
大模型计算图探究
当我们在说计算图优化的时候,我们在说什么?
各种各样的计算图
计算图
首先是对于“计算图”这个最高层、最抽象、但也相对来说最好理解的概念:一个计算图就是其节点代表数学运算,其边代表输入输出数据的有向无环图。Tensorflow最初设计论文里对其的描述是
In a TensorFlow graph, each vertex represents an atomic unit of computation, and each edge represents the output from or input to a vertex. We refer to the computation at vertices as operations, and the values that flow along edges as tensors.
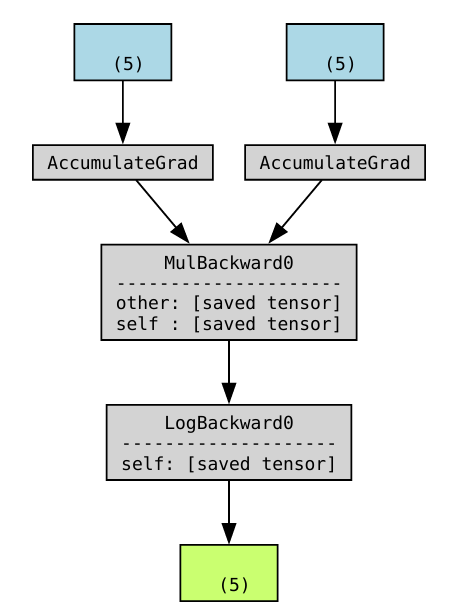
举一个来自Pytorch官方博客的例子,下面的函数代表对输入数据\(x,y\)做数学运算后得到输出结果\(w\),中间经过相乘和对数两个数学运算:
它对应的计算图可以画成这样:
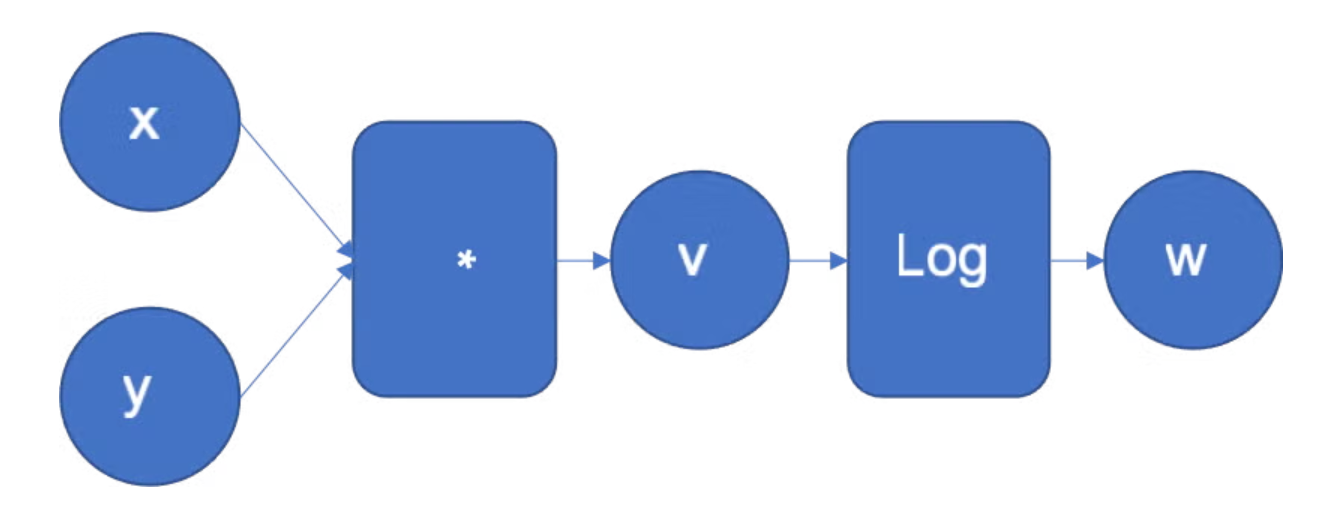
这里的计算图有圆圈和方框,其中圆圈代表在边上流动的张量数据,而方框代表计算图中的操作节点。说实话这样的画法不太好,容易让人以为数据和操作都是计算图里的节点,而边上啥都没有。
下面这个来自OpenMLSys的例子能更好地反映计算图地概念。它表示了\(Z = ReLU(XY)\)这个计算,其中数据\(X,Y,Z\)都画成了Graph里Edge上的方框,代表它是在边上流动的,而两个数学运算MatMul和ReLU则用了常见的圆圈节点:
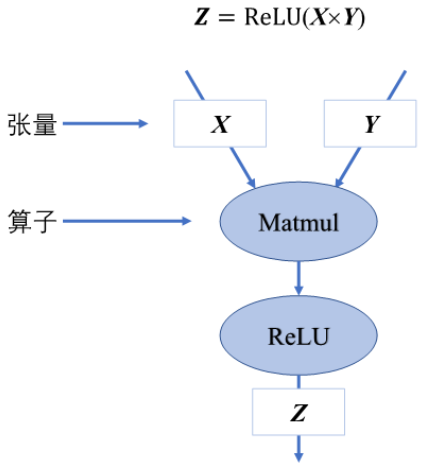
但无论画法怎样,计算图的本质其实是描述了一个计算过程包含哪些数据、哪些操作,以及描述了计算间的依赖关系。只要抓住这个本质,具体怎么画怎么定义就不太重要了。
前向图 vs 反向图
按照表示的内容来分,神经网络领域里的计算图可分为前向图和反向图,前者表示神经网络前向计算的过程,后者表示反向传播计算的过程:
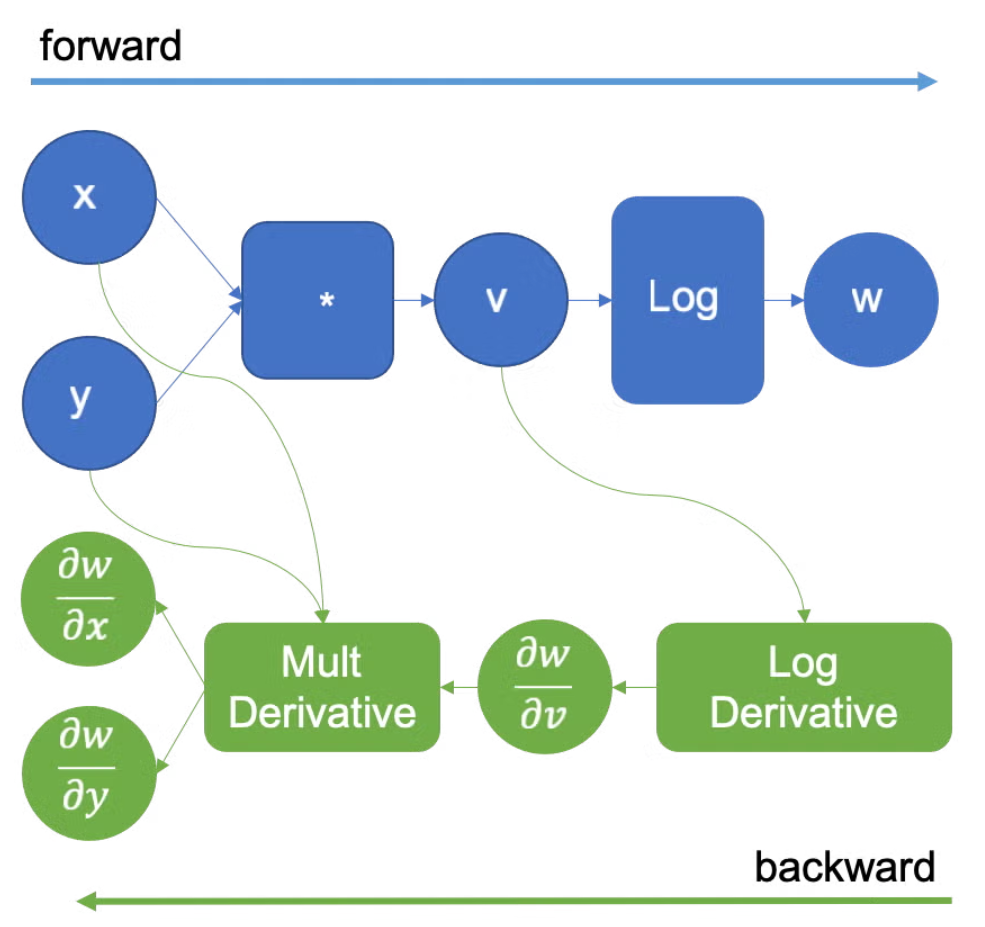
下面是用Tensorflow 1.x的API写的程序,等价于手动组了一张前向计算图:
import numpy as np
import tensorflow as tf
tf.compat.v1.disable_eager_execution() # 进入 TF1 静态图模式
with tf.compat.v1.Graph().as_default(): # 开始构建一张前向计算图
x = tf.compat.v1.placeholder(dtype=tf.float32, shape=[None], name='x')
y = tf.compat.v1.placeholder(dtype=tf.float32, shape=[None], name='y')
with tf.compat.v1.variable_scope('MyTFModel'):
prod = tf.multiply(x, y)
w = tf.math.log(prod, name='w')
# 创建 Session, 用Tensorboard把计算图可视化画出来,但不需要用数据跑一边计算过程
# `tensorboard --logdir=./logs`
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
writer = tf.compat.v1.summary.FileWriter('./logs/my_tf_model', sess.graph)
writer.close()
上面的例子只演示了Tensorflow构建前向图,没有演示反向图。Tensorflow可以根据前向图自动构建反向图,不过需要定义可训练变量,构造标量损失loss,然后调用 tf.train.GradientDescentOptimizer来生成。例如:
with tf.compat.v1.Graph().as_default():
# ...前向图定义...
trainable = tf.compat.v1.get_variable("a", shape=[], initializer=tf.ones_initializer())
loss = tf.reduce_mean(trainable * w, name="loss")
optim = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.1)
train_op = optim.minimize(loss, name="train_op") # 反向图
与Tensorflow不同,Pytorch前向推理不生成前向图,而是一条条代码分析,一个个操作立即执行的。不过在Pytorch做前向计算的过程中会构建一张反向图。当我们跑一次y = model(X)的时候,生成的所有中间张量都会被保存在内存里,作为这张反向图的一个节点。更具体来说,每个张量的grad_fn才是这张反向图的节点,每个grad_fn都是torch.autograd.graph中的一个Node。每个张量的grad_fn还有一个指针列表,指向它下一步反向传播的计算操作,这些指针就是反向图里的Edge。
import torch # 2.8.0
from torchviz import make_dot
class MyModel(torch.nn.Module):
def forward(self, x, y):
return torch.log(x * y)
# 必须用数据跑一遍前向推里才能看到计算图,这一点就跟Tensorflow不一样
model = MyModel()
x = torch.rand(5, requires_grad=True)
y = torch.rand(5, requires_grad=True)
w = model(x, y)
dot = make_dot(w, params=dict(model.named_parameters()), show_attrs=True)
dot.render('mymodel', format='png')
调用了输出张量的.backward()方法后,pytorch会自动计算整个反向图里所有节点的梯度,然后销毁这张图,在有新的前向计算被执行时在开始构建一种新的反向图。Pytoch这种在执行计算的过程中才组建的计算图被称为动态图,而相应的Tensorflow那种在执行计算前就把全部构建好的计算图被称为静态图。
动态图 vs 静态图
动态图和静态图之间的练习很大程度上可以用动态语言和静态语言来类比。无论动态语言还是静态语言,它们都能实现基本功能,毕竟都是Turing-Complete的,不同的地方更多在于体验和速度:像C这样的静态都需要先编译后运行。每次做修改后都得重新编译才能再运行,所以调试起来会比较繁琐。不过静态语言的型能更强,在编译过程中编译器还可以做一些代码逻辑优化,而且提供更多编译检测,让bug在提前在编译时暴露而非拖延到运行时。Python这类的动态语言型能不及静态语言,但就是写起来爽,调试也方便。所以在变成项目中,往往会用Python这样的动态语言快速开发出满足基础功能的原型,验证过以后再基于C这样的静态语言重写项目,以更高的性能和安全性上线。
基本上,静态图和动态图的却别也就这些。动态图边执行边构建、方便开发、方便调试,但是型能低。静态图先把整个图编译完后再调用一个静态图运行时来执行,写起来繁琐,调试更不方便,但是型能比动态图高。
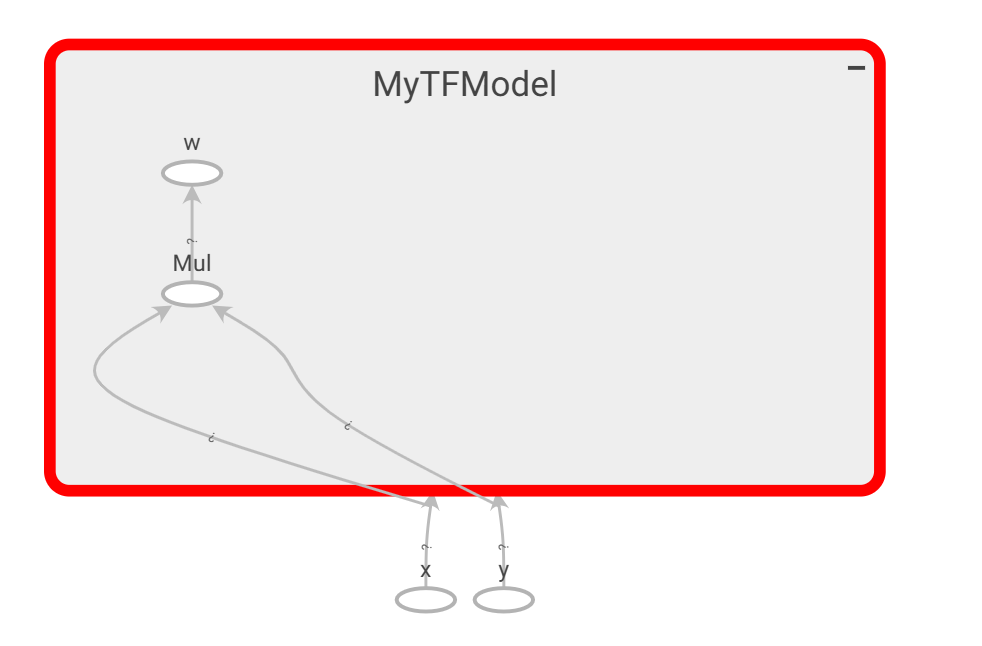
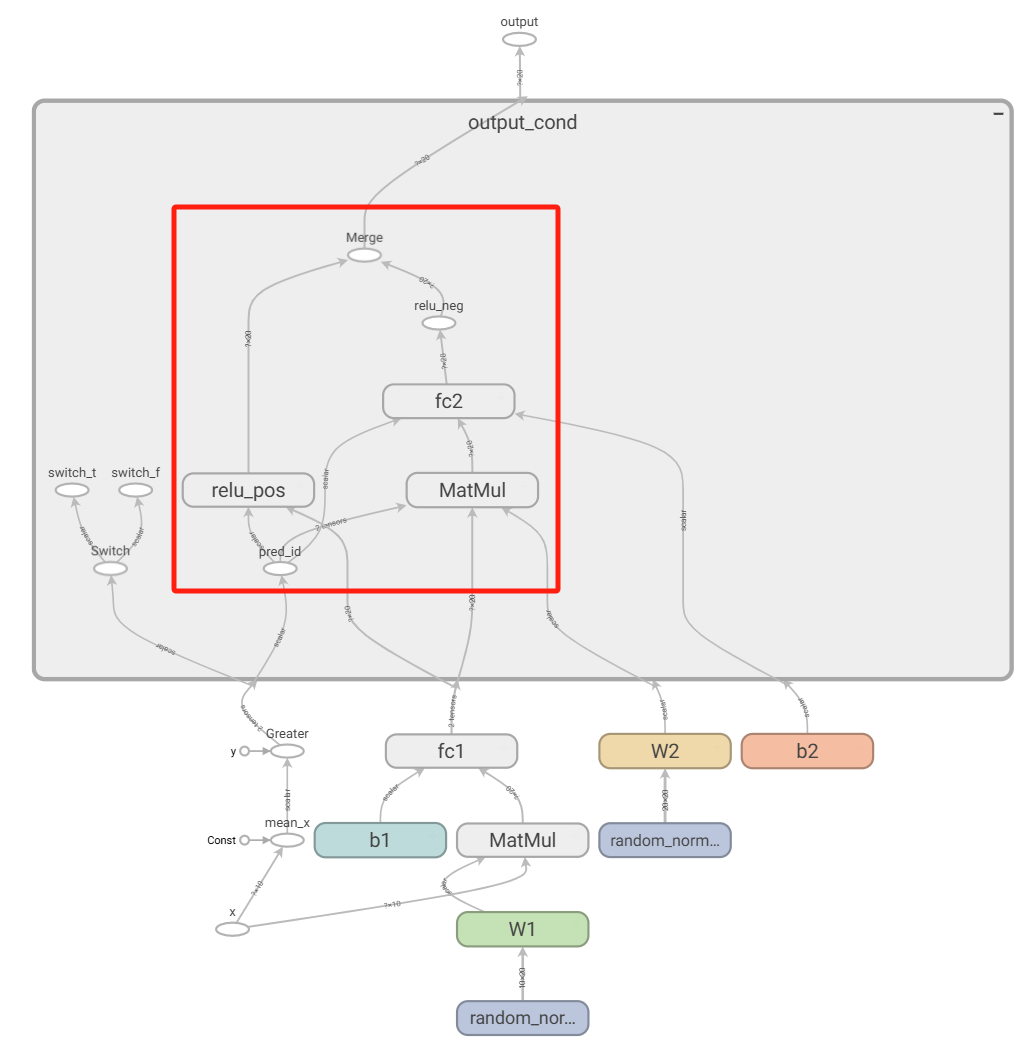
静态图和动态图之间最明显的差别,可能就在于条件控制流。对于静态图来说,条件分支也是一个操作节点,意味着在图里有一个条件控制节点并分支开两个子图,如果条件判断为true,执行其中一个子图,反之执行另一个子图。而且在编程时,条件控制流不能使用python的if..else..语法,得用框架提供的接口。对于Tensorflow来说,就是tf.cond。下面Tensorflow例子中红色方框框住的部分就是静态图里的分支子图。
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
tf.compat.v1.disable_control_flow_v2()
graph = tf.Graph()
with graph.as_default():
x = tf.compat.v1.placeholder(tf.float32, [None, 10], name='x')
W1 = tf.Variable(tf.random.normal([10, 20]), name='W1')
b1 = tf.Variable(tf.zeros([20]), name='b1')
W2 = tf.Variable(tf.random.normal([20, 20]), name='W2')
b2 = tf.Variable(tf.zeros([20]), name='b2')
fc1 = tf.nn.bias_add(tf.matmul(x, W1), b1, name='fc1')
mean_x = tf.reduce_mean(x, name='mean_x')
# tf.print("mean(x) =", mean_x, output_stream='file://stdout')
def branch_pos():
return tf.nn.relu(fc1, name='relu_pos')
def branch_neg():
fc2 = tf.nn.bias_add(tf.matmul(fc1, W2), b2, name='fc2')
return tf.nn.relu(fc2, name='relu_neg')
output = tf.compat.v1.cond(mean_x > 0, branch_pos, branch_neg, name='output')
# ----- 把 GraphDef 直接写进 event 文件 -----
logdir = './logs/tf_cond_graph'
writer = tf.compat.v1.summary.FileWriter(logdir, graph=graph)
但对于动态图而言,除了上述的图内控制流,还可以有图外控制流。因为动态图是边执行边组图,所以它可以只构建被执行到的子图。最后的效果是整张动态前想图里没有条件分支节点,也没有分支开来的子图,只有每次执行计算后不断生成又不断销毁的不同的计算图。
class MyCondModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(10, 20)
self.fc2 = torch.nn.Linear(20, 20)
self.relu = torch.nn.ReLU()
def forward(self, x):
print(x.mean())
if x.mean() > 0:
return self.relu(self.fc1(x))
else:
return self.relu(self.fc2(self.fc1(x)))
def view_graph(model, x, pic_name='backward_graph', format='pdf'):
y = model(x)
dot = make_dot(y, params=dict(model.named_parameters()), show_attrs=True)
dot.render(pic_name, format=format)
model = MyCondModel()
x1 = torch.ones([2, 10])
x2 = -1 * torch.ones([2, 10])
view_graph(model, x1, "backward_graph1")
view_graph(model, x2, "backward_graph2")
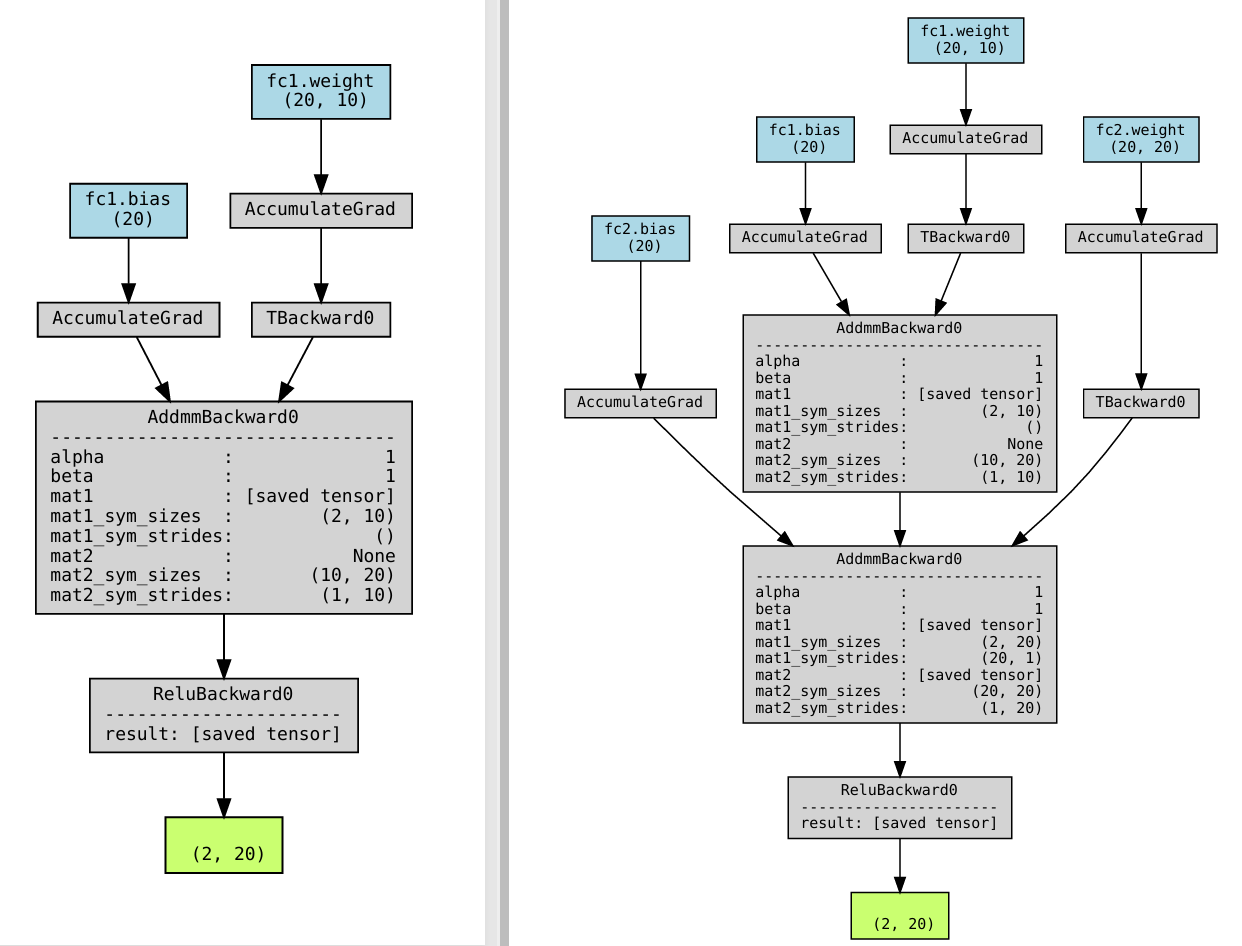
下面的两张反向图就是两次计算过程分别生成的两张不同的计算图。
但是,静态和动态两者也不是那么泾渭分明,都有在互相吸收对方的有点。比如Python就引入了有JIT(Just-In-Time,即时编译),把部分代码先编译,如果下次在执行这些代码就直接跑编译后的代码。而像Java这样的静态语言也有了JShell这样的REPL(Read-Eval-Print Loop,交互编程环境)。同理,Tensorflow现在默认的就是动态图的API,想手动组静态图还得用tf.compat.v1这样的方式。而Pytorch也在探索各种各样的JIT方式把动态图编译成静态图,比如说torch.jit.trace就是跟踪模型的一次前向推理,记录下所有计算操作以及它们之间的依赖,从而自动组建一张静态图。这种方法的问题是当torch模型种有图外控制流的时候,由于部分子图不会在前向推理时被出发,所以不会被记录到。而torch.jit.script就是分析模型的源码,然后编译出一张静态图来。虽然分析源码的方法能一次过编译出一张完整的子图,但python语法和静态图语法毕竟不能完全对应,所以不发排除一部分源码没办法被编译的情况。下面的例子就把上述MyCondModel的图外控制流编译成图内控制流,block0()和block1()两个子块对应静态图里的两个子图。
>>> model = MyCondModel()
>>> scripted_model = torch.jit.script(model)
>>> print(scripted_model.graph)
graph(%self : __torch__.MyCondModel,
%x.1 : Tensor):
%3 : NoneType = prim::Constant()
%8 : int = prim::Constant[value=0]() # <ipython-input-2-d53abd0b52c7>:10:22
%4 : Tensor = aten::mean(%x.1, %3) # <ipython-input-2-d53abd0b52c7>:9:14
= prim::Print(%4) # <ipython-input-2-d53abd0b52c7>:9:8
%7 : Tensor = aten::mean(%x.1, %3) # <ipython-input-2-d53abd0b52c7>:10:11
%9 : Tensor = aten::gt(%7, %8) # <ipython-input-2-d53abd0b52c7>:10:11
%11 : bool = aten::Bool(%9) # <ipython-input-2-d53abd0b52c7>:10:11
%32 : Tensor = prim::If(%11) # <ipython-input-2-d53abd0b52c7>:10:8
block0():
%relu.1 : __torch__.torch.nn.modules.activation.ReLU = prim::GetAttr[name="relu"](%self)
%fc1.1 : __torch__.torch.nn.modules.linear.Linear = prim::GetAttr[name="fc1"](%self)
%15 : Tensor = prim::CallMethod[name="forward"](%fc1.1, %x.1) # <ipython-input-2-d53abd0b52c7>:11:29
%16 : Tensor = prim::CallMethod[name="forward"](%relu.1, %15) # <ipython-input-2-d53abd0b52c7>:11:19
-> (%16)
block1():
%relu : __torch__.torch.nn.modules.activation.ReLU = prim::GetAttr[name="relu"](%self)
%fc2 : __torch__.torch.nn.modules.linear.___torch_mangle_0.Linear = prim::GetAttr[name="fc2"](%self)
%fc1 : __torch__.torch.nn.modules.linear.Linear = prim::GetAttr[name="fc1"](%self)
%21 : Tensor = prim::CallMethod[name="forward"](%fc1, %x.1) # <ipython-input-2-d53abd0b52c7>:13:38
%22 : Tensor = prim::CallMethod[name="forward"](%fc2, %21) # <ipython-input-2-d53abd0b52c7>:13:29
%23 : Tensor = prim::CallMethod[name="forward"](%relu, %22) # <ipython-input-2-d53abd0b52c7>:13:19
-> (%23)
return (%32)
Pytorch 2.x的官方推荐JIT方法torch.compile用的是基于记录的方法——如果一次记录补全,那么下次出发新的计算分支时就回退到python解释器,并记录下新的子图部分,以待下次使用。
CUDA Graph
我们还会再做推理加速的时候时常听到CUDA Graph的概念,在Nvidia的官方介绍博客我们也能看到煞有介事地摆放了一张有向无环图。但严格来说,它与我们之前提到地Tensorflow和Pytorch那种计算图不是一个东西。反向图用来自动求解微分,前想吐用于直接部署和做数学计算层面的优化。而CUDA Graph是一种更底层的图,它把要进行的CUDA Kernel调用按顺序记录起来,然后下次直接重放。如此一来可以减少CPU-GPU之间的调度开销,以达到加速神经网络计算的目的。
CUDA Graphs have been designed to allow work to be defined as graphs rather than single operations. They address the above issue by providing a mechanism to launch multiple GPU operations through a single CPU operation, and hence reduce overheads.
CUDA Graph 的确以“图”的形式表达依赖,但它更像是一种“批量 CUDA 调度对象”而不是深度学习常说的高阶“计算图”。如果我们关心的是算法层面的算子优化与自动求导,要用 TensorFlow/PyTorch 等的计算图;如果我们已经拿到编译好的 kernel,想把百万次 kernel 启动压到十几次 CPU 调用,就用 CUDA Graph。
ONNX Graph
那么ONNX Graph呢?ONNX是一种开放的神经网络格式(Open Neural Network eXchange),提供了一种静态图的导出格式,允许在某个框架下训练出来的模型导出并迁移到另一个训练框架或者推理框架。所以说,ONNX Graph也是一种前向计算图。但为什么需要这么一个中转格式呢?这就要深入到计算图里具体的节点了。我们知道计算图中的节点代表一种对数据的操作,而每一个训练框架(Tensorflow、Pytorch、Mindspore、Scikit-Learn)和每一个推理框架(TensorRT、vllm、Mindspore Lite)都有自己的一套基本操作集合。不同框架之间的操作其实都大同小异,比如名字可能不同但做的具体操作是一样的。但这些“小异”终究是阻碍了模型在框架间的迁移。ONNX就是为了解决这个问题,它尽可能定义了一套标准的操作集合,因此所有框架都可以锚定这套ONNX的操作集合,先抓换成ONNX模型,然后再从ONNX模型转换成其他框架的模型。从这个角度看,ONNX也是一种中间表示了。
如果我们再Huggingface或者哪里看到了一个模型model.onnx,那么这个模型文件里就包含了一个神经网络的完整权重参数以及网络结构(静态图)。相应的,model.safetensors只有神经网络的权重参数,没有网络结构。因此,要使用safetensors文件,还必须搭配相应的模型定义文件modeling.py。在训练框架里,Tensorflow的tf.saved_model.save()导出的也是一种静态图文件。而Pytorch的平常官方推荐的模型保存方式torch.save(model.state_dict(), 'model.pt')其实也像safetensors一样只保存了模型的权重参数,但之间用torch.jit.trace编译出来的静态图模型用torch.jit.save(script_model.pt)保存的模型则是静态图,可以直接用torch.jit.load(script_model.pt)来导入,无需额外的模型定义文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号