

自己总结的面试题
(Java基础)
一.ReenTrantLock和Synchronized区别和原理
相同点:
1.都是可重入锁
2.堵塞式同步,当一个线程获取到了对象锁,进入到了同步块,其他访问该同步块的线程都必须进入堵塞状态
3.加锁方式同步
不同点:
1.sychronized通过JVM加锁解锁;reentrantLock需要手动加锁解锁
2.sychronized不可中断,除非抛出异常;reentrantLock可中断,如果线程长期不释放锁,正在等待的线程可以放弃等待
3.reentrantLock提供更高级的功能,比如isFair(),isLocked()
Synchronized原理:
synchronized进行编译的时候,会在同步块前后形成monitorenter和monitorexit这两个字节码指令,执行monitorenter指令时,会尝试获取对象锁,如果对象没有被锁定,或者当前线程已经拥有了这把对象锁时,就会在锁的计算器上加1,在执行monitorexit指令时,就会将锁的计算器减1,当这个锁的计算器为0时,这个锁就被释放了,如果获取对象锁失败,那当前线程就会进行堵塞,直到对象锁被另一个线程释放
monitorenter:
每个对象都有一个监视器锁,当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时会尝试获取monitor的所有权,过程如下:
1.当monitor的进入数为0时,则该线程就会进入monitor,然后将进入数设置为1,该线程就是monitor的所有者
2.当线程已经占有这个monitor,只是重新进入,则进入monitor的进入数加1
3.当其他线程已经占用这个monitor,则该线程进入堵塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权
monitorexit:
执行monitorexit的线程必须是objecttref所对应的monitor的所有者
执行指令时,monitor的进入数减1,如果减1后进入数为0,则线程就退出monitor,不再是这个monitor的所有者,其他被这个monitor堵塞的线程就可以尝试获取这个monitor的所有权
ReentrantLock原理:
比synchronized提供了更高级的功能,主要有以下3项:
1.等待可中断锁:
只有锁的线程长期不释放的时候,正在等待的线程可以放弃等待
2.公平锁:
多个线程等待同一个锁时,必须按照申请锁的时间获得锁
3.锁绑定多个条件:
一个ReentrantLock对象可以绑定多个对象,提供了一个Condition类,用来实现分组唤醒需要唤醒的线程,而不是像synchronized要么随机唤醒一个,要么全部都唤醒
二.Mysql的事务
事务的基本要素:ACID
A(原子性):要么不做,要么全部做完,事务执行过程中出错,会进行回滚
C(一致性):事务开始前和结束后,数据库的完整性约束没有被破坏
I(隔离性):同一时间,只允许一个事务请求同一数据,不同事务之间彼此不能有任何干扰
D(持久性):事务完成后,事务对数据库的所有更新将保存到数据库中,不能回滚
事务的并发问题:
脏读:事务A读取了事务B更新后的数据,此时事务B进行了回滚,事务A读到的数据是脏数据
不可重复读:事务A多次读取同一数据,事务B在事务A读取的过程中,对数据进行了修改并提交,导致事务A多次读取数据,结果不一致
幻读:A将具体成绩改成了等级,此时B插入了一条带有具体成绩的数据,A结束后发现还有一条记录没有改过来
不可重复读是侧重修改数据,幻读侧重是新增或者删除数据,不可重复读要锁住满足条件的行,幻读需要锁住表
事务隔离级别:
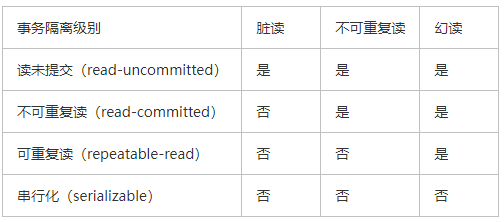
Mysql默认的隔离级别是可重复读
当级别是读未提交时,写数据时锁住对应的行
当级别是可重复读时,如果有索引,默认加锁方式是next-key,如果没有索引,更新数据会锁住整个表
当级别是串行化时,读写数据都会锁住整张表
三.如何创建线程
1.继承Thread类并重写run()方法
2.实现Runable接口,必须重写run方法,没有返回值
3.实现Callable接口,重写call()方法,有返回值
四.线程池
创建和销毁对象很费时间,所以事先创建好多个可执行的线程放到线程池中,需要的时候直接从线程池中获取,使用完后不需要销毁线程而是把它放回线程池中,从而减少创建和销毁线程对象的开销
构造器中各个参数的含义:
核心线程数:创建了线程池之后,线程池中没有任何线程,只有等待有任务到来的时候才会去创建线程执行任务,除非调用prestartAllCoreThreads()或者prestartCoreThread()方法,当线程池中的线程数达到核心线程数后,会把任务放到缓存队列中
最大线程数:标识线程池最多能创建多少个线程
存活时间:默认情况下,只有当线程池中的线程数大于核心线程数,才会起作用
存活单位:单位
堵塞队列:存储等待执行的任务,一般使用LinkedBolockingQueue和Synchronous
线程工厂:用来创建线程
拒绝策略:不再接受任务下发
五.抽象类和接口的区别
抽象类:
含有abstarct修饰符的class就是抽象类,抽象类不能创建实例对象,必须在子类中实现具体行为,不能有抽象构造函数或抽象静态方法,如果子类没有实现抽象父类的所有抽象方法,那么子类也必须定义chengabstarct类型
接口:
是抽象类的一种特例,接口中所有方法都是抽象的,默认是public abstarct类型,接口的成员变量默认是public static final
两者语法区别:
1.抽象类可以有构造方法,接口不能有构造方法
2.抽象类可以有普通成员变量,接口没有普通成员变量
3.抽象类可以包含非抽象方法,接口中所有方法必须是抽象的
4.抽象类的抽象方法的访问类型可以是public或者protected类型,接口中只能是public类型
5.抽象类可以包含静态方法,接口中不能包含静态方法
6.抽象类和接口都可以包含静态成员变量,抽象类的静态成员变量的访问类型是任意的,但接口只能是public static final类型
7.一个类只能继承一个抽象类,但是可以实现多个接口
六.抽象类是否可以使用final修饰
不可以使用final修饰,抽象类就是为了让其他类继承,使用了final,则代表不可以被继承
七.面向对象的特征
封装:把一个对象的属性进行私有化,同时提供一些可以被外界访问属性的方法
继承:在已存在的类的定义作为基础建立新的类,新建立的方法可以增加新的功能
多态:父类引用指向子类对象(实现多态的三个必要条件:继承,重写,向上转型)
八.IO流
按照流的流向划分:输入流,输出流
按照操作单元划分:字节流,字符流
按照流的角色划分:节点流,处理流
InputStream/Reader:所有输入流的基类,前者是字节输入流,后者是字符输入流
OutPutStream/Writer:所有输出流的基类,前者是字节输出流,后者是字符输出流
九.BIO,NIO,AIO的区别
BIO:同步堵塞IO,模式简单,并发处理能力低
NIO:同步非堵塞IO,客户端和服务器通过Cannel(信道)实现通讯,实现了多路复用
AIO:是NIO的升级,实现了一步非堵塞IO,异步IO的操作基于事件和回调机制
十.什么是反射
反射机制:对于任意一个类,都可以知道它的方法及属性,对于任意的对象,都可以调用它的方法和属性,这种动态多去信息以及动态调用对象的方法的功能就是反射
反射的优缺点:
优点:运行期类型的判断,动态加载类,提高代码的灵活度
缺点:性能瓶颈,需要通知JVM做事,比直接的java代码慢
反射机制的应用场景:
1.使用JDBC连接数据库时使用Class.forName()
2.Spring框架的XML配置,通过XML配置状装载Bean,
具体过程:将XML或者properties文件加载到内存中,Java类解析XML或properties的内容,得到对应的信息,利用反射机 制,获取到类的Class实例,并动态的配置实例的属性
Java获取反射的三种方法:
1.通过路径实现反射 Class clazz = Class.forName("xxxx")
2.通过new对象实现反射 Student s = new Student() Class clazz = s.getClass() clazz.getName()
3.通过类名实现反射 Class clazz = Student.class()
十一.String常用方法
indexOf():返回指定字符串的索引
trim():去除字符串两端的空白
length():返回字符串长度
equals:字符串比较
replace():字符串替换
十二.集合
Collection:
List:有序可重复,可以插入多个null元素,元素都有索引
Set:无序不重复,只能存放一个null元素
Map:键值对(key-value)集合,key无序且唯一
底层:
List:
ArrayList:动态数组
LinkedList:双向循环链表
Vector:数组
Set:
HashSet:无序且唯一,基于HashMap实现,底层使用HashMap保存元素
LinkedHashSet:继承HashSet,底层通过LinkedHashMap实现
TreeSet:有序且唯一,底层是红黑树(自平衡二叉树)
Map:
HshMap:在脑子里
LinkedHashMap:继承HashMap,增加了一条双向链表,可以保持键值对的插入顺序
HashTable:数组+链表
TreeMap:红黑树(自平衡的二叉树)
快速失败机制(fail-fast):
线程A通过Iterator遍历元素,线程B修改元素结构,就会快速抛出异常,产生fail-fast机制
原因:迭代器遍历元素时,会改变modCount值,每次使用hasNext遍历下一个元素时,都会检测modCount
十三.Iterator和ListIterator的区别
1.Iterator可以遍历List和Set,ListIterator只能遍历List
2.Iterator只能单向遍历,ListIterator可以双向遍历
3.ListIterator实现了Iterator接口,添加了新的功能,比如添加元素,替换元素等
十四.如何实现数组和List的转换
数组转List:Array.asList(array)
集合转数组:List.toArray()
十五.造成死锁的四个条件以及如何避免死锁
1.互斥条件:一个资源只能被一个线程获取到,一直到被这个线程释放(无法破坏)
2.请求与保持条件:一个线程占用资源发生堵塞时,对已获得的资源保持不放(一次性申请所有的资源)
3.不剥夺条件:线程获取到资源后再未使用完前不能被其他线程剥夺(申请不到,主动释放占有的资源)
4.循环等待条件:发生死锁时,会死循环,造成堵塞(按顺序申请资源)
十六.Java程序如何保证多线程的安全
1.使用原子类AtomicInteger
2.使用自动锁synchronized
3.使用手动锁Lock
十七.Volatile
从可见性而言:保证可见性和禁止指令重排,它确保一个线程的修改能对其他线程是可见的,修改后会立即更新到内存中,其他线程读取时,直接读取内存
从实践角度而言:与CAS结合,保证了原子性,比如AtomicInteger
Volatile是线程同步的轻量级实现,所以性能比synchronized关键字好,但是后来synchronized减少了获取锁和释放锁带来的性能的消耗,实际使用synchronized比较多
十八.乐观锁和悲观锁的理解
悲观锁:假设最坏的情况,认为每次拿数据都会被修改,所以就会上锁,synchronized就是悲观锁
乐观锁:认为每次拿数据不会被修改,但是更新的时候会判断在此期间别人有没有去更新数据,会使用版本号判断
实现方式:使用版本号确定读取到的数据和提交时的数据是否一致,提交会后修改版本号,不一致时会才去丢弃或者再次尝 试的策略
十九.CAS
CAS操作包含三个操作数:内存位置(V),预期原值(A),新值(B)
如果内存地址里面的值和A一样,就将内存里面的值改成B,CAS通过无限循环获取数据,若在第一轮循环中,线程A获取地址里面的值被线程B修改了,线程A就需要自旋
会产生一些问题:
资源竞争激烈的时候,CAS自旋概率比较大,浪费CPU资源
二十.Executors类创建四种常见线程池
1.newSingleThreadExecutor:创建一个单线程的线程池
2.newFixedThreadPool:创建一个固定大小的线程池
3.newScheduledThreadPool:创建一个大小无限的线程池
4.newCachedThreadPool:创建一个可缓存的线程池
(Mysql)
二十一.Mysql中Myisam和Innodb的区别
1.Innodb支持事务,Myisam不支持事务
2.Innodb支持行级锁,Myisam支持表级锁
3.Innodb不支持全文检索,Myisam支持全文检索
二十二.事务隔离级别
读未提交
读已提交
可重复读(默认)
串行化
二十三.为什么Mysql的索引使用的是B+树而不是其他树结构
B-Tree:不管是叶子节点还是非叶子节点都会保存数据,导致在非叶子节点中保存的指针数量变少,增加树的高度,导致IO操作变多,性能变低
Hash:没有顺序,IO复杂度变高
二叉树:高度不均匀,也不能自平衡,查找效率是跟树的高度有关,IO代价高
红黑树:树的高度随着数据的增加而增加,IO代价高
二十四.MyISAM和InnoDB实现B+Tree索引方式的区别
MyISAM:叶子节点的data域存放数据记录的地址,索引检索时,按照B+Tree搜索算法搜索索引,如果指定的Key存在的话,就取出对应的data值,再读取相应的数据
InnoDB:一张表的话一定包含一个聚集索引构成的B+Tree和多个非聚集索引的B+Tree
二十五.为什么不对每个表都创建索引
1.对表中数据进行增加,删除,修改,索引也需要去进行维护,降低了数据的维护速度
2.索引占用物理空间,如果是聚簇索引,需要的空间更大
3.创建索引和维护索引,需要耗费时间
二十六.Mysql执行查询过程
1.客户端通过TCP连接发送连接请求到mysql连接器,连接器会进行权限验证以及资源分配
2.判断缓存是否被命中,Mysql不会去解析SQL语句
3.语法判断,检查数据表和数据列是否存在
4.优化,是否使用索引
5.交给执行器,将数据保存到结果集中,并将数据缓存到查询缓存中,将结果返回给客户端
二十七.MVCC
多版本并发控制,通过保存数据的某时间点的快照来实现,根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能不一样
实现原理:InnoDB的每一行数据都有一个隐藏的回滚指针,指向修改前的最后一个历史版本,存在在undo log,如果执行更新操作,将原记录放入undo log,并通过隐藏的回滚指针指向undo log的原记录,MVCC最大的好处就是读不加锁,读写不冲突,增加了Mysql的并发性,保证了ACID的隔离性
二十八.数据库锁有哪些
行级锁:针对当前操作的行进行加锁,行级锁大大减少了数据库的冲突,但是开销比较大,加锁慢,会造成死锁,并发程度概率最高,分为共享锁(读锁)和排他锁(写锁)
表级锁:对操作的整张表加锁,实现简单,资源消耗少,开销小,加锁块,不会出现死锁,并发程度概率最低,分为共享锁(读锁)排他锁(写锁)
页级锁:行级锁和表级锁中间的一个锁,并发程度概率一般,也会出现死锁
二十九.读写分离,主从复制
主从复制:从一个数据库服务器复制数据到其他服务器,一个服务器当master,其他的当slave
目的:提高数据库的性能,在master进行写入和更新,在slave进行读,并进行备份
如何实现:在master中进行写操作,它会同步到slave
三十.索引
1.mysql使用的是B+Tree索引,数据都在叶子节点上,每个叶子节点都指向了相邻的叶子节点上,进行范围查找时,B+Tree主需要查找两个节点,进行遍历,B-Tree需要获取所有节点
2.B+Tree的磁盘读写代价更低
(Spring)
三十一.通过三种方式完成依赖注入
1.构造器注入
2.Setter注入
3.接口注入
三十二.BeanFactory和ApplicatiinContext区别
BeanFactory:懒加载,运行速度相对比较慢
ApplicationContext:即时加载,启动时都会加载,系统运行速度快
三十三.Bean的生命周期
1.对Bean进行实例化,设置Bean的属性
2.声明依赖
3.调用前置初始化方法,添加自定义的处理逻辑
4.做一些属性被自定义后的事
5.调用init()方法,进行初始化
6.调用后置初始化方法
7.调用destory()方法销毁
三十四.SpringBoot的核心注解
@SpringBootApplication:
1.SpringBootConfigyration:结合@Configuration实现配置文件的功能
2.EnableAutoCOnfiguration:打开自动配置的功能
3.ComponentScan:Spring组件扫描
三十五.Spring Boot Starter工作原理
1.启动时去依赖的starter包寻找文件,根据文件中配置的Jar包扫描项目锁依赖的Jar包
2.根据spring.factories配置加载AutoConfigure类
3.根据Conditional,进行自动装配

 浙公网安备 33010602011771号
浙公网安备 33010602011771号