探索ByteBuffer底层实现
前言
由于最近在了解IO相关知识,而正好看到了nio,这是我以前从来没接触过的,虽然它很早就出现了,所以先来看看有关于它的一些基础。探索ByteBuffer源代码是基于JDK1.8版本的,ByteBuffer的父类是Buffer,通过阅读注释后对Buffer总结如下:
缓冲区是特定基本类型的元素的线性有限序列,除了内容之外,缓冲区的基本属性还包括
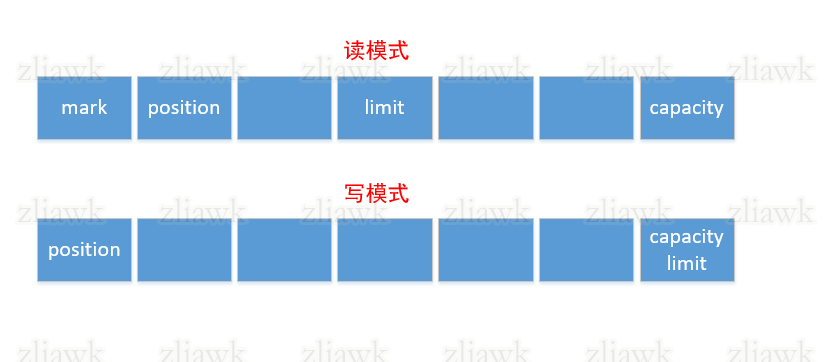
capacity、limit、position、mark。假设缓冲区是一本1000页的书籍,你已经看到800页了,其中在500页处有个很重要的知识点,你做了个标记以便下次能够轻松找到它。那么capacity指代的就是1000,意思就是这本书的最大页数,缓冲区的最大容量,该属性值不会为负不会改变;limit指代的是800,意思是目前只学了这么多知识,可以理解为界限;position指代的是具体某一页,也就是你每看一页,position就会有所增加;mark很容易理解,指代的是我们标记到具体某一页。在实际代码中有读、写模式,我们将读模式比喻成复习,也就是说你可以从第0页复习到第800页,此时的postion从0-800,limit保持800不变,也可以从你所标记的点到第800页,此时的position从mark-800,但是切记不能从第0页复习而后直接跳到mark处,这样子就导致知识点的不连续性,简单来说0 <= mark <= posiiton <= limit <= capacity;将写模式比喻成继续学习新知识点,也就是从第801页继续往后看,position会逐步增加。对于只读缓冲区来说,不允许修改它的内容,但是limit、position、mark是可以变化的。最后一点是缓冲区属于非线程安全!
提供一张图片方便理解。接下来在总结下ByteBuffer,以便对其有个大概性的了解。
字节缓冲区,可创建视图缓冲区,视图缓冲区指的是包含其他基本类型值的缓冲区,如CharBuffer,视图缓冲区的索引不是以字节为单位,而是根据其值的特定类型的大小决定的,如CharBuffer是2个字节。字节缓冲区可分为直接或间接,直接缓冲区的内容存放在堆外内存,JVM将尽最大努力直接执行原生IO操作,而间接缓冲区存放在堆内存中,交由JVM操作,与操作系统并未直接交互,直接缓冲区通常比间接缓冲区具有更高的分配和释放成本,简单来说,对于大型缓冲区来说直接分配直接缓冲区。
概念性的内容就阐述到这里了,接着就直接进入源码世界吧!
数据结构
由于ByteBuffer是个抽象类,故方法可能涉及到多个类,先贴一张继承结构类图。

// 抽象类没办法直接创建该对象
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
// 存储缓冲区的内容
final byte[] hb;
// 缓冲区的第一个元素在hb数组中索引
final int offset;
// 缓冲区是否是只读缓冲区
boolean isReadOnly;
// 缓冲区的字节顺序
boolean bigEndian = true;
// 该属性定义在Buffer中,标记缓冲区中的某个位置 mark <= position
private int mark = -1;
// 该属性定义在Buffer中,代表缓冲区中下一个读取或写入的元素的索引 position <= limit
private int position = 0;
// 该属性定义在Buffer中,代表着界限,该值在写模式下等于capacity,读模式下等于position写模式下的索引 limit <= capacity
private int limit;
// 该属性定义在Buffer中,代表着缓冲区的容量
private int capacity;
}
构造函数
/**
* 初始化,设置属性值
* 在初始化之前需要校验这些成员属性是否合法性
* @param mark 标记缓冲区中的某个索引
* @param pos 下一个读取或写入的元素的索引
* @param lim 界限-读模式下等于position写模式下的索引,简单来说就是记住最后写入内容的索引,以便知道读取结束了;写模式下等于capacity,以便知道缓冲区已经写满了,不能再写了
* @param cap 缓冲区的容量
* @param hb 字节数组-存储缓冲区的内容
* @param offset 缓冲区中第一个元素的索引
*/
ByteBuffer(int mark, int pos, int lim, int cap, byte[] hb, int offset) {
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
/**
* 初始化
* @param mark 标记缓冲区中的某个索引
* @param pos 下一个读取或写入的元素的索引
* @param lim 界限-读模式下等于position写模式下的索引,简单来说就是记住最后写入内容的索引,以便知道读取结束了;写模式下等于capacity,以便知道缓冲区已经写满了,不能再写了
* @param cap 缓冲区的容量
*/
ByteBuffer(int mark, int pos, int lim, int cap) {
this(mark, pos, lim, cap, null, 0);
}
/**
* 该构造函数中涉及到的知识点比较多,笔者也是不懂,借助别人分析的文章进行讲解
* 申请堆外内存与设置释放堆外内存机制
* 堆外内存是不受JVM管理,这导致了堆外内存没办法被JVM回收,所以它通过在堆内存中创建对象,当该对象被回收时,会先调用Cleaner#clean,而在该方法中调用了Deallocator#run,这样子就将堆外内存释放了
* 这里涉及到了虚引用的使用,可参考Reference类中的代码,或者看有关文章
* @param cap 要申请的容量
*/
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned(); // 判断是否需要页面对齐,默认是false,何为页面对齐,目前我是不知道有什么用
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap); // 主要用于判断申请的堆外内存是否超过了最大值,这里的代码就不做深入了,要求大概能懂就行了
long base = 0;
try {
base = unsafe.allocateMemory(size); // 申请堆外内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0); // 初始化堆外内存空间为0
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); // 使用Cleaner机制回收堆外内存
att = null;
}
简单方法
/**
* 校验并设置属性
* 由于mark <= position <= limit 所以只要校验mark、position即可
* @param limit 界限值
* @return 当前对象
*/
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
/**
* 校验并设置属性
* 由于mark <= position 所以只要校验mark即可
* @param newPosition 下一个读取或写入的元素的索引
* @return 当前对象
*/
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
/**
* 通过申请堆外内存来构造直接缓冲区
* 当该对象被回收时会出发释放堆外内存
* @param capacity 申请的容量
*/
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
/**
* 构造间接缓冲区
* @param capacity 缓冲区的容量
*/
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity); // 虽然这是另外一个类,实际上挺简单的,所以这里就不做继续阐述了
}
/**
* 构造一个包含指定字节数组的缓冲区
* 若在外部修改该字节数组,对应的缓冲区内容也会变化
* @param arry 指定字节数组
* @param offset 下一个要读取或写入的元素的索引
* @param length 指定写入或读取的元素的长度
* @return 缓冲区
*/
public static ByteBuffer wrap(byte[] array, int offset, int length) {
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
/**
* 构造一个包含指定字节数组的缓冲区
* @param array 指定字节数组
* @return 缓冲区
*/
public static ByteBuffer wrap(byte[] array) {
return wrap(array, 0, array.length);
}
/**
* 构造一个包含从position到limit之间的源缓冲区内容的新缓冲区(HeapByteBuffer)
* 源缓冲区与新缓冲区共享同一个字节数组,两者的属性position、limit、capacity是相互独立的
* 在源缓冲区构建完后它的offset就已经确定下来了,而对于position来说,它会随着读或写不断的变化,但它始终 >= offset,因为offset代表着缓冲区的第一个元素对应到字节数组上的索引
* position相当于它离第一个元素多远,offset + position = 当前读或者写入的元素对应到字节数组上的索引,所以对于新缓冲区来说,它的第一个元素对应到字节数组上的索引就是position + offset,不知道说清楚没有
*
* 0 1 2 3 4 5 6 7 8 9 10
* 假设这是字节数组,1:offset position:3(此时的3并不是指的3索引,而是指定离第一个元素有多远,那么position对应的索引应该是1 + 3 = 4索引)
* 该类中的arrayOffset方法在第一次获取offset值时个人觉得写的不对,就好比我上面已经指定了position的值了,可惜返回的结果并不是我想要的,而在调用完slice完后再次通过arrayOffset获取offset,这次的结果确实正确的,于是我就有点纳闷了
* 况且它的注释已经写的很明白了
*
* @return 新缓冲区,与源缓冲区共享同一个字节数组
*/
public ByteBuffer slice() {
return new HeapByteBuffer(hb, -1, 0, this.remaining(), this.remaining(), this.position() + offset);
}
/**
* 获取缓冲区中剩余元素的数量
* @return 剩余元素的数量
*/
public final int remaining() {
return limit - position;
}
/**
* 获取position的值
* @return position
*/
public final int position() {
return position;
}
/**
* 对于直接缓冲区来说,笔者不敢保证是否共享同一块内存区域,这块的知识点并不是很充裕
* 注释上说,若调用该方法的是个直接缓冲区,那么新缓冲区将是个只读缓冲区
*/
public ByteBuffer slice() {
int pos = this.position();
int lim = this.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
int off = (pos << 0);
assert (off >= 0);
return new DirectByteBuffer(this, -1, 0, rem, rem, off);
}
/**
* 复制源缓冲区,包括其属性position、limit、capacity、offset
* 源缓冲区与新缓冲区共享同一个字节数组
* @return 新缓冲区
*/
public ByteBuffer duplicate() {
return new HeapByteBuffer(hb, this.markValue(), this.position(), this.limit(), this.capacity(), offset);
}
/**
* 注释上说,若调用该方法的是个直接缓冲区,那么新缓冲区将是个只读缓冲区
*/
public ByteBuffer duplicate() {
return new DirectByteBuffer(this, this.markValue(), this.position(), this.limit(), this.capacity(), 0);
}
/**
* 复制源缓冲区,但是不允许新缓冲区修改内容,源缓冲区还是可以继续修改其内容,毕竟它不属于只读
* HeapByteBufferR类中覆写了put方法,调用put方法都将抛出异常
*/
public ByteBuffer asReadOnlyBuffer() {
return new HeapByteBufferR(hb, this.markValue(), this.position(), this.limit(), this.capacity(), offset);
}
/**
* 读取缓冲区中position上的字节
* 缓冲区中position会对应到字节数组中的索引来获取字节
* 调用完该方法后position会自增
*
* 与该方法类似的直接缓冲区的知识点将尽量讲解,不懂的点我不会讲解!!!
*
* @return 字节
*/
public byte get() {
return hb[ix(nextGetIndex())];
}
/**
* 获取下一个读取的元素的索引
* @return 下一个读取的元素的索引
*/
final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
/**
* 获取字节数组上对应的索引
* @param i 对应position
* @return 字节数组上对应的索引
*/
protected int ix(int i) {
return i + offset;
}
/**
* 将指定字节写入到缓冲区中position位置上
* @param x 指定字节
* @return 缓冲区
*/
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
/**
* 获取下一个写入的元素的索引
* @return 下一个写入的元素的索引
*/
final int nextPutIndex() {
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
/**
* 读取缓冲区中指定位置上的字节
* 注意这里并没有修改position的值
* 这里一直称作是指定位置,而不是指定索引,因为该位置并不是字节数组中的索引,而是缓冲区的指定位置对应到字节数组的指定索引
* @param i 指定位置
* @return 指定位置上的字节
*/
public byte get(int i) {
return hb[ix(checkIndex(i))];
}
/**
* 校验指定索引是否超过界限
* @param i 指定位置
* @return 指定位置
*/
final int checkIndex(int i) {
if ((i < 0) || (i >= limit))
throw new IndexOutOfBoundsException();
return i;
}
/**
* 将指定字节写入到缓冲区中指定位置上
* 注意这里并没有修改position的值
* @param i 指定位置
* @param x 指定字节
* @return 缓冲区
*/
public ByteBuffer put(int i, byte x) {
hb[ix(checkIndex(i))] = x;
return this;
}
/**
* 将缓冲区中的剩余元素复制指定数量,从指定字节数组的指定起始索引处开始复制缓冲区的内容
* 校验字节数组的参数是否合法
* 若所需数量大于缓冲区的剩余元素长度,则会抛出异常
* @param dst 指定字节数组
* @param offset 指定起始索引
* @param length 指定数量
* @return 缓冲区
*/
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
dst[i] = get();
return this;
}
/**
* 将缓冲区中的剩余元素复制到指定字节数组
* @param dst 指定字节数组
* @return 缓冲区
*/
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
/**
* 将指定缓冲区的剩余元素复制到当前缓冲区
* 若当前缓冲区是个只读,则抛出异常
* 若当前的缓冲区的剩余元素个数小于指定缓冲区的剩余元素个数,简单来说,就是不够放了,那么抛出异常
* @param src 指定缓冲区
* @return 缓冲区
*/
public ByteBuffer put(ByteBuffer src) {
if (src == this)
throw new IllegalArgumentException();
if (isReadOnly())
throw new ReadOnlyBufferException();
int n = src.remaining();
if (n > remaining())
throw new BufferOverflowException();
for (int i = 0; i < n; i++)
put(src.get());
return this;
}
/**
* 从指定字节数组的指定起始位置开始遍历指定数量,将遍历后的元素复制到缓冲区中
* @param src 指定字节数组
* @param offset 指定起始索引
* @param length 指定数量
* @return 缓冲区
*/
public ByteBuffer put(byte[] src, int offset, int length) {
checkBounds(offset, length, src.length);
if (length > remaining())
throw new BufferOverflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
this.put(src[i]);
return this;
}
/**
* 将字节数组的内容复制到缓冲区中
* @param src 指定字节数组
* @return 缓冲区
*/
public final ByteBuffer put(byte[] src) {
return put(src, 0, src.length);
}
/**
* 是否是可访问数组(缓冲区),代表非只读缓冲区已初始化
* @return 是否是可访问数组(缓冲区)
*/
public final boolean hasArray() {
return (hb != null) && !isReadOnly;
}
/**
* 获取字节数组
* 若修改缓冲区的内容,则返回的字节数组的内容也将跟着变化
* @return 字节数组
*/
public final byte[] array() {
if (hb == null)
throw new UnsupportedOperationException();
if (isReadOnly)
throw new ReadOnlyBufferException();
return hb;
}
/**
* 获取缓冲区的第一个元素对应到字节数组中的索引
* @return 索引
*/
public final int arrayOffset() {
if (hb == null)
throw new UnsupportedOperationException();
if (isReadOnly)
throw new ReadOnlyBufferException();
return offset;
}
/**
* 将缓冲区的剩余元素拷贝到缓冲区的起始位置
* postion上的字节被拷贝到索引0上
* 该方法最好在缓冲区写完数据后调用,防止数据不完整
* positions设置到limit,limit设置到capacity,mark = -1
*
* buf.clear();
* while (in.read(buf) >= 0 || buf.position != 0) { // in.read(buf):从channel读取数据到buf中 channel -> buf
* buf.flip(); // 将limit设置到position, position = 0 实际上就是将写模式切换到读模式,一般在写完后要开始读取数据了调用
* out.write(buf); // 将buf中的数据写入到channel中 buf -> channel
* buf.compact(); // In case of partial write
* }
*
* @return 缓冲区
*/
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark(); //mark = -1
return this;
}
/**
* 是否是直接缓冲区
* @return 是否是直接缓冲区
*/
public boolean isDirect() {
return false;
}
/**
* 比较两个缓冲区的剩余元素是否完全相同
* 若有一处不同则直接返回结果
* @param that 另一个缓冲区
* @return 比较结果
*/
public int compareTo(ByteBuffer that) {
int n = this.position() + Math.min(this.remaining(), that.remaining());
for (int i = this.position(), j = that.position(); i < n; i++, j++) {
int cmp = compare(this.get(i), that.get(j));
if (cmp != 0)
return cmp;
}
return this.remaining() - that.remaining();
}
/**
* 获取缓冲区的字节顺序,默认是高位优先
* 不同的机器可能会使用不同的字节排序方法来存储数据
* 高位优先:高位字节存放在内存的低地址,低位字节存放在高地址
* 低位优先:低位字节存放在内存的高地址,高位字节存放在低地址
* 对于不同的基本类型的位数是不一样的
* 高位 低位
* 0001 1111
* 低地址 -----> 高地址
*
* @return 代表字节顺序的对象
*/
public final ByteOrder order() {
return bigEndian ? ByteOrder.BIG_ENDIAN : ByteOrder.LITTLE_ENDIAN;
}
/**
* 修改缓冲区的字节顺序
*/
public final ByteBuffer order(ByteOrder bo) {
bigEndian = (bo == ByteOrder.BIG_ENDIAN);
nativeByteOrder = (bigEndian == (Bits.byteOrder() == ByteOrder.BIG_ENDIAN));
return this;
}
/**
* 读取缓冲区的position与position对应的字节,根据当前字节顺序将两个字节组成一个char值,然后将position + 2
* 因为char类型是占用两个字节, 所以会将两个字节变成1个char类型
*
* | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 97 | bytes
* | | | | a | chars
* | 0 | 0 | 0 | 97 | shorts
* | 0 | 97 | ints
* 以此类推....
* @return char值
*/
public char getChar() {
return Bits.getChar(this, ix(nextGetIndex(2)), bigEndian);
}
/**
* 将指定char值写入到缓冲区中指定位置上
* 由于char占用两个字节,分为高位与低位,根据缓冲区中字节的顺序进行存储,默认情况是将高位存储在低地址,低位存储在高地址
* 最终position会加2
* @param x 指定char值
* @return 缓冲区
*/
public ByteBuffer putChar(char x) {
Bits.putChar(this, ix(nextPutIndex(2)), x, bigEndian);
return this;
}
/**
* 读取缓冲区中指定位置上的char值
* 注意这里并没有修改position的值
* char值占用两个字节,所以会将position与position + 1上的字节进行组合,position放在高位、position + 1放在低位
* 这里一直称作是指定位置,而不是指定索引,因为该位置并不是字节数组中的索引,而是缓冲区的指定位置对应到字节数组的指定索引
* @param i 指定位置
* @return 指定位置上的char值
*/
public char getChar(int i) {
return Bits.getChar(this, ix(checkIndex(i, 2)), bigEndian);
}
/**
* 将指定char值写入到缓冲区中指定位置上
* 注意这里并没有修改position的值
* char值可分成高低位,根据缓冲区中的字节顺序进行存放,默认情况下将高位存储在低地址,低位存储在高地址
* @param i 指定位置
* @param x 指定char值
* @return 缓冲区
*/
public ByteBuffer putChar(int i, char x) {
Bits.putChar(this, ix(checkIndex(i, 2)), x, bigEndian);
return this;
}
/**
* 将字节缓冲区转换成字符缓冲区
* 实际上内部还是通过字节缓冲区来操作,由于char占用两个字节,所以该对象对应的position、limit、capacity可能都会/2
* @return 字符缓冲区
*/
public CharBuffer asCharBuffer() {
int size = this.remaining() >> 1;
int off = offset + position();
return (bigEndian ? (CharBuffer)(new ByteBufferAsCharBufferB(this, -1, 0, size, size, off)) : (CharBuffer)(new ByteBufferAsCharBufferL(this, -1, 0, size, size, off)));
}
// 对于转换成其他类型,如short、int、float、double都是一样的道理,就不在做展示了
/**
* 相当于从写模式切换到读模式
* @return 缓冲区
*/
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
/**
* 是否缓冲区中还有剩余元素
* 要么是写满缓冲区、要么是缓冲区的内容读完了
* @return 缓冲区是否还有剩余元素
*/
public final boolean hasRemaining() {
return position < limit;
}
/**
* 重新读取/写入缓冲区
* 可重复读取缓冲区的内容,可重复写入来覆盖缓冲区的内容
* @return 缓冲区
*/
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
总结
-
缓冲区的基本属性有position、limit、capacity、mark,这些属性必须满足
0 <= mark <= posiiton <= limit <= capacity。 -
可创建视图缓冲区,视图缓冲区指的是包含其他基本类型值的缓冲区,省去了类型转换的麻烦。但是千万记住视图缓冲区的索引不是以字节为单位,而是根据其值的特定类型的大小决定的。
-
直接缓冲区建议还是了解下,不过本文没有讲的很详细,笔者能力有限。
-
高低位、高地址、低地址,缓冲区的字节顺序。
-
compact:将缓冲区的剩余元素拷贝到缓冲区的起始位置,修改position = limit,limit = capacity。
-
slice:构造一个包含从position到limit之间的源缓冲区内容的新缓冲区,源缓冲区与新缓冲区共享同一个字节数组,但两者的基本属性是相互的独立。
-
duplicate:复制源缓冲区的内容构造一个新缓冲区,包括复制基本属性,两个缓冲区共享同一个字节数组。
重点关注
基本属性 compact、slice、duplicate

 浙公网安备 33010602011771号
浙公网安备 33010602011771号