


Zookeeper概念学习系列之zookeeper是什么?
1、 Zookeeper是Hadoop的分布式协调服务。
2、 分布式应用程序可以基于它,来实现同步服务,配置维护和命名服务等。
3、 zookeeper可以保证数据在zookeeper集群之间的数据的事务性一致。
前言
Google的三篇论文影响了很多很多人,也影响了很多很多系统。这三篇论文一直是分布式领域传阅的经典。根据MapReduce,于是我们有了Hadoop;根据GFS,于是我们有了HDFS;根据BigTable,于是我们有了HBase。而在这三篇论文里都提及Google的一个lock service---Chubby,哦,于是我们有了Zookeeper。
伴随着Zookeeper有两篇论文:一篇是Zab,就是介绍Zookeeper背后使用的一致性协议的(Zookeeper atomic broadcast protocol),还有一篇就是介绍Zookeeper本身的。在这两篇论文里都提到Zookeeper是一个分布式协调服务(a service for coordinating processes of distributed applications)。那分布式协调服务又是个什么东西呢?首先我带各位来看“协调”是什么意思。
zookeeper可谓是目前使用最广泛的分布式组件了。其功能和职责单一,但却非常重要。
在现今这个年代,介绍zookeeper的书和文章可谓多如牛毛,本人不才,试图通过自己的理解来介绍zookeeper,希望通过一个初学者的视角来学习zookeeper,以期让人更加深入和平稳的理解zookeeper。其中参考了不少教程和书,相关书目列在文末,也感谢这些作者。
学习新的框架,先让我们搞清楚他是什么,这是它的内涵,然后再介绍它能做什么,这是它的外延,内涵和外延共同来定义框架本身,会对框架有较为深刻的理解,在应用层面上知道如何用。其次再搞清楚zookeeper相关的理论基础,其目的是知道zookeeper是如何被发明的,是否能够借鉴以便今后自己能够用到其他地方。最后搞清楚zookeeper中一些设计的原理和细节,目的也是搞清来龙去脉,学会“术”从而应用到别的地方。当然了,加深的理解同样能够帮助认识zookeeper本身,在使用时才知道为什么这样用。
什么是协调?
说到协调,我首先想到的是北京很多十字路口的交通协管,他们手握着小红旗,指挥车辆和行人是不是可以通行。如果我们把车辆和行人比喻成运行在计算机中的单元(线程),那么这个协管是干什么的?很多人都会想到,这不就是锁么?对,在一个并发的环境里,我们为了避免多个运行单元对共享数据同时进行修改,造成数据损坏的情况出现,我们就必须依赖像锁这样的协调机制,让有的线程可以先操作这些资源,然后其他线程等待。对于进程内的锁来讲,我们使用的各种语言平台都已经给我们准备很多种选择。
就拿Java来说,有最普通不过的同步方法或同步块:
public synchronized void sharedMethod(){ //对共享数据进行操作 }
使用了这种方式后,多个线程对sharedMethod进行操作的时候,就会协调好步骤,不会对sharedMethod里的资源进行破坏,产生不一致的情况。这个最简单的协调方法,但有的时候我们可能需要更复杂的协调。比如我们常常为了提高性能,我们使用读写锁。因为大部分时候我们对资源是读取多而修改少,而如果不管三七二十一全部使用排他的写锁,那么性能有可能就会受到影响。
public class SharedSource{ private ReadWriteLock rwlock = new ReentrantReadWriteLock(); private Lock rlock = rwlock.readLock(); private Lock wlock = rwlock.writeLock(); public void read(){ rlock.lock(); try{ //读取资源 }finally{ rlock.unlock(); } } public void write(){ wlock.lock(); try{ //写资源 }finally{ wlock.unlock(); } } }
我们在进程内还有各种各样的协调机制(一般我们称之为同步机制)。现在我们大概了解了什么是协调了,但是上面介绍的协调都是在进程内进行协调。在进程内进行协调我们可以使用语言,平台,操作系统等为我们提供的机制。
那么如果我们在一个分布式环境中呢?也就是我们的程序运行在不同的机器上,这些机器可能位于同一个机架,同一个机房又或不同的数据中心。在这样的环境中,我们要实现协调该怎么办?那么这就是分布式协调服务要干的事情。
ok,可能有人会讲,这个好像也不难。无非是将原来在同一个进程内的一些原语通过网络实现在分布式环境中。是的,表面上是可以这么说。但分布式系统中,说往往比做容易得多。在分布式系统中,所有同一个进程内的任何假设都不存在:因为网络是不可靠的。
比如,在同一个进程内,你对一个方法的调用如果成功,那就是成功(当然,如果你的代码有bug那就另说了),如果调用失败,比如抛出异常那就是调用失败。在同一个进程内,如果这个方法先调用先执行,那就是先执行。但是在分布式环境中呢? 由于网络的不可靠,你对一个服务的调用失败了并不表示一定是失败的,可能是执行成功了,但是响应返回的时候失败了。还有,A和B都去调用C服务,在时间上A还先调用一些,B后调用,那么最后的结果是不是一定A的请求就先于B到达呢? 这些本来在同一个进程内的种种假设我们都要重新思考,我们还要思考这些问题给我们的设计和编码带来了哪些影响。还有,在分布式环境中为了提升可靠性,我们往往会部署多套服务,但是如何在多套服务中达到一致性,这在同一个进程内很容易解决的问题,但在分布式环境中确实一个大难题。
所以分布式协调远远比同一个进程里的协调复杂得多,所以类似Zookeeper这类基础服务就应运而生。这些系统都在各个系统久经考验,它的可靠性,可用性都是经过理论和实践的验证的。所以我们在构建一些分布式系统的时候,就可以以这类系统为起点来构建我们的系统,这将节省不少成本,而且bug也将更少。
Zookeeper是什么?
ZooKeeper---译名为“动物园管理员”。动物园里当然有好多的动物,游客可以根据动物园提供的向导图到不同的场馆观赏各种类型的动物,而不是像走在原始丛林里,心惊胆颤的被动 物所观赏。为了让各种不同的动物呆在它们应该呆的地方,而不是相互串门,或是相互厮杀,就需要动物园管理员按照动物的各种习性加以分类和管理,这样我们才能更加放心安全的观赏动物。
回到企业级应用系统中,随着信息化水平的不断提高,企业级系统变得越来越庞大臃肿,性能急剧下降,客户抱怨频频。拆分系统是目前我们可选择的解决系统可伸缩性和性能问题的唯一行之有效的方法。但是拆分系统同时也带来了系统的复杂性——各子系统不是孤立存在的,它们彼此之间需要协作和交互,这就是我们常说的分布式系统0。各个子系统就好比动物园里的动物,为了使各个子系统能正常为用户提供统一的服务,必须需要一种机制来进行协调——这就是ZooKeeper(动物园管理员)。
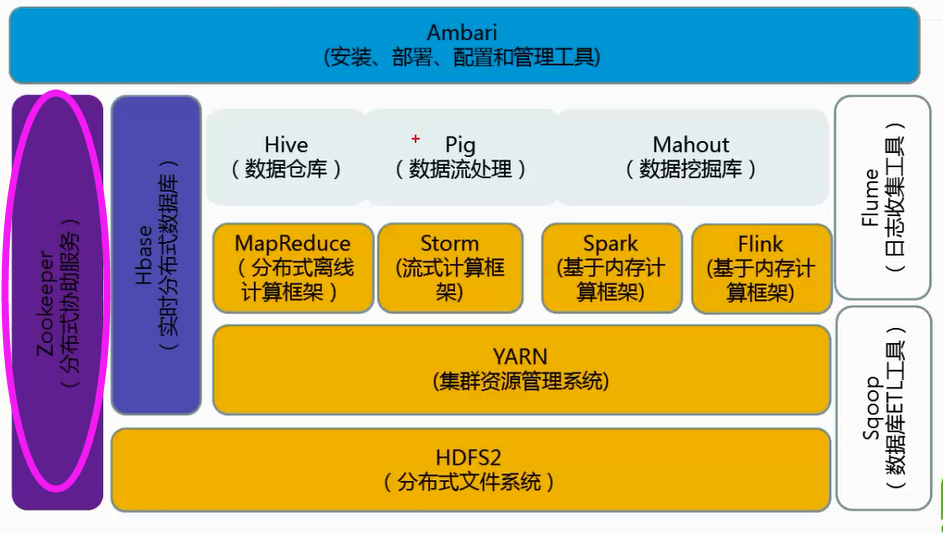
ZooKeeper 是一个针对大型分布式系统的可靠协调系统。
它提供的功能包括:配置维护、名字服务、分布式同步、组织服务等;
它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户; ZooKeeper 已经成为 Hadoop 生态系统中的基础组件。
在Zookeeper的官网上有这么一句话:ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
这大概描述了Zookeeper主要可以干哪些事情:配置管理,名字服务,提供分布式同步、分布式锁、监控以及集群管理。
Zookeeper可以用来配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。但是当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,有很多服务器都需要这个配置,而且还可能是动态的话使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。比如我们可以把配置放在数据库里,然后所有需要配置的服务都去这个数据库读取配置。但是,因为很多服务的正常运行都非常依赖这个配置,所以需要这个集中提供配置服务的服务具备很高的可靠性。一般我们可以用一个集群来提供这个配置服务,但是用集群提升可靠性,那如何保证配置在集群中的一致性呢? 这个时候就需要使用一种实现了一致性协议的服务了。Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。现在有很多开源项目使用Zookeeper来维护配置,比如在HBase中,客户端就是连接一个Zookeeper,获得必要的HBase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列Kafka中,也使用Zookeeper来维护broker的信息。在Alibaba开源的SOA框架Dubbo中也广泛的使用Zookeeper管理一些配置来实现服务治理。
Zookeeper可以用来名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的IP地址,但是IP地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是不能是别域名的。怎么办呢?如果我们每台机器里都备有一份域名到IP地址的映射,这个倒是能解决一部分问题,但是如果域名对应的IP发生变化了又该怎么办呢?于是我们有了DNS这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应的IP是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
Zookeeper可以用来提供分布式同步
ZkConfig是为zookeeper开发的配置服务工具包,能与现有的Java系统进行良好的集成,也可以使用与非java系统以独立进程运行。提供与spring进行集成的插件。采用注解方式对需要动态更新的内存数据对象进行标注。
ZkConfig用于解决在系统集群中配置文件的实时同步。当任意一台服务器配置文件发生变化的时候,所有集群服务器配置文件实现同步更新,并且在不启动web容器的情况下,实现内存配置对象的实时更新。
目前支持所有种类配置文件的同步更新,仅支持扩展名为.properties与.cfg结尾的健值对文件格式的内存数据对象实时同步。其余配置文件仅支持磁盘数据同步。
Zookeeper可以用来分布式锁(实用编程)
Zookeeper是一个分布式协调服务。这样我们就可以利用Zookeeper来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。比如HBase的Master就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
Zookeeper可以用来监控(实用编程)
这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。
利用ZooKeeper有两个特性(读可监控,临时节点),就可以实现一种集群机器存活性监控系统:
1. 客户端在节点 x 上注册一个Watcher,那么如果x的子节点变化了,会通知该客户端2. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失利用这两个特性,可以分别实现对客服端的状态变化、上下线进行监控。
例如,监控系统在 /Monitor 节点上注册一个Watcher,以后每动态加机器,那么就往 /Monitor 下创建一个 EPHEMERAL类型的节点:/Monitor/{hostname}. 这样,监控系统就能够实时知道机器的增减情况,至于后续处理就是监控系统的业务了。
Zookeeper可以用来集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一个分布式的SOA架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有开源的Kafka队列就采用了Zookeeper作为Cosnumer的上下线管理。
zookeeper到底是什么?
zookeeper实际上是yahoo开发的,用于分布式中一致性处理的框架。最初其作为研发hadoop时的副产品。由于分布式系统中一致性处理较为困难,其他的分布式系统没有必要 费劲重复造轮子,故随后的分布式系统中大量应用了zookeeper,以至于zookeeper成为了各种分布式系统的基础组件,其地位之重要,可想而知。著名的hadoop,kafka,dubbo 都是基于zookeeper而构建。
要想理解zookeeper到底是做啥的,那首先得理解清楚,什么是一致性。
所谓的一致性,实际上就是围绕着“看见”来的。谁能看见?能否看见?什么时候看见?举个例子:淘宝后台卖家,在后台上架一件大促的商品,通过服务器A提交到主数据库,假设刚提交后立马就有用户去通过应用服务器B去从数据库查询该商品,就会出现一个现象,卖家已经更新成功了,然而买家却看不到;而经过一段时间后,主数据库的数据同步到了从数据库,买家就能查到了。
假设卖家更新成功之后买家立马就能看到卖家的更新,则称为强一致性;
如果卖家更新成功后买家不能看到卖家更新的内容,则称为弱一致性;
而卖家更新成功后,买家经过一段时间最终能看到卖家的更新,则称为最终一致性。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号