hadoop高可用安装和原理详解
本篇主要从hdfs的namenode和resourcemanager的高可用进行安装和原理的阐述。
一、HA安装
1、基本环境准备
1.1.1、centos7虚拟机安装,详情见VMware安装Centos7虚拟机
1.1.2、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
1.1.3、修改selinux
vim /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
[hadoop@lgh2 ~]$ cat /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of three two values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted
1.1.4、安装java
java 安装 tar -zxvf jdk-8u201-linux-x64.tar.gz -C /usr/local/ vim /etc/profile export JAVA_HOME=/usr/local/jdk1.8.0_201 export JRE_HOME=/usr/local/jdk1.8.0_201/jre export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
source /etc/profile
1.1.5、添加用户hadoop
groupadd hadoop useradd -g hadoop -d /home/hadoop echo 'hadoop' | passwd hadoop --stdin
1.1.6、修改/etc/hosts
cat /etc/hosts 192.168.88.131 lgh1 192.168.88.132 lgh2 192.168.88.133 lgh3
如上环境我们准备三台机器,如上1.1.6所见:
1.1.7、配置免密登录
ssh-keygen -t rsa #这个操作需要连续三次按enter键, ssh-copy-id lgh3 ssh-copy-id lgh2 ssh-copy-id lgh1
1.1.8、配置时间同步(这个很重要,在生产环境必定要有,不过自己玩也可以不用配置)
首先我们选定192.168.88.131(lgh1)这台为时间标准的节点,其他两台机器同这个节点进行同步
设置192.168.88.131这个节点:
yum install -y ntp #如果没有安装就安装 [root@lgh1 ~]# rpm -qa | grep ntp #查看安装结果 ntp-4.2.6p5-29.el7.centos.x86_64 #用来提供时间同步服务 ntpdate-4.2.6p5-29.el7.centos.x86_64 #和某台服务器进行同步
修改/etc/ntp.conf文件
egrep -v "^$|#" /etc/ntp.conf [root@lgh1 ~]# egrep -v "^$|#" /etc/ntp.conf driftfile /var/lib/ntp/drift restrict default nomodify notrap nopeer noquery restrict 192.168.88.0 mask 255.255.255.0 nomodify notrap restrict 127.0.0.1 restrict ::1 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst server 127.127.1.0 fudge 127.127.1.0 stratum 10 includefile /etc/ntp/crypto/pw keys /etc/ntp/keys disable monitor
systemctl enable ntpd #启动
其他两个节点:lhg2和lgh3设置如下:
首先要安装ntpd:yum install -y ntp #如果没有安装则要安装
新增crontab -e
*/5 * * * * /usr/sbin/ntpdate -u 192.168.88.131 #表示每五分钟和131时间同步一次
测试:(可以通过如下命令修改131的时间,看其他两个节点是否能同步成功,亲测成功)
date "+%Y-%m-%d %H:%M:%S"
date -s '2018-09-20 10:02:02'
2、hadoop高可用安装
1.2.1、安装规划--目录
mkdir -p /opt/hadoop #存放hadoop文件,安装目录 chown -R hadoop:hadoop /opt/hadoop mkdir -p /opt/data/hadoop/hdfs #存放namenode和datanode的数据 mkdir -p /opt/data/hadoop/tmp #存放临时文件 chown -R hadoop:hadoop /opt/data/hadoop/hdfs chown -R hadoop:hadoop /opt/data/hadoop/tmp
1.2.2、角色规划

解压1.2.3、zookeeper安装
cd /opt/hadoop tar -zxvf zookeeper-3.4.8.tar.gz ln -s zookeeper-3.4.8 zookeeper
配置环境变量
vim /etc/profile export ZOOKEEPER_HOME=/opt/hadoop/zookeeper export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH source /etc/profile
修改配置zoo.cfg
cd /opt/hadoop/zookeeper/conf cp zoo_sample.cfg zoo.cfg vim zoo.cfg tickTime=2000 #服务器与客户端之间交互的基本时间单元(ms) initLimit=10 # 此配置表示允许follower连接并同步到leader的初始化时间,它以tickTime的倍数来表示。当超过设置倍数的tickTime时间,则连接失败 syncLimit=5 # Leader服务器与follower服务器之间信息同步允许的最大时间间隔,如果超过次间隔,默认follower服务器与leader服务器之间断开链接 dataDir=/opt/hadoop/zookeeper/data #保存zookeeper数据路径 dataLogDir=/opt/hadoop/zookeeper/dataLog #保存zookeeper日志路径,当此配置不存在时默认路径与dataDir一致 clientPort=2181 #客户端访问zookeeper时经过服务器端时的端口号 server.1=lgh1:2888:3888 #表示了不同的zookeeper服务器的自身标识,作为集群的一部分,每一台服务器应该知道其他服务器的信息 server.2=lgh2:2888:3888 server.3=lgh3:2888:3888 maxClientCnxns=60 #限制连接到zookeeper服务器客户端的数量
修改myid文件
cd /opt/hadoop/zookeeper mkdir data dataLog cd /opt/hadoop/zookeeper/data touch myid && echo 1 > myid
分发并修改myid文件
scp -r /opt/hadoop/zookeeper hadoop@lgh2:/opt/hadoop/
scp -r /opt/hadoop/zookeeper hadoop@lgh3:/opt/hadoop/
vim /opt/hadoop/zookeeper/data/myid #lgh2 修改为2
vim /opt/hadoop/zookeeper/data/myid #lgh3 修改为3
启动并查看状态
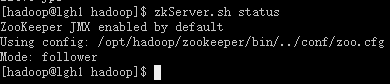
zkServer.sh start
zkServer.sh status
一台为leader状态,其他两个为follower状态


1.2.4、解压hadoop
cd /opt/hadoop tar -zxvf hadoop-2.7.7.tar.gz ln -s hadoop-2.7.7 hadoop
1.2.5、配置环境变量
export HADOOP_HOME="/opt/hadoop/hadoop-2.7.7"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
1.2.6、修改hadoop-env.sh、mapred-env.sh、yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_201
1.2.7、修改hdfs-site.xml文件
<configuration>
<property>
<!-- 为namenode集群定义一个services name -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>lgh1:8020</value>
</property>
<property>
<!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>lgh2:8020</value>
</property>
<property>
<!--名为nn1的namenode 的http地址和端口号,web客户端 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>lgh1:50070</value>
</property>
<property>
<!--名为nn2的namenode 的http地址和端口号,web客户端 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>lgh2:50070</value>
</property>
<property>
<!-- namenode间用于共享编辑日志的journal节点列表 -->
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推荐使用nameservice,默认端口号是:8485 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://lgh1:8485;lgh2:8485;lgh3:8485/mycluster</value>
</property>
<property>
<!-- journalnode 上用于存放edits日志的目录 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/hadoop/tmp/data/dfs/jn</value>
</property>
<property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- journalnode集群之间通信的超时时间 -->
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--namenode路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/data/hadoop/hdfs/nn</value>
</property>
<!--datanode路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/data/hadoop/hdfs/dn</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
1.2.8、修改core-site.xml
<configuration>
<property>
<!-- hdfs 地址,ha中是连接到nameservice -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- -->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>lgh1:2181,lgh2:2181,lgh3:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
<description>ms</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>*</value>
</property>
</configuration>
1.2.9、修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<!-- 启用resourcemanager的ha功能 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 为resourcemanage ha 集群起个id -->
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<!-- 指定resourcemanger ha 有哪些节点名 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定第一个节点的所在机器 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>lgh2</value>
</property>
<property>
<!-- 指定第二个节点所在机器 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>lgh3</value>
</property>
<property>
<!-- 指定resourcemanger ha 所用的zookeeper 节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>lgh1:2181,lgh2:2181,lgh3:2181</value>
</property>
<property>
<!-- -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://lgh2:19888/jobhistory/logs/</value>
</property>
</configuration>
1.2.10、修改 slaves
lgh1
lgh2
lgh3
1.2.11、分发到其他两个节点
scp /opt/hadoop/hadoop-2.7.7 hadoop@lgh2:/opt/hadoop/
scp /opt/hadoop/hadoop-2.7.7 hadoop@lgh3:/opt/hadoop/
1.2.12、格式化nomenode和zookeeper
[hadoop@lgh1 ~]$ hdfs namenode -format
[hadoop@lgh2 ~]$ hdfs namenode -bootstrapStandby
[hadoop@lgh1 ~]$ hdfs zkfc -formatZK #格式化zookeeper
1.2.13、启动
stop-dfs.sh #关闭所有journalnode start-dfs.sh #启动namenode,datanode,journalnode等组件 start-yarn.sh #启动yarn [hadoop@lgh2 ~]$ /opt/hadoop/hadoop/sbin/yarn-daemon.sh start resourcemanager #这里一定要注意是yarn-daemon.sh,启动resourcemanager [hadoop@lgh3 ~]$ /opt/hadoop/hadoop/sbin/yarn-daemon.sh start resourcemanager
1.2.14、查看进程
jps (图片不协调。。。)



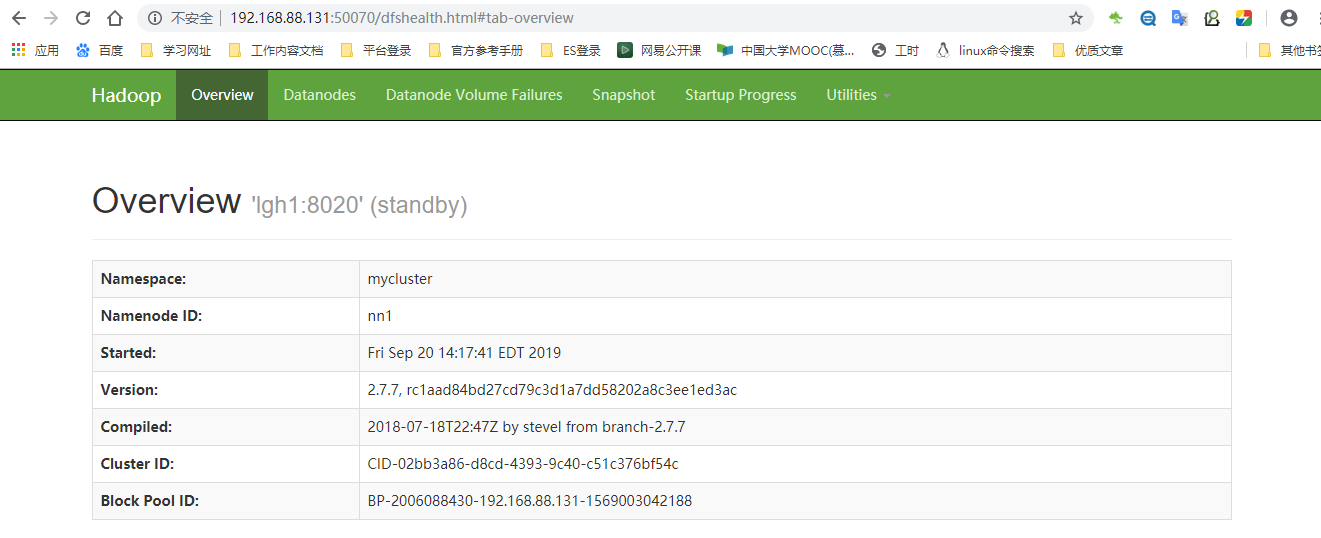
1.2.15、 访问页面(namenode)
192.168.88.131:50070
192.168.88.132:50070
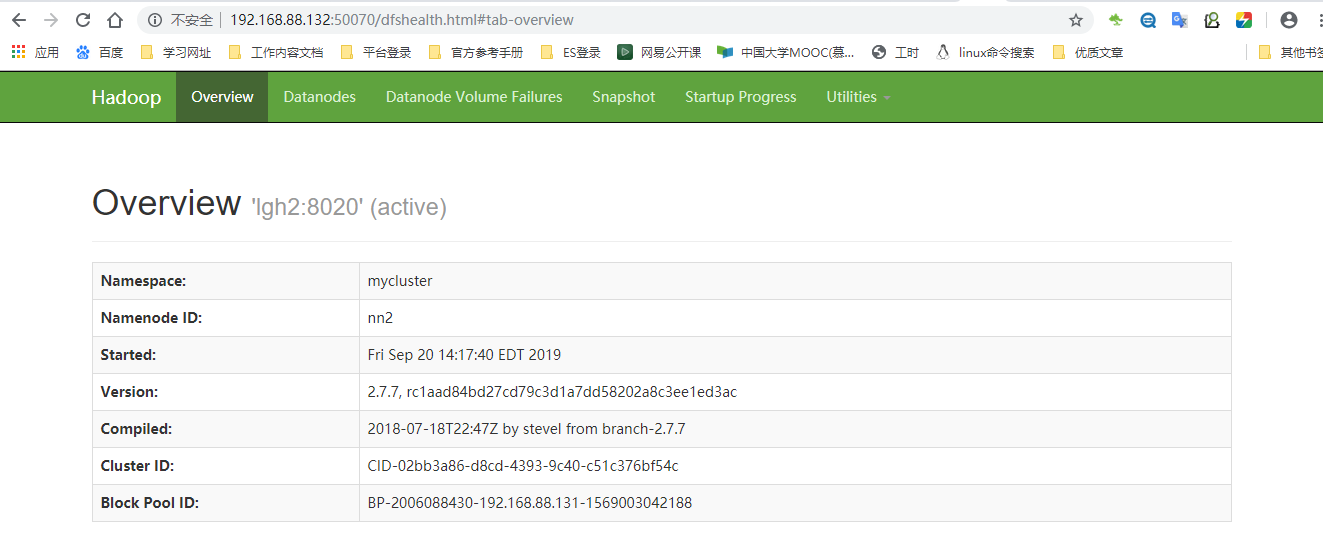
1.2.16、测试namenode故障转移
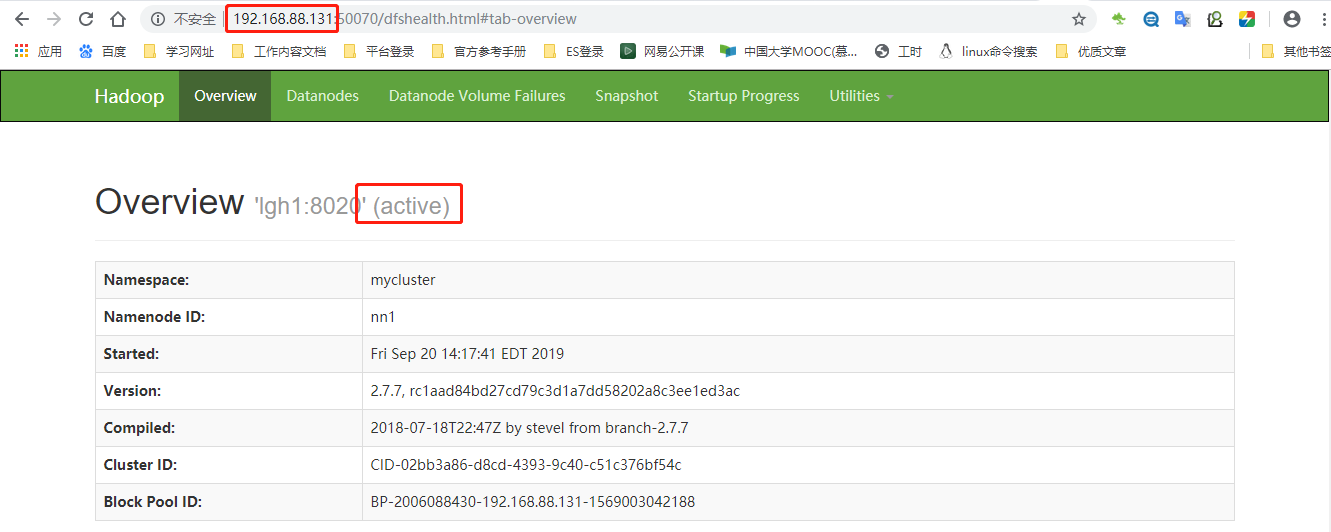
在节点192.168.88.132上执行:
[hadoop@lgh2 ~]$ /opt/hadoop/hadoop/sbin/hadoop-daemon.sh stop namenode

然后我们恢复192.168.88.132的namenode
[hadoop@lgh2 ~]$ /opt/hadoop/hadoop/sbin/hadoop-daemon.sh start namenode

该节点变成了standby节点。说明故障转移成功
1.2.17、查看yarn页面访问
resourcemanager的故障测试:
[hadoop@lgh3 ~]$ /opt/hadoop/hadoop/sbin/yarn-daemon.sh stop resourcemanager #停掉lgh3节点上的resourcemanager
这里不截图了,很成功
到这里hadoop的高可用就安装完毕了(不过笔者这个中踩了不少坑,遇到一些奇葩问题,但是没有记录,总之,删除掉生成的东西,多格式化几次试试)
删除的目录有:
rm -rf /opt/data/hadoop/hdfs/*
rm -rf /opt/data/hadoop/tmp/*
rm -rf /opt/hadoop/hadoop/logs/*
二、基本原理
1、namenode高可用
我们知道namenode是整个hdfs的核心,如果namenode挂了,那么整个hdfs文件系统也不能提供服务,所以hadoop对hdfs提供了高可用的方案,即Hadoop HA,hdfs的高可用提供了两种方案,一种是基于QJM(Quorum Journal Manager)的,一种是基于NFS的,我们用的一般都是基于QJM的,所以这里也是讲基于QJM的高可用,高可用用来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode节点。那么提供多个namenode必定存在新的问题:
1、如何保证NameNode内存中元数据数据一致,并保证编辑日志文件的安全性。
2、多个NameNode如何协作
3、客户端如何能正确地访问到可用的那个NameNode。
4、怎么保证任意时刻只能有一个NameNode处于对外服务状态
针对如上问题,hadoop提供了如下解决方案:
对于保证NameNode元数据的一致性和编辑日志的安全性,采用Zookeeper来存储编辑日志文件。
两个NameNode一个是Active状态的,一个是Standby状态的,一个时间点只能有一个Active状态的 。
NameNode提供服务,两个NameNode上存储的元数据是实时同步的,当Active的NameNode出现问题时,通过Zookeeper实时切换到Standby的NameNode上,并将Standby改为Active状态。
客户端通过连接一个Zookeeper的代理来确定当时哪个NameNode处于服务状态。
我们看一下hdfs高可用的架构图:如下图所示:

HDFS HA架构中有两台NameNode节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。为了使备用节点保持其状态与Active节点同步,两个节点都与一组称为“JournalNodes”(JN)的单独守护进程通信。当Active节点执行任何名称空间修改时,它会将修改记录持久地记录到大多数这些JN中。待机节点能够从JN读取编辑,并且不断观察它们对编辑日志的更改。当备用节点看到编辑时,它会将它们应用到自己的命名空间。如果发生故障转移,Standby将确保在将自身升级为Active状态之前已从JournalNodes读取所有编辑内容。这可确保在发生故障转移之前完全同步命名空间状态。注意:必须至少有3个JournalNode守护进程,因为编辑日志修改必须写入大多数JN。这将允许系统容忍单个机器的故障。您也可以运行3个以上的JournalNodes,但为了实际增加系统可以容忍的失败次数,您应该运行奇数个JN(即3,5,7等)。请注意:当使用N JournalNodes运行时,系统最多可以容忍(N-1)/ 2个故障并继续正常运行。
Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
故障检测 - 集群中的每个NameNode计算机都在ZooKeeper中维护一个持久会话。如果计算机崩溃,ZooKeeper会话将过期,通知其他NameNode应该触发故障转移。Active NameNode选举 - ZooKeeper提供了一种简单的机制,可以将节点专门选为活动节点。如果当前活动的NameNode崩溃,则另一个节点可能在ZooKeeper中采用特殊的独占锁,指示它应该成为下一个活动的。
ZKFailoverController(ZKFC)是一个新组件,它是一个ZooKeeper客户端,它还监视和管理NameNode的状态。运行NameNode的每台机器也运行ZKFC,ZKFC负责:
1、运行状况监视 : ZKFC定期使用运行状况检查命令对其本地NameNode进行ping操作。只要NameNode及时响应健康状态,ZKFC就认为该节点是健康的。如果节点已崩溃,冻结或以其他方式进入不健康状态,则运行状况监视器会将其标记为运行状况不佳。
2、ZooKeeper会话管理 :当本地NameNode运行正常时,ZKFC在ZooKeeper中保持会话打开。如果本地NameNode处于活动状态,它还拥有一个特殊的“锁定”znode。此锁使用ZooKeeper对“短暂”节点的支持; 如果会话过期,将自动删除锁定节点
3、基于ZooKeeper的选举 :如果本地NameNode是健康的,并且ZKFC发现没有其他节点当前持有锁znode,它将自己尝试获取锁。如果成功,那么它“赢得了选举”,并负责运行故障转移以使其本地NameNode处于活动状态。故障转移过程类似于上述手动故障转移:首先,必要时对先前的活动进行隔离,然后本地NameNode转换为活动状态。
元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
2、resourcemanager高可用
首先我们来看一下官方提供的架构图:如图所示:
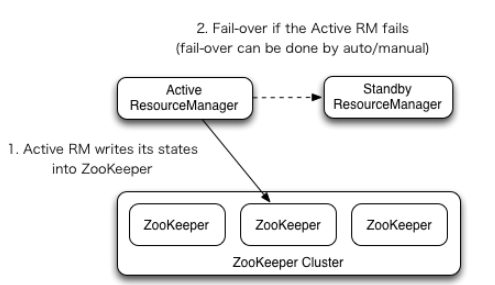
ResourceManager HA通过主动/备用架构实现 - 在任何时间点,其中一个RM处于活动状态,并且一个或多个RM处于待机模式,等待活动RM出现故障或者宕机时机。转换为活动的触发器来自管理员(通过CLI)或启用自动故障转移时的集成故障转移控制器。
RM可以选择嵌入基于Zookeeper的ActiveStandbyElector来决定哪个RM应该是Active。当Active关闭或无响应时,另一个RM自动被选为Active,然后接管。请注意,不需要像HDFS那样运行单独的ZKFC守护程序,因为嵌入在RM中的ActiveStandbyElector充当故障检测器和领导者选择器而不是单独的ZKFC守护程序。
当存在多个RM时,客户端和节点使用的配置(yarn-site.xml)应该列出所有RM。客户端,应用程序管理器ApplicationMaster(AM)和节点管理器NodeManager(NM)尝试以循环方式连接到RM,直到它们到达活动RM。如果活动停止,他们将恢复循环轮询,直到他们连接到新的RM
更多相关文章:hadoop生态系列
参考:
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
出处:https://www.cnblogs.com/zsql/
如果您觉得阅读本文对您有帮助,请点击一下右下方的推荐按钮,您的推荐将是我写作的最大动力!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号