Mysql主从同步和数据一致性
Mysql主从同步架构
Mysql集群通常指Mysql的主从复制架构,架构为一主多从,通过逻辑复制的方式把主库数据复制到从库,但主从之间无法保证严格一致的模式,会带来主从“数据一致性”的问题。
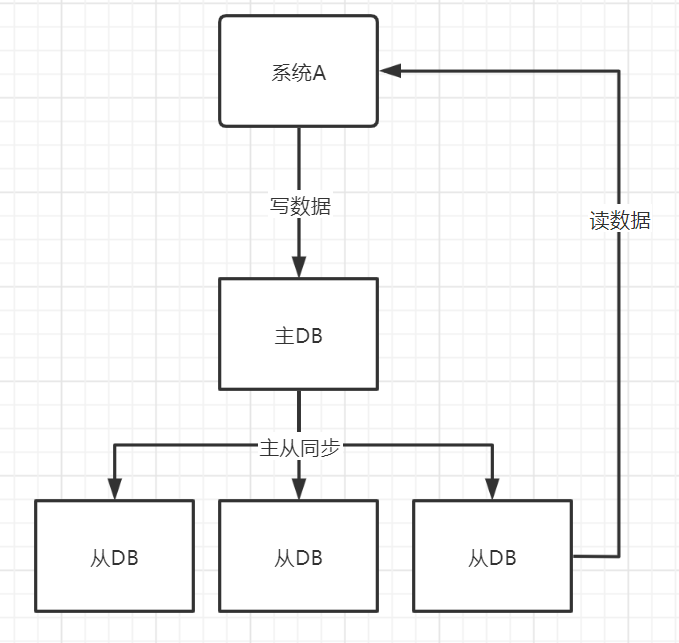
Mysql主从复制原理
主从同步步骤:
- 主库将变更写入
binlog日志 - 从库连接到主库后会有一个IO进程把主库的
binlog复制过来,写入一个中继日志中 - 从库的一个sql进程会从中继日志中读取
sql然后执行
注意点:
- 从库同步主库的数据是串行化的,也就是说在主库并行的操作,在从库会串行化执行。在高并发场景下,从库的数据是一定会比主库慢一些的,是有延时的,所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
- 如果主库突然宕机,数据恰好没有同步到从库,那么从库就会产生数据丢失的问题
解决Mysql主从同步数据一致性的问题
1. mysql的主从复制机制
首先看mysql在主从复制这块使用的三种机制:
- 异步复制
- 半同步复制
- 全同步复制(组复制)
异步复制
mysql的默认复制机制是异步的,主库执行完客户端提交的事务后会立刻把结果返回给客户端,并不关心从库是否接收并处理,会导致如果主DB宕机了,就可能导致主机上提交的事务可能并没有同步到从db中,主从之间无法保证严格一致的模式
半同步复制
- 介于异步复制和并行复制之间,MySQL在5.5中引入了半同步复制,主库执行完客户端提交的事务后并不会立刻返回给客户端,而是强制立即将数据同步给从库,从库将日志写入到自己的reply log中后,接着会返回一个ack给主库,主库等待至少一个从库接收到ack才返回给客户端;相对于异步复制,提高了数据的安全性,但也提高了延迟,最少是一个TCP/IP往返的时间,所以最好在低延迟的网络中使用
- 半同步复制通过
rpl_semi_sync_master_wait_point参数来控制主库在哪个环节接收从库的ack,该参数有两个选项:WAIT_AFTER_SYNC、WAIT_AFTER_COMMIT
配置为WAIT_AFTER_COMMIT时:
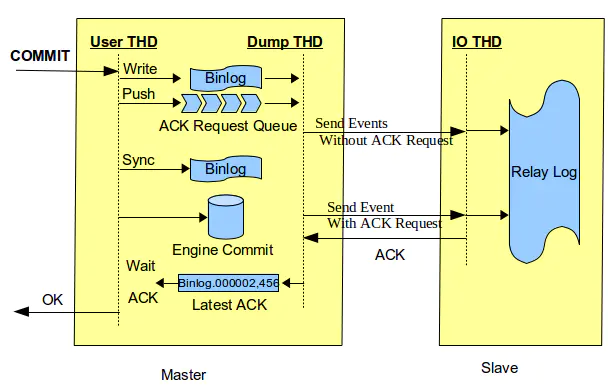
如上图所示,会带来两个问题:
- 提交的调用在主db提交之后,虽然没有返回给客户端,但是事务已经提交了,其他客户端会读取到已提交的数据;
- 如果从库还没有读到该事务,但是主库宕机了,切换到了其他从库,那么之前读到的事务就不见了,就出现了数据不一致的问题,如果主库永远启动不了,那么实际上在主库已经成功提交的事务,在从库上是找不到的,也就是数据丢失了。
配置为WAIT_AFTER_SYNC时:

mysql针对上面的问题,在5.7引入了Loss-less Semi-Synchronous,就是说在调用binlog sync之后,主库engine层会等待从库的ack再进行提交,这样只有确认了从库收到了事务之后,主库才会进行提交。
虽然WAIT_AFTER_SYNC解决了WAIT_AFTER_COMMIT模式带来的数据一致性的问题,但是也带来了新的问题:
当主库binlog flush之后而且把事务发送到了从库,但在等待从库ack的过程中宕机了,很明显这个事务在主库上是未提交成功的,会被回滚掉,但由于从库已经收到了事务并执行成功,相当于从库上多出了数据,从而可能导致数据不一致;
但无论配置的哪种模式,在主库等待从库ack的过程中超时退化成了异步,都会导致数据一致性的问题
优点:
- 利用数据库原生功能,比较简单
- 可以降低数据一致性风险,提高数据安全性
缺点:
- 主库的写请求时延会增长,吞吐量会降低
- 只能提高数据安全性,并不能保证绝对的数据一致性
全同步复制(组复制)
所谓全同步复制(组复制),指的是从库会开启多个线程,并行去读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行,是MySQL 5.7.17开始引入的新功能,为主从复制实现高可用功能,它支持单主模型和多主模型,默认是单主模型。
- 单主模型:从复制组中众多个MySQL节点中自动选举一个
master节点,只有master节点可以写,其他节点自动设置为read only;当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master - 多主模型:复制组中的任何一个节点都可以写,因此没有
master和slave的概念
组复制原理:
- 复制组由多个
server成员构成,并且组中的每个server成员可以独立地执行事务 - 所有读写(
RW)事务只有在冲突检测成功后才会提交。只读(RO)事务不需要在冲突检测,可以立即提交
- 简单来说,就是对于任何的
RW事务,提交操作都不是有始发的server单向决定的,而是由组来决定的。 - 在始发server上,当事务准备提交时,该 server 会广播写入值(已改变的行)和对应的写入集(已更新的行的唯一标识符),然后会为该事务建立一个全局的顺序。最终,这意味着所有 server 成员以相同的顺序接收同一组事务。因此,所有 server 成员以相同的顺序应用相同的更改,以确保组内一致。
优点:
- 组复制能够根据在一组 server 中复制系统的状态来创建具有冗余的容错系统。
- 因此,只要它不是全部或多数 server 发生故障,即使有一些 server 故障,系统仍然可用,最多只是性能和可伸缩性降低,但它仍然可用。
- server 故障是孤立并且独立的。它们由组成员服务来监控,组成员服务依赖于分布式故障检测系统,其能够在任何 server 自愿地或由于意外停止而离开组时发出信号。
- 提供了高可用性,高弹性,可靠的 MySQL 服务
缺点:
1效率很低,当master节点写数据的时候,会等待所有的slave节点完成数据的复制,然后才继续往下进行组复制的每一个节点都可能是slave
2. 使用数据库中间件
- 所有的读写都走数据库中间件,通常情况下,写请求路由到主库,读请求路由到从库
- 记录所有路由到写库的key,在主从同步时间窗口内(假设是500ms),如果有读请求访问中间件,此时有可能从库还是旧数据,就把这个key上的读请求路由到主库
- 在主从同步时间过完后,对应key的读请求继续路由到从库
常用的数据库中间件:canal、otter等
优点:
- 保证数据绝对一致
缺点:
- 实现成本较高
3. 缓存记录写key法
写:
- 如果key要发生写操作,记录在cache里,并根据经验设置的cache超时时间,例如500ms
- 然后修改主数据库
读
- 先到缓存里查看,对应key有没有相关数据
- 有相关数据,说明缓存命中,这个key刚发生过写操作,此时需要将请求路由到主库读最新的数据
- 如果缓存没有命中,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离
优点:
- 相对数据库中间件,实现成本较低
缺点:
- 为了保证“一致性”,引入了一个cache组件,并且读写数据库时都多了缓存操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号