

http://web.cse.ohio-state.edu/hpcs/WWW/HTML/publications/papers/TR-11-7.pdf
- Introduce
样例sql语句:“what is the average number of pages a user visits between a page in category X and a page in category Y?”![]()
![]()
- MR对复杂查询有限制(Limitations of MapReduce for Complex Queries):
- MR在本地磁盘保存中间文件(为了容错),临时结果需要存到hdfs
- hadoop不感知并行job之间的关联
- 查询内关联(Intra-query Correlations)
- 背景。 很简明扼要的介绍了MR、hive的运行机制。
- 关联识别的MR概述。III. CORRELATION-AWARE MAPREDUCE: AN OVERVIEW
说明为什么要做关联识别:MR对中间结果的处理要比DBMS要代价高很多,所以将多个操作集中在一个MR中效率高。 the way of executing multiple operations in a single job (many-to-one), if possible, could be a much more effective choice than the one-to-one translation - 内部关联以及优化原理。IV. INTRA-QUERY CORRELATIONS AND THEIR
OPTIMIZATION PRINCIPLES
- 关联类型和优化收益Types of Correlations and the Optimization Benefits
- 输入关联:Multiple nodes have input correlation
(IC) if their input relation sets are not disjoint
两个操作可以共享一个表扫描 - 转换关联Transit Correlation: Multiple nodes have transit correlation
(TC) if they have not only input correlation, but
also the same partition key;
存在数据交叠,存在冗余的IO操作 - 流程关联。Job Flow Correlation: A node has job flow correlation
(JFC) with one of its child nodes if it has the same
partition key as that child node
后面的MR可以在前一个MR的reduce里面直接执行 - 带group的聚合。An aggregation node with grouping can be directly executed in the reduce function of its only child node;
- A join node J1 has job flow correlation with only one
of its child nodes C1. Thus as long as the job of another
child node of this join node C2 has been completed, a
single job is sufficient to execute both C1 and J1
- A join node J1 has job flow correlation with two child
nodes C1 and C2. Then, according to the correlation
definitions, C1 and C2 must have both input correlation
and transit correlation. Thus a single job is sufficient to
execute both C1 and C2. Besides, J1 can also be directly
executed in the reduce phase of the job
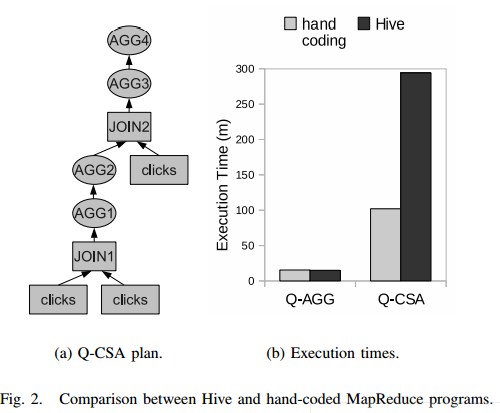
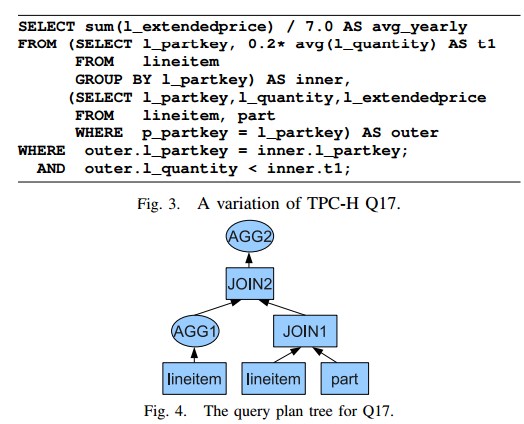
- An Example of Correlation Query and Its Optimization
sql以及原始的执行计划(3个MR)![]()
![]()
Ysmart后:![]()
- YSmart如何残生job V. JOB GENERATION IN YSMART
- Primitive Job Types,4中原生操作类型:
- 选择和投影。A SELECTION-PROJECTION (SP) Job is used to execute
a simple query with only selection and projection
operations on a base relation
- 聚合。An AGGREGATION (AGG) job is used to execute
aggregation and grouping on an input relation
- 关联合并。A JOIN job is used to execute an equi-join (inner or left/right/full outer) of two input relations;
- 排序。A SORT job is used to execute a sorting operation.
- Job Merging job合并
输入关联和转换关联将在map里面合并;流程关联将在reduce里面合并 - rule 1:如果两个job有输入关联和转换关联,将被合并。If two jobs have input correlation and transit correlation, they will be merged into a common job.
- Rule 2: 一个聚合job如果仅与它前面的一个job有流程关联,那该聚合job可以合并到前面job的reduce中。An AGGREGATION job that has job flow correlation
with its only preceding job will be merged into this
preceding job.
- Rule 3: 如果一个join job与它前面的两个job有输入关联,这个join job可以合并。For a JOIN job with job flow correlation with its
two preceding jobs, the join operation will be merged into the
reduce phase of the common job。 In this case, there must be
transit correlation between the two preceding jobs, and the two
jobs have been merged into a common job in the first step.
Based on this, the join operation can be put into the reduce
phase of the common job
- Rule 4: For a JOIN job that has job flow correlation with
only one of its two preceding jobs, merge the JOIN job with
the preceding job with job flow correlation – which has to be
executed later than the other one.
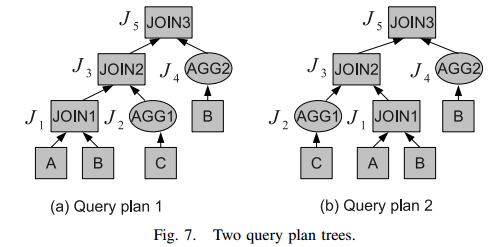
- An Example of Job Merging
We assume that 1) JOIN1 and AGG2 have input correlation and transit correlation, 2) JOIN2 has job flow correlation with JOIN1 but not AGG1, and 3) JOIN3 has job flow correlation with both JOIN2 and AGG2. In the figure, we show the job number for each node.![]()
后续遍历执行计划,得到job序列:{J1, J2, J3, J4, J5}. 执行rule 1 得到{J1+4, J2, J3, J5}. 执行其他规则得到{J1+4, J2, J3+5}. -》s {J2, J1+4+3+5} - 通用MR框架。VI. THE COMMON MAPREDUCE FRAMEWORK
解决两个问题: - The first requirement is to provide a flexible framework
to allow different types of MapReduce jobs
- The second requirement is to execute multiple merged jobs in a common job with minimal overhead
- CMF提供合并两个关联job的通用模板。CMF provides a general template based approach to generate
a common job that can merge a collection of correlated
jobs。The template has the following structures. The common
mapper executes operations (selection and/or projection
operations) involved in the map functions of merged jobs.
The common reducer executes all the operations (e.g. join or
aggregation) involved in the reduce functions of merged jobs.
The post-job computation is a subcomponent in the common
reducer to execute further computations on the outputs of
merged jobs.
- Common Mapper
读取一行数据,然后产生key-value给所有的被合并的job。由于不同的被合并的job有不同的选择条件,所有common mapper需要记录job对应哪些数据。 - 投影信息被保存在job级别的配置属性中;
- 每个值都有一个tag指明哪个reduce会用到这个值。(记录不使用这个值的job id)
- Common Reducer and Post-job Computations
common reduce不限制他能实现的功能。它读一些列key-value,按投影信息分配给所有的被合并的reducer(这些reducer有三个接口)
1)init; 2) next 处理每个值;3)final 计算所有值
这样又两个优点:通用且允许任何类型的reducer被合并;高效,因为只有一次迭代遍历。
common reducer输出结果到hdfs,并且外加一个tag指明这个结果来自哪个源。
如果存在job-a存在流程关联,将立即在post-job流程中计算这个job-a,并且输出的结果是job-a的结果。![]()
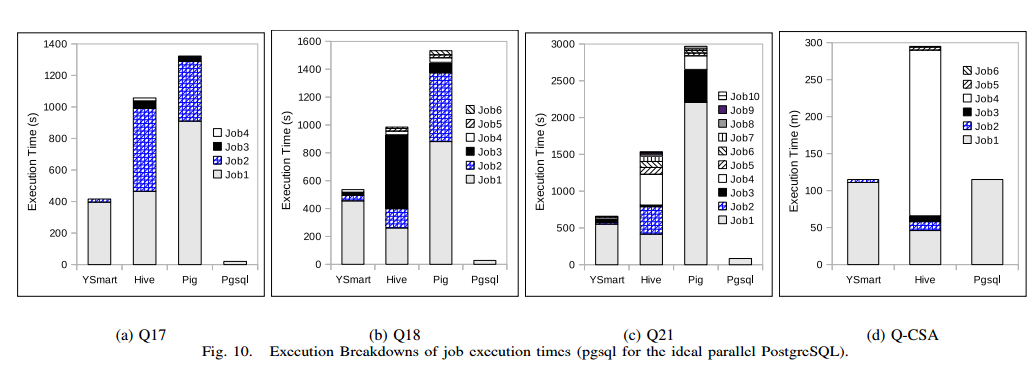
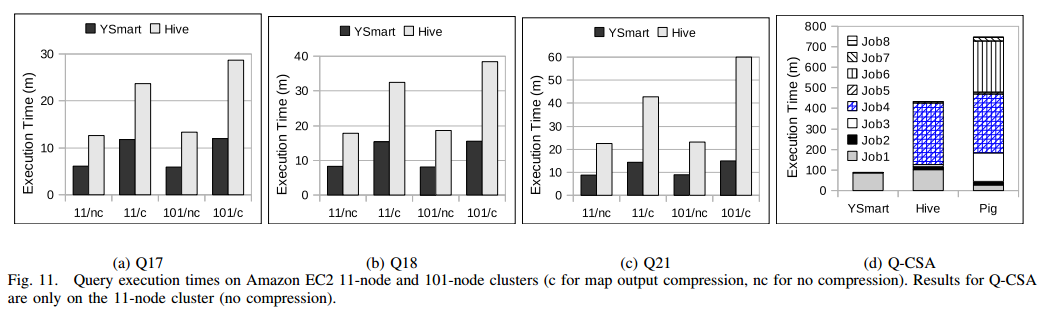
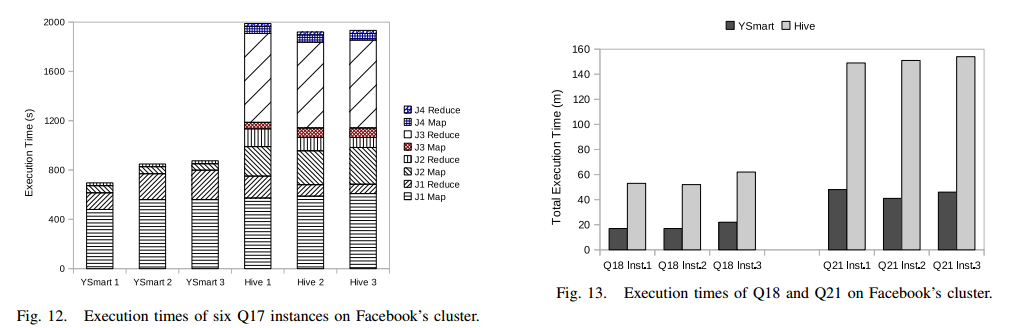
- 负载分析。Workloads and Analysis
![]()
![]()
![]()
![]()
![]()







 浙公网安备 33010602011771号
浙公网安备 33010602011771号