
06.linux CPU负载高,问题排查
1.CPU负载高
主要通过top命令看到 1,5,15 平均负载情况;
通需要查看 虚拟机或者实体机的 cpu核数。
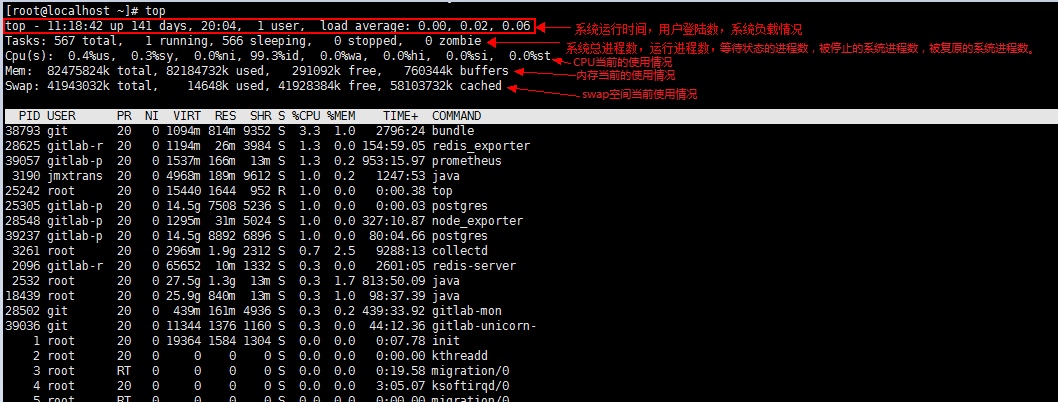
在top命令运行过程中可以通过top的内部命令做显示方式的控制。
- 1- 开启或关闭显示所有cpu使用详细情况
- l - 关闭或开启第一部分第一行 top 信息的表示
- t - 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
- m - 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
- N - 以 PID 的大小的顺序排列表示进程列表(第三部分后述)
- P - 以 CPU 占用率大小的顺序排列进程列表 (第三部分后述)
- M - 以内存占用率大小的顺序排列进程列表 (第三部分后述)
- h - 显示帮助
- n - 设置在进程列表所显示进程的数量
- q - 退出 top
- s - 改变画面更新频率(输入数字)
通过top观察cpu很空闲,但是负载比较高的情况
- load average 是对 CPU 负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。
- 出现此种情况时,可能是由于僵死进程导致的。可以通过指令 ps -axjf 查看是否存在 D 状态进程。
- D 状态是指不可中断的睡眠状态。该状态的进程无法被 kill,也无法自行退出。只能通过恢复其依赖的资源或者重启系统来解决。
2.问题处理过程
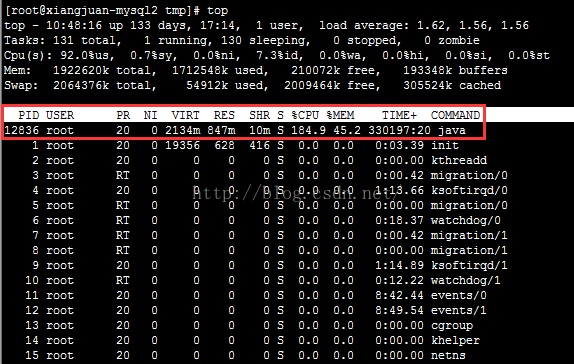
- 使用top命令定位异常进程。可以看见12836的CPU和内存占用率都非常高
![]()
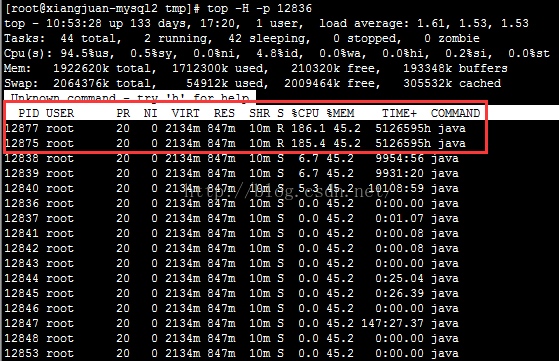
- 使用top -H -p 进程号查看异常线程
![]()
- 使用printf “%x\n” 线程号将异常线程号转化为16进制
![]()
- 使用jstack 进程号|grep 16进制异常线程号 -A90来定位异常代码的位置(最后的-A90是日志行数,也可以输出为文本文件或使用其他数字)。可以看到异常代码的位置。
![]() 找到相应代码检查,发现确实有死循环存在。
找到相应代码检查,发现确实有死循环存在。

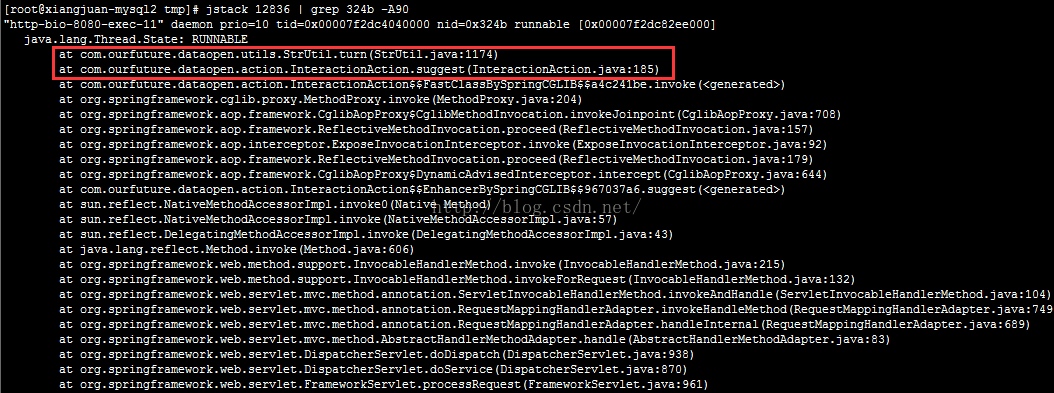 找到相应代码检查,发现确实有死循环存在。
找到相应代码检查,发现确实有死循环存在。3.负载的经验法则
1.0是系统负荷的理想值吗?
- 不一定,系统管理员往往会留一点余地,当这个值达到
0.7,就==应当引起注意==了。经验法则是这样的: - 当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
- 当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
- 当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
对于我的机器,有24个core,那么,load多少合适呢?
[root@lpf]# grep -c 'model name' /proc/cpuinfo
24
答案是:
[root@lpf]# echo "0.7*24" | bc
16.8
最佳观察时长
最后一个问题,”load average” 一共返回三个平均值—-1分钟系统负荷、5分钟系统负荷,15分钟系统负荷,—-应该参考哪个值?
如果只有1分钟的系统负荷大于1.0,其他两个时间段都小于1.0,这表明只是暂时现象,问题不大。
如果15分钟内,平均系统负荷大于1.0(调整 CPU 核心数之后),表明问题持续存在,不是暂时现象。
所以,你应该主要观察”15分钟系统负荷”,将它作为电脑正常运行的指标。
4.造成原因总结
一般java应用cpu过高基本上是因为
- 程序计算比较密集
- IO读写太高
- 程序死循环
- 程序逻请求堵塞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号