
浅谈rocketmq
rocketmq主要由4部分组成:Producer、Consumer、Broker、NameServe
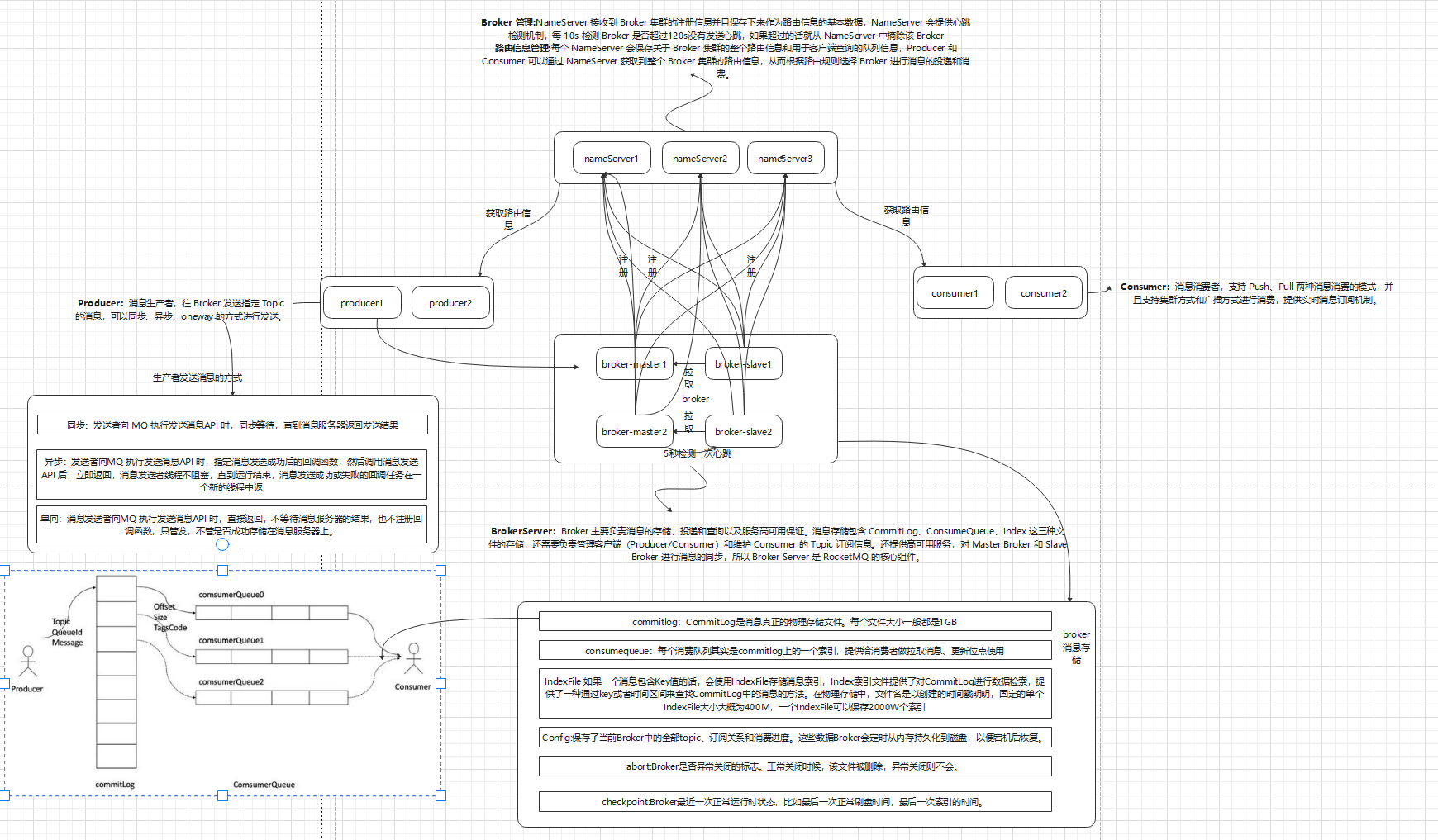
- NameServer:整个集群的注册中心和配置中心,管理集群的元数据。包括 Topic 信息和路由信息、Producer 和 Consumer 的客户端注册信息、Broker 的注册信息。
- Broker:负责接收消息的生产和消费请求,并进行消息的持久化和消息的读取。
- Producer:负责生产消息。
- Consumer:负责消费消息。
RocketMQ 网络模型
RocketMQ 的 Broker 端基于 Netty 实现了主从 Reactor 模型
rocketmq为什么高效?
保证高效写
保证高效读
零拷贝 : 使用mmap的方式进行零拷贝,提高了数据传输的效率
如何保证高效写
1,顺序写: 顺序写比随机写的性能会高很多,不会有大量寻址的过程
先Broker是以顺序的方式将消息写入CommitLog磁盘文件的,也就是每次写入就是在文件末尾追加一条数据就可以了,对文件进行顺序写的性能要比对文件随机写的性能提升很多。
2.异步刷盘 : 相比较于同步刷盘,异步刷盘的性能会高很多
消息写入CommitLog文件的时候,并不是直接写入磁盘文件的,而是先进入OS的PageCache内存缓存中,然后再由OS的后台线程选一个时间,异步化的将OS PageCache内存缓冲中的数据刷入底层的磁盘文件。
异步刷盘的利弊:异步刷盘的的策略下,可以让消息写入吞吐量非常高,但是可能会有数据丢失的风险。rocketmq提供了同步刷盘,让使用者可选择。如果你使用同步刷盘模式的话,那么生产者发送一条消息出去,broker收到了消息,必须直接强制把这个消息刷入底层的物理磁盘文件中,然后才会返回ack给producer,此时你才知道消息写入成功了。
如何保证高效读
为了提高读取的效率,RocketMQ使用ConsumeQueue作为消费消息的索引,使用IndexFile作为基于消息key的查询的索引。
ConsumeQueue:RocketMQ专门建立了ConsumeQueue索引文件,每次先从ConsumeQueue中获取需要的消息的地址,消息大小,然后从CommitLog文件中根据地址直接读取消息内容。在读取消息内容的过程中,也尽量利用到了操作系统的页缓存机制,进一 步加速读取速度。
IndexFile :IndexFile逻辑上是基于哈希表来实现的,Slot Table为哈希键,Index Linked List中存储的为哈希值。
RocketMQ存储架构
- abort:该文件在broker启动时创建,关闭时删除,如果broker异常退出,则文件会存在,在下次启动时会走修复流程;
- checkpoint:检查点,主要存放以下内容:
- physicMsgTimestamp:commitlog文件最后一次落盘时间;
- logicsMsgTimestamp:consumequeue最后一次落盘时间;
- indexMsgTimestamp:索引文件最后一次落盘时间;
- commitlog:存放消息的完整内容,所有的topic消息都会通过文件追加的形式写入到该文件中;
- config:消息队列的配置文件,包括了topic配置,消费的偏移量等信息。其中consumerOffset.json文件存放消息队列消费的进度;
- consumequeue:topic的逻辑队列,在消息存放到commitlog之后,会把消息的存放位置记录到这里,只有记录到这里的消息,才能被消费者消费;
- index:消息索引文件,通过Message Key查询消息时,是通过该文件进行检索查询的。
RocketMQ消息是如何存储的
消息投递到Broker之后,是先把实际的消息内容存放到CommitLog中的,然后再把消息写入到对应主题的ConsumeQueue中。其中:
CommitLog:消息的物理存储文件,存储实际的消息内容。每个Broker上面的CommitLog被该Broker上所有的ConsumeQueue共享。
单个文件大小默认为1G,文件名长度为20位,左边补零,剩余为起始偏移量。预分配好空间,消息顺序写入日志文件。当文件满了,则写入下一个文件,下一个文件的文件名基于文件第一条消息的偏移量进行命名;
ConsumeQueue:消息的逻辑队列,相当于CommitLog的索引文件。RocketMQ是基于Topic主题订阅模式实现的,每个Topic下会创建若干个逻辑上的消息队列ConsumeQueue,在消息写入到CommitLog之后,通过Broker的后台服务线程(ReputMessageService)不停地分发请求并异步构建ConsumeQueue和IndexFile(索引文件,后面介绍),然后把每个ConsumeQueue需要的消息记录到各个ConsumeQueue中。
为什么RocketMQ没有使用Zookeeper,而自己写了一套nameserver来进行注册?
1.nameserver之间没有数据交互,就避免了脑裂问题(集群间网络中断,分成了2边,同时选举之后出现2个主节点。当网络恢复后,就会出现脑裂问题);
2.作为注册中心的功能,zookeeper保证的是CP(数据一致),没有保证A(高可用)——内部选举时,zookeeper服务是不可用的。在rocketmq服务中,保证的是AP,原因是若broker数据不是最新,可以接受消息重新发送。(C数据一致性,A高可用,P网络容忍度)
3.nacos,做通用的服务注册和配置的功能。再rocketMQ中没有配置信息,仅仅只有服务注册,使用nacos会使得架构变得复杂(版本问题等等)
nameserver如果全部挂了还能发消息嘛?
producer会从nameserver上拉取broker的消息,存到本地缓存,在发消息时从缓存中获取broker地址;同时,每次发消息都会与nameserver发消息确认本地缓存信息是否需要更新。若nameserver挂了,则这个确认则得不到回复,如果当下并不需要更新broker信息,那么producer发消息仍然会成功。
同理,consumer也会从nameserver拉取broker信息到缓存,再每次向nameserver确认是否需要更新broker信息。
Broker如何实现自动故障转移的?
基于Dledger协议实现高可用:
把Dledger融入RocketMQ之后,就可以让一个Master Broker对应多个Slave Broker,也就是说一份数据可以有多分副本,比如一个Master Broker对应两个Slave Broker.
此时一旦Master Broker宕机了,就可以在多个副本,也就是多个Slave中,通过Dledger技术和Raft协议算法进行leader选举,直接将一个Slave Broker选举为新的Master Broker,然后这个新的Master Broker就可以对外提供服务了。
预计整个过程也行只要10秒或者几十秒的时间就可以完成。
RocketMq怎么保证消息不丢失
Producer发送消息阶段:事务消息机制保证消息零丢失
broker消息持久化:RocketMQ配置同步刷盘+Dledger主从架构保证MQ自身不会丢消息
Consumer消费消息阶段:补偿消费+幂等校验
如果 Broker 宕机了怎么办?
如果生产者和消费者向一台已经挂了的 Broker 发送或者拉取消息必然是徒劳的,那如何保证 Broker 挂了之后,能够迅速的通知到整个系统的各个组件和上下游呢?
要解决这个问题,靠的就是 Broker 和 NameServer 之间的心跳机制。
每隔 30 秒,Broker 就会向集群里所有的 NameServer 发送心跳连接,告诉它们自己的最新状态,NameServer 接收到之后会更新这个 Broker 的最近一次心跳时间。
然后 NameServer 会每隔 10 秒去检查各个 Broker 的最近一次心跳时间,如果某个 Broker 超过 120 秒都没发送心跳了, 那么就认为这个 Broker 已经挂掉了,NameServer 就知道现在集群中的 Broker 已经少了一台。
对于生产者而言,可以考虑不发送消息到那台 Broker,改成发到其他Broker上去。对于消费者而言,每个 Broker 都有 Slave 节点进行备份,可以继续从 Slave 上去拉取信息从而继续使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号