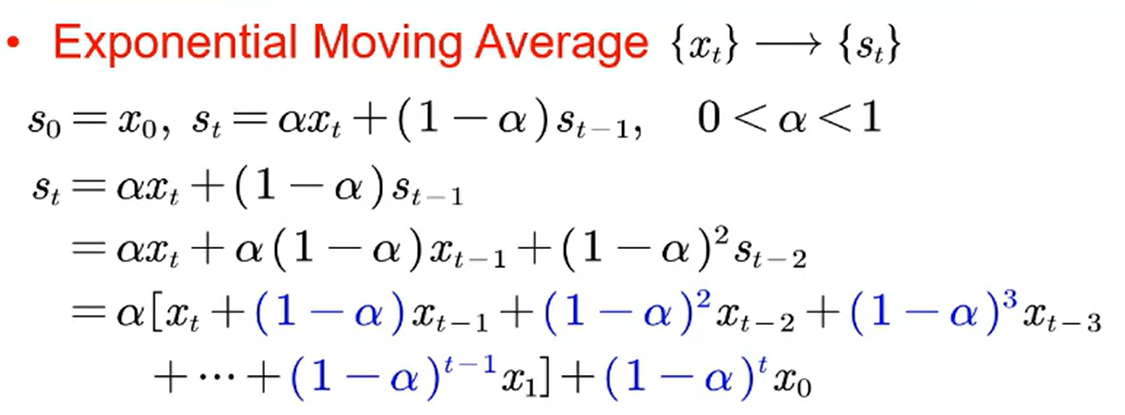
st 是xt,...,x0的线性组合,系数分别是α,(1-α) ,(1-α)2 ,...,(1-α)t ,
比如:明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。
计算公式可以用下面的式子来表示:
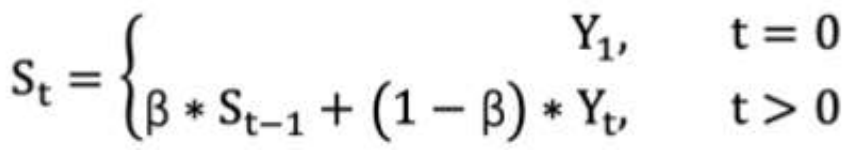
• St 表示指数加权*均值;
• Yt 表示 t 时刻的值;
• β 调节权重系数,该值越大*均数越*缓。
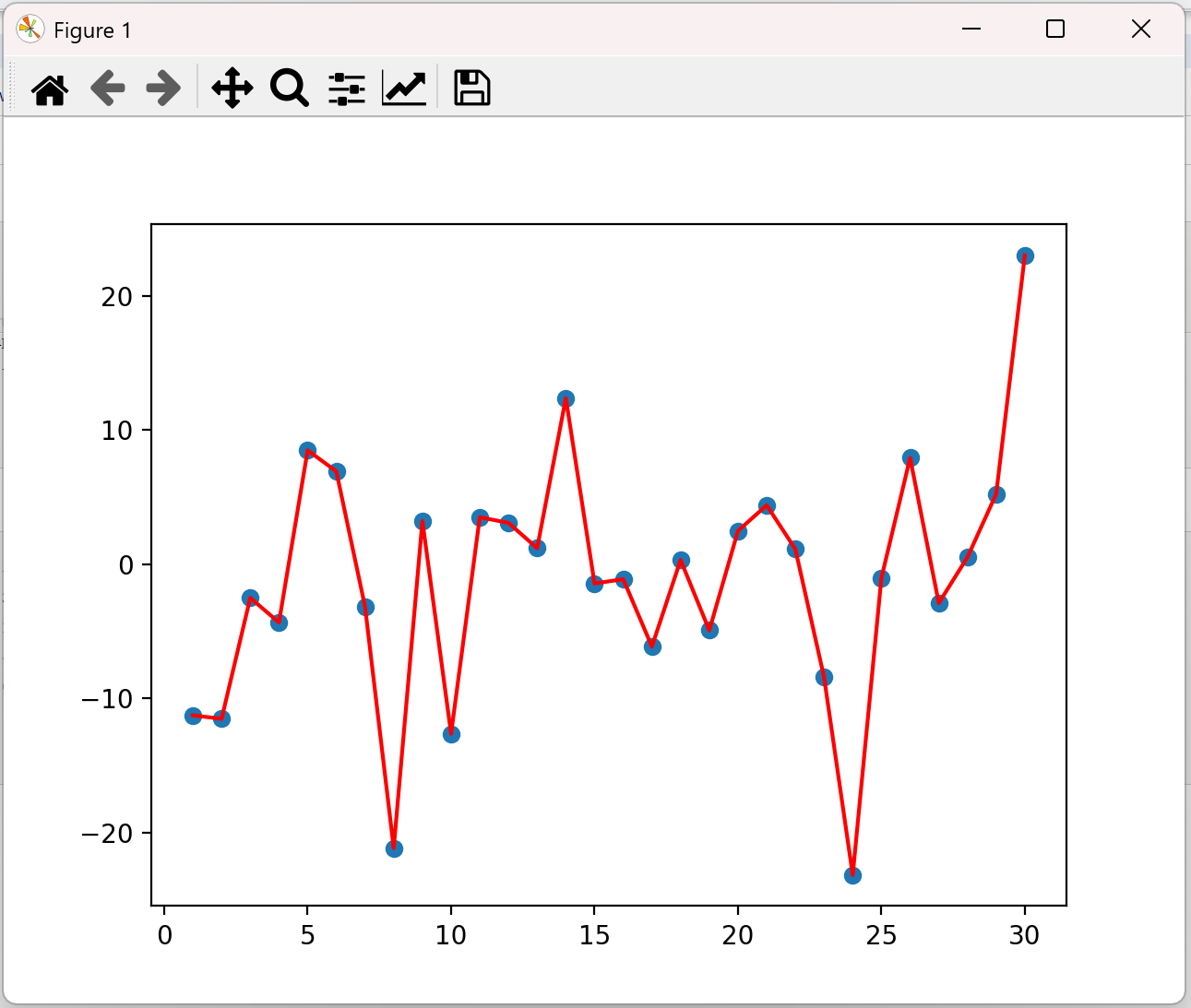
下面通过代码来看结果,随机产生 30 天的气温数据:
import torch import matplotlib.pyplot as plt ELEMENT_NUMBER = 30 # 1. 实际*均温度 def test01(): # 固定随机数种子 使得运行代码每次生成的随机数都一样,不同的随机种子生成不同的值,如torch.manual_seed(1) torch.manual_seed(0) # 产生30天的随机温度 temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10 # 由于设置了随机数种子,每次生成的随机温度都一样 print(temperature) # 在指定区间内按照步长生成元素,start值为1,end值为31,步长为1 days = torch.arange(1, ELEMENT_NUMBER + 1, 1) print(days) plt.plot(days, temperature, color='r') plt.scatter(days, temperature) plt.show() test01()
结果:
tensor([-11.2584, -11.5236, -2.5058, -4.3388, 8.4871, 6.9201, -3.1601, -21.1522, 3.2227, -12.6333, 3.4998, 3.0813, 1.1984, 12.3766, -1.4347, -1.1161, -6.1358, 0.3159, -4.9268, 2.4841, 4.3970, 1.1241, -8.4106, -23.1604, -1.0231, 7.9244, -2.8967, 0.5251, 5.2286, 23.0221]) tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30])
import torch import matplotlib.pyplot as plt ELEMENT_NUMBER = 30 # 2. 指数加权*均温度 def test02(beta=0.9): torch.manual_seed(0) # 设置固定随机数种子,使得运行代码每次生成的随机数都一样 temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10 # 产生30天的随机温度,由于设置了随机种子,每次生成的随机温度都一样 print(temperature) exp_weight_avg = [] # 索引从0开始 for idx, temp in enumerate(temperature, 1): # 从下标1开始 # 第一个元素的的 EWA 值等于自身 # idx从1开始 if idx == 1: exp_weight_avg.append(temp) print(temp) continue # 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气温乘以 (1-β) new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * temp exp_weight_avg.append(new_temp) days = torch.arange(1, ELEMENT_NUMBER + 1, 1) # 在指定区间内按照步长生成元素 plt.plot(days, exp_weight_avg, color='r') # 绘制折线图,days为横坐标,exp_weight_avg为纵坐标 plt.scatter(days, temperature) # 绘制散点图 plt.show() test02()
结果:
tensor([-11.2584, -11.5236, -2.5058, -4.3388, 8.4871, 6.9201, -3.1601, -21.1522, 3.2227, -12.6333, 3.4998, 3.0813, 1.1984, 12.3766, -1.4347, -1.1161, -6.1358, 0.3159, -4.9268, 2.4841, 4.3970, 1.1241, -8.4106, -23.1604, -1.0231, 7.9244, -2.8967, 0.5251, 5.2286, 23.0221]) tensor(-11.2584)
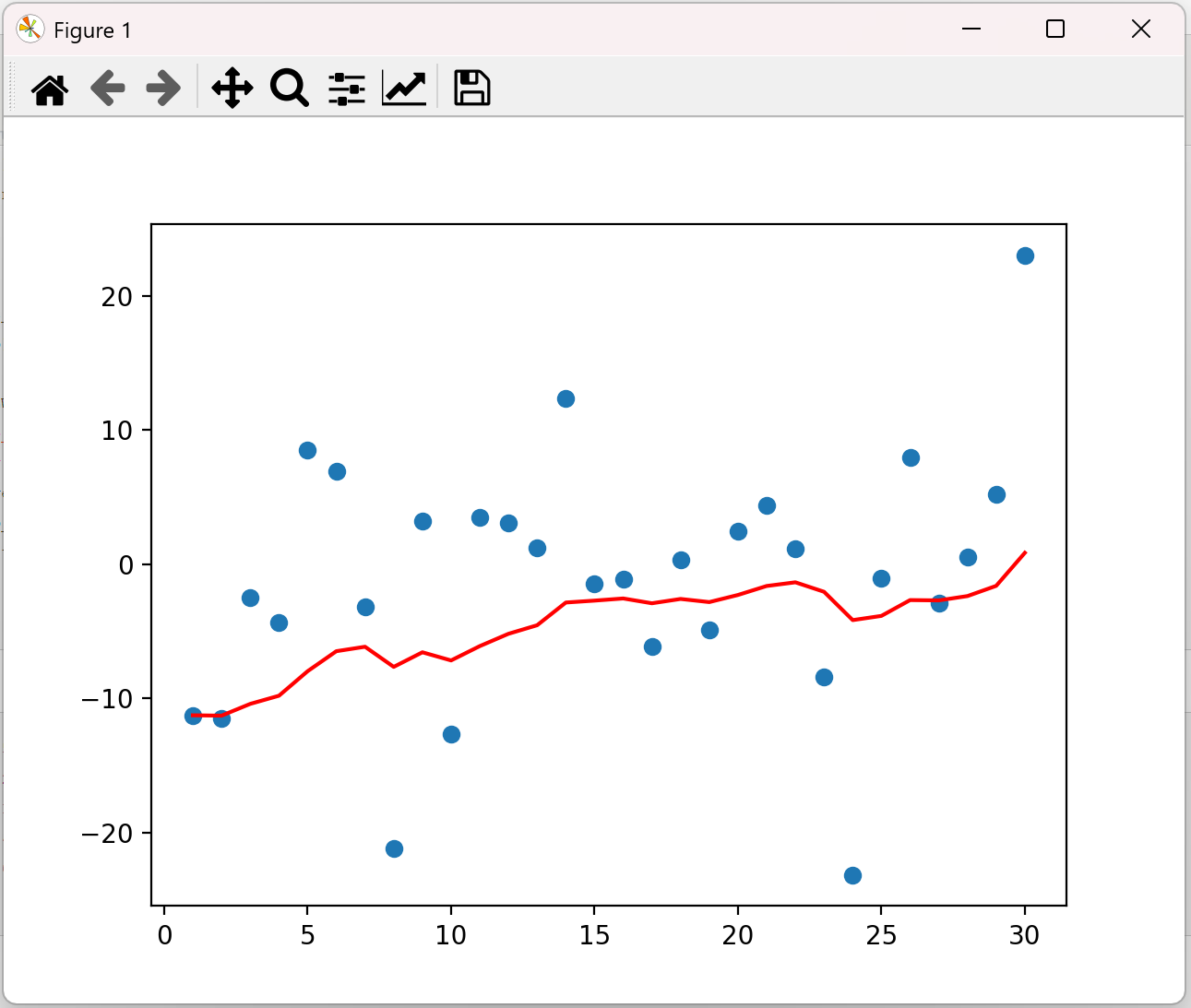
如果将β改为0.5,图像如下:
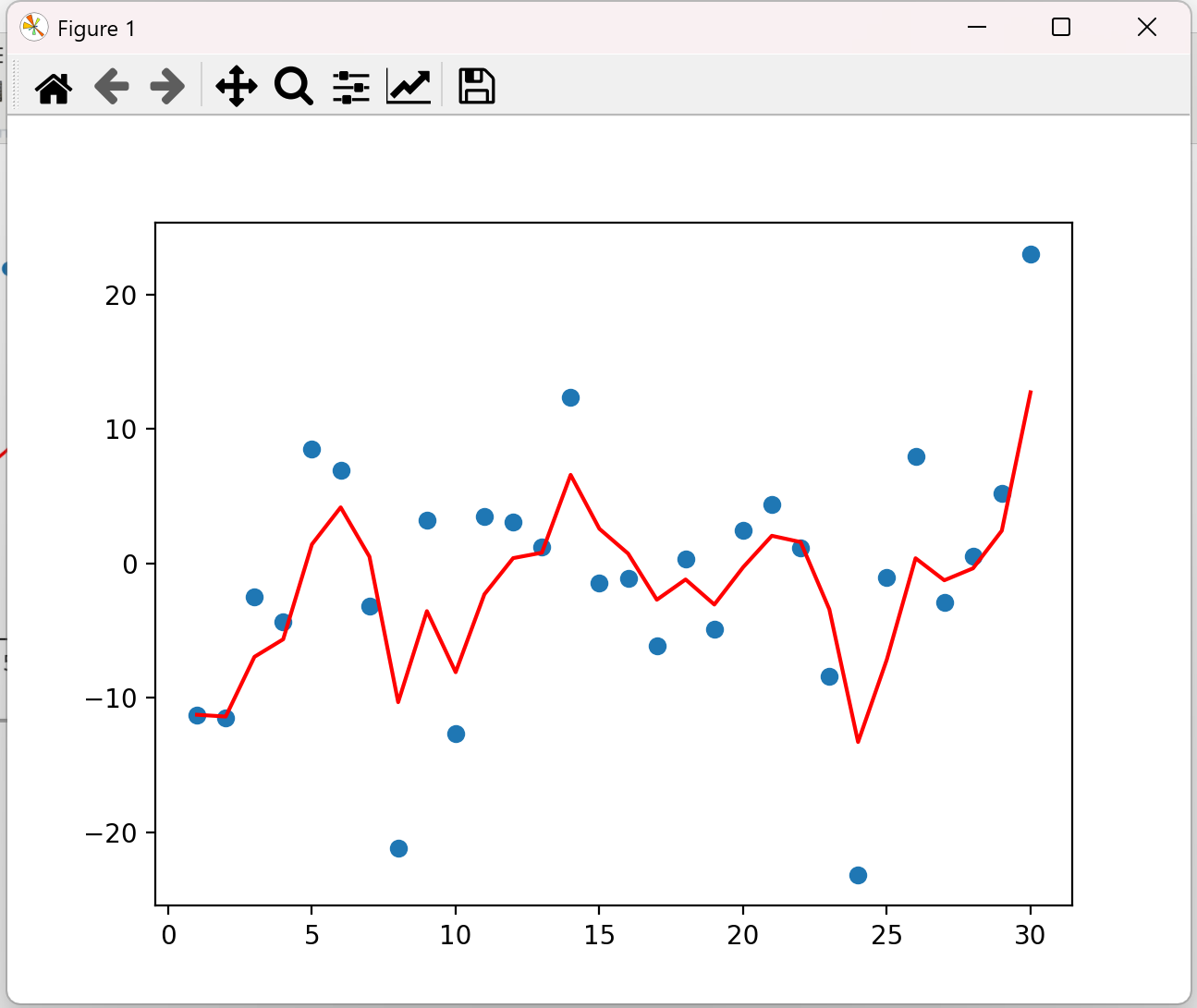
上图是β为0.5和0.9时的结果,从中可以看出:
• 指数加权*均绘制出的气温变化曲线更加*缓,
• β 的值越大,则绘制出的折线越加*缓,波动越小。
(2)、梯度下降的优化方法-动量算法Momentum
梯度计算公式:Dt = β * St-1 + (1- β) * Wt1. St-1 表示历史梯度移动加权*均值
2. Wt 表示当前时刻的梯度值
3. Dt 为当前时刻的指数加权*均梯度值
4. β 为权重系数
假设:权重 β 为 0.9,例如:
第一次梯度值:s1 = d1 = w1
第二次梯度值:d2=s2 = 0.9 * s1 + w2 * 0.1
第三次梯度值:d3=s3 = 0.9 * s2 + w3 * 0.1
第四次梯度值:d4=s4 = 0.9 * s3 + w4 * 0.1
我们不再使用梯度来更新参数,而是使用动量。这样做的好处是动量会累积之前的信息,
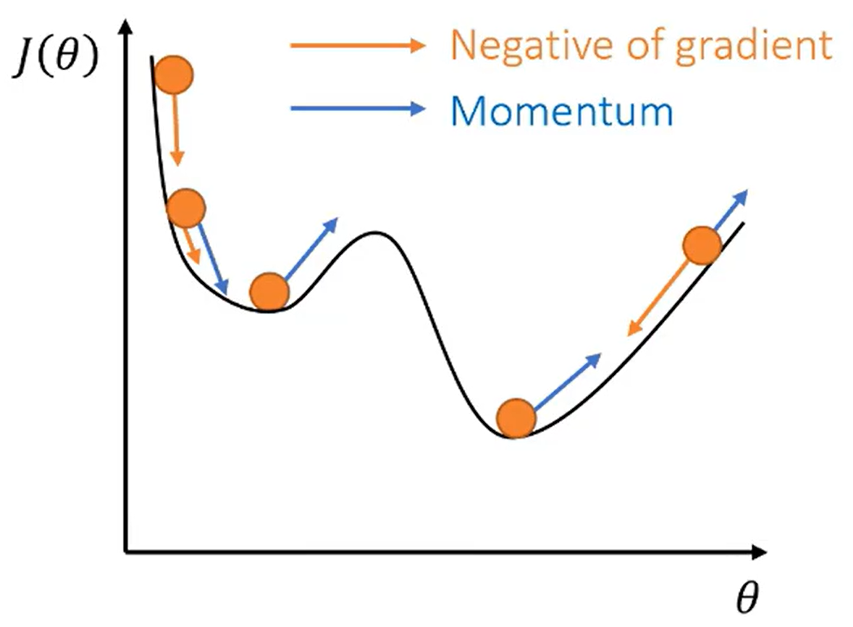
Monmentum 优化方法是如何一定程度上克服 “*缓”、”鞍点” 的问题呢?
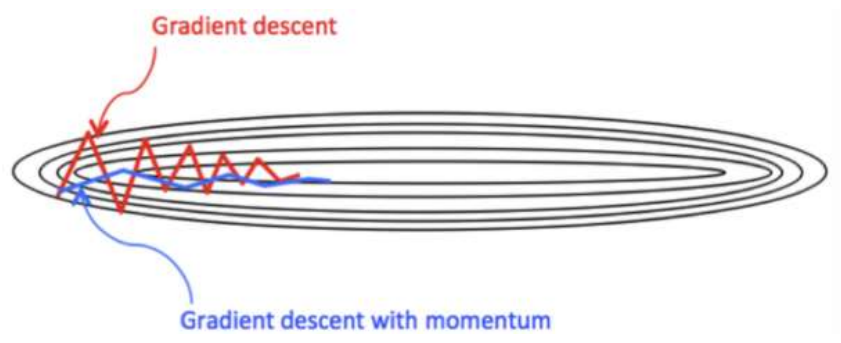
⚫ 当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
⚫ 由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权*均,*滑了梯度的变化,使得前进方向更加*缓,有利于加快训练过程。
import torch; def test01(): # 1 初始化权重参数 w = torch.tensor([2.0], requires_grad=True, dtype=torch.float32) y = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:SGD 指定参数beta=0.9 optimizer = torch.optim.SGD([w], lr=0.01, momentum=0.9) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() y.backward() optimizer.step() # 参数更新 print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 y = ((w ** 2) / 2.0).sum() optimizer.zero_grad() y.backward() optimizer.step() # 参数更新 print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) test01()
结果:
第1次: 梯度w.grad: 2.000000, 更新后的权重:1.980000 第2次: 梯度w.grad: 1.980000, 更新后的权重:1.942200
Stochastic Gradient Descent是随机梯度下降
第一次梯度值为d1 = s1 = ω1=2,第一次更新权重:ω2 = ω1-α*d1 = 2- 0.01*2=1.98。第二次梯度值为1.98,β=0.9,s1=2,d2=s2 = 0.9 * s1 + ω2 * 0.1 = 0.9 * 2 + 1.98 * 0.1 = 1.998,更新后的权重为: 1.98-0.01*1.998=1.96002 ????
(3)、梯度下降的优化方法-adaGrad
其计算步骤如下:
1. 初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2. 初始化梯度累积变量 s = 0
3. 从训练集中采样 m 个样本的小批量,计算梯度 g
4. 累积*方梯度 s = s + g ⊙ g,⊙ 表示各个分量相乘
学习率 α 的计算公式如下:
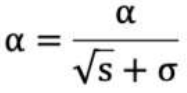
参数更新公式如下:
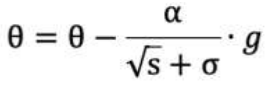
重复 2-4 步骤,即可完成网络训练。
AdaGrad 缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
import torch; def test02(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32) y = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:adagrad优化方法 optimizer = torch.optim.Adagrad ([w], lr=0.01) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() y.backward() optimizer.step() # 参数更新 print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 y = ((w ** 2) / 2.0).sum() optimizer.zero_grad() y.backward() optimizer.step() # 参数更新 print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) test02()
结果:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.990000 第2次: 梯度w.grad: 0.990000, 更新后的权重:0.982965
(4)、梯度下降的优化方法RMSProp
RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数移动加权*均梯度替换历史梯度的*方和。其计算过程如下:
1. 初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2. 初始化参数 θ
3. 初始化梯度累计变量 s
4. 从训练集中采样 m 个样本的小批量,计算梯度 g
5. 使用指数移动*均累积历史梯度,公式如下:
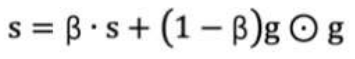
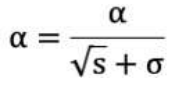

import torch; def test03(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32) y = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:RMSprop算法,其中alpha对应这beta optimizer = torch.optim.RMSprop([w], lr=0.01,alpha=0.9) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() y.backward() optimizer.step() print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 y = ((w ** 2) / 2.0).sum() optimizer.zero_grad() y.backward() optimizer.step() print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) test03()
结果:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.968377 第2次: 梯度w.grad: 0.968377, 更新后的权重:0.945788
(5)、梯度下降的优化方法-Adam
⚫ Momentum 使用指数加权*均计算当前的梯度值
⚫ AdaGrad、RMSProp 使用自适应的学习率
⚫ Adam优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和RMSProp 算法结合在一起。
1.修正梯度: 使⽤梯度的指数加权*均
2.修正学习率: 使用梯度*方的指数加权*均。
import torch def test04(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True) y = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:Adam算法,其中betas是指数加权的系数 optimizer = torch.optim.Adam([w], lr=0.01,betas=[0.9,0.99]) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() y.backward() optimizer.step() print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 y = ((w ** 2) / 2.0).sum() optimizer.zero_grad() y.backward() optimizer.step() print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) test04()
结果:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.990000 第2次: 梯度w.grad: 0.990000, 更新后的权重:0.980003
4、学习率衰减方法
(1)、等间隔学习率衰减

lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)# 功能:等间隔-调整学习率 # 参数: # step_size:调整间隔数=50 # gamma:调整系数=0.5 # 调整方式:lr = lr * gamma
示例:
import torch import torch.optim as optim import matplotlib.pyplot as plt def test_StepLR(): # 0.参数初始化 LR = 0.1 # 设置学习率初始化值为0.1 iteration = 10 max_epoch = 200 # 1 初始化参数 y_true = torch.tensor([0]) x = torch.tensor([1.0]) w = torch.tensor([1.0], requires_grad=True) # 2.优化器 optimizer = optim.SGD([w], lr=LR, momentum=0.9) # 3.设置学习率下降策略 scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5) # 4.获取学习率的值和当前的epoch lr_list, epoch_list = list(), list() for epoch in range(max_epoch): lr_list.append(scheduler_lr.get_last_lr()) # 获取当前lr epoch_list.append(epoch) # 获取当前的epoch for i in range(iteration): # 遍历每一个batch数据 loss = ((w*x-y_true)**2)/2.0 # 目标函数 optimizer.zero_grad() # 反向传播 loss.backward() optimizer.step() # 更新下一个epoch的学习率 scheduler_lr.step() # 5.绘制学习率变化的曲线 plt.plot(epoch_list, lr_list, label="Step LR Scheduler") plt.xlabel("Epoch") plt.ylabel("Learning rate") plt.legend() plt.show() test_StepLR()
结果:
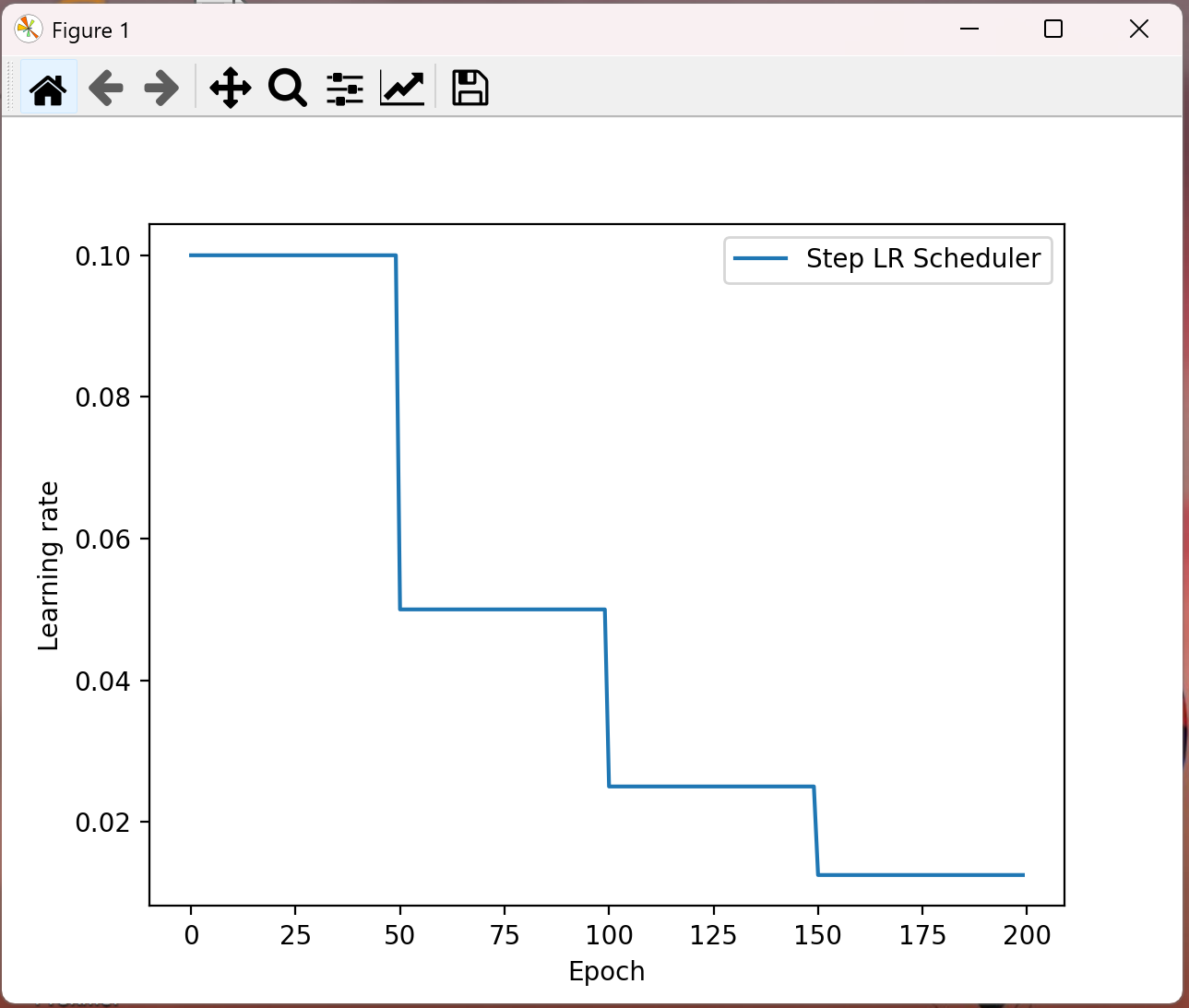
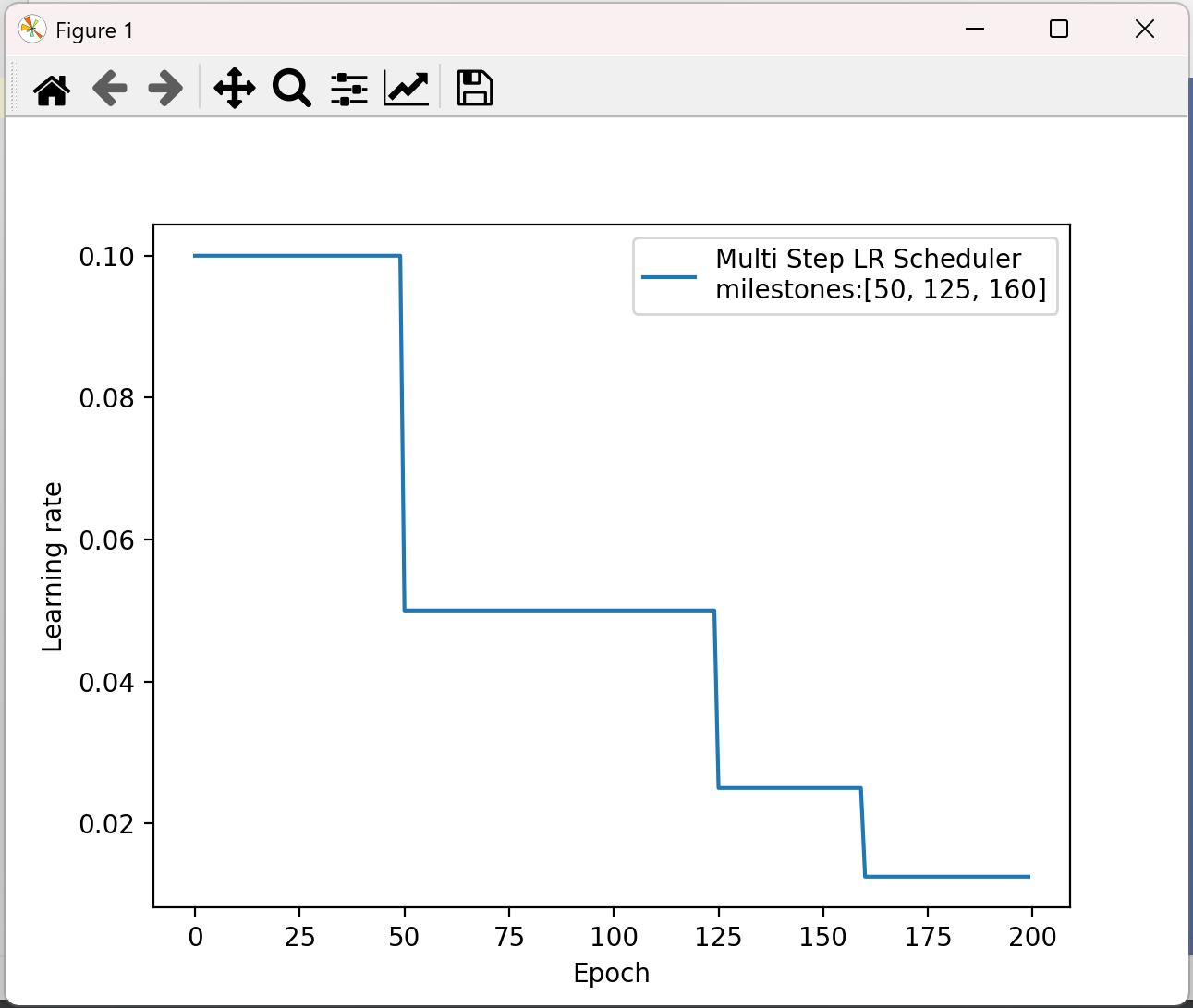
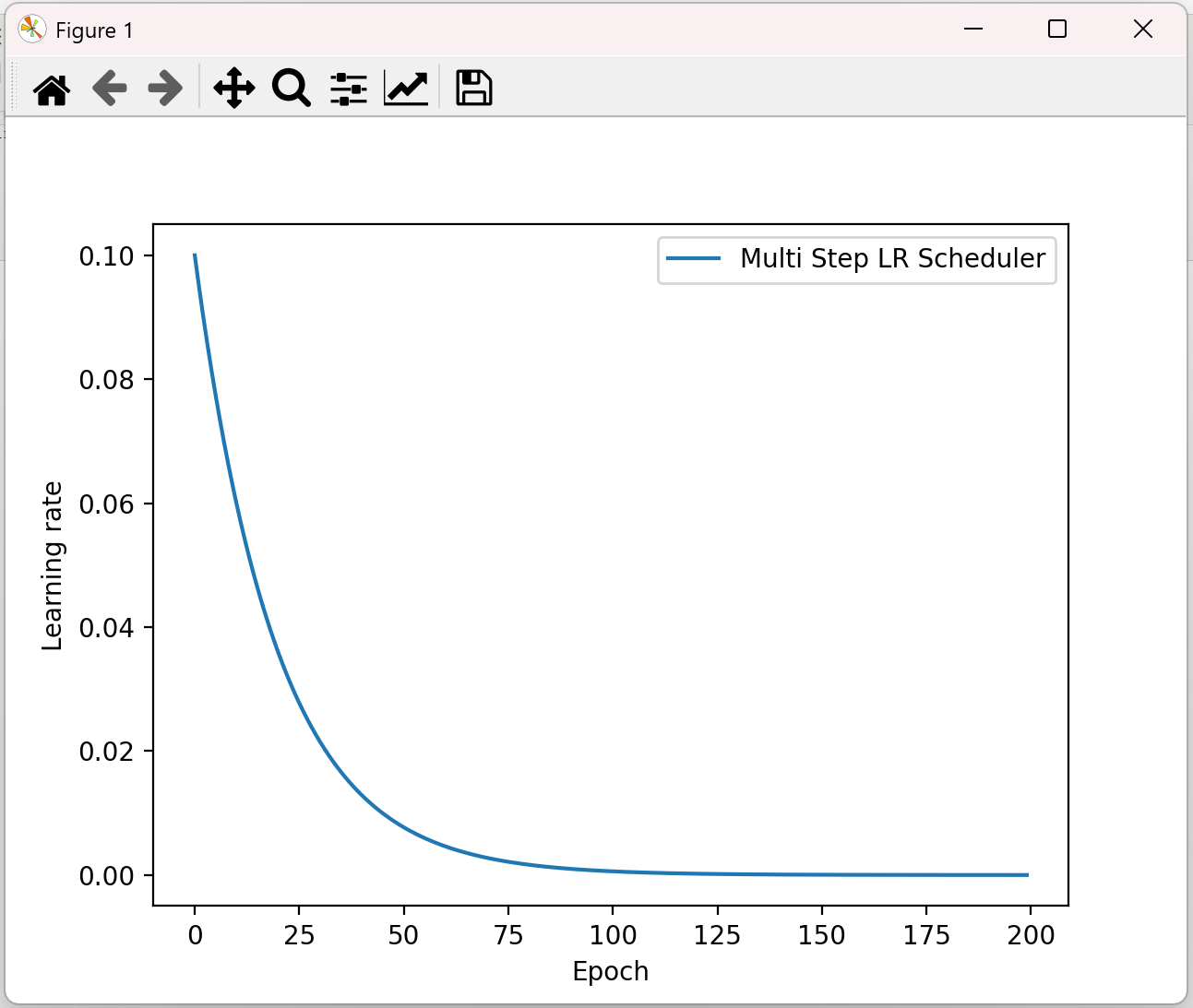
(2)、指定间隔学习率衰减
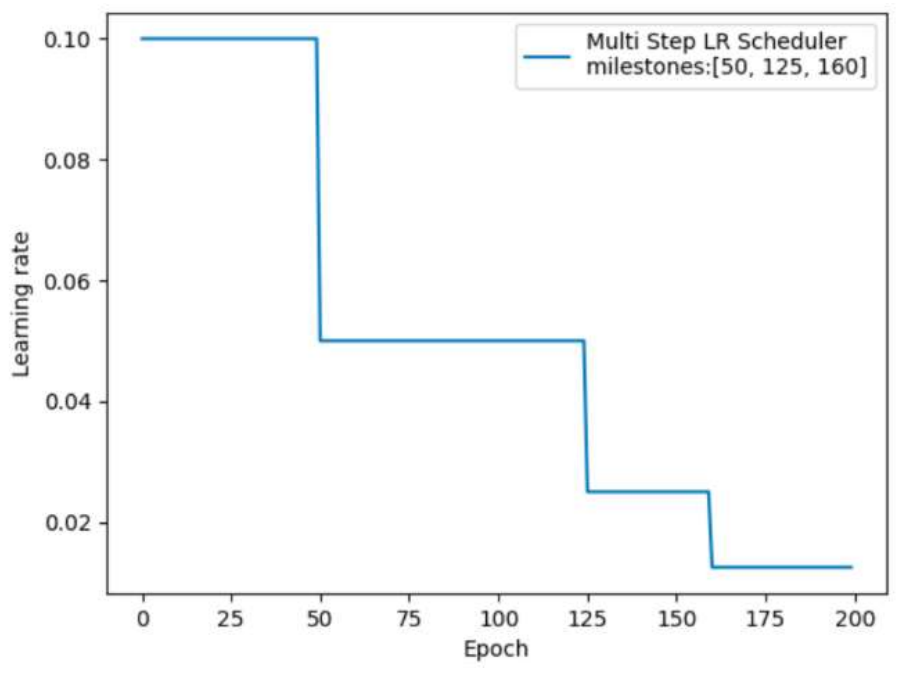
lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1) # 功能:指定间隔-调整学习率 # 主要参数: # milestones:设定调整轮次:[50, 125, 160] # gamma:调整系数 # 调整方式:lr = lr * gamma
示例
import torch import torch.optim as optim import matplotlib.pyplot as plt def test_MultiStepLR(): torch.manual_seed(1) LR = 0.1 iteration = 10 max_epoch = 200 weights = torch.randn((1), requires_grad=True) target = torch.zeros((1)) print('weights--->', weights, 'target--->', target) optimizer = optim.SGD([weights], lr=LR, momentum=0.9) # 设定调整时刻数 milestones = [50, 125, 160] # 设置学习率下降策略 scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer,milestones=milestones, gamma=0.5) lr_list, epoch_list = list(), list() for epoch in range(max_epoch): lr_list.append(scheduler_lr.get_last_lr()) epoch_list.append(epoch) for i in range(iteration): loss = torch.pow((weights - target), 2) optimizer.zero_grad() # 反向传播 loss.backward() # 参数更新 optimizer.step() # 更新下一个epoch的学习率 scheduler_lr.step() plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones)) plt.xlabel("Epoch") plt.ylabel("Learning rate") plt.legend() plt.show() test_MultiStepLR()
结果:
(3)、按指数学习率衰减
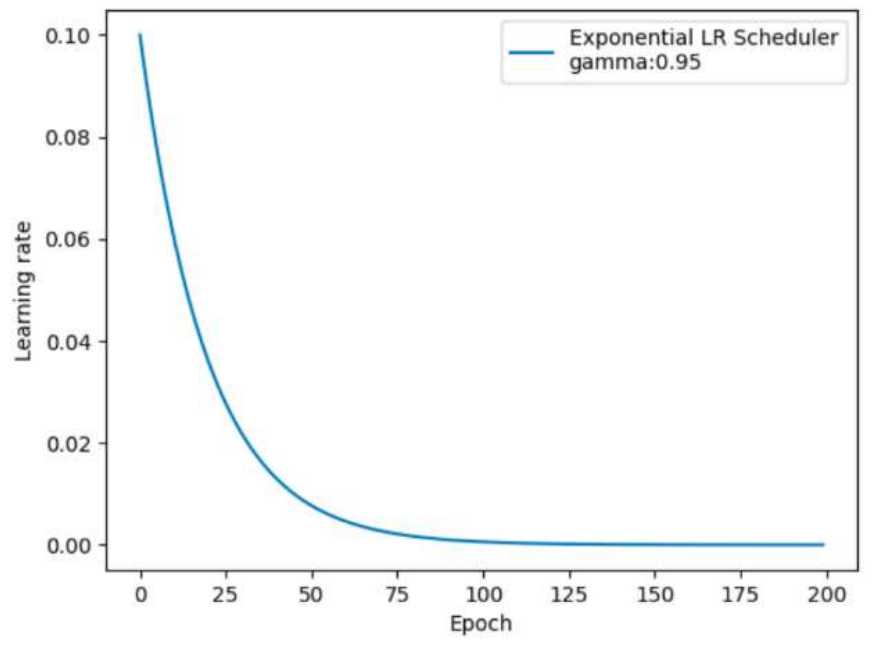
lr_scheduler.ExponentialLR(optimizer, gamma) # 功能:按指数衰减-调整学习率 # 主要参数: # gamma:指数的底 # 调整方式 # lr= lr∗ gamma^epoch
示例:
import torch import torch.optim as optim import matplotlib.pyplot as plt def test_ExponentialLR(): # 0.参数初始化 LR = 0.1 # 设置学习率初始化值为0.1 iteration = 10 max_epoch = 200 # 1 初始化参数 y_true = torch.tensor([0]) x = torch.tensor([1.0]) w = torch.tensor([1.0], requires_grad=True) # 2.优化器 optimizer = optim.SGD([w], lr=LR, momentum=0.9) # 3.设置学习率下降策略 gamma = 0.95 scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma) # 4.获取学习率的值和当前的epoch lr_list, epoch_list = list(), list() for epoch in range(max_epoch): lr_list.append(scheduler_lr.get_last_lr()) epoch_list.append(epoch) for i in range(iteration): # 遍历每一个batch数据 loss = ((w * x - y_true) ** 2) / 2.0 optimizer.zero_grad() # 反向传播 loss.backward() optimizer.step() # 更新下一个epoch的学习率 scheduler_lr.step() # 5.绘制学习率变化的曲线 plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler") plt.xlabel("Epoch") plt.ylabel("Learning rate") plt.legend() plt.show() test_ExponentialLR()
结果:
四、正则化方法
• 在设计机器学习算法时希望在新样本上的泛化能力强。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。
• 神经网络的强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。

• 目前在深度学习中使用较多的策略有范数惩罚,DropOut,特殊的网络层等,接下来我们对其进行详细的介绍。
(1)、Dropout正则化

随机失活DropOut策略:让神经元以超参数p的概率停止工作或者激活被置为0
import torch import torch.nn as nn def test(): # 初始化随机失活层 dropout = nn.Dropout(p=0.4) # 初始化输入数据:表示某一层的weight信息 inputs = torch.randint(0, 10, size=[1, 4]).float() print(inputs) layer = nn.Linear(4,5) y = layer(inputs) print("未失活FC层的输出结果:\n", y) y = dropout(y) print("失活后FC层的输出结果:\n", y) test()
结果:
tensor([[7., 5., 4., 5.]]) 未失活FC层的输出结果: tensor([[ 6.9824, 0.6448, 6.7105, -6.8321, -1.7599]], grad_fn=<AddmmBackward0>) 失活后FC层的输出结果: tensor([[ 0.0000, 0.0000, 0.0000, -11.3869, -0.0000]], grad_fn=<MulBackward0>)
上述代码将 Dropout 层的概率 p 设置为 0.4,此时经过 Dropout 层计算的张量中就出现了很多 0 , 未变为0的按照(1/(1-0.4))进行处理,-6.8321*1/(1-0.4)=11.3868。
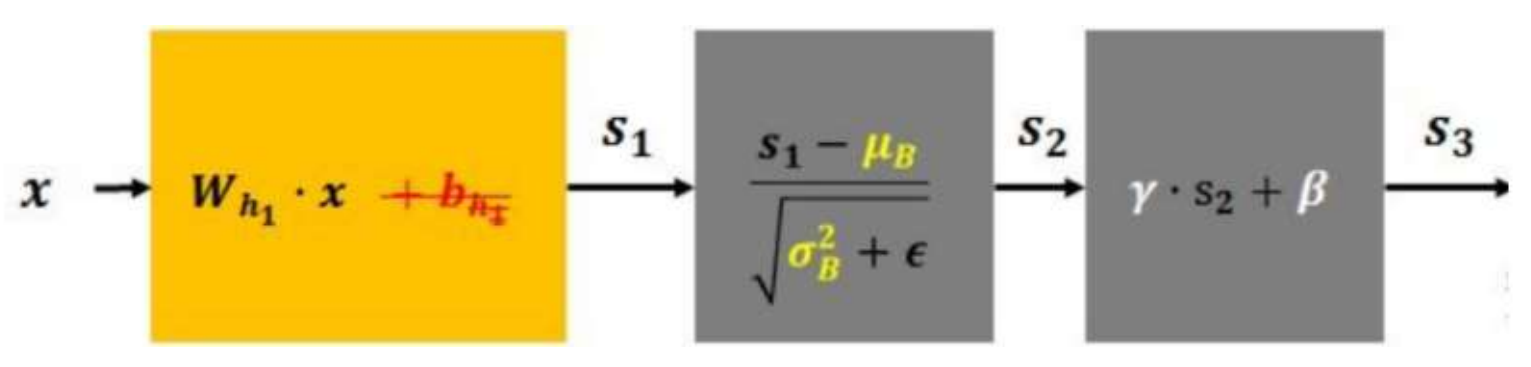
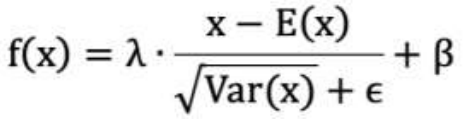
1. λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏置;
2. eps 通常指为 1e-5,避免分母为 0;
3. E(x) 表示变量的均值;
4. Var(x) 表示变量的方差;
五、案例-价格分类案例
1、需求分析

我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。接下来我们还是按照四个步骤来完成这个任务:
⚫ 准备训练集数据
⚫ 构建要使用的模型
⚫ 模型训练
⚫ 模型预测评估
注意:运行之前要新建dataset目录和model目录
# 1.导入相关模块 import torch from torch.utils.data import TensorDataset from torch.utils.data import DataLoader import torch.nn as nn import torch.optim as optim from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt import numpy as np import pandas as pd import time from torchsummary import summary # 2.构建数据集 def create_dataset(): # 使用pandas读取数据 data = pd.read_csv('dataset/手机价格预测.csv') # 特征值和目标值,x为特征值,y为目标值 x, y = data.iloc[:, :-1], data.iloc[:, -1] # 类型转换:特征值,目标值 x = x.astype(np.float32) # 特征值转成float32类型 y = y.astype(np.int64) # 目标值转为int64 # 数据集划分 分成训练数据(x_train、y_train)和测试数据(x_valid、y_valid) x_train, x_valid, y_train, y_valid = train_test_split(x, y, train_size=0.8, random_state=88) # 构建数据集,转换为pytorch的形式 train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.tensor(y_train.values)) valid_dataset = TensorDataset(torch.from_numpy(x_valid.values), torch.tensor(y_valid.values)) # 返回结果 return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y)) # 3.构建网络模型 class PhonePriceModel(nn.Module): def __init__(self, input_dim, output_dim): super(PhonePriceModel, self).__init__() # 1. 第一层:输入维度:20,输出维度:128 self.linear1 = nn.Linear(input_dim, 128) # 2. 第二层:输入维度:128,输出维度:256 self.linear2 = nn.Linear(128, 256) # 3. 第三层:输入维度:256,输出维度:4 self.linear3 = nn.Linear(256, output_dim) def forward(self, x): # 前向传播过程 x = torch.relu(self.linear1(x)) x = torch.relu(self.linear2(x)) output = self.linear3(x) # 获取数据结果 return output # 4.模型训练 def train(train_dataset, input_dim, class_num, ): # 固定随机数种子 torch.manual_seed(0) # 初始化模型 model = PhonePriceModel(input_dim, class_num) # 构建网络模型 # 损失函数 criterion = nn.CrossEntropyLoss() # 优化方法 optimizer = optim.SGD(model.parameters(), lr=1e-3) # 训练轮数 num_epoch = 50 # 遍历每个轮次的数据 for epoch_idx in range(num_epoch): # 初始化数据加载器 dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8) # 训练时间 start = time.time() # 计算损失 total_loss = 0.0 total_num = 1 # 遍历每个batch数据进行处理 for x, y in dataloader: # 将数据送入网络中进行预测 output = model(x) # 计算损失 loss = criterion(output, y) # 根据预测值和目标值计算损失函数 # 梯度归零 optimizer.zero_grad() # 反向传播 loss.backward() # 参数更新 optimizer.step() # 损失计算 total_num += 1 total_loss += loss.item() # 打印损失变换结果 print('epoch: %4s loss: %.2f, time: %.2fs' % (epoch_idx + 1, total_loss / total_num, time.time() - start)) # 模型保存 torch.save(model.state_dict(), 'model/phone.pth') def test(valid_dataset, input_dim, class_num): # 加载模型和训练好的网络参数 model = PhonePriceModel(input_dim, class_num) # 构建网络模型 model.load_state_dict(torch.load('model/phone.pth', weights_only=True)) # 加载模型状态字典 # 构建加载器 dataloader = DataLoader(valid_dataset, batch_size=8, shuffle=False) # 评估测试集 correct = 0 # 遍历测试集中的数据 for x, y in dataloader: # 将其送入网络中 output = model(x) # 获取类别结果 y_pred = torch.argmax(output, dim=1) # 获取预测正确的个数 correct += (y_pred == y).sum() # 求预测精度 print('Acc: %.5f' % (correct.item() / len(valid_dataset))) if __name__ == '__main__': # 1.获取数据 train_dataset, valid_dataset, input_dim, class_num = create_dataset() print("输入特征数:", input_dim) # 20个特征 print("分类个数:", class_num) # 4个目标值 # 2.模型实例化 model = PhonePriceModel(input_dim, class_num) # 构建网络模型 summary(model, input_size=(input_dim,), batch_size=16) # 生成神经网络模型的摘要信息 # 3.模型训练 train(train_dataset, input_dim, class_num) # 4.模型预测 test(valid_dataset, input_dim, class_num)
结果:
输入特征数: 20 分类个数: 4 ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Linear-1 [16, 128] 2,688 Linear-2 [16, 256] 33,024 Linear-3 [16, 4] 1,028 ================================================================ Total params: 36,740 Trainable params: 36,740 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.05 Params size (MB): 0.14 Estimated Total Size (MB): 0.19 ---------------------------------------------------------------- epoch: 1 loss: 13.04, time: 0.14s epoch: 2 loss: 0.97, time: 0.15s epoch: 3 loss: 0.91, time: 0.14s epoch: 4 loss: 0.91, time: 0.17s epoch: 5 loss: 0.87, time: 0.15s epoch: 6 loss: 0.86, time: 0.13s epoch: 7 loss: 0.84, time: 0.13s epoch: 8 loss: 0.84, time: 0.13s epoch: 9 loss: 0.84, time: 0.13s epoch: 10 loss: 0.81, time: 0.13s epoch: 11 loss: 0.81, time: 0.13s epoch: 12 loss: 0.80, time: 0.16s epoch: 13 loss: 0.80, time: 0.15s epoch: 14 loss: 0.80, time: 0.14s epoch: 15 loss: 0.77, time: 0.13s epoch: 16 loss: 0.78, time: 0.13s epoch: 17 loss: 0.78, time: 0.13s epoch: 18 loss: 0.77, time: 0.12s epoch: 19 loss: 0.75, time: 0.13s epoch: 20 loss: 0.78, time: 0.13s epoch: 21 loss: 0.76, time: 0.13s epoch: 22 loss: 0.73, time: 0.13s epoch: 23 loss: 0.73, time: 0.15s epoch: 24 loss: 0.75, time: 0.13s epoch: 25 loss: 0.75, time: 0.13s epoch: 26 loss: 0.73, time: 0.13s epoch: 27 loss: 0.74, time: 0.13s epoch: 28 loss: 0.73, time: 0.13s epoch: 29 loss: 0.74, time: 0.13s epoch: 30 loss: 0.71, time: 0.13s epoch: 31 loss: 0.71, time: 0.13s epoch: 32 loss: 0.72, time: 0.14s epoch: 33 loss: 0.70, time: 0.14s epoch: 34 loss: 0.70, time: 0.13s epoch: 35 loss: 0.71, time: 0.14s epoch: 36 loss: 0.71, time: 0.14s epoch: 37 loss: 0.70, time: 0.13s epoch: 38 loss: 0.69, time: 0.13s epoch: 39 loss: 0.71, time: 0.13s epoch: 40 loss: 0.71, time: 0.12s epoch: 41 loss: 0.69, time: 0.13s epoch: 42 loss: 0.68, time: 0.14s epoch: 43 loss: 0.70, time: 0.14s epoch: 44 loss: 0.68, time: 0.13s epoch: 45 loss: 0.67, time: 0.13s epoch: 46 loss: 0.69, time: 0.13s epoch: 47 loss: 0.68, time: 0.14s epoch: 48 loss: 0.67, time: 0.13s epoch: 49 loss: 0.68, time: 0.15s epoch: 50 loss: 0.66, time: 0.16s Acc: 0.64250
我们前面的网络模型在测试集的准确率为: 0.54750, 我们可以通过以下方面进行调优:
1. 优化方法由 SGD 调整为 Adam
2. 学习率由 1e-3 调整为 1e-4
3. 对数据数据进行标准化
4. 增加网络深度, 即: 增加网络参数量
5. 调整训练轮次
6. ………..
import pandas as pd data = pd.read_csv('dataset/手机价格预测.csv') data
结果:

获取所有行,最后一列去掉,去掉最后一列的所有列称为特征值
x=data.iloc[:, :-1] x
结果:
获取所有行,只取最后一列,最后一列为目标值
y=data.iloc[:, -1] y
结果:
0 1 1 2 2 2 3 2 4 1 .. 1995 0 1996 2 1997 3 1998 0 1999 3 Name: price_range, Length: 2000, dtype: int64
train_test_split
from sklearn.model_selection import train_test_split
(2)、使用train_test_split函数进行数据划分:
X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size=0.25, random_state=0)
其中,train_data是特征数据集,train_target是目标变量,test_size指定测试集的比例或数量,random_state用于设置随机数种子以确保结果的可重复性
参数说明
- arrays:输入的数据集,可以是一个数组或多个数组(特征矩阵和目标向量)。确保所有数组的第一维长度相同。
- test_size:测试集的大小,可以是浮点数(表示比例)或整数(表示样本数量)。默认值为0.25,即25%的数据作为测试集。
- train_size:训练集的大小,与
test_size相对应。如果未指定,将自动计算为1 -test_size。 - random_state:随机数种子,用于确保可重复的随机划分。可以设置一个整数来复现结果。
- shuffle:是否在划分前对数据进行洗牌,默认为True。
- stratify:是否根据目标变量进行分层抽样,确保训练集和测试集中的类别分布相似。默认为None
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(x, y, train_size=0.8, random_state=88)
x_train
x_train和y_train表示训练数据。x_train结果如下:

y_train:
231 3 1016 0 1035 0 1490 1 834 3 .. 613 0 916 0 362 3 433 1 288 1 Name: price_range, Length: 1600, dtype: int64
x_valid和y_valid表示测试数据,x_valid的值如下:
y_valid
1059 2 929 0 1506 1 237 3 1371 2 .. 1700 0 336 3 1820 0 1540 2 1686 3 Name: price_range, Length: 400, dtype: int64
将训练集的特征值数据转换为数组
x_train.values
结果如下:
array([[1.313e+03, 1.000e+00, 1.800e+00, ..., 0.000e+00, 1.000e+00, 1.000e+00], [5.510e+02, 1.000e+00, 2.800e+00, ..., 1.000e+00, 0.000e+00, 1.000e+00], [1.696e+03, 0.000e+00, 1.700e+00, ..., 0.000e+00, 1.000e+00, 1.000e+00], ..., [1.976e+03, 1.000e+00, 7.000e-01, ..., 0.000e+00, 1.000e+00, 1.000e+00], [1.464e+03, 0.000e+00, 5.000e-01, ..., 1.000e+00, 0.000e+00, 0.000e+00], [1.191e+03, 0.000e+00, 1.300e+00, ..., 1.000e+00, 0.000e+00, 1.000e+00]])
将NumPy数组转换为张量
import torch x_train_tensor = torch.from_numpy(x_train.values) x_train_tensor
结果:
tensor([[1.3130e+03, 1.0000e+00, 1.8000e+00, ..., 0.0000e+00, 1.0000e+00, 1.0000e+00], [5.5100e+02, 1.0000e+00, 2.8000e+00, ..., 1.0000e+00, 0.0000e+00, 1.0000e+00], [1.6960e+03, 0.0000e+00, 1.7000e+00, ..., 0.0000e+00, 1.0000e+00, 1.0000e+00], ..., [1.9760e+03, 1.0000e+00, 7.0000e-01, ..., 0.0000e+00, 1.0000e+00, 1.0000e+00], [1.4640e+03, 0.0000e+00, 5.0000e-01, ..., 1.0000e+00, 0.0000e+00, 0.0000e+00], [1.1910e+03, 0.0000e+00, 1.3000e+00, ..., 1.0000e+00, 0.0000e+00, 1.0000e+00]], dtype=torch.float64)
将训练集的目标值数据转换为数组
y_train.values
结果:
array([3, 0, 0, ..., 3, 1, 1], dtype=int64)
将NumPy数组转换为张量
torch.tensor(y_train.values)
结果:
tensor([3, 0, 0, ..., 3, 1, 1])
TensorDataset
TensorDataset是Pytorch中的一个类,用于将多个Tensor对象打包成一个数据集对象,以便在训练过程中方便地成对取出数据和标签,并进行数据批次处理、打乱顺序等操作。TensorDataset特别适合用于监督学习场景,其中每个输入样本都有对应的标签或目标。
使用方法:
(1)、创建TensorDataset:使用TensorDataset将这些数据打包在一起。
import torch data = torch.randn(100, 3, 32, 32) # 100个样本,每个样本有3个通道,32x32大小的图像 labels = torch.randint(0, 10, (100,)) # 100个样本,每个样本的标签是一个0-9之间的随机整数 dataset = TensorDataset(data, labels)
(2)、使用DataLoader:创建好的TensorDataset可以与DataLoader配合使用,以实现数据的批处理、随机化、并行加载等功能。例如:
from torch.utils.data import DataLoader data_loader = DataLoader(dataset, batch_size=10, shuffle=True) for batch_data, batch_labels in data_loader:
print(batch_data) # 特征数据
print(batch_labels) # 目标数据
案例中的代码:
# 构建数据集,转换为pytorch的形式 train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.tensor(y_train.values)) valid_dataset = TensorDataset(torch.from_numpy(x_valid.values), torch.tensor(y_valid.values))
获取x_train的维度和形状:
x_train.shape
结果:
(1600, 20)
获取x_train的列数:
x_train.shape[1]
结果:20
对y数组进行去重
import numpy as np np.unique(y)
结果:
array([0, 1, 2, 3], dtype=int64)
获取目标值的个数
len(np.unique(y))
结果:4
load_state_dict
load_state_dict是Pytorch中用于加载模型状态字典的重要函数。其主要作用是将之前保存的模型参数加载到当前模型的实例中,从而恢复模型的训练状态。这对于模型的部署、迁移学习以及持续训练等场景都至关重要
使用load_state_dict()函数加载模型参数的基本步骤如下:
- 定义一个神经网络模型。
- 保存模型的
state_dict,通常是通过调用model.state_dict()方法获取。 - 使用
torch.save()函数将state_dict保存到文件中。 - 在需要时,使用
torch.load()函数加载保存的state_dict。 - 使用
model.load_state_dict()方法将加载的state_dict应用到当前模型实例上。
import torch import torch.nn as nn # 定义一个简单的神经网络模型 class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(10, 2) def forward(self, x): return self.fc(x) # 实例化模型 model = SimpleModel() # 假设我们已经有了一个保存了模型参数的state_dict state_dict = {'fc.weight': torch.randn(2, 10), 'fc.bias': torch.randn(2)} # 使用load_state_dict()加载模型参数 model.load_state_dict(state_dict) # 现在, model的fc层的权重和偏置已经被更新为state_dict中的值
应用场景
load_state_dict()在深度学习中有着广泛的应用,特别是在迁移学习和模型复用方面:
- 迁移学习:在迁移学习中,我们通常会将一个在大型数据集上预训练好的模型(如ResNet-50)迁移到新的任务或数据集上。通过加载预训练模型的参数,并修改输出层以适应新的类别数,可以快速开始新任务的学习。
- 模型复用:在模型的持续训练或部署中,通过加载之前保存的模型状态,可以快速恢复模型的训练状态或进行部署,减少训练时间和资源消耗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号