
记一次flink任务因sink表被锁住而引发的flink雪崩问题
问题现象
前段线上用户频繁反馈,flink任务运行一段时间就失败了。然后查看flink UI管理界面,发现整个taskmanager都挂了
问题分析
收集了用户flink日志,主要是taskmanager日志
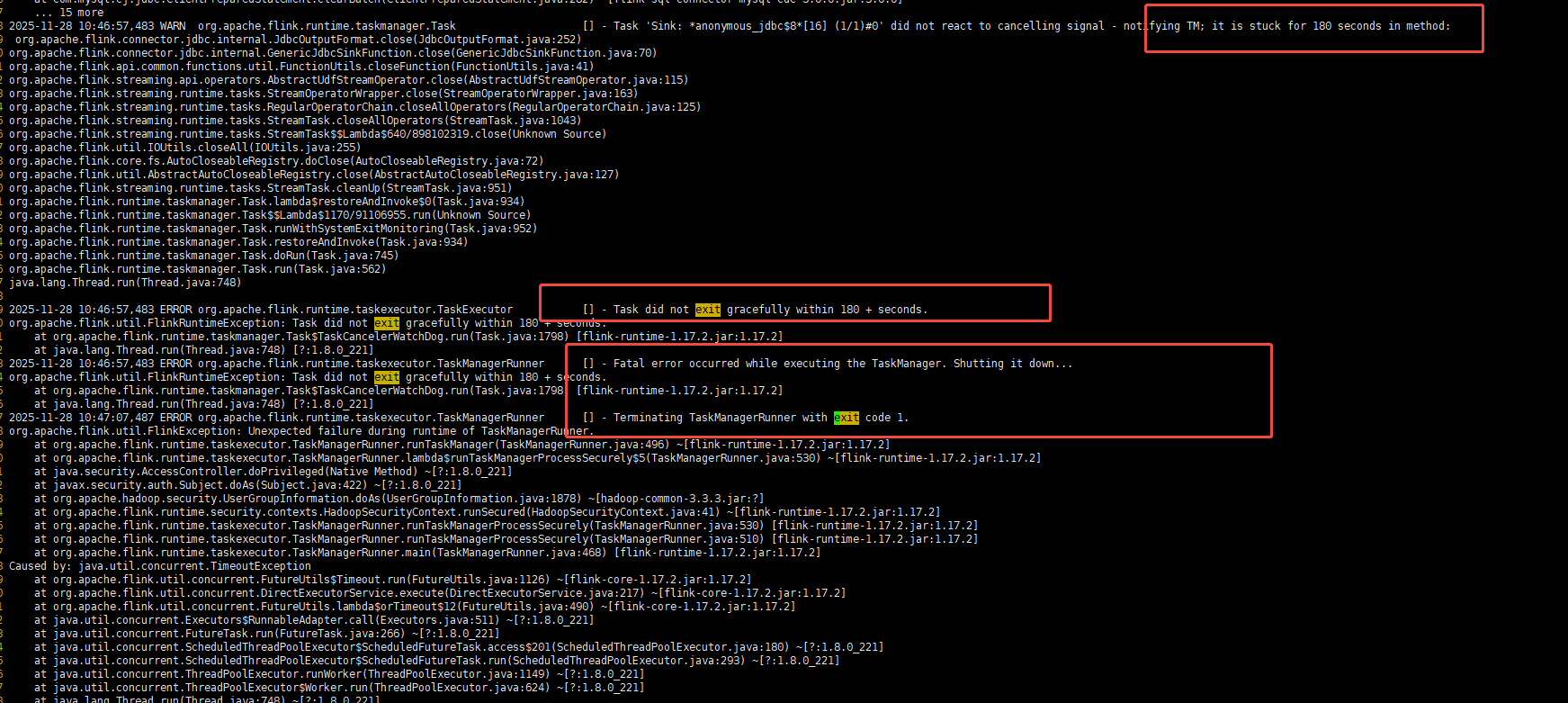
发现非内存因素OOM的,而是自主退出的。
关键因素由于取消任务超时180s引起的,taskmanager误判服务异常,自主退出
接着跟踪日志,找到经过多次重试,尝试恢复任务的地方
第一次重试

第二次重试,刚好间隔60s

总共重试3次了。超过180s
taskmanager打印退出日志
排查到根因是因为mysql业务操作引起的sink表被锁住导致无法写入。
接着排查60s时间,询问客户发现配置的数据源的socketTimeout为60s,对于实时场景,该超时时间过大了。
解决方案
业务层面,告知用户flink实时任务,尽量保证链路的纯粹,不要因为类似操作影响实时性。
flink层面:默认180s取消任务超时时间适当调大一些,task.cancellation.timeout
数据源层面: socket超时时间,不要过长,不然容易引起任务线程IO阻塞等待过大,无法及时响应一些内部状态变更,从而引发雪崩。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号