8. SparkSQL综合作业
综合练习:学生课程分数
网盘下载sc.txt文件,创建RDD,并转换得到DataFrame。
分别用RDD操作、DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
预处理
(1)RDD:生成RDD
sc_stu = sc.textFile("file:///home/zt/sc.txt").map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])])

(2)DataFrame:创建RDD,并转换得到DataFrame。
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql.functions import col
from pyspark.sql.functions import count
fields = [
StructField('name', StringType(), True),
StructField('course', StringType(), True),
StructField('score', IntegerType(), True)]
schema = StructType(fields)
lines = sc.textFile('file:///home/zt/sc.txt').map(lambda x:x.split(','))
data = lines.map(lambda p:Row(p[0], p[1], int(p[2])))
df = spark.createDataFrame(data, schema)
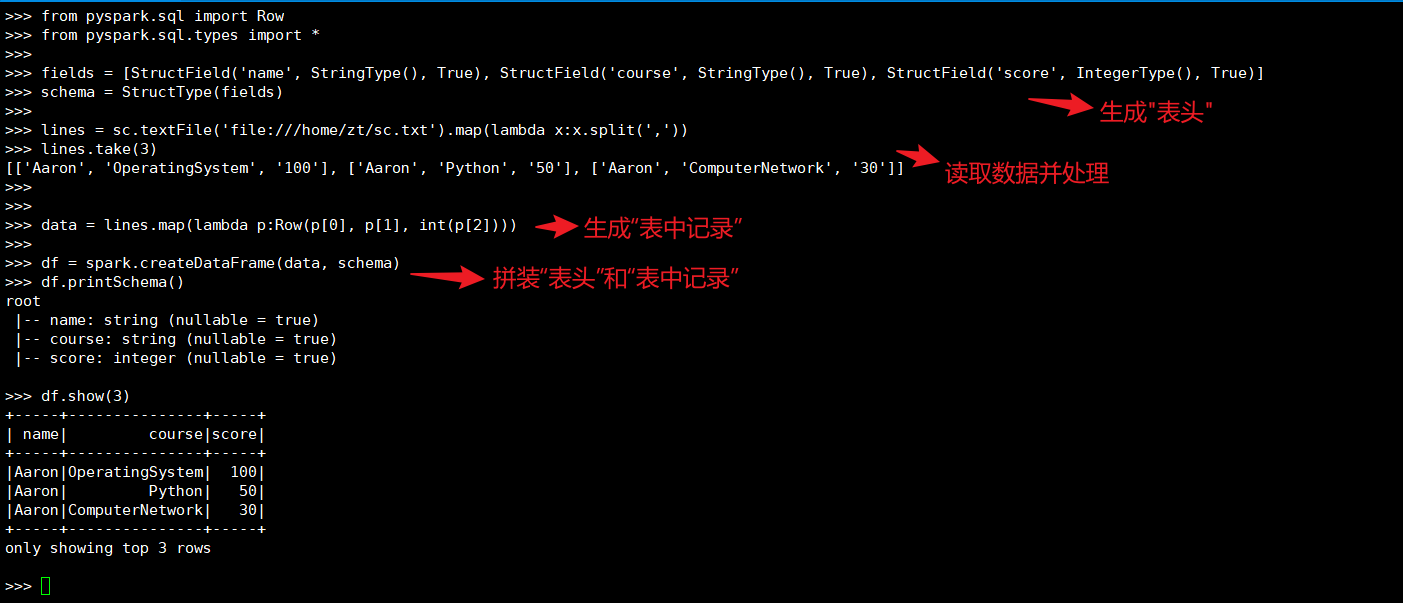
(3)spark.sql:创建临时表
from pyspark.sql import Row
student = spark.sparkContext.textFile("file:///home/zt/sc.txt").map(lambda line:line.split(",")).map(lambda p:Row(name=p[0], course=p[1], score=p[2]))
schemaStudent = spark.createDataFrame(student)
schemaStudent.createOrReplaceTempView("student")

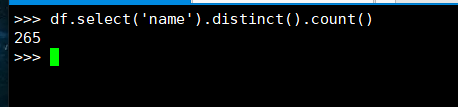
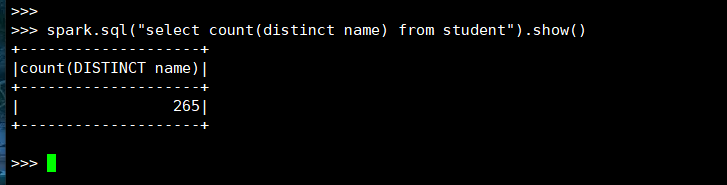
1. 总共有多少学生?
(1) RDD:

(2) DataFrame
(3) spark.sql
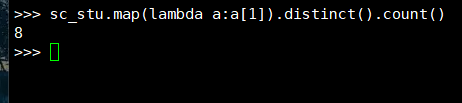
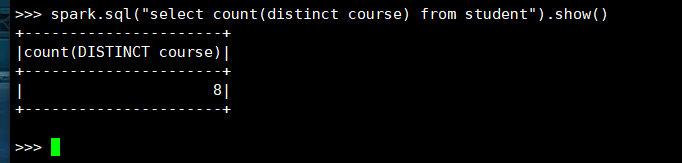
2. 开设了多少门课程?
(1) RDD:
(2) DataFrame
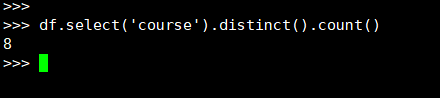
(3) spark.sql
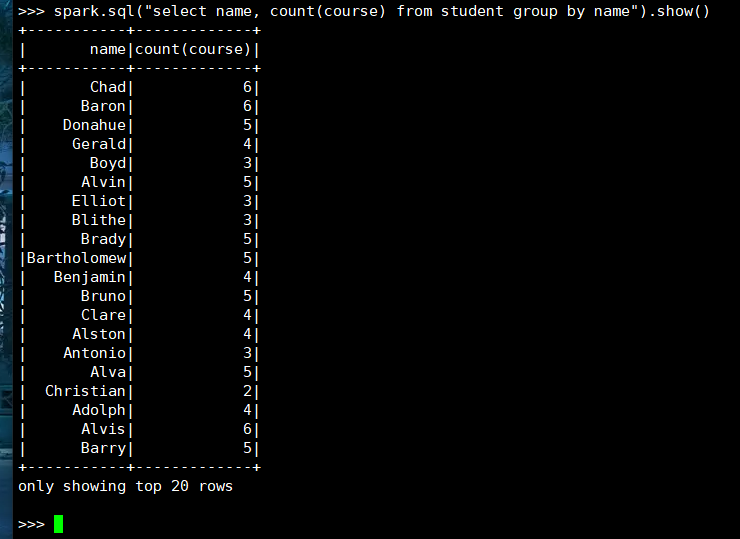
3. 每个学生选修了多少门课?
(1) RDD:
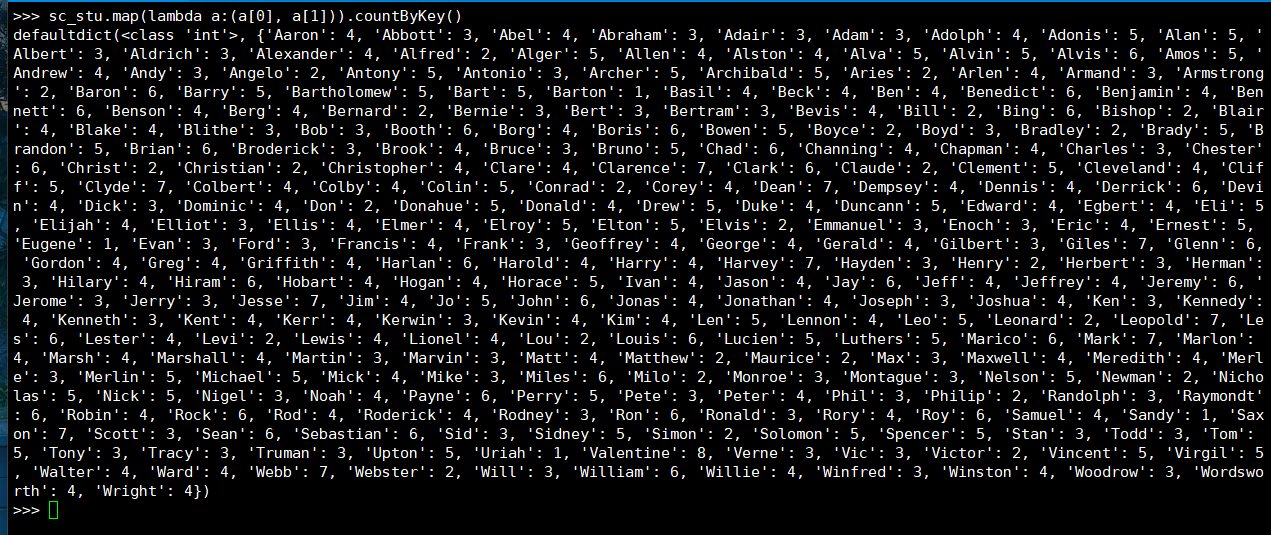
(2) DataFrame
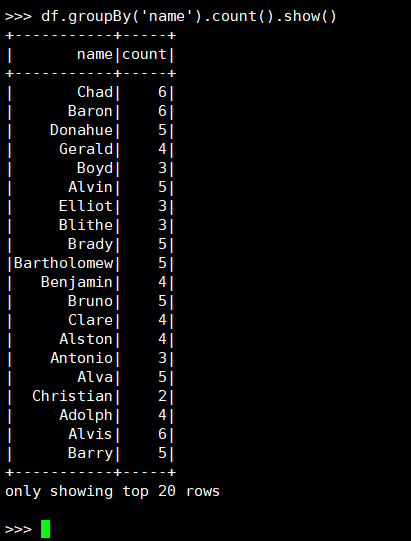
(3) spark.sql
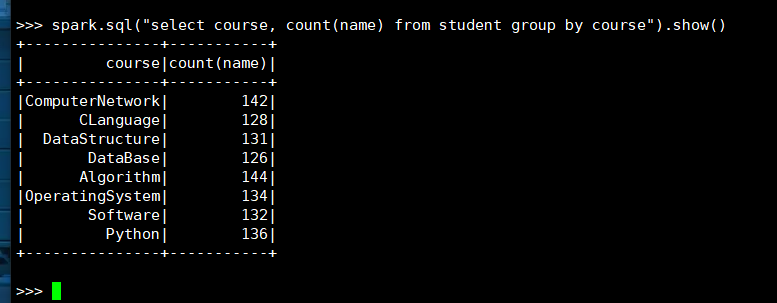
4. 每门课程有多少个学生选?
(1) RDD:

(2) DataFrame
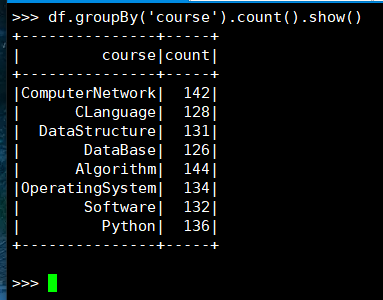
(3) spark.sql
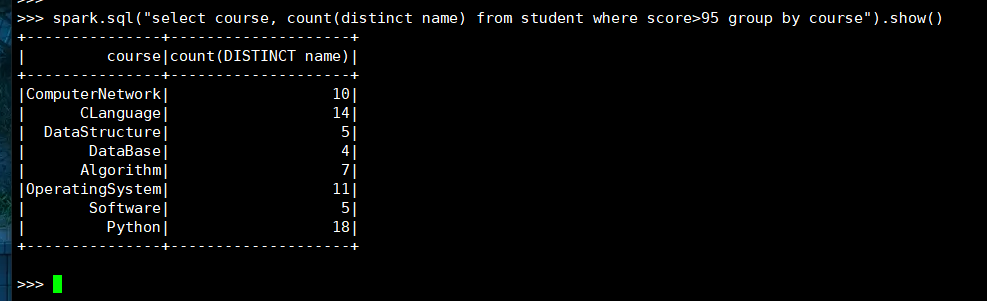
5. 每门课程>95分的学生人数
(1) RDD:

(2) DataFrame
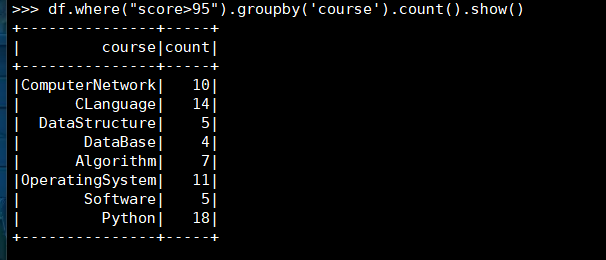
(3) spark.sql
6. 课程'Python'有多少个100分?
(1) RDD:

(2) DataFrame
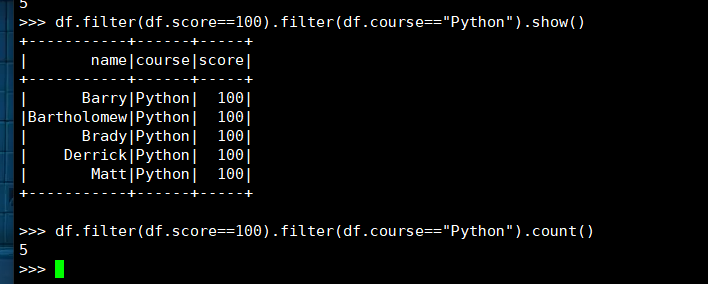
(3) spark.sql

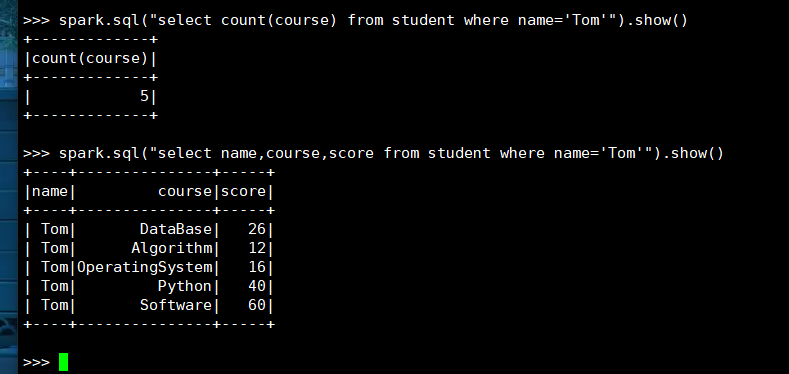
7. Tom选修了几门课?每门课多少分?
(1) RDD:
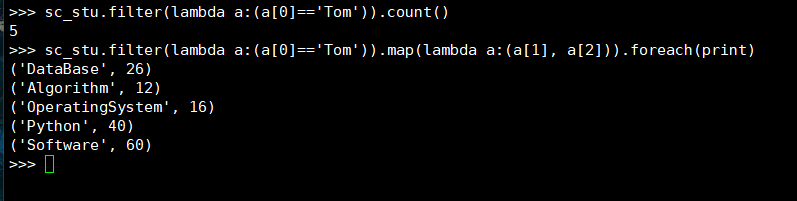
(2) DataFrame
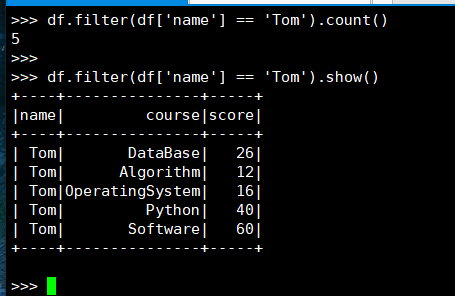
(3) spark.sql
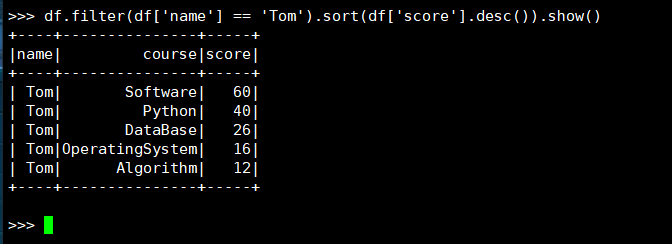
8. Tom的成绩按分数大小排序。
(1) RDD:

(2) DataFrame
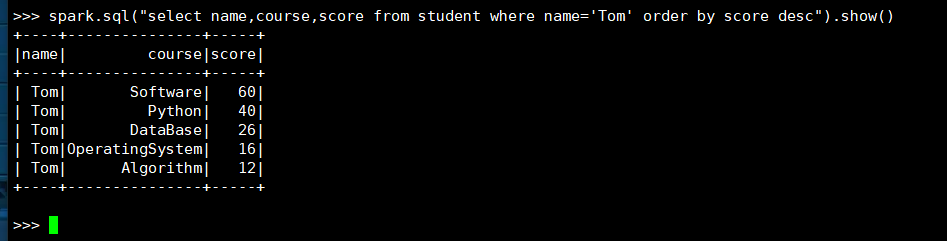
(3) spark.sql
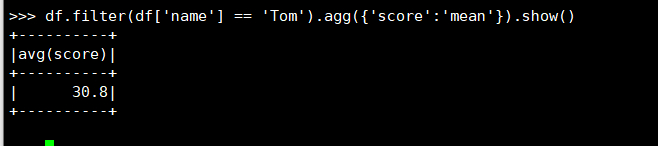
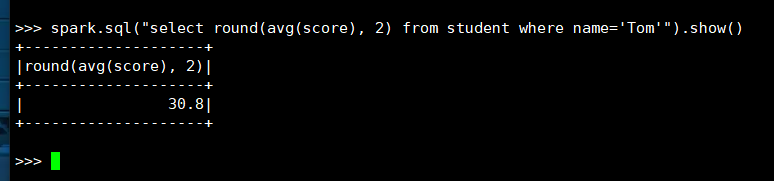
9. Tom的平均分。
(1) RDD:

(2) DataFrame
(3) spark.sql
10. 'OperatingSystem'不及格人数
(1) RDD:

(2) DataFrame
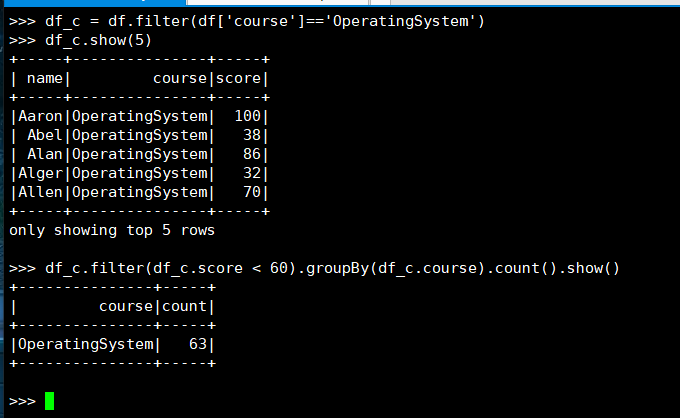
(3) spark.sql

11. 'OperatingSystem'平均分
(1) RDD:

(2) DataFrame

(3) spark.sql

12. 'OperatingSystem'90分以上人数
(1) RDD:

(2) DataFrame

(3) spark.sql

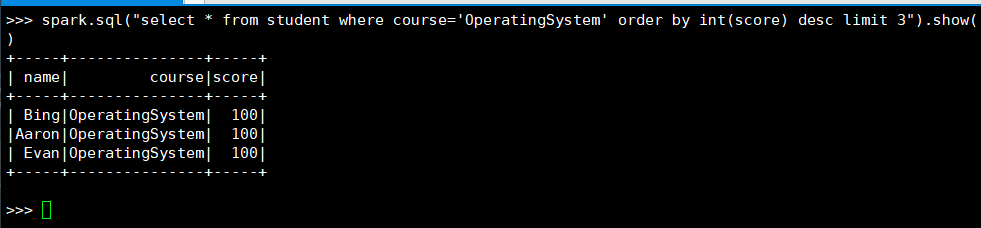
13. 'OperatingSystem'前3名
(1) RDD:

(2) DataFrame
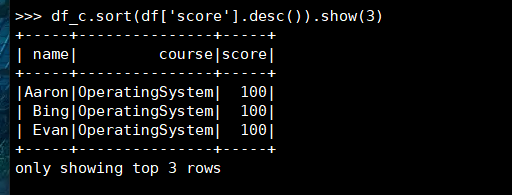
(3) spark.sql
14. 每个分数按比例+20平时分。
(1) RDD:

(2) DataFrame
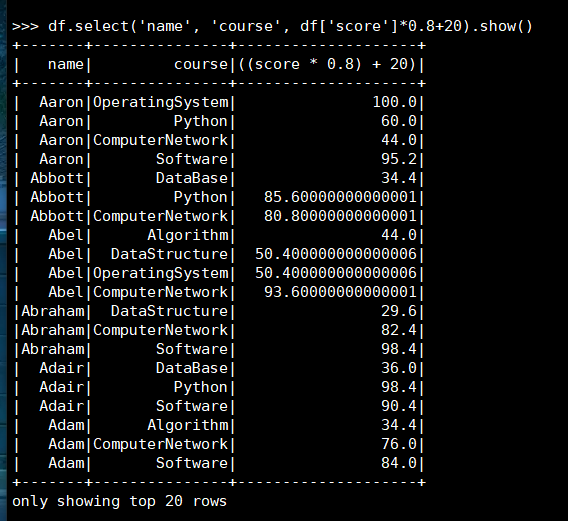
(3) spark.sql
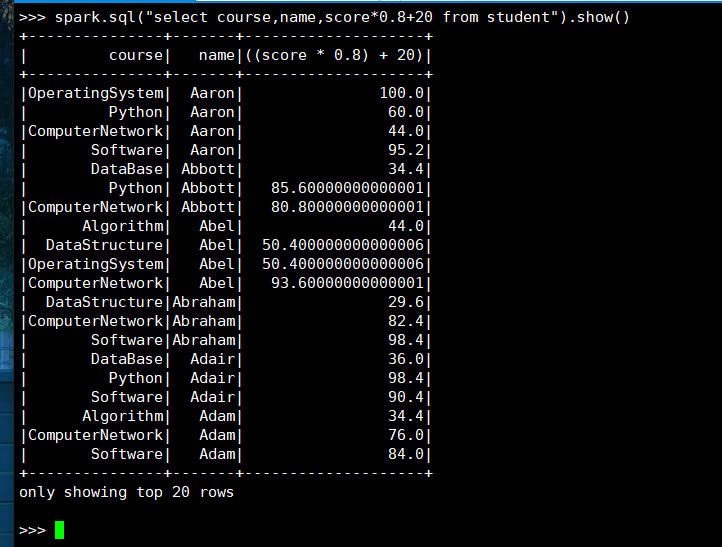
15. 求每门课的平均分
(1) RDD:

(2) DataFrame
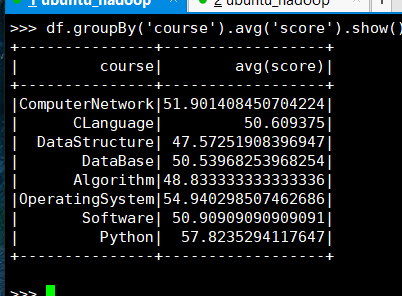
(3) spark.sql
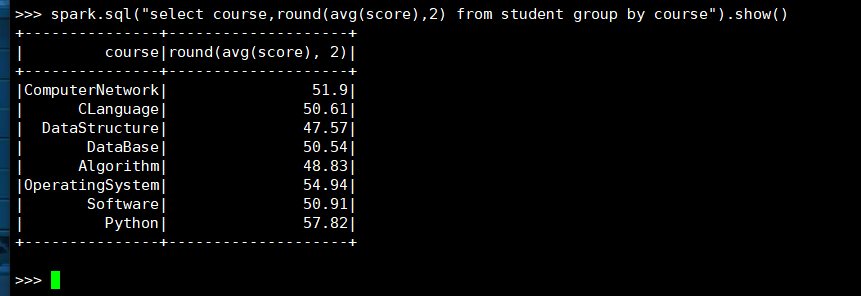
16. 选修了7门课的有多少个学生?
(1) RDD:

(2) DataFrame
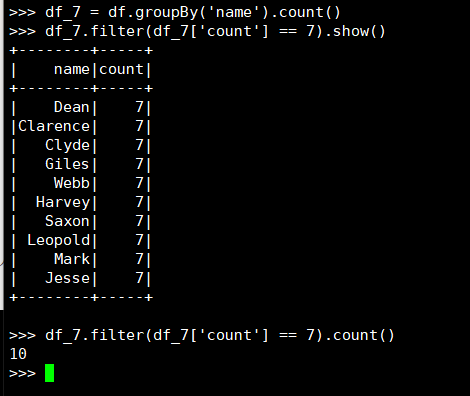
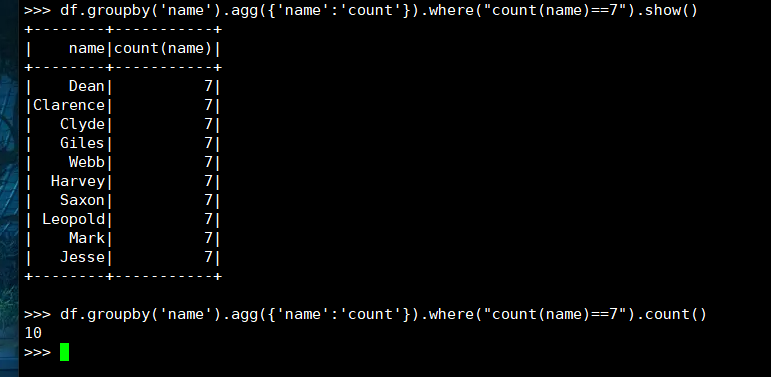
(3) spark.sql

17. 每门课大于95分的学生数
(1) RDD:

(2) DataFrame
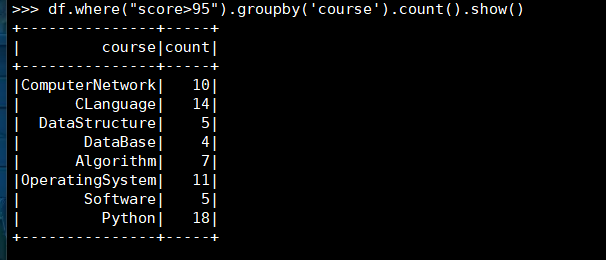
(3) spark.sql
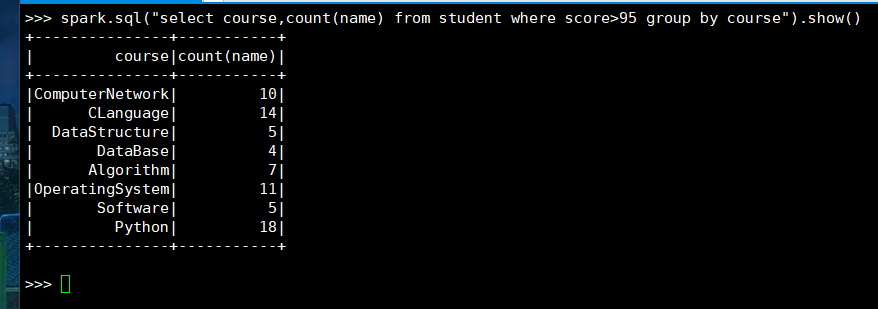
18. 每门课的选修人数、平均分、不及格人数、通过率
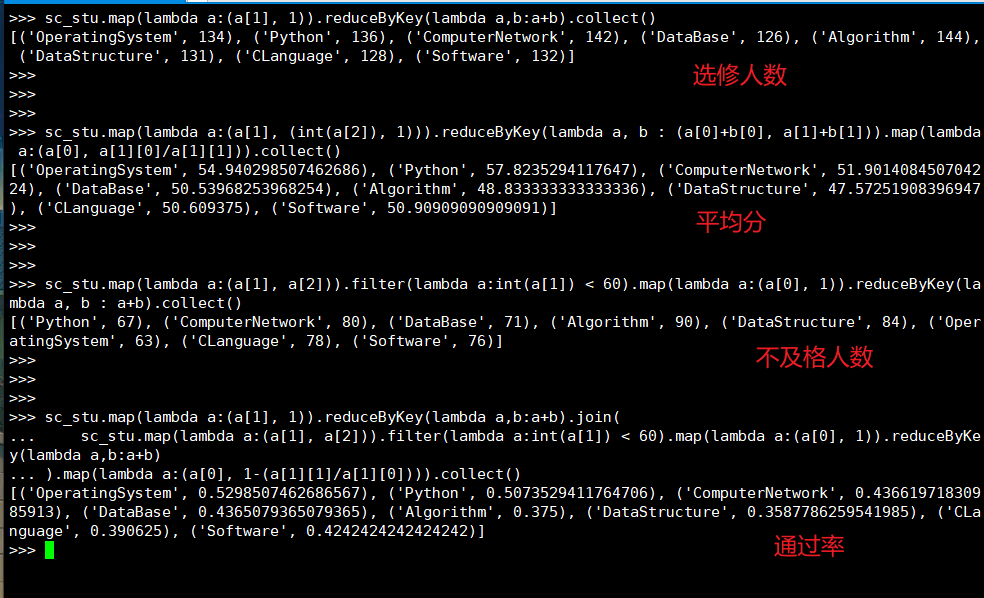
(1) RDD:
# 选修人数
>>> sc_stu.map(lambda a:(a[1], 1)).reduceByKey(lambda a,b:a+b).collect()
>>>
>>>
# 平均分
>>> sc_stu.map(lambda a:(a[1], (int(a[2]), 1))).reduceByKey(lambda a, b : (a[0]+b[0], a[1]+b[1])).map(lambda a:(a[0], a[1][0]/a[1][1])).collect()
>>>
>>>
# 不及格人数
>>> sc_stu.map(lambda a:(a[1], a[2])).filter(lambda a:int(a[1]) < 60).map(lambda a:(a[0], 1)).reduceByKey(lambda a, b : a+b).collect()
>>>
>>>
# 通过率
>>> sc_stu.map(lambda a:(a[1], 1)).reduceByKey(lambda a,b:a+b).join(
... sc_stu.map(lambda a:(a[1], a[2])).filter(lambda a:int(a[1]) < 60).map(lambda a:(a[0], 1)).reduceByKey(lambda a,b:a+b)
... ).map(lambda a:(a[0], 1-(a[1][1]/a[1][0]))).collect()
>>>
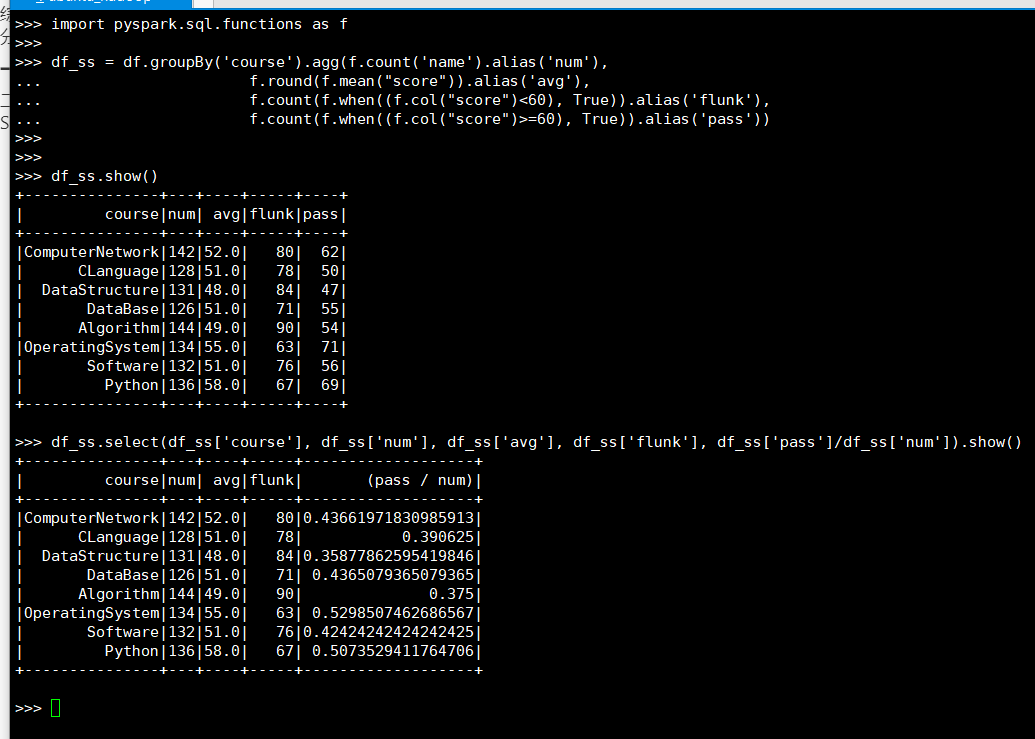
(2) DataFrame
>>> import pyspark.sql.functions as f
>>> df_ss = df.groupBy('course').agg(f.count('name').alias('num'),
... f.round(f.mean("score")).alias('avg'),
... f.count(f.when((f.col("score")<60), True)).alias('flunk'),
... f.count(f.when((f.col("score")>=60), True)).alias('pass'))
>>>
>>>
>>> df_ss.select(df_ss['course'], df_ss['num'], df_ss['avg'], df_ss['flunk'], df_ss['pass']/df_ss['num']).show()
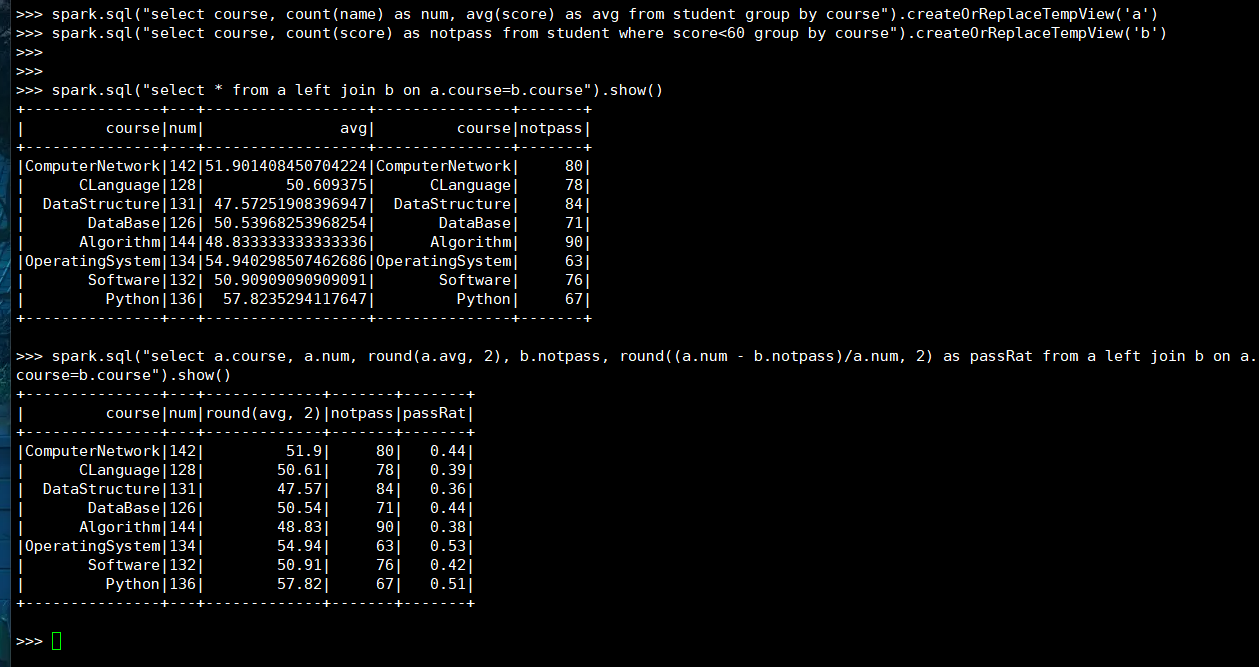
(3) spark.sql
>>> spark.sql("select course, count(name) as num, avg(score) as avg from student group by course").createOrReplaceTempView('a')
>>> spark.sql("select course, count(score) as notpass from student where score<60 group by course").createOrReplaceTempView('b')
>>>
>>>
>>> spark.sql("select * from a left join b on a.course=b.course").show()
>>
>>
>>> spark.sql("select a.course, a.num, round(a.avg, 2), b.notpass, round((a.num - b.notpass)/a.num, 2) as passRat from a left join b on a.course=b.course").show()
19. 优秀、良好、通过和不合格各有多少人?
(1) RDD:
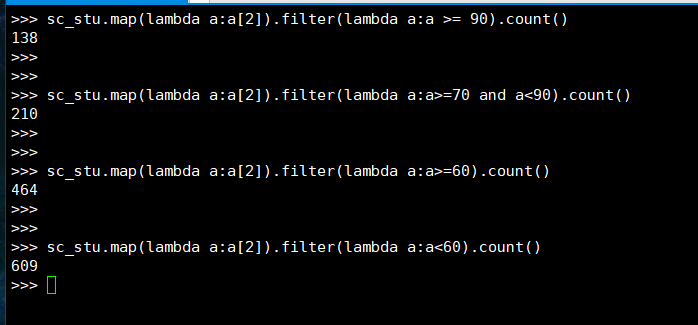
(2) DataFrame
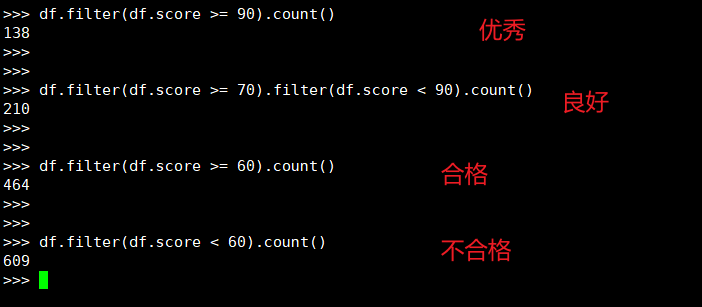
(3) spark.sql
>>> spark.sql("select count(name) as excellent from student where score>=90").createOrReplaceTempView('excellent')
>>> spark.sql("select count(name) as fine from student where score>=70 and score<90").createOrReplaceTempView('fine')
>>> spark.sql("select count(name) as pass from student where score>=60").createOrReplaceTempView('pass')
>>> spark.sql("select count(name) as notpass from student where score<60").createOrReplaceTempView('notpass')
>>>
>>>
>>> spark.sql("select * from excellent left join fine,pass,notpass").show()
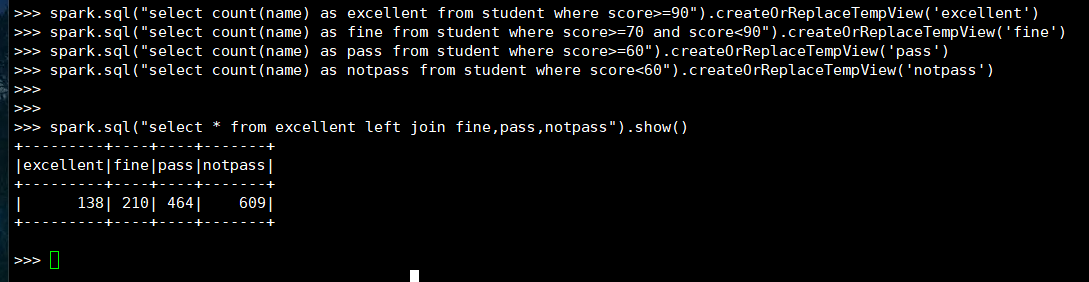
20. 同时选修了DataStructure和 DataBase 的学生
(1) RDD:

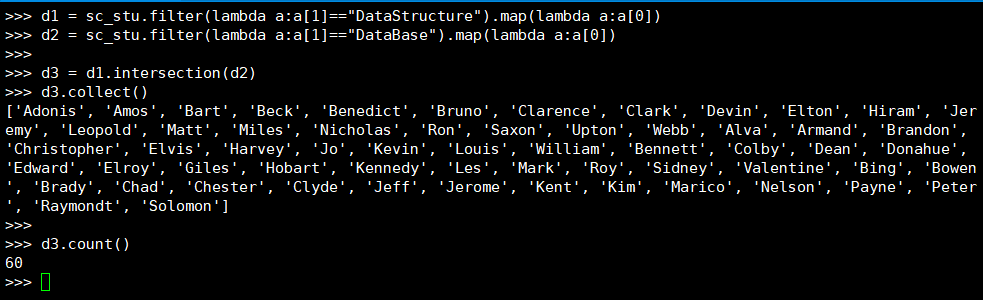
(2) DataFrame
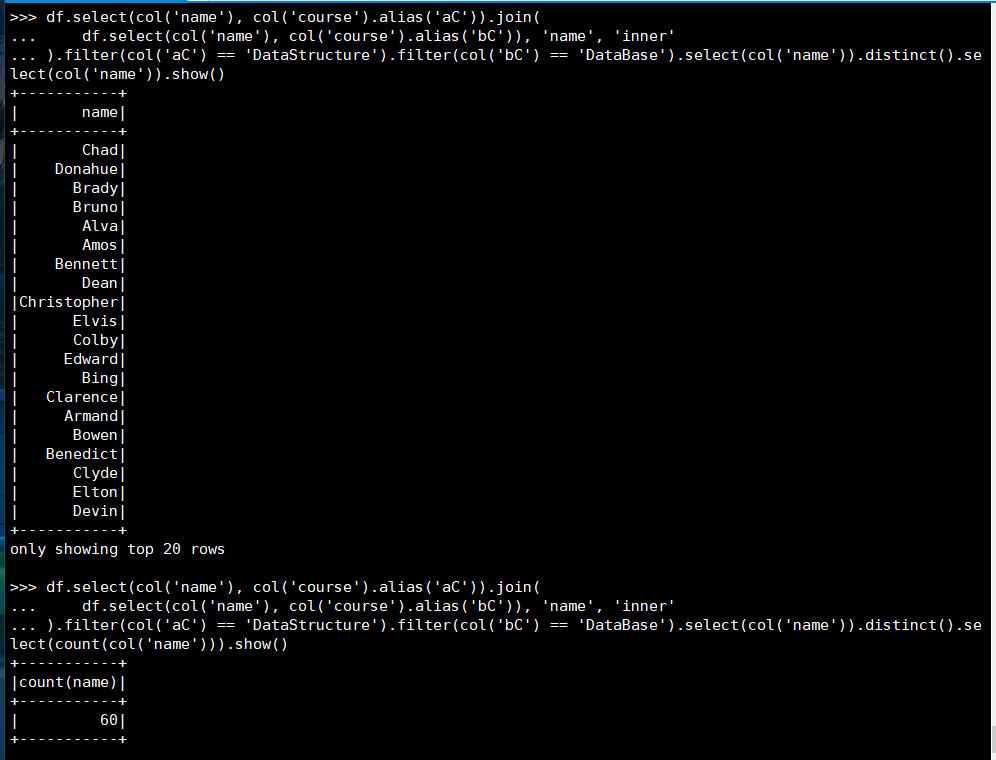
(3) spark.sql
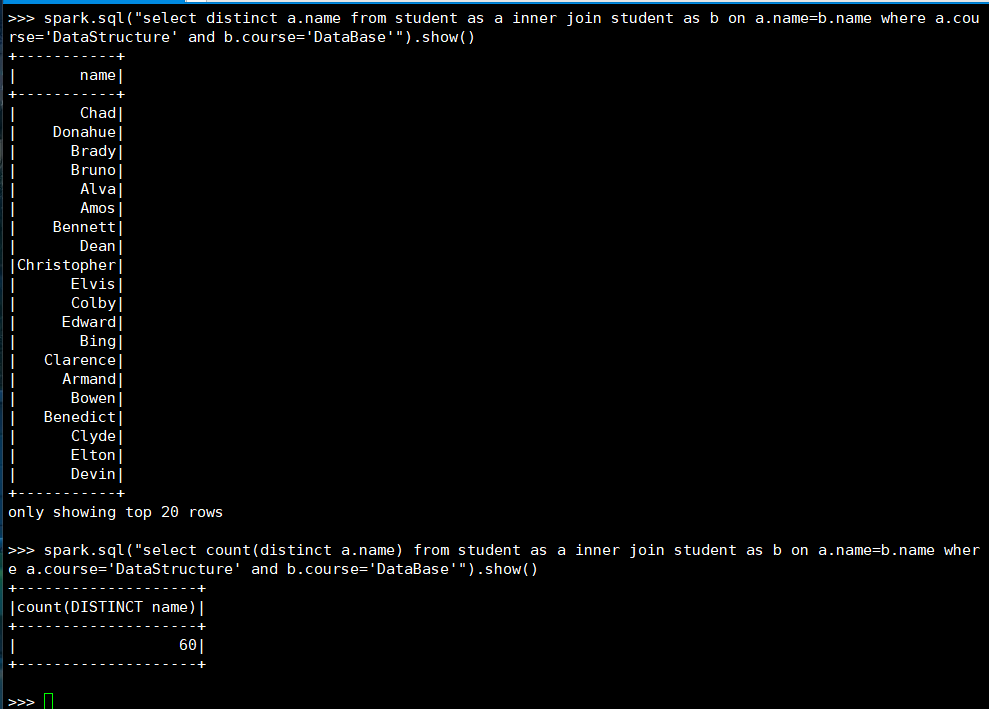
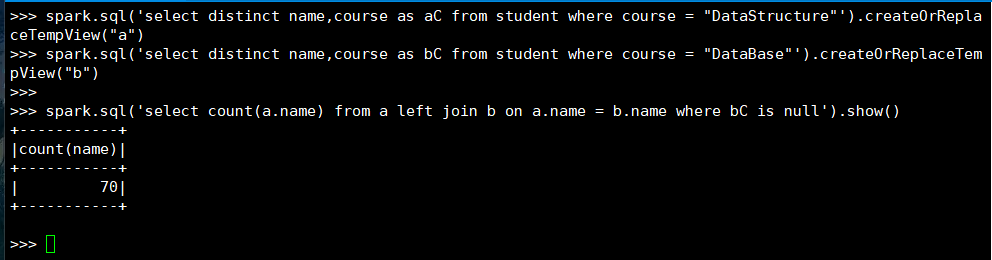
21. 选修了DataStructure 但没有选修 DataBase 的学生
(1) RDD:

(2) DataFrame
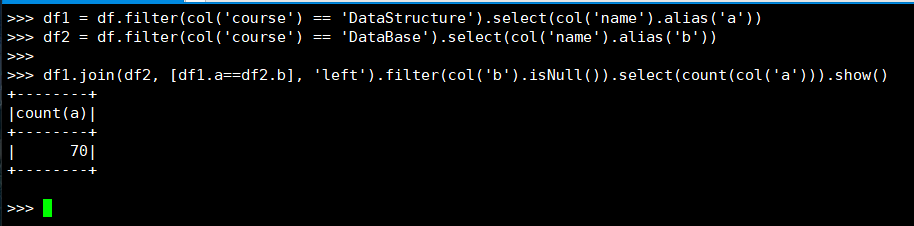
(3) spark.sql
22. 选修课程数少于3门的同学
(1) RDD:

(2) DataFrame
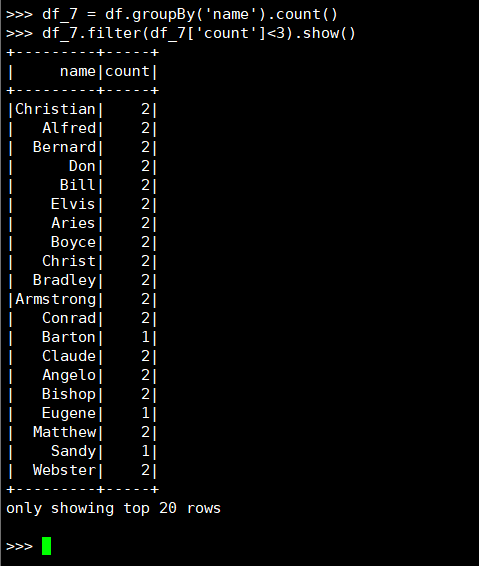
(3) spark.sql
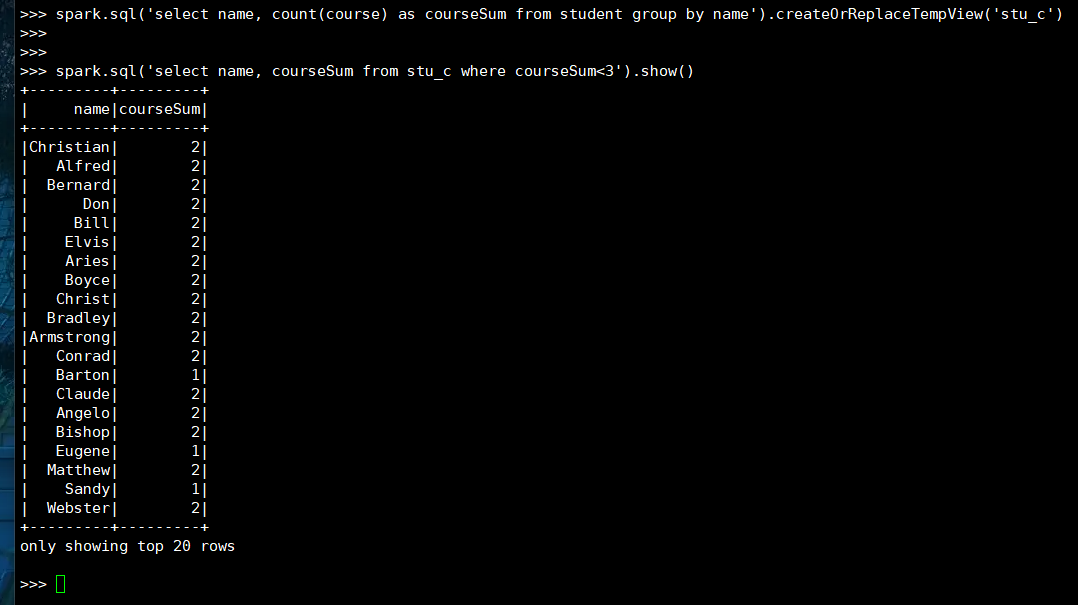
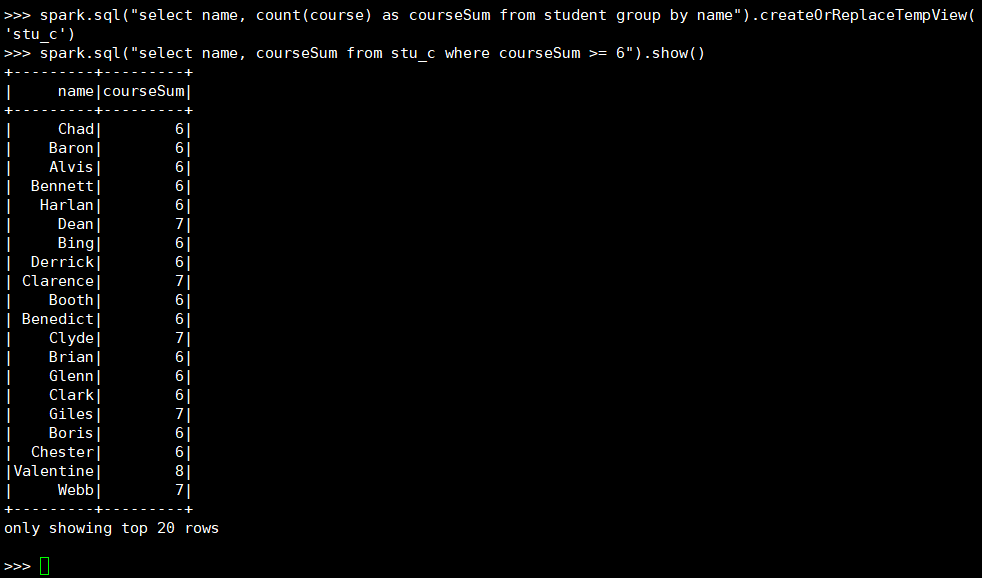
23. 选修6门及以上课程数的同学
(1) RDD:

(2) DataFrame
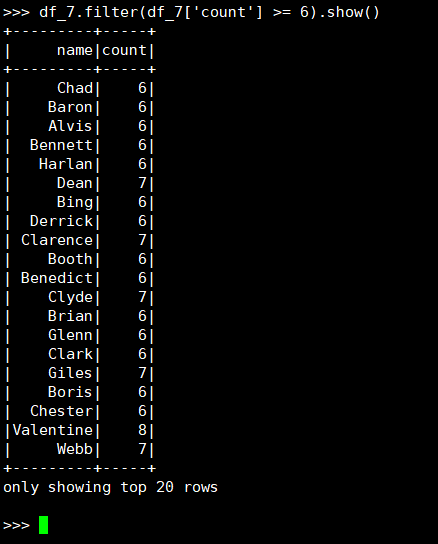
(3) spark.sql
24. 查询平均成绩大于等于60分的姓名和平均成绩
(1) RDD:
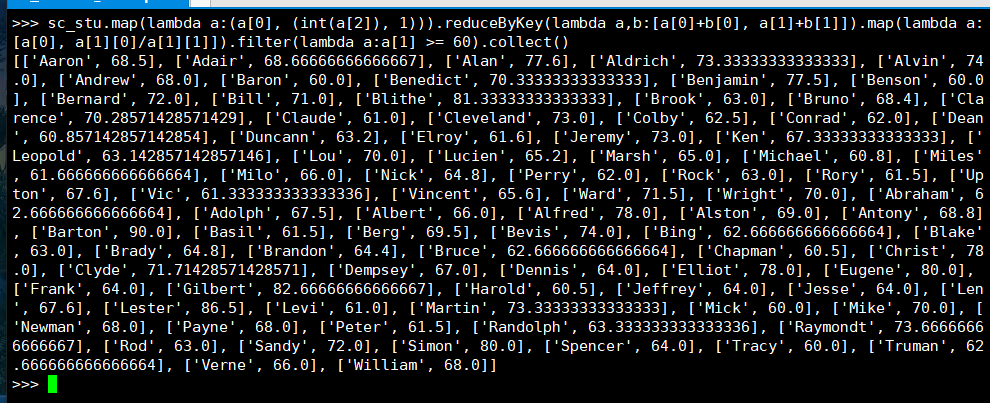
(2) DataFrame
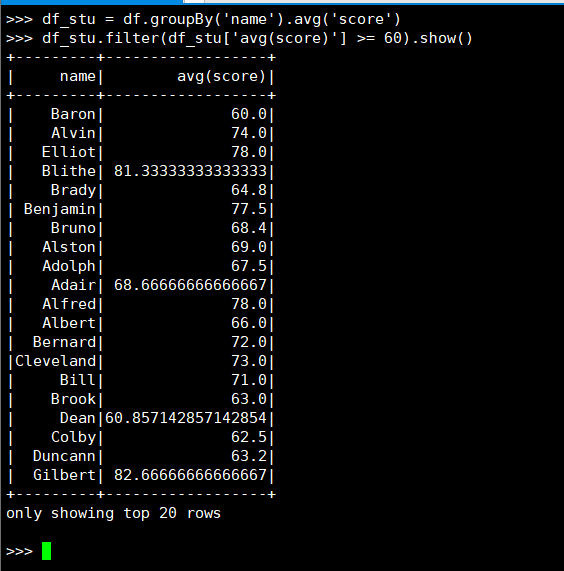
(3) spark.sql
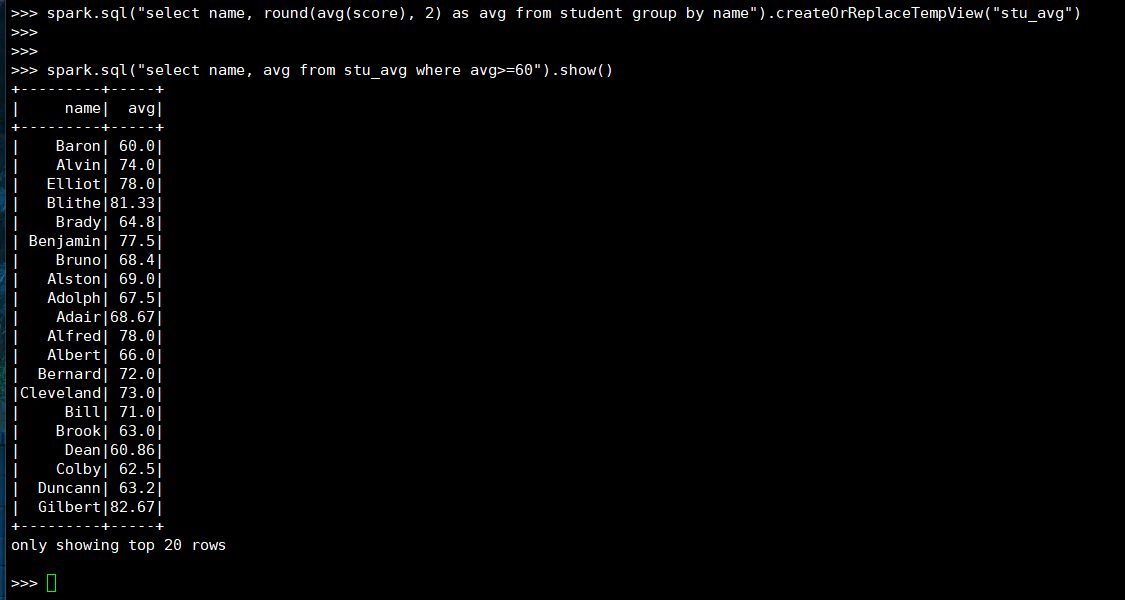
25. 找出平均分最高的10位同学
(1) RDD:

(2) DataFrame
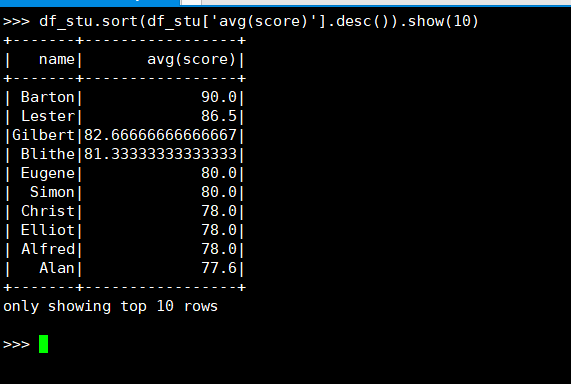
(3) spark.sql
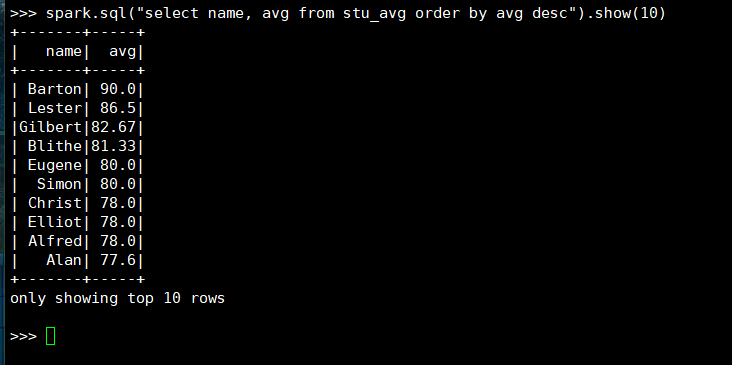
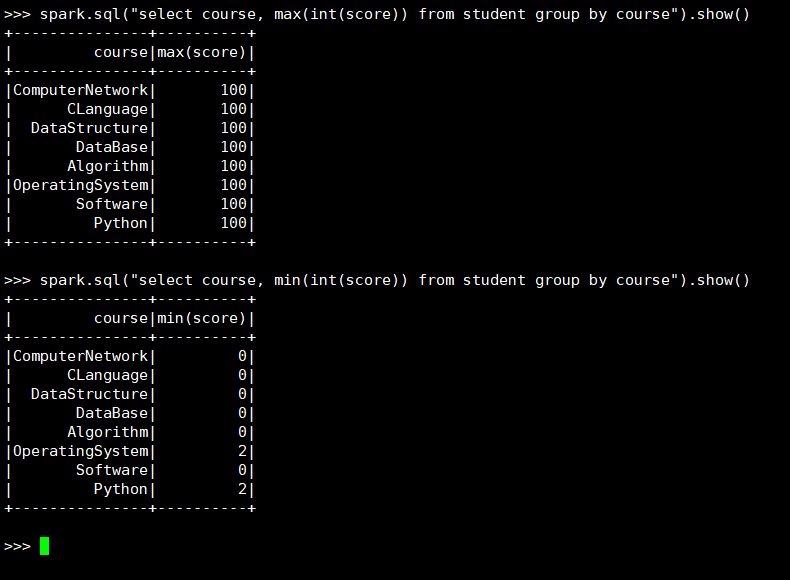
26. 求每门课的最高分最低分
(1) RDD:
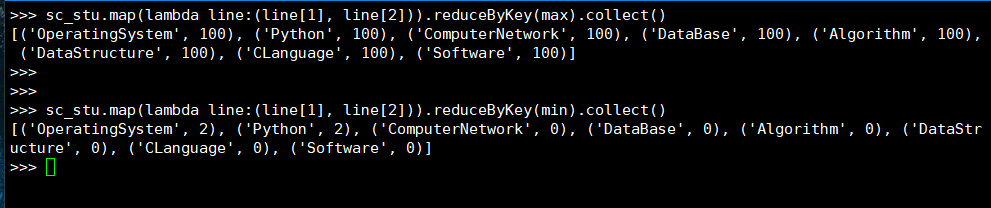
(2) DataFrame
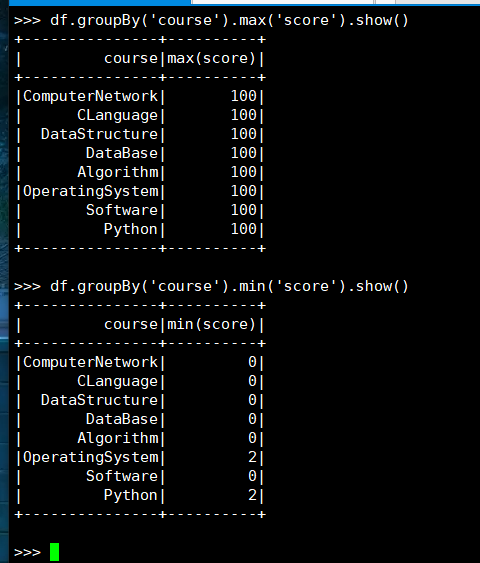
(3) spark.sql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号