
[Python]爬取 游民星空网站 每周精选壁纸(1080高清壁纸) 网络爬虫
一、检查
首先进入该网站的https://www.gamersky.com/robots.txt页面
给出提示:

弹出错误页面
注:
- 网络爬虫:自动或人工识别robots.txt,再进行内容爬取
- 约束性:robots协议建议但非约束性,不遵守可能存在法律风险
如果一个网站不设置robots协议,说明所有内容都可以爬取,所以该网站为可爬取内容。
二、实现
源程序如下:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @File : HtmlParser.py 4 # @Author: 赵路仓 5 # @Date : 2020/2/28 6 # @Desc : 爬取游民星空网站每周精选壁纸 7 # @Contact : 398333404@qq.com 8 9 import requests 10 from bs4 import BeautifulSoup 11 import os 12 import re 13 14 # 网址 15 url = "http://so.gamersky.com/all/news?s=%u58c1%u7eb8%u7cbe%u9009&type=hot&sort=des&p=" 16 # 请求头 17 head = { 18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' 19 } 20 21 22 # 检查是否存在filePath路径的文件夹,若无则创建,若有则不执行 23 def createFile(filePath): 24 if os.path.exists(filePath): 25 print('%s:存在' % filePath) 26 else: 27 try: 28 os.mkdir(filePath) 29 print('新建文件夹:%s' % filePath) 30 except: 31 print("创建文件夹失败!") 32 33 34 # 获取每周壁纸的主题超链接 35 def href(url): 36 try: 37 path = "D:/img" 38 createFile(path) 39 # 清空html_href.txt的内容 40 f_init = open(path + '/html_href.txt', 'w', encoding='utf-8') 41 f_init.write("") 42 f_init.close() 43 f = open(path + '/html_href.txt', 'a+', encoding='utf-8') 44 for i in range(1, 12): 45 r = requests.get(url + str(i)) 46 r.encoding = r.apparent_encoding 47 soup = BeautifulSoup(r.text, 'html.parser') 48 hrefs = soup.find_all("div", {"class": "link"}) 49 for h in hrefs: 50 print(h.string) 51 # 写入txt文件 52 f.write(h.string + '\n') 53 f.close() 54 print("爬取成功!") 55 except: 56 print("爬取壁纸主题失败!") 57 58 59 # 读取html_href(主题地址超链接)并写入img_hef(图片地址) 60 def read(): 61 try: 62 path = "D:/img" 63 f_read = open(path + '/html_href.txt', 'r+', encoding='utf-8') 64 # 清空img_href.txt的内容 65 f_init = open(path + '/img_href.txt', 'w', encoding='utf-8') 66 f_init.write("") 67 f_init.close() 68 # 读取txt文件内容 69 f_writer = open(path + '/img_href.txt', 'a+', encoding='utf-8') 70 number=1 71 for line in f_read: 72 try: 73 line = line.rstrip("\n") 74 r = requests.get(line, headers=head, timeout=3) 75 soup = BeautifulSoup(r.text, 'html.parser') 76 imgs = soup.find_all("p", {"align": "center"}) 77 try: 78 for i in imgs: 79 print(re.sub(r'http.*shtml.', '', i.find("a").attrs['href'])+" 当前第"+str(number)+"张图片!") 80 f_writer.write(re.sub(r'http.*shtml.', '', i.find("a").attrs['href']) + '\n') 81 number+=1 82 except: 83 print("图片地址出错!") 84 except: 85 print("超链接出错!") 86 f_read.close() 87 f_writer.close() 88 print("共有"+str(number)+"个图片地址!") 89 except: 90 print("读取html_href并写入img_href过程失败!!") 91 92 93 def save_img(): 94 path = "D:/img/" 95 img_path="D:/img/images/" 96 createFile(path) 97 f_read = open(path + 'img_href.txt', 'r+', encoding='utf-8') 98 number = 1 99 for line in f_read: 100 try: 101 line = line.rstrip("\n") 102 # 根据个数顺序重命名名称 103 f_write = open(img_path + str(number) + '.jpg', 'wb') 104 r = requests.get(line) 105 # 打印状态码 106 print(r.status_code) 107 # 如果图片地址有效则下载图片状态码200,否则跳过。 108 if r.status_code == 200: 109 f_write.write(r.content) 110 # 若保存成功,则命名顺序+1 111 number += 1 112 print("当前保存第" + str(number) + "张图片。") 113 f_write.close() 114 except: 115 print("下载图片出错!!") 116 f_read.close() 117 118 119 120 if __name__ == "__main__": 121 href(url) 122 read() 123 save_img() 124 # 测试下载图片↓ 125 # save_img("https://img1.gamersky.com/image2019/04/20190427_ljt_red_220_3/gamersky_001origin_001_201942716489B7.jpg","D:/img/1.jpg")
路径无需改动,但有需求可自行更改。
在爬取过程中,在游民星空网站的壁纸栏是通过js跳转,页面不翻页的模式,但后来可以通过搜索——壁纸到达如下界面:
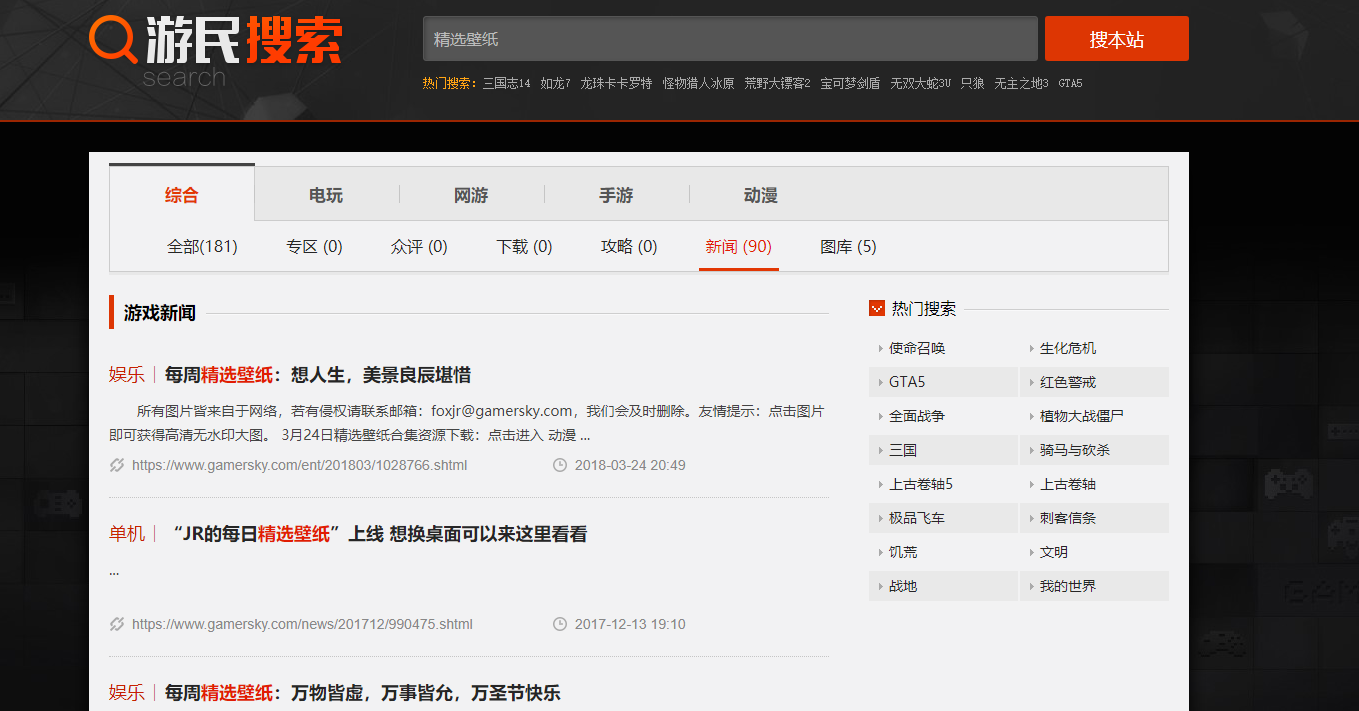
三、实现步骤
- 然后通过 href(url) 函数爬取每周的大标题写入 html_href.txt 中
- 通过 read() 读取写入的标题超链接,将爬取的图片地址写入 img_href.txt 中。
- 最后一步,通过 save_img() 函数读取图片地址,下载壁纸图片。
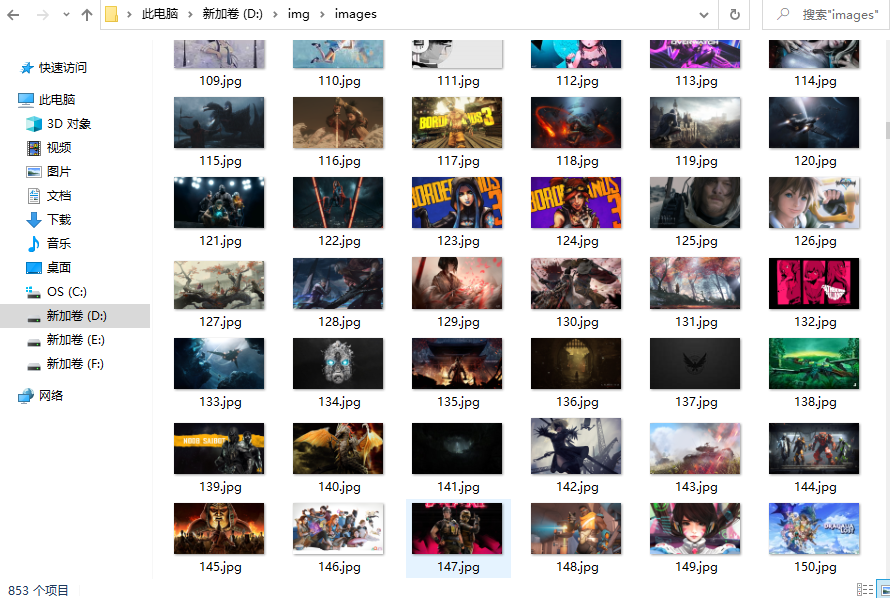
四、效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号