




一. 窗口函数的作用
窗口函数(Window Function),又被叫做分析函数(Analytics Function),通常在需要对数据进行分组汇总计算时使用,因此与聚集函数有一定的相似性。但与聚集函数不同的是,聚集函数通过对数据进行分组,仅能够输出分组汇总结果,而原始数据则无法展现在结果中。而窗口函数则可以同时将原始数据和聚集分析结果同时显示出来。通过下例,大家可以体会一下区别。
给定表score(id, classid, score),每行表示学生id,所在班级id以及考试成绩,数据如下图所示:

如果我们想获取每个班的总分、平均分及学生数量,可以通过对classid进行聚集,查询语句为:
select classid, sum(score), avg(score), count(*) from score group by classid order by classid;结果如下:

通过这个结果,我们了解了班级1和2的基本信息,但是此时丢掉了学生信息,也不知道每个学生在班级中的排名如何。如果想查询这些信息,当然可以通过将聚集结果和原表进行Join得出,但显然更繁琐。而通过窗口函数的语句,我们可以轻而易举地将所需要的信息查询出来。
select classid, id, score,
sum(score) over(partition by classid),
avg(score) over(partition by classid),
count(*) over(partition by classid),
rank() over(partition by classid order by score desc)
from score
order by classid;结果如下:

通过以上信息,我们可以很方便地进行进一步的查询,例如:查询每个班超过平均分的学生id,排名前5的学生id等。
可以看出,窗口函数其实是对查询,聚集等多个操作所做的一个组合操作,但相对于多个操作而言,使用窗口函数在完成功能的情况下,书写也更加简洁。同时,窗口函数还提供了更多的函数、更多的聚集方式以支持多样化的功能,而且支持分组中的排序功能。通过与聚集结果比较,可以方便地提取符合一定统计要求的记录信息。
二. 窗口函数的SQL语法介绍
单个窗口函数表达式的主要语法为:
SUM(SCORE) OVER (PARTITION BY CLASSID ORDER BY SCORE ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)
该表达式主要由以下部分组成(下图为图解):

- 窗口函数表达式(紫色部分):指定该窗口函数进行计算的聚集函数,可以是SUM(), COUNT(), AVG(), MIN(), MAX()等聚集函数,可以通过以下语句在GaussDB(DWS)中查到:
SELECT proname FROM pg_proc WHERE proisagg = TRUE;也可以是其它专有的窗口函数,可以通过如下语句在GaussDB(DWS)系统表中查到:
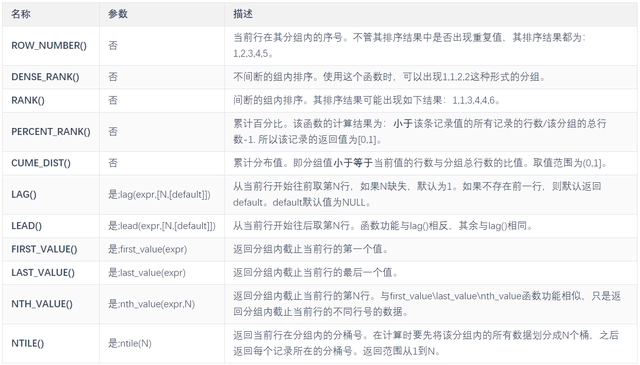
SELECT proname FROM pg_proc WHERE proiswindow = TRUE;GaussDB(DWS)目前支持的专有窗口函数有15个:

下面将详细说明一下其中常用的窗口函数ROW_NUMBER(), RANK(), DENSE_RANK()的区别。首先通过如下查询的结果来对比。
SELECT id, classid, score,
ROW_NUMBER() OVER(ORDER BY score DESC),
RANK() OVER(ORDER BY score DESC),
DENSE_RANK() OVER(ORDER BY score DESC)
FROM score;

可以看出,三个函数都是用于进行行排序的,且参数个数为0。通过①可以看出ROW_NUMBER()和RANK()的区别:前者顾名思义,对行从1开始进行编号,无论数据是否重复,结果不重;而后者对于相同的数据,给出的排序结果是相同的。通过②可以看出RANK()和DENSE_RANK()的区别:前者在重复值后,编号和ROW_NUMBER()是相同的,虽然相同的数据编号相同,但仍然占用多个编号位置;而后者对于重复值只占用一个编号,重复后紧接着进行编号。
在实际应用着,前两个函数应用较多,ROW_NUMBER()主要用于行编号,用于分页展示等应用中;而RANK()主要用于对结果进行排序后展示。
注意:窗口函数返回的排名数据类型为unsigned,mysql的unsigned做相减出现负数时会出现错误情况,需要用cast() 函数再转换为signed类型数据才能作差:cast(rn1 as signed)
- 窗口函数分区列(红色部分):表示根据哪一列进行分组计算,类似于聚集语句中的GROUP BY子句。该部分可以没有,类似于聚集语句,表示对所有语句划分同一组处理。
- 窗口函数排序列(绿色部分):表示数组划分到同一组后,在进行窗口函数计算前排序的顺序,可以指定多列,语法与ORDER BY类似。当聚集函数计算结果与顺序无关时,此子句可以省略。
- 窗口函数移动窗口选项(蓝色部分):该选项也称为Window Frame Option,默认可以省略,表示对每个分组内所有行进行聚集计算(无排序列时)或对每个分组内起始行到当前行进行聚集计算(有排序列时)。但指定该选项后,仅针对指定的窗口内的元组进行聚集计算。
对分组内所有行结果,当需要指定一个窗口时,我们需要指定开始的行和结束的行,则聚集函数将针对窗口之内的所有行的结果进行计算。因此,移动窗口选项的主要语法为:
RANGE|ROWS [BETWEEN] <rows_loc> [AND <rows_loc>]
或
RANGE|ROWS <rows_loc>第一种语法同时指定开始行和结束行,第二种语法仅指定开始行,结束行默认为当前行。
<rows_loc>用于指定某一行,支持以下五种用法:
- UNBOUNDED PRECEDING
表示该分组的第一行
- UNBOUNDED FOLLOWING
表示该分组的最后一行
- CURRENT ROW
表示当前行。
- <expression> PRECEDING
表示从当前行往前数<expression>数量的行,其中<expression>不能包含变量。RANGE选项禁用。
- <expression> FOLLOWING
表示从当前行往后数<expression>数量的行,其中<expression>不能包含变量。RANGE选项禁用。
例如:
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 以该分组所有元组为窗口
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 以该分组起始行到当前行为窗口
ROWS BETWEEN 10 PRECEDING AND 5 FOLLOWING 以该分组当前行前10行到后5行为窗口(不能超过起始行和结束行)
示例:下图左边表含有列x,计算的表达式值SUM(x) OVER(ROWS 2 PRECEDING AND 2 FOLLOWING)的值见右表所示,中间箭头上的数字表示起始和结束窗口的行号。例如:第1行的窗口为[1-2, 1+2]=[1, 3](不超过起始行);第4行的窗口为[4-2, 4+2]=[2, 6]。

了解完单个窗口函数表达式的语法,我们来看下在SQL语句中的使用规范。
首先还是简要地理解一下窗口函数该怎么写,不过这次要多加一点点东西
[你要的操作] OVER ( PARTITION BY <用于分组的列名>
ORDER BY <按序叠加的列名>
ROWS <窗口滑动的数据范围> )
<窗口滑动的数据范围> 用来限定[ 你要的操作] 所运用的数据的范围,具体有如下这些:
当前行 - current row
之前的行 - preceding
之后的行 - following
无界限 - unbounded
表示从前面的起点 - unbounded preceding
表示到后面的终点 - unbounded following
举例理解一下:
取当前行和前五行:ROWS between 5 preceding and current row --共6行
取当前行和后五行:ROWS between current row and 5 following --共6行
取前五行和后五行:ROWS between 5 preceding and 5 folowing --共11行
-
单个查询中可以包含一个或多个窗口函数表达式。
-
窗口函数仅能出现在输出列中。如果需要使用窗口函数的值进行条件过滤,需要将窗口函数嵌套在子查询中,在外层使用窗口函数表达式的别名进行条件过滤。例如:
select classid, id, score from (select *, avg(score) over(partition by classid) as avg_score from score) where score >= avg_score; -
窗口函数所在查询块中支持使用GROUP BY表达式进行分组去重,但要求窗口函数中的PARTITION BY子句中必须是GROUP BY表达式的子集,以保证窗口函数在GROUP BY列去重后的结果上进行窗口运算,同时ORDER BY子句的表达式也需要是GROUP BY表达式的子集,或聚集运算的聚集函数。例如:
select classid, rank() over(partition by classid order by sum(score)) as avg_score from score group by classid, id;
三.窗口函数range和rows的区别
【窗口分区】:就是将窗口指定列具有相同值的那些行进行分区,分区与分组比较类似,但是分组指定后对于整个SELECT语句只能按照这个分组,不过分区可以在一条语句中指定不同的分区。
【窗口排序】:分区之后可以指定排序列,那么在窗口计算之前,各个窗口的行的逻辑顺序将确定。
【窗口框架】:框架是对窗口进行进一步的分区,框架有两种范围限定方式:一种是使用ROWS子句,通过指定当前行之前或之后的固定数目的行来限制分区中的行数;另一种是RANGE子句,按照排序列的当前值,根据相同值来确定分区中的行数。
- 当使用框架时,必须要有ORDER BY子句,如果仅指定了ORDER BY子句而未指定框架,那么默认框架将采用 RANGE UNBOUNDED PRECEDING AND CURRENT ROW。
- 如果窗口函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算。
- 如果ROWS/RANGE子句采用 <window frame preceding>,那么CURRENT ROW 作为框架的默认结束行,例如:“ROWS 5 PRECEDING” 等价于 “ROWS BETWEEN 5 PRECEDING AND CURRENT ROW”。
- PS:RANGE 只支持使用 UNBOUNDED 和 CURRENT ROW 窗口框架分隔符(未必正确)。
-
rows 是指行数,以ID1为例, 月数 1,2,3,4,7,8。 当我们用 rows between 2 preceding and current row时,当月数等于7时,我们sum了7所在的一行加7之前的两行(月数3和4)所以sum是190;range 是指逻辑或者读值。我的理解就是这玩意比较智能,当我们用 range between 2 preceding and current row时,当月数等于7时, range智能的选择了 7-1 = 6月,和 7-2 =5月这两个月,然而表里id 1并没有这两个月所以是0,所以sum是90。
select id,
sum(id) over (order by id ) default_num,
sum(id) over (order by id range between unbounded preceding and current row) range_sum,
sum(id) over (order by id rows between unbounded preceding and current row) rows_sum,
sum(id) over (order by id range between 1 preceding and 2 following) range_sum1,
sum(id) over (order by id rows between 1 preceding and 2 following) rows_sum1
from test;| id | default_num | range_sum | rows_sum | range_sum1 | rows_sum1 |
|---|---|---|---|---|---|
| 1 | 2 | 2 | 1 | 5 | 5 |
| 1 | 2 | 2 | 2 | 5 | 11 |
| 3 | 5 | 5 | 5 | 3 | 16 |
| 6 | 23 | 23 | 11 | 33 | 21 |
| 6 | 23 | 23 | 17 | 33 | 25 |
| 6 | 23 | 23 | 23 | 33 | 27 |
| 7 | 30 | 30 | 30 | 42 | 30 |
| 8 | 38 | 38 | 38 | 24 | 24 |
| 9 | 47 | 47 | 47 | 17 | 17 |
rows 是物理窗口,是哪一行就是哪一行,与当前行的值(order by key 的 key 的值)无关,只与排序后的行号相关,就是我们常规理解的那样。
range 是逻辑窗口,与当前行的值有关(order by key 的 key 的值),在 key 上操作 range 范围。
结果分析
1.当order by后面的rows/range缺失时,默认是range between unbounded preceding and current row
2.range_sum 按照 order by 的值进行划分窗口大小,由于出现两个id = 1 的记录,两个1 会划分到同一个窗口,所以第一行和第二行两个1进行了求和都是2,第三行进行累加5,第4 5 6 三行都是6,再一次同时划分到了同一个窗口进行累加,7 8 9 分别和第3行一样
3.rows_sum :rows 与排序值无关,与排序后的序号有关,所以在进行汇总求和的时候,即使遇到数值相同的数据,但是由于排序后的序号不同,不会将两个相同的数同时划分到同一个窗口。
后面两列划分方式和之前两列一样;
平时工作中 range可应用于订单日期等纬度值,rows可应用于金额,用户数汇总值。
四.其他窗口函数
lag 把数据从上往下推,上方出现空格
lead 把数据从下往上推,下方出现空格
有3个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是超出记录窗口时的默认值(不知道用什么可以用null)
一道LeetCode题目:

first_value, last_value 取分组排序后截止到到当前行第一个值,最后一个值,所以在使用last_value时需要变通一下:order by date desc


 浙公网安备 33010602011771号
浙公网安备 33010602011771号