一、AlertManager概述
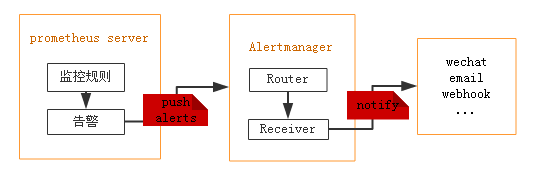
Prometheus 包含一个报警模块,就是我们的 AlertManager,Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。
 Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
Prometheus发出告警时分为两个部分。Prometheus服务器按告警规则(rule_files配置块)将警报发送到Alertmanager(即告警规则是在Prometheus上定义的)。然后,由Alertmanager 来管理这些警报,包括去重(Deduplicating)、分组(Grouping)、沉默(silencing),抑制(inhibition),聚合(aggregation),最终通过电子邮件发出通知,对呼叫通知系统,以及即时通讯平台,将告警通知路由(route)给对应的联系人。
设置警报和通知的主要步骤是:
- 设置和配置 Alertmanager
- 配置Prometheus与Alertmanager对话
- 在Prometheus中创建警报规则
分组
分组将类似性质的警报分类为单个通知。当许多系统同时发生故障并且可能同时触发数百到数千个警报时,此功能特别有用。
比如:发生网络分区时,群集中正在运行数十个或数百个服务实例。您有一半的服务实例不再可以访问数据库。Prometheus中的警报规则配置为在每个服务实例无法与数据库通信时为其发送警报。结果,数百个警报被发送到Alertmanager。
作为用户,人们只希望获得一个页面,同时仍然能够准确查看受影响的服务实例。因此,可以将Alertmanager配置为按警报的群集和警报名称分组警报,以便它发送一个紧凑的通知。警报的分组,分组通知的时间以及这些通知的接收者由配置文件中的路由树配置。
沉默
沉默是一种简单的特定时间静音提醒的机制。一种沉默是通过匹配器来配置,就像路由树一样。传入的警报会匹配RE,如果匹配,将不会为此警报发送通知。在Alertmanager的Web界面中配置沉默。
抑制
抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。
例如,当警报被触发,通知整个集群不可达,可以配置Alertmanager忽略由该警报触发而产生的所有其他警报,这可以防止通知数百或数千与此问题不相关的其他警报。抑制机制可以通过Alertmanager的配置文件来配置。
总之,AlertManager制定这一系列规则的目的只有一个,就是提高告警质量。
Alert的三种状态:
- pending:警报被激活,但是低于配置的持续时间。这里的持续时间即rule里的FOR字段设置的时间。改状态下不发送报警。
- firing:警报已被激活,而且超出设置的持续时间。该状态下发送报警。
- inactive:既不是pending也不是firing的时候状态变为inactive
prometheus触发一条告警的过程:
prometheus—>触发阈值—>超出持续时间—>alertmanager—>分组|抑制|静默—>媒体类型—>邮件|钉钉|微信等。
二、AlertManager 配置邮件和微信告警
说明
| 主机名 | 角色 | IP | 说明 |
|---|---|---|---|
| test | Prometheus | 192.168.126.120 | 安装prometheus,配置告警规则 |
| nginx | node_exporter | 192.168.126.41 | 安装node_exporter,收集监控信息 |
| ds-slave | AlertManager | 192.1687.126.91 | 安装alertmanager,管理并发送告警 |
目的:
当被监控主机nginx(192.168.126.41)关机时,标记标签为Disaster,并发送告警信息到企业微信;当内存使用率超过75%时,标记标签为warning,并发送告警信息到qq邮箱;当磁盘使用超过80%时,标记标签为warning,并发送告警信息到qq邮箱。
所有主机准备工作
yum install ntpdate -y
ntpdate ntp1.aliyun.com
hwclock -w
crontab -e
sed -i 's/SELINUX=enforcing/SLINUX=disabled/g' /etc/selinux/config
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
(一)AlertManager部署配置
下载并配置
二进制包下载解压后即可使用,官网地址:https://prometheus.io/download/
[root@ds-slave ~]# ifconfig ens32| awk 'NR==2 {print $2}'
192.168.126.91
[root@ds-slave ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz
[root@ds-slave ~]# ls
alertmanager-0.23.0.linux-amd64.tar.gz
[root@ds-slave ~]# tar xf alertmanager-0.23.0.linux-amd64.tar.gz -C /usr/local
[root@ds-slave ~]# mv /usr/local/alertmanager-0.23.0.linux-amd64/ /usr/local/alertmanager
# 查看版本等信息
[root@ds-slave ~]# /usr/local/alertmanager/alertmanager --version
alertmanager, version 0.23.0 (branch: HEAD, revision: 61046b17771a57cfd4c4a51be370ab930a4d7d54)
build user: root@e21a959be8d2
build date: 20210825-10:48:55
go version: go1.16.7
platform: linux/amd64
[root@ds-slave ~]# vim /usr/local/alertmanager/alertmanager.yml
# global:全局配置,主要配置告警方式,如邮件、webhook等。
global:
resolve_timeout: 5m # 超时,默认5min
smtp_smarthost: 'smtp.qq.com:465' # 这里为 QQ 邮箱 SMTP 服务地址,官方地址为 smtp.qq.com 端口为 465 或 587,同时要设置开启 POP3/SMTP 服务。
smtp_from: '916719080@qq.com'
smtp_auth_username: '916719080@qq.com'
smtp_auth_password: 'lojdeopbholobgah' # 这里为第三方登录 QQ 邮箱的授权码,非 QQ 账户登录密码,否则会报错,获取方式在 QQ 邮箱服务端设置开启 POP3/SMTP 服务时会提示。
smtp_require_tls: false # 是否使用 tls,根据环境不同,来选择开启和关闭。如果提示报错 email.loginAuth failed: 530 Must issue a STARTTLS command first,那么就需要设置为 true。着重说明一下,如果开启了 tls,提示报错 starttls failed: x509: certificate signed by unknown authority,需要在 email_configs 下配置 insecure_skip_verify: true 来跳过 tls 验证。
templates: # # 模板
- '/usr/local/alertmanager/alert.tmp'
# route:用来设置报警的分发策略。Prometheus的告警先是到达alertmanager的根路由(route),alertmanager的根路由不能包含任何匹配项,因为根路由是所有告警的入口点。
# 另外,根路由需要配置一个接收器(receiver),用来处理那些没有匹配到任何子路由的告警(如果没有配置子路由,则全部由根路由发送告警),即缺省
# 接收器。告警进入到根route后开始遍历子route节点,如果匹配到,则将告警发送到该子route定义的receiver中,然后就停止匹配了。因为在route中
# continue默认为false,如果continue为true,则告警会继续进行后续子route匹配。如果当前告警仍匹配不到任何的子route,则该告警将从其上一级(
# 匹配)route或者根route发出(按最后匹配到的规则发出邮件)。查看你的告警路由树, https://www.prometheus.io/webtools/alerting/routing-tree-editor/ ,
# 将alertmanager.yml配置文件复制到对话框,然后点击"Draw Routing Tree"
route:
group_by: ['alertname'] # 用于分组聚合,对告警通知按标签(label)进行分组,将具有相同标签或相同告警名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送。如果想完全禁用聚合,可以设置为group_by: [...]
group_wait: 30s # 当一个新的告警组被创建时,需要等待'group_wait'后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送。
group_interval: 2m # 当第一次告警通知发出后,在新的评估周期内又收到了该分组最新的告警,则需等待'group_interval'时间后,开始发送为该组触发的新告警,可以简单理解为,group就相当于一个通道(channel)。
repeat_interval: 10m # 告警通知成功发送后,若问题一直未恢复,需再次重复发送的间隔。
receiver: 'email' # 配置告警消息接收者,与下面配置的对应。例如常用的 email、wechat、slack、webhook 等消息通知方式。
routes: # 子路由
- receiver: 'wechat'
match: # 通过标签去匹配这次告警是否符合这个路由节点;也可以使用 match_re 进行正则匹配
severity: Disaster # 标签severity为Disaster时满足条件,使用wechat警报
receivers: # 配置报警信息接收者信息。
-
name: 'email' # 警报接收者名称
email_configs:
- to: '{{ template "email.to"}}' # 接收警报的email(这里是引用模板文件中定义的变量)
html: '{{ template "email.to.html" .}}' # 发送邮件的内容(调用模板文件中的)
# headers: { Subject: " {{ .CommonLabels.instance }} {{ .CommonAnnotations.summary }}" } # 邮件标题,不设定使用默认的即可
send_resolved: true # 故障恢复后通知
-
name: 'wechat'
wechat_configs:
- corp_id: wwd76d598b5fad5097 # 企业信息("我的企业"--->"CorpID"[在底部])
to_user: '@all' # 发送给企业微信用户的ID,这里是所有人
# to_party: '' 接收部门ID
agent_id: 1000004 # 企业微信("企业应用"-->"自定应用"[Prometheus]--> "AgentId")
api_secret: DY9IlG0Bdwawb_ku0NblxKFrrmMwbLIZ7YxMa5rCg8g # 企业微信("企业应用"-->"自定应用"[Prometheus]--> "Secret")
message: '{{ template "email.to.html" .}}' # 发送内容(调用模板)
send_resolved: true # 故障恢复后通知
inhibit_rules: # 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)。
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
# 修改好配置文件后,可以使用amtool工具检查配置
[root@ds-slave ~]# /usr/local/alertmanager/amtool check-config /usr/local/alertmanager/alertmanager.yml
Checking '/usr/local/alertmanager/alertmanager.yml' SUCCESS
Found:
- global config
- route
- 1 inhibit rules
- 2 receivers
- 1 templates
SUCCESS
[root@ds-slave ~]# vim /usr/local/alertmanager/alert.tmp
{{ define "email.from" }}916719080@qq.com{{ end }}
{{ define "email.to" }}916719080@qq.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知</h2>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }}<br>
故障主题: {{ .Annotations.summary }}<br>
告警详情: {{ .Annotations.description }}<br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}<br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
# 上边模板文件配置了 email.from、email.to、email.to.html 三种模板变量,可以在 alertmanager.yml 文件中直接配置引用。这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式,这里为了显示好看,采用 Html 格式简单显示信息。下边 {{ range .Alerts }} 是个循环语法,用于循环获取匹配的 Alerts 的信息。
[root@ds-slave ~]# /usr/local/alertmanager/alertmanager --config.file /usr/local/alertmanager/alertmanager.ymllevel=info ts=2021-10-01T14:14:55.695Z caller=main.go:225 msg="Starting Alertmanager" version="(version=0.23.0, branch=HEAD, revision=61046b17771a57cfd4c4a51be370ab930a4d7d54)"
level=info ts=2021-10-01T14:14:55.695Z caller=main.go:226 build_context="(go=go1.16.7, user=root@e21a959be8d2, date=20210825-10:48:55)"
level=info ts=2021-10-01T14:14:55.700Z caller=cluster.go:184 component=cluster msg="setting advertise address explicitly" addr=192.168.126.91 port=9094
level=info ts=2021-10-01T14:14:55.705Z caller=cluster.go:671 component=cluster msg="Waiting for gossip to settle..." interval=2s
level=info ts=2021-10-01T14:14:55.751Z caller=coordinator.go:113 component=configuration msg="Loading configuration file" file=/usr/local/alertmanager/alertmanager.yml
level=info ts=2021-10-01T14:14:55.752Z caller=coordinator.go:126 component=configuration msg="Completed loading of configuration file" file=/usr/local/alertmanager/alertmanager.yml
level=info ts=2021-10-01T14:14:55.754Z caller=main.go:518 msg=Listening address=:9093
level=info ts=2021-10-01T14:14:55.754Z caller=tls_config.go:191 msg="TLS is disabled." http2=false
level=info ts=2021-10-01T14:14:57.707Z caller=cluster.go:696 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.001884344s
level=info ts=2021-10-01T14:15:05.714Z caller=cluster.go:688 component=cluster msg="gossip settled; proceeding" elapsed=10.008544279s
[root@ds-slave ~]# ss -aulntp | grep 9093
tcp LISTEN 0 128 :::9093 ::😗 users:(("alertmanager",pid=101921,fd=8))

查看AlertManager的WEB UI页面


(二)node_exporter部署
[root@nginx ~]# ifconfig ens32 | awk 'NR==2 {print $2}'
192.168.126.41
# 下载
[root@nginx ~]# wget https://github.com/prometheus/node_exporter/releases/download/v1.2.2/node_exporter-1.2.2.linux-amd64.tar.gz
# 解压
[root@nginx ~]# tar xf node_exporter-1.2.2.linux-amd64.tar.gz -C /usr/local
[root@nginx ~]# mv /usr/local/node_exporter-1.2.2.linux-amd64/ /usr/local/node_exporter
[root@nginx ~]# cd /usr/local/node_exporter
# 查看版本等信息
[root@nginx node_exporter]# ./node_exporter --version
node_exporter, version 1.2.2 (branch: HEAD, revision: 26645363b486e12be40af7ce4fc91e731a33104e)
build user: root@b9cb4aa2eb17
build date: 20210806-13:44:18
go version: go1.16.7
platform: linux/amd64
# 因为我们要确保node_exporter随着主机的启动而启动,所以需配置开启自启动
[root@nginx ~]# vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
[root@nginx ~]# systemctl start node_exporter
[root@nginx ~]# systemctl status node_exporter
● node_exporter.service - node_exporter
Loaded: loaded (/usr/lib/systemd/system/node_exporter.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2021-10-06 12:56:51 CST; 22min ago
Docs: https://github.com/prometheus/node_exporter
Main PID: 893 (node_exporter)
CGroup: /system.slice/node_exporter.service
└─893 /usr/local/node_exporter/node_exporter
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.122Z caller=node_exporter.go:115 collector=thermal_zone
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.122Z caller=node_exporter.go:115 collector=time
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.122Z caller=node_exporter.go:115 collector=timex
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.122Z caller=node_exporter.go:115 collector=udp_queues
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.122Z caller=node_exporter.go:115 collector=uname
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.122Z caller=node_exporter.go:115 collector=vmstat
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.123Z caller=node_exporter.go:115 collector=xfs
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.123Z caller=node_exporter.go:115 collector=zfs
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.123Z caller=node_exporter.go:199 msg="Listening ...s=:9100
Oct 06 12:56:51 nginx node_exporter[893]: level=info ts=2021-10-06T04:56:51.124Z caller=tls_config.go:191 msg="TLS is disabl...2=false
Hint: Some lines were ellipsized, use -l to show in full.
[root@nginx ~]# ss -aulntp | grep 9100
tcp LISTEN 0 128 :::9100 ::😗 users:(("node_exporter",pid=893,fd=3))
[root@nginx ~]# ps -aux | grep [n]ode_exporter
root 893 0.1 1.0 718088 21268 ? Ssl 12:56 0:02 /usr/local/node_exporter/node_exporter
# 加入开机自启
[root@nginx ~]# systemctl enable node_exporter
Created symlink from /etc/systemd/system/multi-user.target.wants/node_exporter.service to /usr/lib/systemd/system/node_exporter.service.
(三)Prometheus配置
[root@test ~]# vim /usr/local/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
# 关联Alertmanager服务
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.126.91:9093 # 指定Alertmanager 的地址
rule_files: # 指定报警规则文件
- "/usr/local/prometheus/rules/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "alertmanager_test" # 同时添加对alertmanager的监控
static_configs:
- targets: ["192.168.126.91:9093"]
- job_name: "test"
static_configs:
- targets: ["192.168.126.41:9100"]
# 编辑报警规则文件
[root@test ~]# mkdir /usr/local/prometheus/rules
[root@test ~]# vim /usr/local/prometheus/rules/node_alerts.yml
groups:
-
name: 实例存活告警规则
rules:
- alert: 实例存活告警 # 告警规则的名称(alertname)
expr: up 0 # expr 是计算公式,up指标可以获取到当前所有运行的Exporter实例以及其状态,即告警阈值为up0
for: 30s # for语句会使 Prometheus 服务等待指定的时间, 然后执行查询表达式。(for 表示告警持续的时长,若持续时长小于该时间就不发给alertmanager了,大于该时间再发。for的值不要小于prometheus中的scrape_interval,例如scrape_interval为30s,for为15s,如果触发告警规则,则再经过for时长后也一定会告警,这是因为最新的度量指标还没有拉取,在15s时仍会用原来值进行计算。另外,要注意的是只有在第一次触发告警时才会等待(for)时长。)
labels: # labels语句允许指定额外的标签列表,把它们附加在告警上。
severity: Disaster
annotations: # annotations语句指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的。
summary: "节点失联"
description: "节点断联已超过1分钟!"
-
name: 内存告警规则
rules:
- alert: "内存使用率告警"
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 75 # 告警阈值为当内存使用率大于75%
for: 30s
labels:
severity: warning
annotations:
summary: "服务器内存报警"
description: "内存资源利用率大于75%!(当前值: {{ $value }}%)"
-
name: 磁盘报警规则
rules:
- alert: 磁盘使用率告警
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80 # 告警阈值为某个挂载点使用大于80%
for: 1m
labels:
severity: warning
annotations:
summary: "服务器 磁盘报警"
description: "服务器磁盘设备使用超过80%!(挂载点: {{ \(labels</span>.mountpoint }} 当前值: {<!-- -->{ <span class="token variable">\)value }}%)"
# 检查配置文件
[root@test ~]# /usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml
Checking /usr/local/prometheus/prometheus.yml
SUCCESS: 1 rule files found
Checking /usr/local/prometheus/rules/node_alerts.yml
SUCCESS: 3 rules found
# 启动
[root@test ~]# nohup /usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
[1] 14316
[root@test ~]# nohup: ignoring input and appending output to ‘nohup.out’
查看监控节点是否添加正常

查看告警规则配置信息


查看这三个告警表达式目前的结果
内存使用率:

实例存活:
 磁盘使用率:
磁盘使用率:

均未达到告警阈值,所以不会触发告警
(四)测试告警
(1)当被监控主机nginx(192.168.126.41)内存使用率超过75%时,是否会发送告警信息到qq邮箱;
下载压测工具
[root@nginx ~]# yum install epel-release -y
[root@nginx ~]# yum clean all
[root@nginx ~]# yum makecache fast
[root@nginx ~]# yum install stress -y
内存压测
[root@nginx ~]# free -h
total used free shared buff/cache available
Mem: 1.9G 101M 1.7G 8.5M 121M 1.7G
Swap: 4.0G 0B 4.0G
# 总内存2G,我们设置的告警阈值为内存使用率为%75则告警,2048*%75=1536M
# 表示运行3个进程,每个进程分配500M内存
[root@nginx ~]# stress --vm 3 --vm-bytes 500M --vm-keep
stress: info: [1032] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd
查看内存使用率

超过阈值,触发告警


- inactive: 非活动状态,表示正在监控,但是还未有任何警报触发。
- pending: 表示这个警报已经被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。
- firing: 将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到 Inactive,如此循环。
查看AlertManager的WEB UI页面

在这个页面中我们可以进行一些操作,比如过滤、分组等等,里面还有两个新的概念:Inhibition(抑制)和 Silences(静默)。
Inhibition:如果某些其他警报已经触发了,则对于某些警报,Inhibition 是一个抑制通知的概念。例如:一个警报已经触发,它正在通知整个集群是不可达的时,Alertmanager 则可以配置成关心这个集群的其他警报无效。这可以防止与实际问题无关的数百或数千个触发警报的通知,Inhibition 需要通过上面的配置文件进行配置。
Silences:静默是一个非常简单的方法,可以在给定时间内简单地忽略所有警报。Silences 基于 matchers配置,类似路由树。来到的警告将会被检查,判断它们是否和活跃的 Silences 相等或者正则表达式匹配。如果匹配成功,则不会将这些警报发送给接收者。
由于全局配置中我们配置的 repeat_interval: 10m,所以正常来说,上面的测试报警如果一直满足报警条件的话,那么每10分钟我们就可以收到一条报警邮件。
收到邮件

可以看到从检测到问题到收到邮件不超过两分钟
alertmanager主要处理流程(引用:https://www.kancloud.cn/huyipow/prometheus/527563,对alertmanager做了很全面到位的解释)
- 接收到Alert,根据labels判断属于哪些Route(可存在多个Route,一个Route有多个Group,一个Group有多个Alert)
- 将Alert分配到Group中,没有则新建Group
- 新的Group等待group_wait指定的时间(等待时可能收到同一Group的Alert),根据resolve_timeout判断Alert是否解决,然后发送通知
- 已有的Group等待group_interval指定的时间,判断Alert是否解决,当上次发送通知到现在的间隔大于repeat_interval或者Group有更新时会发送通知
此时关闭压测
[root@nginx ~]# stress --vm 3 --vm-bytes 500M --vm-keep
stress: info: [1103] dispatching hogs: 0 cpu, 0 io, 3 vm, 0 hdd
^C
- 1
- 2
- 3
收到故障解决的邮件

这里有几个地方需要解释一下:
- 每次停止/恢复服务后,15s 之后才会发现 Alert 状态变化,是因为 prometheus.yml中 global -> scrape_interval: 15s 配置决定的,如果觉得等待 15s 时间太长,可以修改小一些,可以全局修改,也可以局部修改。也可以局部修改 node-exporter 等待时间。
- Alert 状态变化时会等待 30s 才发生改变,是因为报警规则配置文件(/usr/local/prometheus/rules/node_alerts.yml)中中配置了 for: 30s 状态变化等待时间。
- 报警触发后,每隔 10m 会自动发送报警邮件(服务未恢复正常期间),是因为 alertmanager.yml 中 route -> repeat_interval: 10m 配置决定的。
同时告警也恢复未激活状态

(2)当被监控主机nginx(192.168.126.41)关机时,是否会发送告警信息到企业微信;
关机
[root@nginx ~]# shutdown -h now
- 1



企业微信收到告警信息

此时模拟故障恢复,开机
收到问题解决的信息

同时告警也恢复未激活状态

(3)当被监控主机nginx(192.168.126.41)磁盘使用超过80%时,是否会发送告警信息到qq邮箱;
[root@nginx ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 9.8G 2.5G 7.4G 25% /
devtmpfs 982M 0 982M 0% /dev
tmpfs 993M 0 993M 0% /dev/shm
tmpfs 993M 8.5M 984M 1% /run
tmpfs 993M 0 993M 0% /sys/fs/cgroup
/dev/sda1 187M 102M 85M 55% /boot
/dev/mapper/centos-home 6.0G 33M 6.0G 1% /home
tmpfs 199M 0 199M 0% /run/user/0
[root@nginx boot]# dd if=/dev/zero of=./test.io count=1 bs=80M
1+0 records in
1+0 records out
83886080 bytes (84 MB) copied, 0.0457123 s, 1.8 GB/s
[root@nginx boot]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 9.8G 2.5G 7.4G 25% /
devtmpfs 982M 0 982M 0% /dev
tmpfs 993M 0 993M 0% /dev/shm
tmpfs 993M 8.5M 984M 1% /run
tmpfs 993M 0 993M 0% /sys/fs/cgroup
/dev/sda1 187M 182M 4.7M 98% /boot
/dev/mapper/centos-home 6.0G 33M 6.0G 1% /home
tmpfs 199M 0 199M 0% /run/user/0



收到告警邮件

恢复故障
[root@nginx boot]# rm -rf test.io
告警恢复未激活状态
 收到故障恢复邮件
收到故障恢复邮件

附:企业微信说明(关于alertmanager.yml文件中微信相关的配置参数说明)
- name: 'wechat'
wechat_configs:
- corp_id: wwd76d598b5fad5097
to_user: '@all'
# to_party: '' 接收部门ID
agent_id: 1000004
api_secret: DY9IlG0Bdwawb_ku0NblxKFrrmMwbLIZ7YxMa5rCg8g
message: '{{ template "email.to.html" .}}'
send_resolved: true
登录企业微信:https://work.weixin.qq.com/
 此企业ID即为配置文件中的 corp_id
此企业ID即为配置文件中的 corp_id




此Agentid即为配置文件中的 agent_id;此Secret即为配置文件中的 api_secret

 浙公网安备 33010602011771号
浙公网安备 33010602011771号