

SQL语句优化
目录
- 慢查询日志
- 慢日志分析工具使用
- 一般优化策略
慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
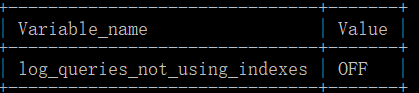
#查看查询日期是否开启

#查询log_queries_not_using_indexes,表示记录未使用索引的查询
![]()
若为off
设置为on
set global log_queries_not_using_indexes = on
#查看变量long_query_time,表示查询事件多久以上的语句记录到慢查询日志中

可以自己进行设置这个阈值。
#查询慢日志文件所在路径

其中返回的slow_query_log_file 就是其存储位置
使用MySQL的示例数据库sakila进行测试得到以下结果
# Time: 2018-07-05T14:25:40.064938Z # User@Host: root[root] @ localhost [::1] Id: 5 # Query_time: 0.001002 Lock_time: 0.001002 Rows_sent: 10 Rows_examined: 10 SET timestamp=1530800740; select * from actor limit 10;
其中 query_time:SQL的执行时间
慢日志分析工具
常用的工具有pt-query-digest
安装流程:(后续补充)
使用方法:见博客
一般优化策略
通过上述分析工具之后定位至相应的拖累系统的慢的SQL语句,再使用explain命令来解读SQL语句,方便后续的分析。(更复杂的例子可见美团博客)

上述一个举的例子,直接将explain加至SQL语句前面。
表中id:id可以认为是执行的顺序,id相同则是同一组操作,顺序由上至下;当存在子查询的时候,每嵌套一层,id加1。满足id越大,越先执行。
select_type:查询的类别,有以下几种
(1)SIMPLE:简单的SELECT,不适用UNION或子查询等
(2) PRIMARY :查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY
(3) UNION:(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION:(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT:(UNION的结果)
(6) SUBQUERY:(子查询中的第一个SELECT)
(7) DEPENDENT SUBQUERY:(子查询中的第一个SELECT,取决于外面的查询)
(8) DERIVED:(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY:(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
table:查询的表名
当有构造表时,derived表示构造表,也就是不存在的表,可以简单理解成是一个语句形成的结果集,后面的数字表示语句的ID。
主要看type和rows,分别是“访问类型“和需要访问的行数。
前者:常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
后者则是越小越好,越小查询行数越少,就越快。
优化策略
(1)对查询进行优化,要尽量避免全表扫描,首先应考虑再where及order by 涉及的列上建立索引。
(2)尽量避免再where子句中对字段进行null值判断,否则导致引擎放弃索引而进行全表扫描。所以最后不要给数据库留NULL,尽可能使用NOT NULL 填充数据库。
(3)尽量避免在where子句中使用!=或<>操作符,否则同(2)。
(4)尽量避免在where子句中使用or来连接条件,因为如果一个字段有索引一个字段没有,则同(3)。
(5)in和not in要少用,否则会导致全表扫描。比如 对于连续的数值:
select id from actor where id in(1,2,3)
可以改用between来代替in。
(6)尽量的扩展索引,不要新建索引。
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
(7)在使用like进行模糊查询时,尽量不要使用通配符%开头,如下,这样就会使语句变成全表扫描。
select id from t where name like ‘%abc%’
(8)尽量避免在where子句中对字段进行表达式操作或者函数操作,这样也会变成全表扫描。
(9)where子句中使用复合索引时,需要满足最左前缀原则
最左前缀原则:当数据库的索引为复合索引时,总是从索引的最前面字段开始,接着往后,中间不能跳过。比如创建了多列索引(name,age,sex),会先匹配name字段,再匹配age字段,再匹配sex字段的,中间不能跳过。mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
一般,在创建多列索引时,where子句中使用最频繁的一列放在最左边。
当破坏最左前缀原则时,就会变成全表扫描。
(8)尽量避免更新聚集索引数据列,因为聚集索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费很大的资源。
(9)Update语句,如果只改变1,2个字段,尽量不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
建立索引几大原则:
1,满足最左前缀原则比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2,尽量选择区分度高的列作为索引
3,索引不能参与计算,保持列干净。
4,尽量扩展索引,不要新建索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号