


1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
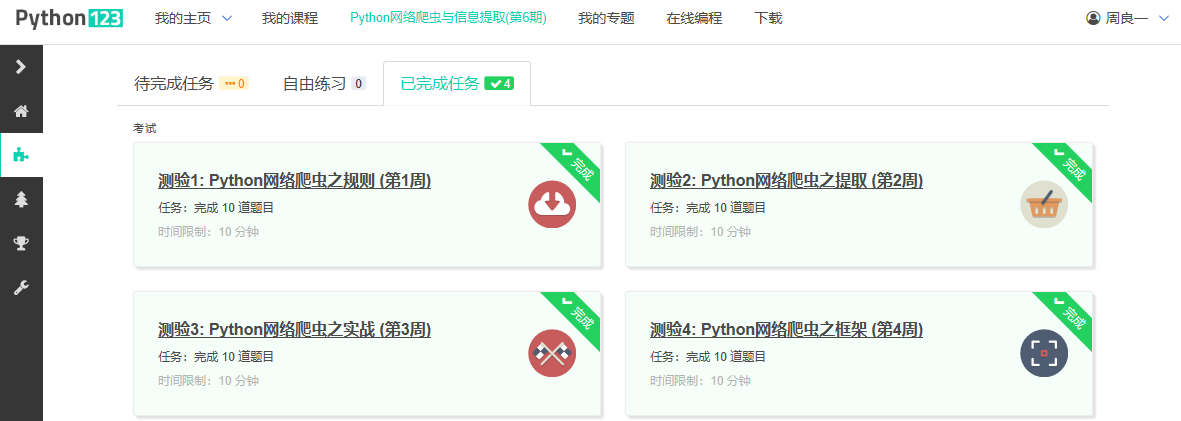
4.提供图片或网站显示的学习进度,证明学习的过程。
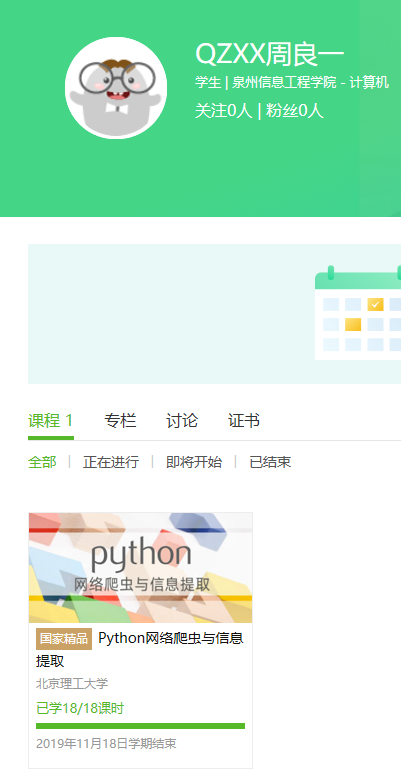
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
最早接触python是从大三上学期开始的,从那时起就体会到了python第三方库的强大。这一次选择了上了北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程后,逐渐将“爬虫”这一概念实体化,也颠覆了我对这一门语言的想象,它的强大远不止这些。
在这长达一个多星期的爬虫学习过程中,先是从requests这一入门级别的第三方库开始学习,简单的获取url的页面信息,再到Beautiful Soup库对于标签内容和属性等的获取,再通过Re正则表达式的运用,通过对页面的解析,能够精确获取到自己想要的信息,但是正则表达式也是一个难点,比较难理解它的运用;最后到爬虫框架Scrapy的学习,循序渐进,也让我深知,网络爬虫并不简单!
嵩天老师细致入微地给我们讲解了爬虫的概念,通过一次次的实例演示向我们教授了如何从网站获取我们所需要的信息,并站在用户的角度,通过print的format的输出格式控制来达到良好的用户体验。在能完成程序功能的同时,给用户一个良好的体验才是衡量程序是否优秀的标准,这也给未来从事这一方面工作的人一个很好的启发。另外,嵩天老师常说的一句话是“网络连接有风险,异常处理很重要”,其实在我们平时所写的程序中,一般很少有异常处理的部分,在python中用try、except的语句异常处理可以避免很多可能会出错的情况,也能使程序即使碰到异常也能够运行下去,不至于让程序碰到异常情况就停止了,这是一个很好的编程习惯,也值得我们学习。还有爬虫最为重要的一点则是遵守Robots协议,在一般比较官方和商用的网站都会有这样的协议,这也是爬虫“盗亦有道”的准则,如果不遵守Robots协议,将所爬取到的信息用以商业用途,就很有可能造成犯罪,当然如果只是小规模的爬取,用以学习的话,这种情况下也是可以忽略Robots协议的。
当然,在学习的过程中也遇到过不少坑,比如获取淘宝搜索页面信息的实例中,发现代码不能运行,原因是淘宝自2019年开始便需要用户登录才能进行搜索,因此需要修改代码,将网页的cookies和users-agent的相关信息加入到header标签中才能运行;在获取股票信息的实例中,发现教学所用的百度股票已经停止了使用,以至于无法实现教学的内容,以目前所学要实现爬取,只能利用其他股票网站,并且股票的相关信息不能以后台表单提交到页面的形式,而要通过数据直接提交到页面的网站,但至今我还没有解决这个问题。
通过这一次的网络爬虫的学习,再一次发现我所掌握的东西少之又少,而且太浅层了,距离一个合格的程序员还有很大的一段距离,也希望在接下来的学习中能够多加学习一些内容补充匮乏的知识,做到全面的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号