



图文多模态大模型工作粗读
MLLM
Learning Transferable Visual Models From Natural Language Supervision (CLIP)
Motivation:
- 当前迁移学习的流行范式仍然需要少量任务特定样本对模型进行微调,作者希望利用自然语言做监督信号实现零样本学习。
- 之前的工作受限于模型发展和数据规模效果不佳,作者采用先进的transformer模型,构建了从互联网爬取的包含4亿图像文本对的数据集WIT。
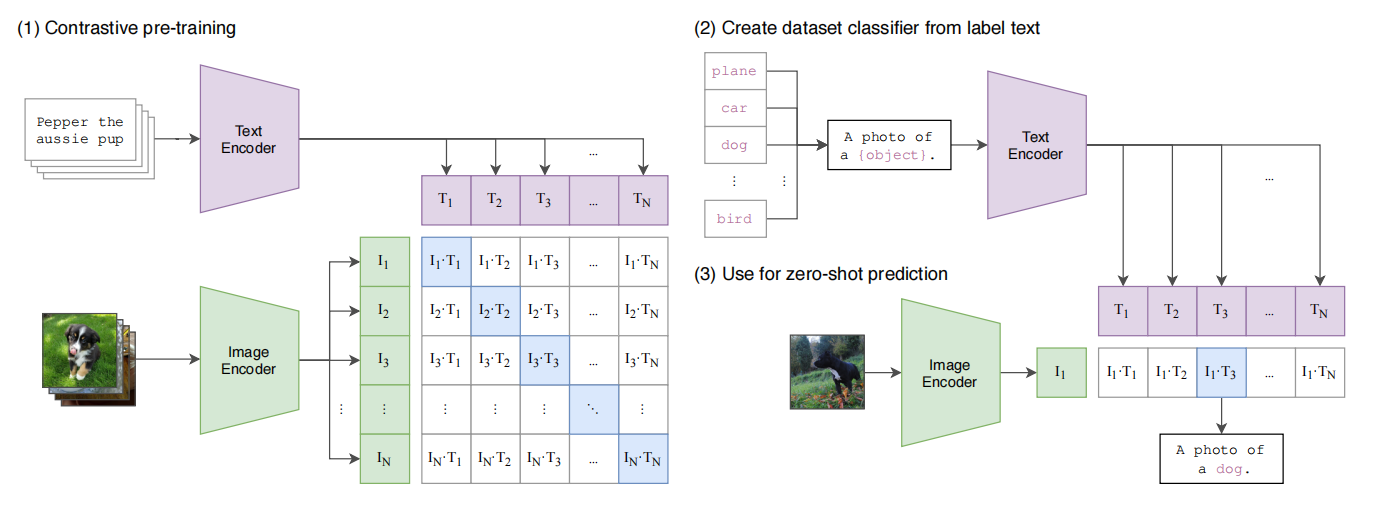
CLIP核心思想是通过海量的弱监督图像文本对通过对比学习,将图片和文本通过各自的预训练模型获得的编码向量在向量空间上对齐。
为什么是弱监督的呢?我想这里并非只有对角线上的才严格匹配,比如一个图是狗狗,一个batch里面其他文本也可能有狗狗。还有就是互联网上的这种图像文本对无法保证数量,也就是说并不是严格aligned的。
CLIP的zero-shot能力突出,可以在没有见过的数据上完成分类,我认为这可能来源于其庞大的数据量(来自互联网的四亿个图像文本对)。大力出奇迹。
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
motivation:
-
Bootstrapping: 用于训练的图像文本数据存在噪声(从互联网上爬取),如何清洗噪声?
-
Unified:encoder-model(理解)不适合做文本生成,encoder-decoder model(生成)不适合做图像文本检索,正如标题中Unified Vision-Language Understanding and Generation,作者想做一个多任务模型。
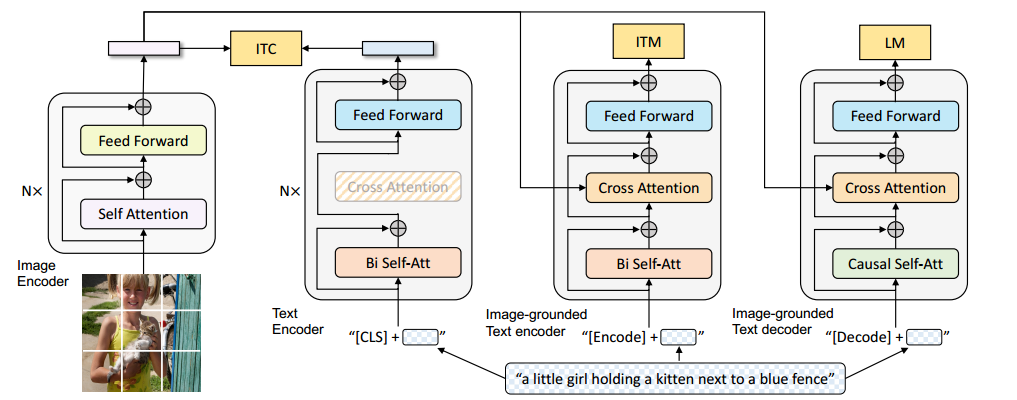
三塔模型,相同颜色共享参数。
模型:
-
图像分支:ImageNet预训练的ViT-8
-
文本多任务分支:
- Text-encoder(对比学习图像文本匹配分支): 预训练的Bert,对比学习I和T向量尽量对齐。
- Image-grounded text encoder(二分类图像文本细粒度匹配分支): CA模块插入图像特征
二分类任务一个关键的点是如何构造负样本,具体来讲,是足够难的负样本,这里可以用ITC任务失败的图像文本对来作为负样本。
- Image-grounded text decoder(生成文本描述):CSA代替BSA,MASK后续token,避免待预测token泄露
如何处理噪声数据:
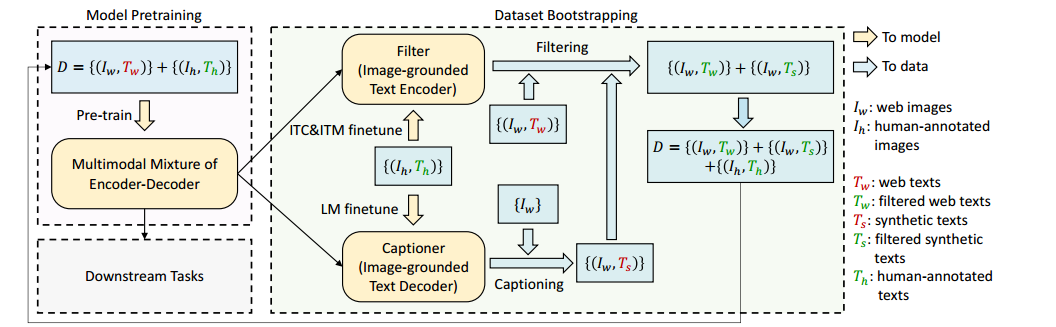
这是BLIP的另一大贡献,如何清洗弱监督的图像文本数据。
-
第一步,我们在训练时把人标注的,我们认为顶级数据和互联网上标注的,一般的,可能存在的噪声数据,一起放进去训练,然后拿这份数据去pretrain ITC,ITM和LM的训练。
-
第二步,我们用人类的标注数据去tuning 这3个下游任务。这样,这3个模型其实就接近于我们想要的效果了,符合了下游任务的范式,这还没完。
-
第三步,把互联网标注的语料,拿ITC,和ITM给过滤了(判断图文是否匹配),错的,我就不要了,只留下好的,就是Tw的绿色部分,另外还可以用LM来标注成Ts(可能不准确)过滤一遍,再和老的数据,重新灌注给模型的变成新的pretrain,完成下一个epoch,周而复始,把不断迭代优化Loss。
以上就是Blip的创新和训练方式。
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
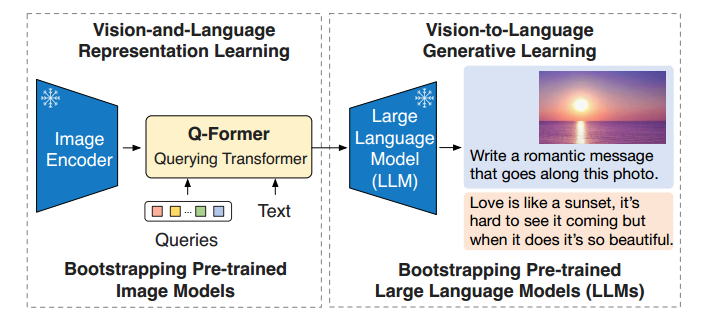
BLIP的缺点是要重新训练模型,训练的参数量还比较大。且还有一个数据的问题,图像数据很多,文本数据也很多,那么图像文本对的数据就比较少了,CLIP这里是爬取的互联网上的图片和注释,噪声较多。
左边是表征学习,右边是生成学习。
创新点:
- 在Image Encoder和LLM中间搭建了一座桥(轻量架构QFormer(querying transformer)来建立图像-文本的对齐的bridge),将表征学习得到的向量投射到文本向量附近,能够被语言模型所理解(图像prompt),而图像encoder和文本decoder是被冻结而不需要参数的。只需要训练Q-Former即可。
- 二阶段预训练范式实现高效训练,实现将目前的视觉backbone与LLM模型连接起来。 (后面就随便换了,LLM越强,模型越强,比如GPT4...)
表征学习:在保留图像信息的前提下变为一个向量。
训练阶段一:训练Q-Former
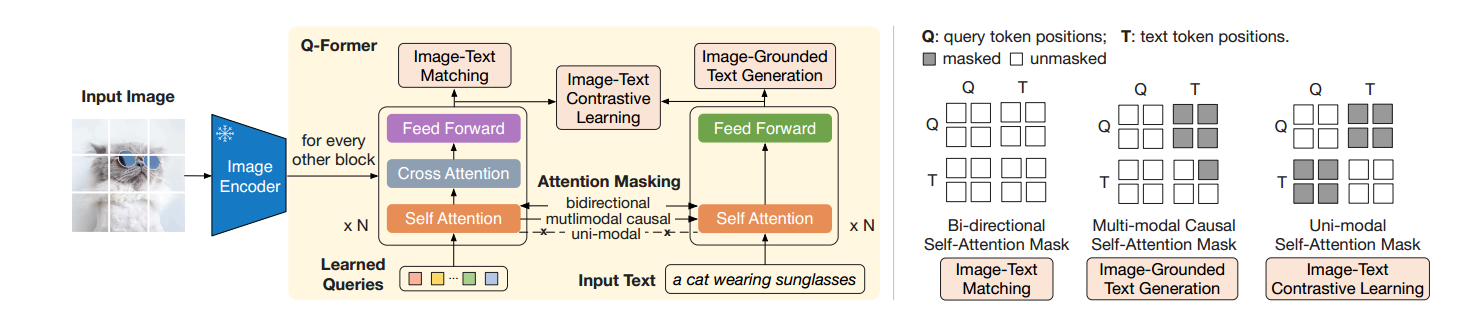
训练阶段二:将对齐后的表征向量映射到LLM中,使得模型获得图片信息,进行指令微调。
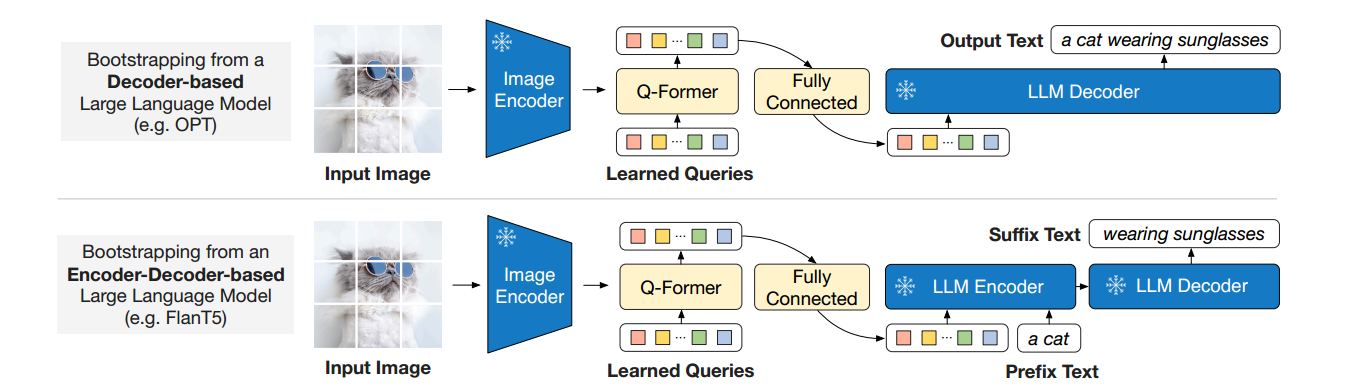
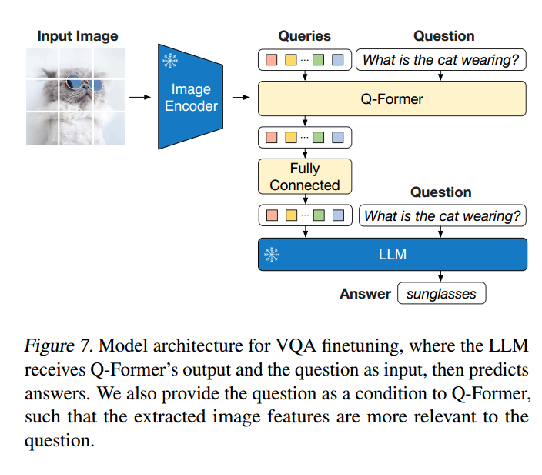
缺点:对细节的处理不到位,可能是ViT图像编码器的限制,不能把所有的细节都抽出来。(教科书示意图问答)
LLaVA:Visual Instruction Tuning
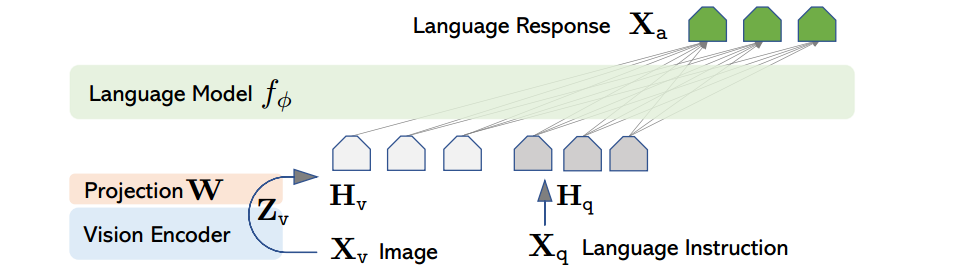
它是2阶段训练:
第一阶段,拿clip 的image encoder来训练,冻结住LLM,经过一个W的project转换(可以理解为线性层的矩阵对齐),说白了,就是一个线性层,image转换embedding的层W。第一阶段是将image和text特征进行对齐。
第二阶段,冻住image encoder,然后再训练W和LLM,它是将图片还有prompt的语料(这prompt语料是GPT生成的关于这个图片的问题)一齐作为输入,然后把这个东西输入进随便什么LLM来训练,也是有监督的,监督的label就是生成的响应语句,求Loss。第二阶段是让大语言模型理解图片和文本,并具有多轮对话能力,是一个微调过程
总结:
① 更强大的单模态模型影响效果。
② LLM指令学习丰富VQA任务数据。
③ 冻结大模型保留表征能力,对特征进行对齐。
反思:
① 使用LLM帮助生成数据会引入噪声信息。夹带私货?
② 示意图问答要求更加细粒度图像特征,如何得到。
③ 多模态大模型在教科书示意图问答方面如何应用。
挖坑:transformer llm


 浙公网安备 33010602011771号
浙公网安备 33010602011771号