zookeper简称zk
了解zk,从这几个方面入手:概念,特性,提供什么,选举机制,zk底层工作原理,zk监听原理,zk 分布式锁原理,恕我直言,很多人写的东西让人抓不住重点,因此才想自己总结一篇。
1. 概念(zk是什么):
它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
2. ZooKeeper的特性:
顺序一致性,从同一个客户端发起的事务请求,最终将会严格地按照其发起顺序被应用到Zookeeper中去。
原子性,所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,即整个集群要么都成功应用了某个事务,要么都没有应用。
单一视图,无论客户端连接的是哪个 Zookeeper 服务器,其看到的服务端数据模型都是一致的。
可靠性,一旦服务端成功地应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会一直被保留,除非有另一个事务对其进行了变更。
实时性,Zookeeper 保证在一定的时间段内,客户端最终一定能够从服务端上读取到最新的数据状态。
3.提供了什么
参考自:https://blog.csdn.net/u011506543/article/details/82027453
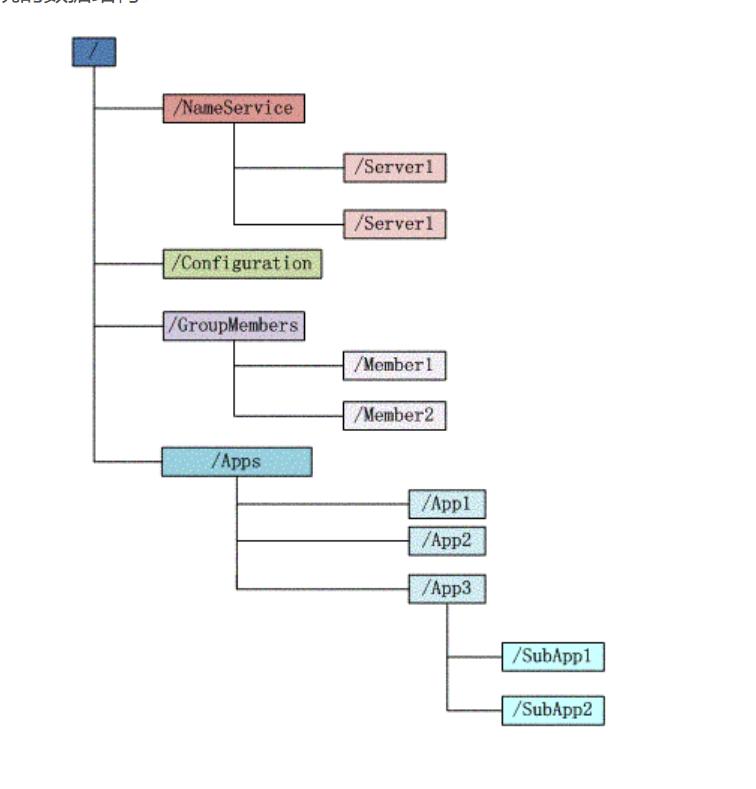
简单的说,zookeeper=文件系统+通知机制。
3.1通知机制
![]()
每个子目录项如 NameService 都被称作为 znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
说明:有四种类型的znode
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、 PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
3.2 通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
有四种类型的znode:
1、PERSISTENT-持久化目录节点 ,客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点 ,客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点 ,客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
4.选举机制(从角色,Serverid,Zxid,Epoch,Server状态,选举原则,选主流程方面入手)
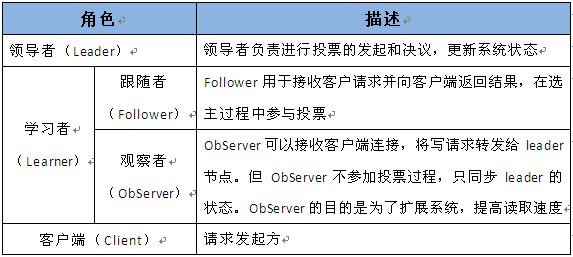
4.1角色
![]()
4.2 ServiceId(服务器id)
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
4.3 Zxid:数据id
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
4.4Epoch:逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
4.5 Server状态:选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
4.6选举原则:
(1)Zookeeper集群中只有超过半数以上的服务器启动,集群才能正常工作;
(2)在集群正常工作之前,myid小的服务器给myid大的服务器投票,直到集群正常工作,选出Leader;
(3)选出Leader之后,之前的服务器状态由Looking改变为Following,以后的服务器都是Follower。
4.7选举流程
口语化解释:
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
专业术语:
5. 底层工作原理:
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
7. zk 分布式锁原理:
利用临时节点与 watch 机制。每个锁占用一个普通节点 /lock,当需要获取锁时在 /lock 目录下创建一个临时节点,创建成功则表示获取锁成功,失败则 watch/lock 节点,有删除操作后再去争锁。
临时节点好处在于当进程挂掉后能自动上锁的节点自动删除即取消锁。
redis 分布式锁和 zk 分布式锁的对比
1、redis 分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
2、zk 分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小。
3、如果是 redis 获取锁的那个客户端 出现 bug 挂了,那么只能等待超时时间之后才能释放锁;而 zk 的话,因为创建的是临时 znode,只要客户端挂了,znode 就没了,此时就自动释放锁。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号