


[大数据技术]Kettle对 前程无忧软件相关职位 进行数据清洗
爬虫代码参考:https://www.cnblogs.com/zlc364624/p/12377019.html
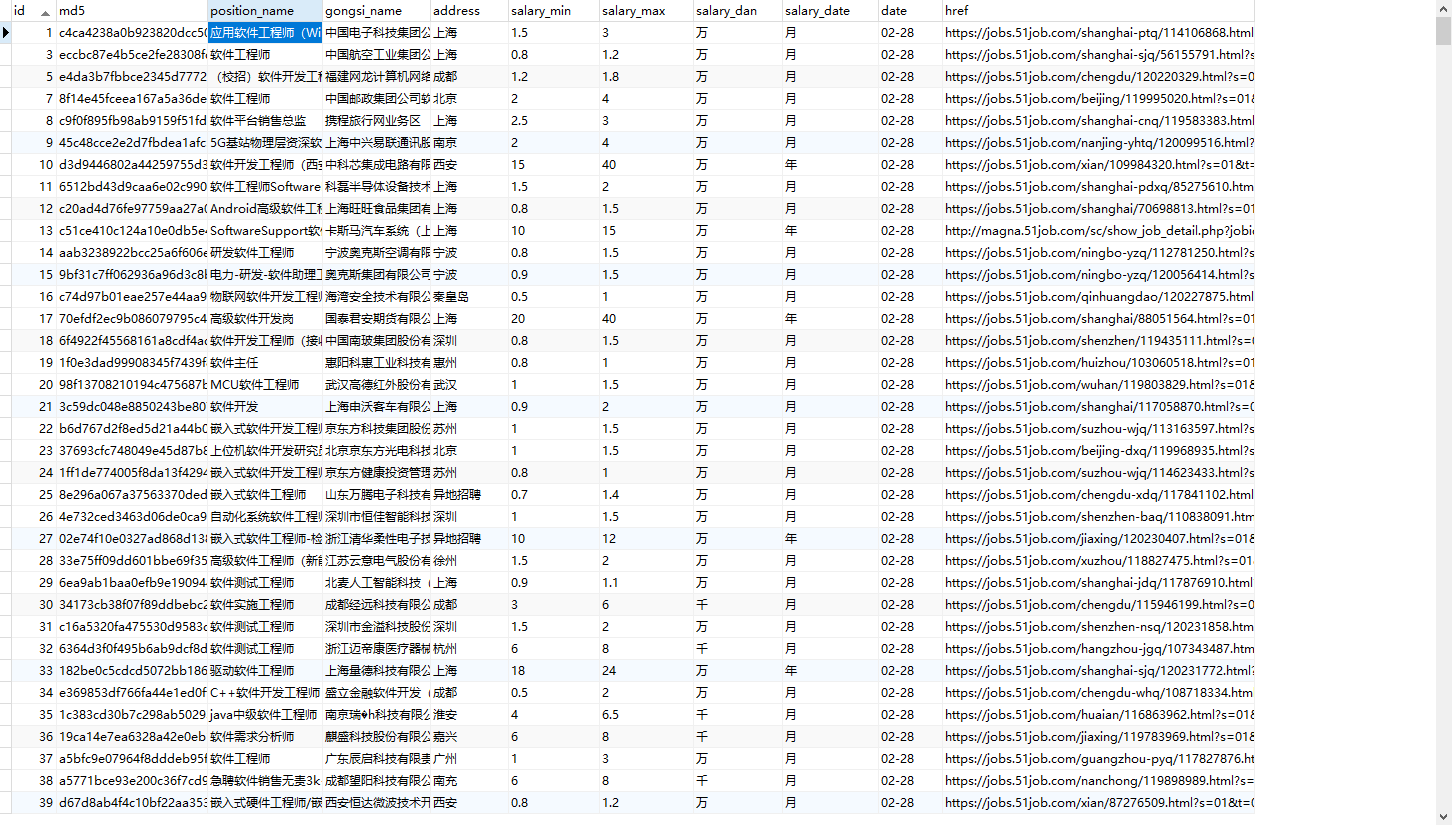
1、原始数据格式
爬取格式如下图:

用空格隔开,数据属性分别为 名称、公司名称、地址、薪酬、日期、网址
2、数据清洗
数据清洗的所有步骤

分为以下几步:
- 在表输入中去除存在null的记录。原因是含有null的脏数据进行数据处理容易出错。
- 增加校验列,进行排序,并且去除重复记录。
- 将例如 2-4万/月 切分为四个属性值 最低薪资:2 最高薪资:4 单位:万 时长:月 。
- 利用过滤记录再去除处理后含null的记录。
- 将 北京-朝阳区 处理为 北京 容易进行处理
3、处理结果
处理后可以较为方便的进行数据统计与结果分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号