用ELK分析每天4亿多条腾讯云MySQL审计日志(2)--EQL
上一篇介绍了用ELK分析4亿多条审计日志过程,现在介绍如何用Python3分析ES的程序
需要分析的核心库审计数据:
1,950多张表,几十个账号,
2,5种操作类型(select,update,insert,delete,replace),14个实例(1主13从库)
分析说明:
select汇总: 必须包含from关键字:排除INSERT INTO 表 SELECT '609818','1' 这样情况
insert汇总: 必须有into关键字: 排除select中有insert关键字
update汇总: 不包含for 关键字: 排查 for update 的select查询
delete汇总: 不包含into 关键字: 排除insert等内容里包含delete的数据情况
replace汇总: 必须有into 关键字: 排除select查询中有replace函数
分析方法:
为保证把以上数据都能分析出来, 将950多张表,存放到数据表中,循环950多次表,每个表循环5次类型:
sql="select id,name,ea_time from tab order by id desc --查询全部表
dml={'select','update','insert','delete','replace'} --每个表循环5次类型
后来研发发现,分析程序表ol_list统计,但"库名.表",如line.ol_list,不会统计出来。后来修改EQL解决,具体代码如下:
下列是“”select“查询EQL的代码:


if op.find('select')>=0: # select,包含from body ={"query":{ "bool":{ "must":[{ "match":{"Sql":'{op}'.format(op=op) }},{ "match":{"Sql": 'from'}}], "should": [{ "term": {"Sql": '{name}'.format(name=tabname)}}, { "term": {"Sql": 'online.{name}'.format(name=tabname)}}], "minimum_should_match": 1, "filter":{ "range":{ "Timestamp.keyword":{ "lte": "{date}".format(date=end_time), "gte": "{begindate}".format(begindate=begin_time), } } }}}, "size":0, "aggs":{ "aggr_mame":{ "terms":{ "field":"User.keyword", "size":2000 }, "aggs":{ "aggr_der":{ "terms":{ "field":"PolicyName.keyword" }, "aggs":{ "top_tag_hits":{ "top_hits":{ "size":1 } } }}}}} }
说明:
1,使用:"minimum_should_match": 1, ,这个是兼容: "表名","库名.表名“
5种类型的全部EQL:
if op.find('select')>=0: # select,包含from body ={"query":{ "bool":{ "must":[{ "match":{"Sql":'{op}'.format(op=op) }},{ "match":{"Sql": 'from'}}], "should": [{ "term": {"Sql": '{name}'.format(name=tabname)}}, { "term": {"Sql": 'online.{name}'.format(name=tabname)}}], "minimum_should_match": 1, "filter":{ "range":{ "Timestamp.keyword":{ "lte": "{date}".format(date=end_time), "gte": "{begindate}".format(begindate=begin_time), } } }}}, "size":0, "aggs":{ "aggr_mame":{ "terms":{ "field":"User.keyword", "size":2000 }, "aggs":{ "aggr_der":{ "terms":{ "field":"PolicyName.keyword" }, "aggs":{ "top_tag_hits":{ "top_hits":{ "size":1 } } }}}}} } elif op.find('update')>=0: # update 不能有for关键字 body = {"query": { "bool": {"must": [{ "match": {"Sql": '{op}'.format(op=op)}},{ "match": {"PolicyName.keyword": 'd8t'}}], "must_not": [{"match": {"Sql": "for"}}], "should": [{ "term": {"Sql": '{name}'.format(name=tabname)}}, { "term": {"Sql": 'online.{name}'.format(name=tabname)}}], "minimum_should_match": 1, "filter": { "range": { "Timestamp.keyword": { "lte": "{date}".format(date=end_time), "gte": "{begindate}".format(begindate=begin_time), } }}}}, "size": 0, "aggs": {"aggr_mame": { "terms": { "field": "User.keyword", "size": 2000 }, "aggs": { "aggr_der": { "terms": { "field": "PolicyName.keyword" }, "aggs": { "top_tag_hits": { "top_hits": { "size": 1 } }}}}}} } elif op.find('replace') >= 0: # replace 必须有into关键字 body = {"query": { "bool": {"must": [{ "match": {"Sql": '{op}'.format(op=op)}}, { "match": {"PolicyName.keyword": 'd8t'}},{ "match": {"Sql": 'into'}}], "should": [{ "term": {"Sql": '{name}'.format(name=tabname)}}, { "term": {"Sql": 'online.{name}'.format(name=tabname)}}], "minimum_should_match": 1, "filter": { "range": { "Timestamp.keyword": { "lte": "{date}".format(date=end_time), "gte": "{begindate}".format(begindate=begin_time), } }}}}, "size": 0, "aggs": {"aggr_mame": { "terms": { "field": "User.keyword", "size": 2000 }, "aggs": { "aggr_der": { "terms": { "field": "PolicyName.keyword" }, "aggs": { "top_tag_hits": { "top_hits": { "size": 1 } }}}}}} } elif op.find('insert') >= 0: # insert 必须有into关键字 body = {"query": { "bool": {"must": [{ "match": {"Sql": '{op}'.format(op=op)}}, { "match": {"PolicyName.keyword": 'd8t'}},{ "match": {"Sql": 'into'}}], "should": [{ "term": {"Sql": '{name}'.format(name=tabname)}}, { "term": {"Sql": 'online.{name}'.format(name=tabname)}}], "minimum_should_match":1, "filter": { "range": { "Timestamp.keyword": { "lte": "{date}".format(date=end_time), "gte": "{begindate}".format(begindate=begin_time), } }}}}, "size": 0, "aggs": {"aggr_mame": { "terms": { "field": "User.keyword", "size": 2000 }, "aggs": { "aggr_der": { "terms": { "field": "PolicyName.keyword" }, "aggs": { "top_tag_hits": { "top_hits": { "size": 1 } }}}}}} } else: # delete 不能有into关键字 body = {"query": { "bool": {"must": [{ "match": {"Sql": '{op}'.format(op=op)}},{ "match": {"PolicyName.keyword": 'd8t'}}], "must_not": [{"match": {"Sql": "into"}}], "should": [{ "term": {"Sql": '{name}'.format(name=tabname)}}, { "term": {"Sql": 'online.{name}'.format(name=tabname)}}], "minimum_should_match": 1, "filter": { "range": { "Timestamp.keyword": { "lte": "{date}".format(date=end_time), "gte": "{begindate}".format(begindate=begin_time), } }}}}, "size": 0, "aggs": {"aggr_mame": { "terms": { "field": "User.keyword", "size": 2000 }, "aggs": { "aggr_der": { "terms": { "field": "PolicyName.keyword" }, "aggs": { "top_tag_hits": { "top_hits": { "size": 1 } }}}}}} }
写入统计数据Py:
doc = res["aggregations"]["aggr_mame"]['buckets'] cn = conn() cur = cn.cursor() if len(doc): for item in doc: user=item['key'] # 账号 total=str(item['doc_count']) # 该账号在全部实例下的调用次数 if len(item["aggr_der"]["buckets"]): for bucket in item["aggr_der"]["buckets"]: server=bucket['key'] # 服务器实例 s_total =str(bucket['doc_count']) # 该服务器实例下的调用次数 sql=bucket["top_tag_hits"]["hits"]["hits"][0]["_source"]["Sql"] # 样例Sql sql=emoji.demojize(transferContent(sql)) #转义并去掉表情符号 tsql="replace into ea_tj(tab,username,op,num,server,sqltext,dt) "\ " values ('{0}','{1}','{2}','{3}','{4}','{5}','{6}')".format(tabname,user,op,s_total,server,sql,dt) cur.execute(tsql) cn.commit()
存放分析结果表:
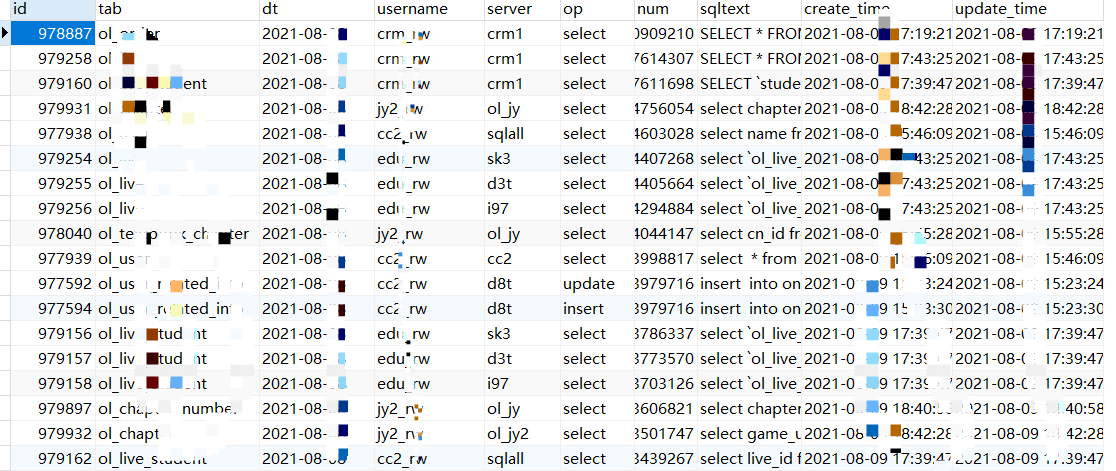
CREATE TABLE `ea_tj` ( `id` int(11) NOT NULL AUTO_INCREMENT, `tab` varchar(200) NOT NULL COMMENT '表名', `username` varchar(200) NOT NULL COMMENT '账号', `op` varchar(50) DEFAULT NULL COMMENT '操作类型', `num` bigint(11) NOT NULL COMMENT '次数', `server` varchar(200) NOT NULL COMMENT '实例策略名', `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `sqltext` text COMMENT '样例SQL', `dt` date DEFAULT NULL COMMENT '线上SQL执行日期', `update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `un` (`tab`,`username`,`op`,`server`,`dt`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4
具体汇总数据:
1,每天13个实例,表,账号,操作之间关系汇总(用来Online表拆分)
2,每天13个数据库实例账号的连接IP汇总(用来迁移VPC)
3,统计调用总次数 (用来分析调用次数异常)
汇总1的结果数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号