

一、收获
1.这是假期的第三周,主要学习了python爬虫的一些基础知识。
爬虫的四个步骤:
-
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
-
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
-
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
-
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
获取数据:
# 引入requests库 import requests # requests.get是在调用requests库中的get()方法,它向服务器发送了一个请求,括号里的参数是你需要的数据所在的网址,然后服务器对请求作出了响应。# 我们把这个响应返回的结果赋值给变量res res = requests.get('URL')
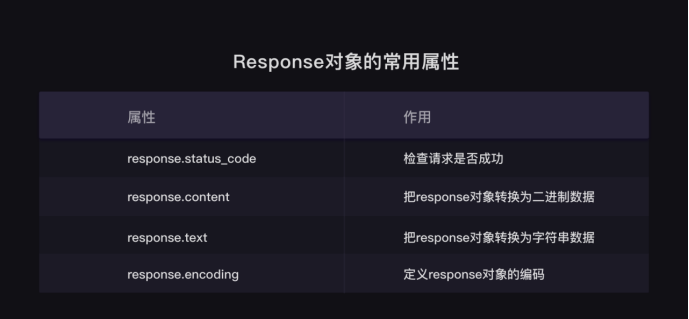
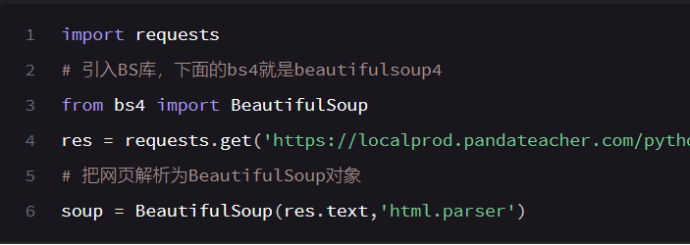
解析数据:
提取数据:
find()与find_all():可以匹配html的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来。
Find():运行结果的数据类型是 <class 'bs4.element.Tag'>,是一个Tag类标签
Find_all():运行结果是<class 'bs4.element.ResultSet'> ,是一个ResultSet类的对象,是Tag对象以列表结构储存了起来。
1 # 调用requests库 2 import requests 3 # 调用BeautifulSoup库 4 from bs4 import BeautifulSoup 5 # 返回一个response对象,赋值给res 6 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') 7 # 把res的内容以字符串的形式返回 8 html = res.text 9 # 把网页解析为BeautifulSoup对象 10 soup = BeautifulSoup( html,'html.parser') 11 # 通过定位标签和属性提取我们想要的数据 12 items = soup.find_all(class_='books') (注:下划线是为了与python语法中的类class区分) 13 for item in items: 14 # 打印item 15 print('想找的数据都包含在这里了:\n',item) 16 print(type(item))
2.每天主要花费1个小时来学习,并且会根据当天学习任务的多少与难度进行调整。
二、下周目标
下周继续学习python的爬虫知识
三、遇到问题
爬取网页时,对于特定内容的获取有点不熟悉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号