


假期学习【三】HDFS操作及spark的安装/使用
1.安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完
成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装 Spark(Local 模式)。
2.HDFS 常用操作
使用 hadoop 用户名登录进入 Linux 系统,启动 Hadoop,参照相关 Hadoop 书籍或网络
资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS 操作常用 Shell 命令”,
使用 Hadoop 提供的 Shell 命令完成如下操作:
(1) 启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件
test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”
目录下;
进入/home/hadoop目录,并创建test.txt文件

输入内容
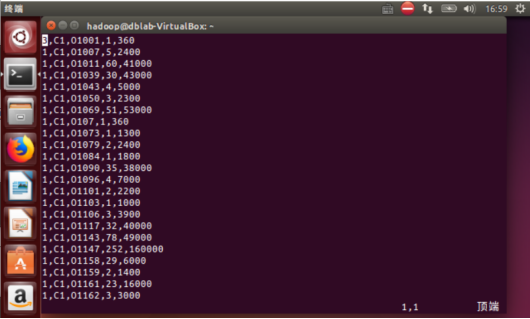
将文件上传到HDFS的/user/hadoop目录下,并查看。

可以发现已经上传成功
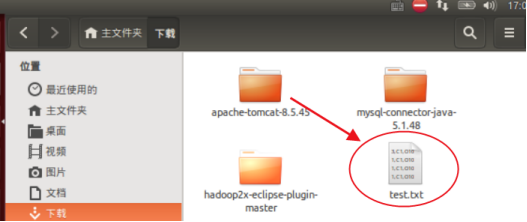
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文
件系统中的“/home/hadoop/下载”目录下;
执行如下命令。

可以查看到已经下载到本地。
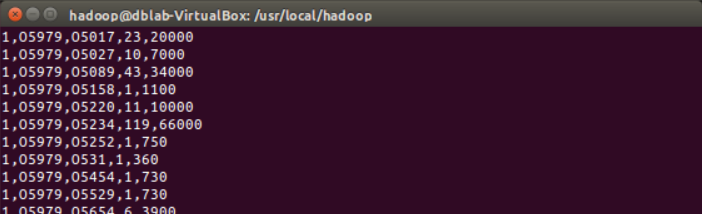
(4) 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
执行如下命令

可以显示
(5) 在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中
“/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;

(6) 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”
目录下的 input 子目录及其子目录下的所有内容。

3. Spark 读取文件系统的数据
Spark安装
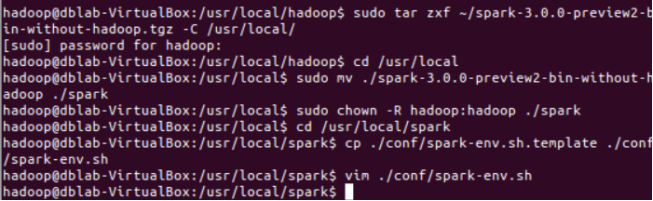
在Spark官网:http://spark.apache.org/downloads.html 下载Spark
并在修改Spark的配置文件spark-env.sh添加输入下列命令:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
如图:

测试输入图中命令将输出大量信息
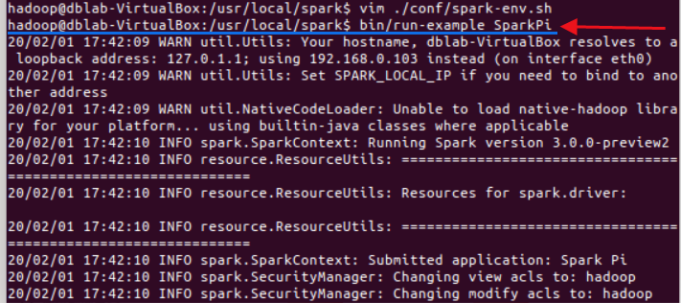

将得到一个π的近似数,说明安装成功
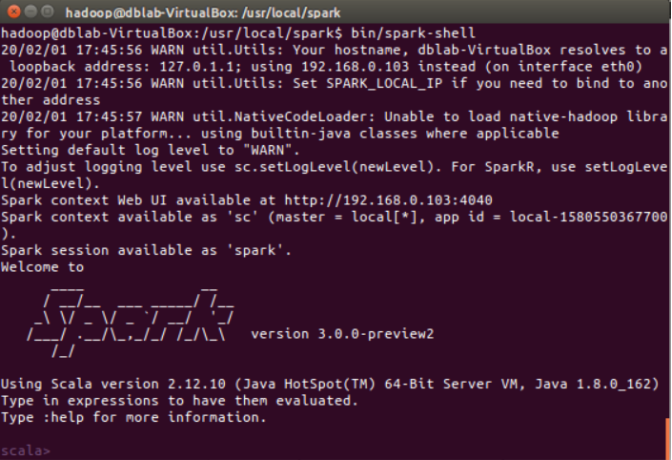
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
启动spark-shell
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;
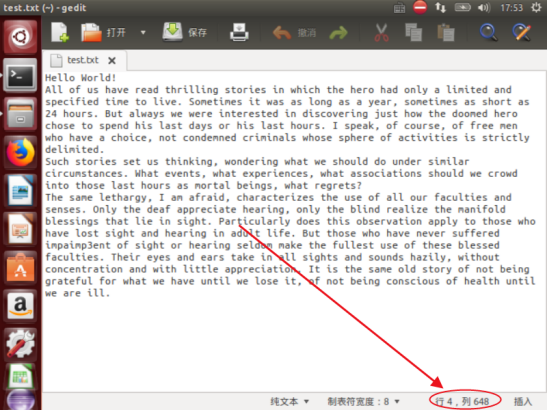
统计结果

未理解的问题:
显示4行正确,但不理解为什么界面行数大于统计的行数。
(3)编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,
并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
1.安装sbt


 浙公网安备 33010602011771号
浙公网安备 33010602011771号