


Selenium 抓取淘宝商品美食信息
在使用python进行数据爬取的时候,我们发现ajax请求比较繁琐,那么有什么好的办法可以解决呢?就是使用selenium自动化工具,模拟输入点击,这样我们就可以不需要知道ajax的请求链接,从而可以直接通过类似人工的操作来模拟,从而可以获取网页数据。我们来举个例子。
淘宝的首页,我们打开发现没有商品数据的信息,而他的数据都是通过ajax请求获取的,那么我们使用ajax请求这种方法来获取数据简单吗?我们来看看。
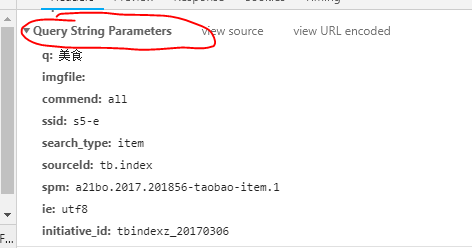
我们在淘宝首页输入美食,进入美食界面我们发现他的链接:https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 这么长,他的参数这么多,我们都需要一一来给他赋值,下面就是所有的参数的名称还有信息,而且有的参数我们根本不知道到底是什么意思。所以就很麻烦,我们就使用selenium工具来自动化输入。
首先我们需要加载淘宝界面:


browser = webdriver.Chrome() wait=WebDriverWait(browser,10) client=pymongo.MongoClient(MONGO_URL) db=client[MONGO_DB] browser.set_window_size(1400,900) def serach(): try: browser.get('https://www.taobao.com') input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'#q')) )#通过css 选择器找到淘宝主页的输入框 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')) )#通过css 选择器找到淘宝主页的搜索按钮 input.send_keys('美食')#向输入框中输入美食 submit.click()#点击搜索按钮 total = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')) )#找到美食界面中所有的页数 get_product() return total.text#返回总页数 except TimeoutException: return serach()#如果没有成功则重新请求
请求成功后,我们需要来解析网页中商品的信息:
def get_product(): wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))#加载找到的本页中所有的商品 html=browser.page_source doc=pq(html) items = doc('#mainsrp-itemlist .items .item').items()#找到本页中商品的列表 for item in items: product = { 'image':item.find('.pic .img').attr('src'),#获取class为pic下的class为.img的src属性,也就是图片链接 'price':item.find('.price').text(),#获取class为priced的文本,也就是价格 'deal':item.find('.deal-cnt').text()[:-3],#获取class为deal-cnt的文本的倒数第三个之前的文本,也就是成交量(多少人付款) 'title':item.find('.title').text(),#获取商品的名称 'shop':item.find('.shop').text(),#获取商品的店铺名称 'location':item.find('.location').text()#获取商品的产地 } save_mongodb(product)
现在我们只获取了一页的内容,我们需要获取全部的内容,有两种办法:
第一种:selenium自动点击下一页,但是该方法的缺点就是,如果改页没有加载成功,我们就爬取不到改页的内容,无法判断是否爬取了这页
第二种:循环,自动输入需要跳转的下一页的页码,通过判断输入的内容和当前页码是否一致判断是否成功加载了本页,我们采用第二种方法。

def next_page(current_page): try: input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input')) )#获取输入下一页的页码的输入框 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')) )#获取确定按钮 input.clear()#先清空输入框的内容 input.send_keys(current_page)#在输入框中输入请求的页码 submit.click()#点击确定 wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(current_page))) # 判断请求的页码是否等于当前页,如果等于说明加载成功 get_product() except TimeoutException: return next_page(current_page)# 如果失败则重新加载本页
然后我们还可以将数据保存在mongdb中,下面是全部代码:
import re import pymongo from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from pyquery import PyQuery as pq from config import * browser = webdriver.Chrome() wait=WebDriverWait(browser,10) client=pymongo.MongoClient(MONGO_URL) db=client[MONGO_DB] browser.set_window_size(1400,900) def serach(): try: browser.get('https://www.taobao.com') input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'#q')) )#通过css 选择器找到淘宝主页的输入框 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')) )#通过css 选择器找到淘宝主页的搜索按钮 input.send_keys('美食')#向输入框中输入美食 submit.click()#点击搜索按钮 total = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')) )#找到美食界面中所有的页数 get_product() return total.text#返回总页数 except TimeoutException: return serach()#如果没有成功则重新请求 def next_page(current_page): try: input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input')) ) submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')) ) input.clear() input.send_keys(current_page) submit.click() wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(current_page))) get_product() except TimeoutException: return next_page(current_page) def get_product(): wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))#加载找到的本页中所有的商品 html=browser.page_source doc=pq(html) items = doc('#mainsrp-itemlist .items .item').items()#找到本页中商品的列表 for item in items: product = { 'image':item.find('.pic .img').attr('src'),#获取class为pic下的class为.img的src属性,也就是图片链接 'price':item.find('.price').text(),#获取class为priced的文本,也就是价格 'deal':item.find('.deal-cnt').text()[:-3],#获取class为deal-cnt的文本的倒数第三个之前的文本,也就是成交量(多少人付款) 'title':item.find('.title').text(),#获取商品的名称 'shop':item.find('.shop').text(),#获取商品的店铺名称 'location':item.find('.location').text()#获取商品的产地 } save_mongodb(product) def save_mongodb(result): try: if db[MONGO_TABLE].insert(result): print('保存到MongoDb成功!',result) except Exception: print('存储失败!') def main(): try: total=serach() total=int(re.compile('(\d+)').search(total).group(1)) for i in range(2,10): next_page(i) except Exception: print('出错了') finally: browser.close() if __name__ == '__main__': main()
新建config.py文件:
MONGO_URL='localhost' MONGO_DB='taobao' MONGO_TABLE='meishi'
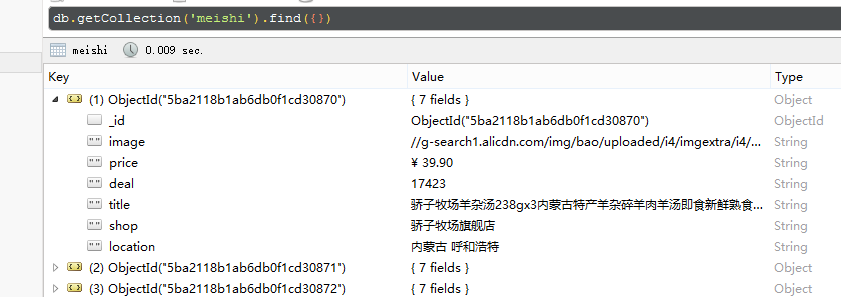
下面就是在MongoDB中的商品信息了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号