linux内核追踪——find_next_bit函数详详详解
写在前面
宗旨:把话说清楚,把道理讲透彻。
约定:所有代码均来自Linux内核2.6.24版。
建议:本文介绍得十分详细,但也略显繁琐,读者可以先看“Ⅴ.总结”部分带注释的源码,如果哪里不清楚,再回头看详细解释。
正文
预备知识
位图:
在Linux下,从数据结构上看,位图本质上是一个数组,数组的每个元素都是long型的(即32bit或64bit)。
假设在32位系统下,某long型数组有128个元素,那么,从逻辑上看,这个数组就是一个128行×32列的bit阵列,就是所谓的位图,见下面的示意图。
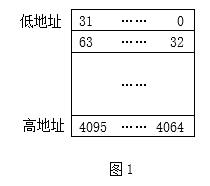
上图中的数字就是各个bit位的标号,即索引。
对于位图的操作,也就是对位图中bit位的操作。
从作用上说,位图通常与其它数据相关联,用位图中的bit位对该数据进行统计或管理。
例如,在文件系统中,每个进程都有一个元素为file指针的数组(为表述方便,后面称之为数组A),同时,也有一个位图,位图中有效bit位(何为有效bit位,后面会详述)的个数与数组A中元素的个数相同。当进程打开一个文件时,要先在位图中找一个为0的bit位,然后将该位置1,返回该bit位的索引fd。当内核创建了与要打开文件对应的file实例后,会使数组A中索引为fd的元素(注意,前边说过,该元素是一个file类型的指针)指向该file实例。这里的索引fd,就是我们平常所说的文件描述符。
正题
Ⅰ.源码
先给出find_next_bit的源码(源码来自内核2.6.24,位置:/lib/find_next_bit.c)
1 unsigned long find_next_bit(const unsigned long *addr, unsigned long size, 2 unsigned long offset) 3 { 4 const unsigned long *p = addr + BITOP_WORD(offset); 5 unsigned long result = offset & ~(BITS_PER_LONG-1); 6 unsigned long tmp; 7 8 if (offset >= size) 9 return size; 10 size -= result; 11 offset %= BITS_PER_LONG; 12 if (offset) { 13 tmp = *(p++); 14 tmp &= (~0UL << offset); 15 if (size < BITS_PER_LONG) 16 goto found_first; 17 if (tmp) 18 goto found_middle; 19 size -= BITS_PER_LONG; 20 result += BITS_PER_LONG; 21 } 22 while (size & ~(BITS_PER_LONG-1)) { 23 if ((tmp = *(p++))) 24 goto found_middle; 25 result += BITS_PER_LONG; 26 size -= BITS_PER_LONG; 27 } 28 if (!size) 29 return result; 30 tmp = *p; 31 32 found_first: 33 tmp &= (~0UL >> (BITS_PER_LONG - size)); 34 if (tmp == 0UL) 35 return result + size; 36 found_middle: 37 return result + __ffs(tmp); 38 }
Ⅱ.功能——参数——返回值
功能:在addr指向的位图中,从索引为offset的bit位(包括该位)开始,找到第一个为1的bit位,返回该位的索引。
参数:
@addr:位图(数组)的起始地址。
@size:位图的大小,即位图中有效bit位的个数。注意,Linux内核实际调用该函数时,该参数的值不一定是32的整数倍(32位系统下)。假设构成位图的数组大小为3,即一共有96个bit,但函数调用时,参数size可 能是90,那么,从逻辑上说,数组最后一个元素的最后6位是不参与构成位图的,即它们不是位图的组成部分,是“无效”的;而前边的90个bit共同构成了位图,它们是“有效”的。注意,后面解释中经常会用 到“有效位”和“无效位”的概念,对此,读者一定要理解清楚。
@offset:查找起点。即从位图中索引为offset的位(包括该位)开始,查找第一个为1的bit位,offset之前的bit位不在搜索范围之内。“查找起点”这个概念在后面的叙述中经常会用到,希望读者能理解清楚。
返回值:找到的bit位的索引。
Ⅲ.BITS_PER_LONG和BITOP_WORD
3.1 BITS_PER_LONG
顾名思义,BITS_PER_LONG是指一个long型数据中bit位的个数,看源码
/*include/asm-x86/types.h*/ #ifdef CONFIG_X86_32 # define BITS_PER_LONG 32 #else # define BITS_PER_LONG 64 #endif
可见,32位系统下,它是32;64位系统下,它是64。
3.2 BITOP_WORD
不多说,直接看源码
/*lib/find_next_bit.c*/ #define BITOP_WORD(nr) ((nr) / BITS_PER_LONG)
就是参数nr除以32或64。
Ⅳ.一句一句解释
注:在后面的所有解释中,我们按32位系统讲解,即BITS_PER_LONG取32。
a.
const unsigned long *p = addr + BITOP_WORD(offset);
该句的作用是使p指向数组中索引为offset的bit位(即查找起点)所在的元素。
我们知道,位图的0~31位在数组第0个元素中, 32~63位在第1个元素中,等等(如图1)。假设offset=33,则BITOP_WORD(offset)就是33/32,结果为1,那addr + BITOP_WORD(offset)就是addr+1,即指向数组第1个元素,就是索引为33的bit位所在的元素。
b.
unsigned long result = offset & ~(BITS_PER_LONG-1);
BITS_PER_LONG-1就是31,二进制形式就是0001 1111(这里为了表述方便,采用8位二进制),再取反就是1110 0000,即低5位全0,剩下的都是1。假设offset=70D=0100 0110B,那么,
offset & ~(BITS_PER_LONG-1)就是0100 0110 & 1110 0000 =0100 0000=64。其实,就是将offset的低5位置0,高位保持不变。这个结果有什么意义呢?其实就是:索引为offset的bit位所在的元素前的元素中bit位的个数,如下图所示。很显然,这些bit位都位于查找起点的前面,即它们都不在搜索范围之内,我们可以将它们理解为“已处理”的bit位。请读者牢记,在find_next_bit函数中,result总是表示“已处理”的bit位总数,并且,很显然,它一定是32的整数倍。

c.
if (offset >= size) return size;
如果查找的起始位置offset大于等于位图的总大小,直接返回位图大小。这里解释一下问什么要有等于,假设offset=size=64,但实际上,这种情况下,合法的索引是0~63,所以,值为64的offset不合法。问题的根源在于offset是从0算起的,而size是从1算起的。另外,个人认为这两句应该放在函数体的最前面,这样一来,只要if条件成立,就直接返回,后面的工作就都不用做了。而按照源码的写法,是无论如何都要执行前两句的,但如果此时if条件成立,前边的工作就白做了,这不是一个高效的安排。
d.
size -= result;
offset %= BITS_PER_LONG;
注意,从这两句开始,size和offset的含义和传参时的含义就不同了。
size-=result就是size=size-result,前边说过,此时的result表示查找起点所在数组元素前的元素中bit位的个数,就是“已处理”的bit位个数,我们要找的bit位一定在这后边;而size表示位图总位数。两者相减的结果,就是“未处理的、待查找的”bit位个数。请读者牢记,此后的代码中,result表示“已处理”的bit位总数,而size表示“待处理”的bit位总数,两者的加和,一定等于传参时size的值。
offset %= BITS_PER_LONG执行之后的offset也不再表示查找起点的索引,而表示查找起点在它所在的元素中是第几个。假设原来offset=32,则执行该句之后,offset的值变成了0,而从前面的示意图中我们可以看到,索引为32的bit位正是在数组的第1个元素(从0算起)的第0位(从0算起)。所以,我们可以这样说,代码执行前,offset是查找起点在整个位图中的索引;代码执行后,offset是查找起点在它所在的数组元素中的索引。
e.
if (offset) { tmp = *(p++); tmp &= (~0UL << offset); if (size < BITS_PER_LONG) goto found_first; if (tmp) goto found_middle; size -= BITS_PER_LONG; result += BITS_PER_LONG; }
进入这个if的条件是offset不为0,通过前面的分析,就是查找起点不在所在数组元素的首位(我们前边举的例子就是在首位的情况)。好了,开始分析里面的代码,看看这个if做了什么。
e_1
tmp = *(p++);
这句得到的是查找起点所在的数组元素的值,也就是那32个bit。tmp是unsigned long型的,在文章开头给出的源码的第6行定义。注意:
1.表达式(p++)得到的是p的值(后置++),之后指针p再自增1,指向下一个数组元素。
2.tmp只是构成位图的数组元素的拷贝而不是数组元素本身,即,对tmp所进行的任何修改,都不会影响到原位图。
e_2
tmp &= (~0UL << offset);
首先,0UL就是unsigned long型的数字0,从二进制的角度看,就是32位全0;然后,对它取反,就是32位全1;接着,再左移offset位,假设offset=3,移位后就是1111 1000(为表述方便,这里只写8位);最后,再和tmp(即查找起点所在的数组元素的值)相与,结果就是tmp的低3位置0,其余位保持不变。为什么要这么做呢?因为offset=3,它前面的第2位、第1位、第0位其实都不在搜索范围之内,所以,我们将它们置为0(当然,e_1中就说过,这只是在拷贝上操作,不会影响到原位图),这主要是为后面的工作做准备(读者看到e_4小节就会自然明了)。所以,这句代码的用意是:在查找起点所在的元素中,将查找起点前的bit位置0。代码之所以要将查找起点是否在数组元素的第0位区别对待,就是因为若查找起点不在数组元素首位,需要将查找起点前的bit位置0。
e_3
if (size < BITS_PER_LONG) goto found_first;
通过前面的分析,我们知道,此时的size表示的是“待处理”的bit位总数,而现在,这个数字小于32,这说明:
1.函数调用时传入的参数不是32的整数倍,构成位图的数组的最后一个元素中含有“无效位”,这一点,在讲解函数参数时就详细解释过;
2.查找起点就在数组的最后一个元素中!
上面的图2就展示了这种情况,假设函数调用时传入的参数size是86,通过d中的分析,我们知道,此时size的值是86-64=22,满足if中的条件,而显然,这种情况下,查找起点(索引为70的bit位)正是在最后一个数组元素中。
在这种情况下,代码要转到found_first处。我们继续跟踪,看看found_first干了些什么。
e_4
found_first: tmp &= (~0UL >> (BITS_PER_LONG - size)); if (tmp == 0UL) return result + size;
首先,我们要知道,代码能走到这里,存在两个前提:
1.查找起点在数组的最后一个元素中
2.最后一个元素中存在“无效位”
通过e_3中的分析,我们知道,此时的size表示的是“待处理”的bit位的个数,同时,它也表示最后一个元素中“有效位”的个数。那么,很显然,BITS_PER_LONG-size就是“无效位”的个数,为了表述方便,我们假设该值位3,那么~0UL >> (BITS_PER_LONG - size)得到的就是这样的32个bit位:最左3位为0,其余位为1。然后,这32个bit位再与tmp(即最后一个数组元素的拷贝)相与,结果就是:将该元素中的“无效位”都置为0了(注意,对32位的long型数据来说,低位、索引小的位在右,高位、索引大的位在左,所以,“无效位“一定是在最左边的)!
回顾一下e_2,在e_2中,将元素中查找起点之前的位都置成了0,而现在,又将“无效位”都置成了0,如下图

那么,剩下的是什么呢?剩下的就是查找范围,即我们要在上图中的白色部分找第一个位1的bit位。
现在,让我们思考这样一个问题:如果此时最后一个数组元素,即tmp的值为0(即if (tmp == 0UL)),说明了什么呢?细思,极恐,这说明查找范围内全是0!因为红色部分和黄色部分早就置为0了,而现在整个元素的值为0,那结论只有一个——白色部分全是0!
而我们可能会马上想到这样一个不幸事实:这已经是位图中的最后一个数组元素了!
于是,我们就会得到这样一个令人绝望的结论:以函数参数offset为查找起点,在当前位图中找到一个值为1的bit位,已经不可能了!
在这种情况下,函数只好无奈地return result + size了,d中说过,result + size的值,一定等于传参时size的值,即数组的总大小。
这,就是e_4中代码的含义。
那么,如果我们的运气没那么差,if (tmp == 0UL)没有被执行,也就是说,白色部分有1存在!进而我们就会欣喜地想到:这样,就一定能找到满足条件的bit位!那么,具体怎么找呢?看了最初的源码我们会发现,代码走到了found_middle标签下。好吧,让我们来看看found_middle下有什么。
e_5
found_middle: return result + __ffs(tmp);
这里出现了一个新的函数__ffs,它定义在include/asm-generic/bitops/__fss.h中,我们先来看一下这个函数
1 /** 2 * __ffs - find first bit in word. 3 * @word: The word to search 4 * 5 * Undefined if no bit exists, so code should check against 0 first. 6 */ 7 static inline unsigned long __ffs(unsigned long word) 8 { 9 int num = 0; 10 11 /*如果BITS_PER_LONG等于64,要先对低32位进行检查;否则(即BITS_PER_LONG等于32),直接对低16位进行检查*/ 12 #if BITS_PER_LONG == 64 13 if ((word & 0xffffffff) == 0) { //如果与0xffffffff相与得0,说明word的低32位全为0 14 num += 32; //索引加32 15 word >>= 32; //word右移32位,把低32位的0移走 16 } 17 #endif 18 if ((word & 0xffff) == 0) { 19 num += 16; 20 word >>= 16; 21 } 22 if ((word & 0xff) == 0) { 23 num += 8; 24 word >>= 8; 25 } 26 if ((word & 0xf) == 0) { 27 num += 4; 28 word >>= 4; 29 } 30 if ((word & 0x3) == 0) { 31 num += 2; 32 word >>= 2; 33 } 34 if ((word & 0x1) == 0) 35 num += 1; 36 return num; 37 }
该函数的功能是在参数word中找到第一个值为1的bit位,返回该位的索引。可以看到,该函数没有对参数word=0的情况(这意味着不可能在word中找到值为1的bit位)进行检查,所以我们应该在调用该函数前对传入的参数是否为0进行检查,这就是上面代码中第5行的英文注释的意思,而该函数的调用者find_next_bit在调用该函数前已经进行过检查了,正如我们在e_4中分析的那样。
该函数的算法还是很巧妙的,它类似于“折半查找”。假设参数word是32位的,先执行word & 0xffff,析取低16位,这时可能出现两种结果:
1.如果结果为0,说明低16位(0~15位)全为0,那么,可能为1的bit位最小是第16位,所以num += 16,并且,执行word >>= 16,将全0的低16位移走,这样,可能有1存在的高16位变成了低16位;接着,如法炮制,word与0xff相与,对剩下的16位进行“折半查找”。
2.如果结果不为0,说明低16位中有1存在,由于我们是要找第一个为1的bit位,所以,高16位就不用看了,直接在低16位中寻找,所以,下一步就是执行word & 0xff,对低16位进行“折半查找”。
可见,无论word & 0xffff的结果是否为0,word & 0xff都是要执行的,只不过,如果word & 0xffff结果为0,需要进行增加计数和右移的工作。
按照上面的步骤,逐步进行“折半查找”,最终就能得到word中第一个为1的bit位的索引。读者可以自己举个例子,手动执行一下__ffs函数,就更加清楚了,这里不再赘述。
有一点大家要意识到,find_next_bit在调用__ffs时传入的参数是tmp,而在e_4中我们看到,tmp中查找起点前的bit位和“无效位”都被置为0了,并且,也已经判断出tmp不为0,所以,__ffs一定能找到为1的bit位且保证该bit位在合法的搜索空间(图3的白色区域)内。
现在我们再来看found_middle下的那句return result + __ffs(tmp)。__ffs(tmp)得到的是tmp中自查找起点起第一个为1的bit位的索引,而result表示的是位图中tmp之前的所有元素中bit位的总和,所以,两者相加,就是我们要找的bit位在位图中的索引,即find_next_bit的最终结果,于是,将这个结果return。
至此,find_next_bit的查找工作就结束了,但是,我们对find_next_bit的分析还没结束。不知读者是否还记得,我们是从e_3中if (size < BITS_PER_LONG)成立这个“路口”进入,一路追踪,才走到这里来的。所以我们还要分析if (size < BITS_PER_LONG)不成立的情况,于是,让我们再次回到最初的源码……
e_6
if (tmp) goto found_middle;
如果if (size < BITS_PER_LONG)不成立,就会执行上面的代码。if (size < BITS_PER_LONG)不成立,说明了什么呢?这说明tmp不是数组的最后一个元素,因此就不可能有“无效位”,也就不存在将“无效位”置为0的问题(即不用goto found_first了),又因为,在e_4中,已经将查找起点前的bit位都置0了,所以,这里直接判断tmp是否为0,如不为0,说明在这个tmp中一定能找到为1的bit位,所以,转到found_middle,找到第一个为1的bit位在位图中的索引,然后返回结果。
那么,如果这里的tmp为0呢,该执行什么样的代码,我们往下看。
e_7
size -= BITS_PER_LONG;
result += BITS_PER_LONG;
如果tmp为0,说明在当前数组元素中不可能找到为1的bit位,于是需要在下一个数组元素中寻找,在此之前,将“未处理”bit位总数减去32,将“已处理”bit位总数增加32。有读者可能会问:怎么没见指针后移呢?不要忘了,在e_1中,这个工作已经做过了。
至此,整个e中的代码就都分析完了 。但是,革命尚未成功,喘口气,我们还得往下看。
f
while (size & ~(BITS_PER_LONG-1)) { if ((tmp = *(p++))) goto found_middle; result += BITS_PER_LONG; size -= BITS_PER_LONG;
}
首先要明白,有两种情况代码会走到这里:
1.这个while循环上面的if(offset)(就是e中的代码)条件不成立(即查找起点位于数组元素的第0位),if中的语句体没有被执行。
2.if(offset)的语句体被执行了,但该语句体内部的两个if条件都不成立,这又分为两种情况:
1.查找起点所在的数组元素不是数组的最后一个元素,并且,该元素中全是0,没有1。
2.查找起点是数组最后一个元素,但该元素中没有“无效位”,并且,该元素中全是0,没有1。
在上面的两种情况下,我们就要执行上面的while循环,在后面的数组元素中依次查找。
我们先来看一下循环进入条件
while (size & ~(BITS_PER_LONG-1))
我们将BITS_PER_LONG换成32,并转换为二进制形式,上面的语句就变成了while(size & 1110 0000),这是什么呢?其实就是while(size>=32)!因为小于32(0010 0000B)的无符号数(注意size是unsigned long型,请看最初的源码)与1110 0000相与的结果都是0000 0000,而大于等于32的无符号数与1110 0000相与的结果都将大于0010 0000。好了,现在我们知道了,上面那句故弄玄虚的while语句其实就是while(size>=32)。
好了,现在我们来看循环体。先看第一句
if ((tmp = *(p++)))
这句代码依次做了三件事:
1.将p指向的数组元素(当然也是我们要进行查找的数组元素)复制到tmp
2.p指针自增,指向下一元素
3.判断tmp是否为0
这里需要解释一下:
1.如果查找起点在一个数组元素的第0位,那么,e中的if语句体就不会被执行,也就不会执行到if语句体中的tmp = *(p++),所以当第一次进入while循环并执行if ((tmp = *(p++)))时,tmp就是查找起点所在的数组元素的拷贝。
2.如果查找起点不在一个数组元素的第0位,e中的if语句体就会被执行,当第一次进入while循环并执行if ((tmp = *(p++)))时,tmp就是if语句体中那个tmp对应的元素的下一个元素的拷贝。
现在让我们在整体看一下这个循环体
if ((tmp = *(p++))) goto found_middle; result += BITS_PER_LONG; size -= BITS_PER_LONG;
如果tmp不为0,说明我们要找的为1的bit位一定在这个tmp中,于是转到found_middle,进行查找并返回结果,find_next_bit函数结束;如果tmp等于0,说明该元素中不含1,将“已处理”位数增加32,“待处理”位数减少32,然后判断循环条件(“待查找”位数是否大于32),若条件成立,进入循环体,对下一个数组元素进行查找,否则,退出循环。
如果上面的while循环是正常退出(即由于size小于32而退出)的,那就说明整个整个while循环都没找到为1的bit位(否则,代码将从循环体转到found_middle,while循环将不会正常退出)。如果是这种情况,接下来该怎么办呢?我们还是继续看源码吧。
g
if (!size) return result; tmp = *p; found_first: tmp &= (~0UL >> (BITS_PER_LONG - size)); if (tmp == 0UL) return result + size; found_middle: return result + __ffs(tmp);
首先要明白,代码走到这里,有四种情况:
1.查找起点位于数组的最后一个元素中,且位于该元素的第0位,同时,该元素含有“无效位”,即传入的参数size不是32的整数倍,并且,执行完d中的代码后,size小于32(这种情况容易被忽略)。在这种情况下,e中的if语句和f中的while循环都不会被执行,代码直接从d处走到g处。
2.代码执行完e中的if后不再满足while循环的条件,直接走到g中代码处。这种情况是:查找起点在倒数第二个元素中且不位于第0位且该元素32位全是0,同时,最后一个数组元素中有“无效位”(传入参数size不是32的整数倍)。
3.while循环由于size=0而退出(传入参数恰好是32的整数倍),这种情况下,整个位图都查找过了且并没有找到为1的bit位,换句话说,不可能再找到了。
4.while循环由于size介于1~31之间而退出,即数组的最后一个元素中有“无效位”(传入参数size不是32的整数倍)。
下面让我们看看,在这四种情况下,代码是怎么做的:
首先,代码先判断size是否等于0,若等于0,直接返回result,这正对应了上面的情况3。注意,我们前面就说过,size+result的值总是等于传参时size的值(位图总大小),而此时size=0,所以,返回result,就是返回位图总大小。
如果size不等于0,那就对应1、2、4三种情况,这三种情况的共同点是:都需要在数组的最后一个元素中查找,并且该元素中含有“无效位”。在这种情形下,find_next_bit函数的处理是:
1.将最后一个数组元素拷贝到tmp
2.在found_first中,将“无效位”置0,检验tmp是否为0,若是,返回位图总大小,否则,进入found_middle
3.在found_middle中,找到tmp中第一个为1的bit位的索引,返回该位在位图中的索引
至此,find_next_bit函数结束。
Ⅴ.总结
至此,我们对find_next_bit函数的分析就全部完成了。我们可以看到:
1.若函数查找成功,返回自查找起点起第一个为1的bit位的索引;若查找失败,返回位图总大小。
2.find_next_bit函数只是在位图中进行查找,自始至终都没有对位图进行任何修改。
最后,我们给出find_next_bit函数源码的简要注释版,作为最后的总结梳理
/* *@addr:位图首地址 *@size:位图总大小 *@offset:查找起点 */ unsigned long find_next_bit(const unsigned long *addr, unsigned long size, unsigned long offset) { /*找到查找起点所在数组元素的地址*/ const unsigned long *p = addr + BITOP_WORD(offset); /*计算查找起点所在数组元素前的数组元素中bit位的总个数,即“已处理”bit位个数*/ unsigned long result = offset & ~(BITS_PER_LONG-1); unsigned long tmp; /*如果查找起点大于等于位图大小,返回位图大小*/ if (offset >= size) return size; /*size:“未处理”bit位个数*/ size -= result; /*offset:查找起点在所在数组元素中的索引*/ offset %= BITS_PER_LONG; /*如果查找起点不在数组元素中的第0位*/ if (offset) { /*拷贝元素*/ tmp = *(p++); /*将查找起点前的bit位都置0*/ tmp &= (~0UL << offset); /*如果查找起点位于最后一个数组元素且该元素含有“无效位”*/ if (size < BITS_PER_LONG) goto found_first; /*如果tmp不为0,一定能找到*/ if (tmp) goto found_middle; /*“待查找”bit位总数减少32,“已查找”bit位总数增加32*/ size -= BITS_PER_LONG; result += BITS_PER_LONG; } /*while(size>=32)*/ while (size & ~(BITS_PER_LONG-1)) { /*拷贝元素,若不为0,一定能找到*/ if ((tmp = *(p++))) goto found_middle; /*“待查找”bit位总数减少32,“已查找”bit位总数增加32*/ result += BITS_PER_LONG; size -= BITS_PER_LONG; } /*若size=0,返回位图总大小*/ if (!size) return result; /*否则,拷贝最后一个数组元素*/ tmp = *p; found_first: /*将元素中“无效位”都置为0*/ tmp &= (~0UL >> (BITS_PER_LONG - size)); /*若tmp为,不可能再找到,直接返回位图总大小*/ if (tmp == 0UL) return result + size; found_middle: /*走到这里,就一定能找到,查找,返回结果*/ return result + __ffs(tmp); }
写在后面
自认为写得很详细了,但在下才疏学浅,错误疏漏之处在所难免,恳请广大读者批评指正,您的批评指正是在下前进的不竭动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号