Pandas常用数据结构
Pandas 概述
Pandas(Python Data Analysis Library)是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas专用于数据预处理和数据分析的Python第三方库,最适合处理大型结构化表格数据
- Pandas是2008年Wes McKinney于AQR资本做量化分析师时创建
- Pandas借鉴了R的数据结构
- Pandas基于Numpy搭建,支持Numpy中定义的大部分计算
- Pandas含有使数据分析工作更简单高效的高级数据结构和操作工具
- Pandas底层用Cython和C做了速度优化,极大提高了执行效率
Pandas 常用的数据结构有两种:Series 和 DataFrame
Pandas引入约定
from pandas import Series, DataFrame import pandas as pd
Python、Numpy和Pandas对比
Python
- list:Python自带数据类型,主要用一维,功能简单,效率低
- Dict:Python自带数据类型,多维键值对,效率低
Numpy
- ndarray:Numpy基础数据类型,单一数据类型
- 关注数据结构/运算/维度(数据间关系)
Pandas
- Series:1维,类似带索引的1维ndarray
- DataFrame:2维,表格型数据类型,类似带行/列索引的2维ndarray 关注数据与索引的关系(数据实际应用)
从实用性、功能强弱和和可操作性比较:list < ndarray < Series/DataFrame
数据规整和分析工作中,ndarry数组作为必要补充,大部分数据尽量使用Pandas数据类型
Pandas数据结构
Pandas的核心为两大数据结构,数据分析相关所有事物都是围绕着这两种结构进行的
- Series:用于存储一个序列的一维数据
- DataFrame:DataFrame作为更复杂的数据结构,则用于存储多维数据
虽然这些数据结构不能解决所有的问题,但它们为大多数应用提供了有效和强大的工具。就简洁性
而言,他们理解和使用起来都很简单。
Series 简介
Series 是一个带有 名称 和 索引 的 一维数组,在 Series 中包含的数据类型可以是整数、浮点、字符串、Python对象等。
基础属性:
- values:返回元素
- index:返回索引
- columns:返回列名
- dtypes:返回类型
- size:返回元素个数
- ndim:返回维度数
- shape:返回数据形状(行列数目)
Series 创建
1. 简单构建一个含索引和年龄的用户信息
import pandas as pd user_info = pd.Series(data=[24, 45, 33, 62]) user_info # 结果如下
0 24 1 45 2 33 3 62 dtype: int64
2. 将索引自定义为名字,即将年龄与用户联系起来
# 构建索引 # name="user_index":为索引起一个名字 user_index=pd.Index(['Tom','Scott','Jass','Jame'],name="user_index") # 构建Series # name="user_info":为 Series 起个名字 user_info = pd.Series(data=[24, 45, 33, 62],index=user_index,name="user_info",dtype=float) # 结果如下 user_index Tom 24.0 Scott 45.0 Jass 33.0 Jame 62.0 Name: user_info, dtype: float64
Series 访问
Series 包含了 dict 的特点,也就意味着可以使用与 dict 类似的一些操作。我们可以将 index 中的元素看成是 dict 中的 key
# 查看所有的值列表 user_info.values # 查看所有的索引列表 user_info.index # 获取Tom的年龄 user_info['Tom'] # 24.0 # 可以通过 get 方法来获取。通过这种方式的好处是当索引不存在时,不会抛出异常。 user_info['Scott'] # 45.0
Series 除了像 dict 外,也非常像 ndarray,这也就意味着可以采用切片操作
# 获取第一个元素 user_info[0] # 24.0 # 获取前三个元素(左闭右开) user_info[:3] """ user_index Tom 24.0 Scott 45.0 Jass 33.0 Name: user_info, dtype: float64 """ # 获取年龄大于50的元素 user_info[user_info>50] """ user_index Jame 62.0 Name: user_info, dtype: float64 """ # 获取第4个和第二个元素 user_info[[3, 1]] """ user_index Jame 62.0 Scott 45.0 Name: user_info, dtype: float64 """ # 查看去重后的元素 user_info.unique() # 计算不同元素出现的次数 user_info.value_counts() # 判断元素所属关系 s.isin([24,32]) # 将元素中的值取出判断是否出现在指定数组中 s[s.isin([24,32])]
Series 的向量化操作
Series 与 ndarray 一样,也是支持向量化操作的。同时也可以传递给大多数期望 ndarray 的NumPy 方法。
# 将所有人的年龄加1 user_info + 1 """ user_index Tom 25.0 Scott 46.0 Jass 34.0 Jame 63.0 Name: user_info, dtype: float64 """
DataFrame 简介
DataFrame 是一个带有索引的二维数据结构,每列可以有自己的名字,并且可以有不同的数据类型。你可以把它想象成一个 excel 表格或者数据库中的一张表,DataFrame 是最常用的 Pandas 对象。
基础属性:
- values:返回元素
- index:返回索引
- columns:返回列名
- dtypes:返回类型
- size:返回元素个数
- ndim:返回维度数
- shape:返回数据形状(行列数目)
DataFrame 创建
构建方式一:构建一个dict,将dict传递给data参数
data={ "age":[12,23,45,37], "city":["chongqing","nanjing","wuhan","shenyang"] } index = pd.Index(['Tom','Scott','Jass','Jame'],name="user_name") pd.DataFrame(data=data,index=index)
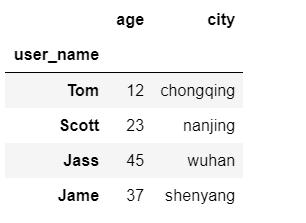
由上表我们可以看到,DataFrame已经成功构建,且索引是用户姓名,另外两列信息分别为用户年龄和城市信息
构建方式二:先构建一个二维数组,然后再生成一个列名称列表。
data=[[12,"shenyang"], [23,"chongqing"], [45,"wuhan"], [37,"nanjing"] ] index = pd.Index(['Tom','Scott','Jass','Jame'],name="user_index") # 标签 column = ["age","city"] user_info = pd.DataFrame(data=data,index=index,columns=column) user_info

DataFrame 访问
访问行 --> 通过索引名 --> loc方法
# 通过索引访问某个人的数据 user_info.loc[['Tom']] # 通过索引访问指定人的数据 user_info.loc[['Tom','Jass']]
访问行 --> 通过行所在位置 --> iloc方法
# 访问第一个人的信息 user_info.iloc[0] # 访问前3个人的信息 user_info.iloc[0:3]
访问列 --> 通过属性(.列名)
user_info.age """ user_index Tom 12 Scott 23 Jass 45 Jame 37 Name: age, dtype: int64 """
访问列 --> 通过[column]
# 获取一列数据 user_info[["age"]] # 获取多列数据 user_info[["age","city"]] """ age city user_index Tom 12 shenyang Scott 23 chongqing Jass 45 wuhan Jame 37 nanjing """
新增列
通过传入一个标量,Pandas 会自动帮我们广播来填充所有的位置
# 添加的信息一致 user_info["sex"]="male" user_info """ age city sex user_index Tom 12 shenyang male Scott 23 chongqing male Jass 45 wuhan male Jame 37 nanjing male """ # 添加的指定信息 user_info["sex"]=["male","female","male","male"] user_info """ age city sex user_index Tom 12 shenyang male Scott 23 chongqing female Jass 45 wuhan male Jame 37 nanjing male """ # 在原有信息上新增一列与原有信息相关数据 user_info.assign(age_add_one = user_info["age"] + 1) """ age city sex age_add_one user_index Tom 12 shenyang male 13 Scott 23 chongqing female 24 Jass 45 wuhan male 46 Jame 37 nanjing male 38 """ import numpy as np user_info.assign(sex_code = np.where(user_info["sex"] == "male", 1, 0)) """ age city sex sex_code user_index Tom 12 shenyang male 1 Scott 23 chongqing female 0 Jass 45 wuhan male 1 Jame 37 nanjing male 1 """
删除列
drop(labels, axis=0, level=None, inplace=False, errors='raise')
参数解释:
- lables:接收string或array。代表删除的行或列的标签。无默认
- axis:接收0或1。代表操作的轴向。默认为0
- levels:接收int或者索引名。代表标签所在级别。默认为None
- inplace:接收boolean。代表操作是否对原数据生效。默认为False
# 删除某一列 user_info.drop(["sex"],axis=1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号