MapReduce-分布式计算引擎
MapReduce概述
1、源自google的MapReduce论文,论文发表于2004.12
2、Hadoop MapReduce是google MapReduce的克隆版
3、MapReduce优点:海量数据离线处理&易开发&易运行(易开发和易运行只是相对而言)
4、MapReduce缺点:实时流式计算
实时:mapreduce的作业都是通过进程方式启动,必然速度会慢很多,
不可能实时的把数据处理完,无法像MySQL一样,在毫秒级或者秒级内返回结果
流式:MapReduce的输入数据集是静态的,不能动态变化;
MapReduce自身的设计特点决定了数据源必须是静态的。
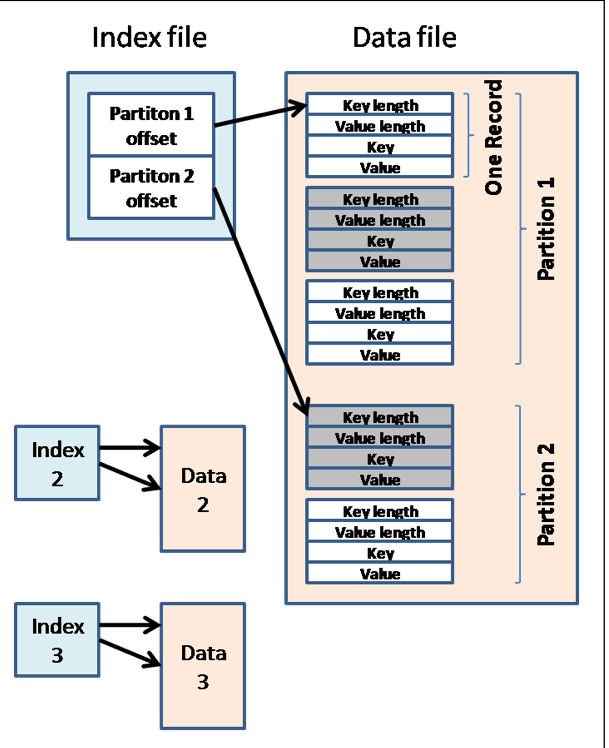
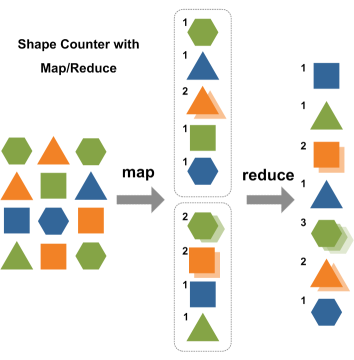
MapReduce编程模型之通过wordcount词频统计分析案例初步认识 MapReduce
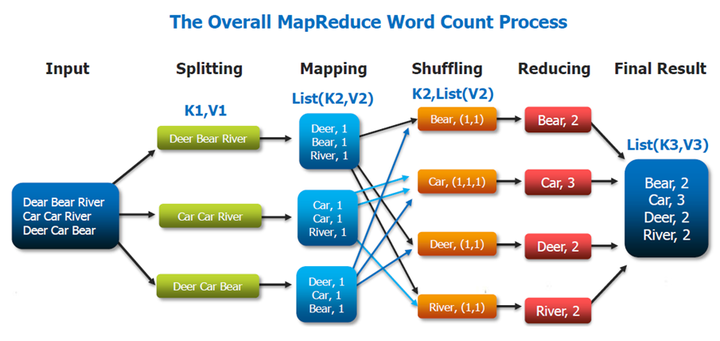
上图就是词频分析的流程图。
① 把一个文件进行拆分,如上图,把文件拆分为三段。
② 然后我们有三个作业对应三段文件并行进行处理。
③ 接着就到了如图mapping,那什么是mapping?就是把每一段文本再按照单词进行拆分。
④ 然后就到了至关重要的一步,shuffling,这是影响分布式计算框架性能的一个瓶颈,
因为我们假设数据在不同机器上运行,我们进行mapping之后,要把相同数据分到同
一个节点上去合并,这样才能统计出来最终结果。
⑤ 我们在shuffling这一步做完之后要做的就是reduce了,reduce干的事情就是把我们
shuffling之后的相同单词的个数加起来。
总结:这整个过程其实就是一个分而治之的思想!我们先把原始数据比如那一小段文本
给他拆开(spliting),拆开之后分开处理到一定程度(mapping&shuffling),
然后再合并到一起做最终计算(reduce)!最终输出到hdfs中去,这样子就得到
final result这个结果
MapReduce编程模型之执行步骤------简述
准备map处理的输入数据并对其进行splitting
对于输入的数据,会被转换成一堆的key,value,那么这里的key,value
到底指的是什么呢?以上图来看,输入数据为三段文字,key就是指偏移量,
读取第一行,k1=0,v1=第一行内容,读取第二行,k1=第一行内容长度。
v1=第二行内容
mapper处理
这里同样也是key,value,经过之前的数据准备,到map这一步以上一步
splitting的数量为基准以相互独立的并行方式执行,把上一步的value拆分为以单词为
k2,出现次数为v2的形式。
shuffle处理
这里同样在上一步基础之上,首先把相同数据放到同一个节点上去合并,比如上图,
以单词名为k2,以这个单词每次出现的计数1为v2,比如Car出现3次,那就是k2=3,
v2=(1,1,1)
reduce处理
将shuffling之后得到的k2和v2进行最终处理,把v2中的所有计数相加得到单词出现的总数
即k2=Car,v2=3
结果输出
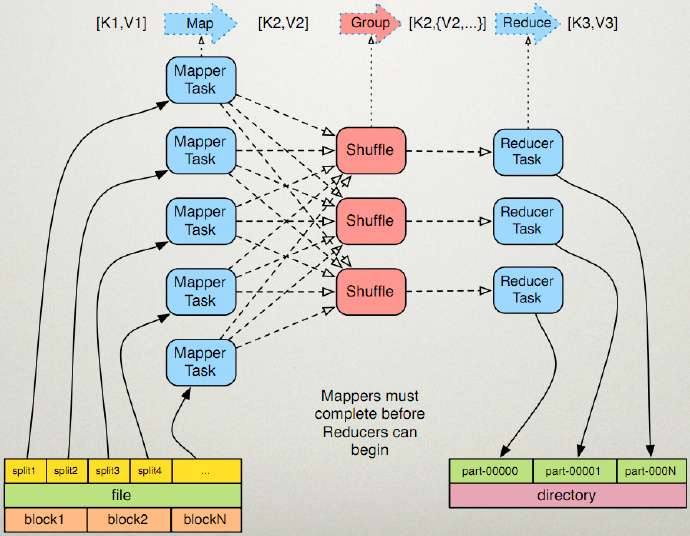
MapReduce编程模型之执行步骤------详解
假设有两个Node

---------------------------Map阶段-------------------------
①对数据进行InputFormat-->split(如图),那么什么是InputFormat-->split?
InputFormat:这是一个接口包含了很多执行程序,我们以InputFormat里面的
FileInputFormat为例,这是读取文件基本的类,这仍然是个抽象类,继续选择
FileInputFormat中的TextInputFormat,这是用来读文本的类,这里面有几个关键的方法
我们需要了解一下,一个是getsplits方法,用途是把我们的输入文件得到很多个split,
每一个split交由相对应的一个MapTask来处理,getsplits方法的返回值是一个InputSplit[ ]
数组,也就是说一个文件可能会被拆分成好多个InputSplit。
另一个是getRecordReader方法,从这个名字我们看的出来,他是一个记录的读取者,
它就是把上面getsplits方法得到的InputSplit[ ]数组中每一个数据给读进来,那么我们以后就
知道每一个行是什么数据了。所以这一步主要就是借助InputFormat中的TextInputFormat
这个类来将文件进行拆分。
② 对split之后的数据进行RR(RecordReader)
这里就是接着上一步,通过InputFormat中的TextInputFormat这个类得到InputSplit数组
然后由RecordReader的getRecordReader方法来读取InputSplit数组中的每一个数据,
并且每读取一份数据交由一个map来处理(并行处理)。
③由getRecordReader 这个方法读取的数据后交给map执行关键步骤之一MapTask
实际包含了输入(input)过程、切分(partition)过程、溢写spill过程(sort和combine过程)、
merge过程。
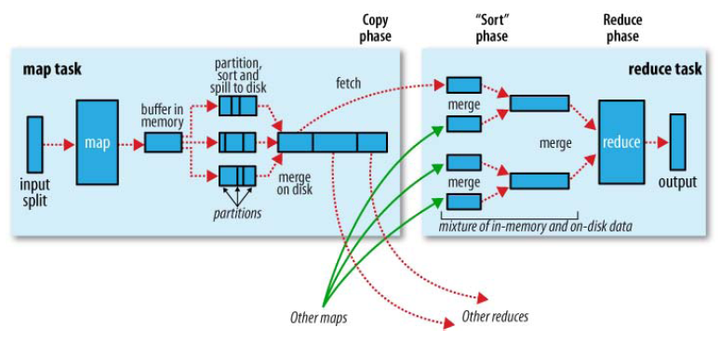
- 对每一个键值对进行map()
- map的输出保存在内存缓冲区,当缓冲区满80%(一般80%),启动溢写,将缓冲的数据写出到磁盘。
- 在溢写的结尾,合并所有的输出,并且打包他们以便进行reduce处理。
No.1 map
在mapper中,用户定义的map代码通过处理record reader解析的每个key/value来产生0
个或多个新的key/value结果。key/value的选择对MapReduce作业的完成效率来说非常重
要。key是数据在reducer中处理时被分组的依据,value是reducer需要分析的数据。
No.2 combine
1)combine简述
combiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看见
WordCount类里是用reduce进行加载的。Combiner是一个本地化的reduce操作,它是
map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操
作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就
会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很
多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了
宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,
Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景
才能使用Combiner呢?Combiner的输出是Reducer的输入,Combiner绝不能改变最终的
计算结果。所以combiner操作是有风险的,使用它的原则是combiner的输入不会影响到
reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用
combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
2)combine具体操作
combine分为map端的combine和reduce端的combine,combine将有相同key的key/value
对的value加起来,减少溢写到磁盘的数据量,combine函数把map函数产生的多个
key/value合并成一 个新的key2/value2,将新的key2/value2作为输入值给reduce函数,
这个value2有多个。实际上combine操作作用就相当于reduce,把mapper端的key,[value,
…]先处理,变成<key, [value1]>(如<a, [1, 1, 1]> => <a, 3>), 这样能有效减少最后写入磁
盘文件的大小,网络需要传输的大小更少,因此更快。
具体实现是由Combine类。 实现combine函数,该类的主要功能是合并相同的key,通过
job.setCombinerClass()方法设置,默认为null,不合并中间结果。
map端的combine和MapReduce中的reduce的区别:
在mapreduce中,map多,reduce少。 在reduce中由于数据量比较多,所以先把map
里面的数据合并归类,这样到了reduce的时候就减轻了压力。
举个例子:
map理解为销售人员,reduce理解为销售经理。
每个人(map)只管销售,赚了多少钱销售人员不统计,也就是说这个销售人员没有
Combine,那么这个销售经理就累垮了,因为每个人都没有统计,它需要统计所有人
员卖了多少件,赚钱了多少钱。这样是不行的,所以销售经理(reduce)为了减轻压
力,每个人(map)都必须统计自己卖了多少钱,赚了多少钱(Combine),然后经
理所做的事情就是统计每个人统计之后的结果。这样经理就轻松多了。所以Combine
在map所做的事情,减轻了reduce的事情。这就是为什么说map的Combine干的是
reduce的事情,有点类似上下级的关系。
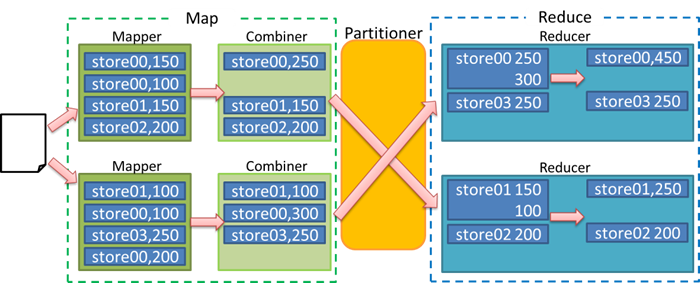
No.3 partitioner
partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定
义的。这里其实可以理解归类。
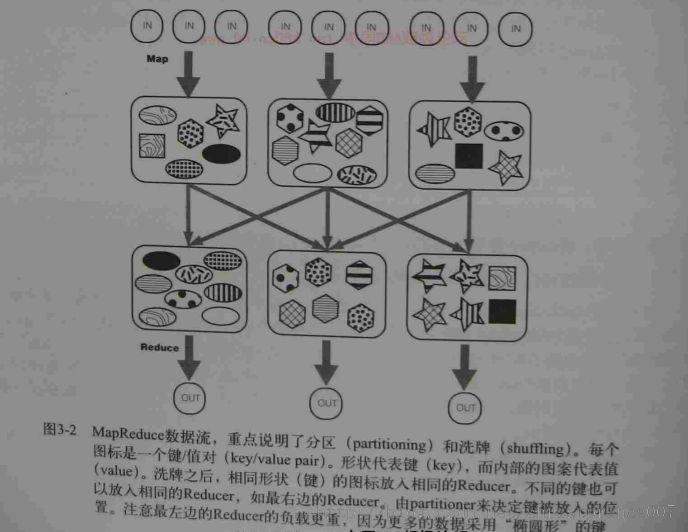
我们对于错综复杂的数据归类。比如在动物园里有牛羊鸡鸭鹅,他们都是混在一起的,
但是到了晚上他们就各自牛回牛棚,羊回羊圈,鸡回鸡窝。partition的作用就是把这些
数据归类。只不过在写程序的时候,mapreduce使用哈希HashPartitioner帮我们归类
了。这个我们也可以自定义。
经过partitioner处理后,每个key-value对都得到分配到的reduecer信息,然后把记录先
写入内存(In-memory buffer)。
内存分配图如下:
内存会划分一个个的partition,每个partition都交个独自一个reduecer处理(总的
partition数目=reducer数量)。
No.3 sort & combiner
1、在partitioner处理时,当写入内存的数据越来越多时当buffer达到一定阀值(默认
80M),就开始执行spill步骤,即分成小文件写入磁盘。在写之前,先对memory中每个
partition进行排序(in-memory sort)。如果数据量大的话,这个步骤会产生很多
个spilled文件,如果我们定义了combine,那么在排序之前还会进行combine,最后一个步
骤就是merge,把溢写(spill)步骤产生的所有spilled files,merge成一个大的已排序文
件。merge是相同的partition之间进行。
MERGE:
Merge是怎样的?如“aaa”从某个map task读取过来时值是5,从另外一个map 读取值是
8,因为它们有相同的key,所以得merge成group。什么是group。对于“aaa”就是像这样
的:{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些
值加起来。请注意,因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的
key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的
key。
---------------------------Reduce阶段-------------------------
在 reduce task 之前,不断拉取当前 job 里每个 maptask 的最终结果,然后对从不同地方拉取
过来的数据不断地做 merge ,也最终形成一个文件作为 reduce task 的输入文件。
总而言之,reduce的运行可以分成copy、merge、reduce三个阶段,下面将具体说明这3个阶
段的详细执行流程。
copy
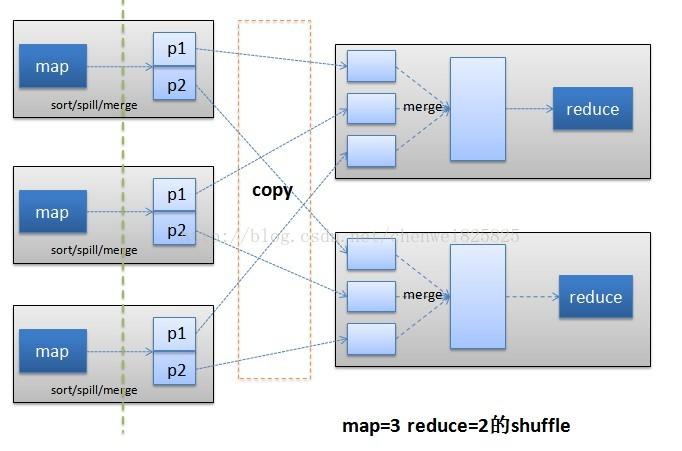
由于job的每一个map都会根据reduce(n)数将数据分成map 输出结果分成n个partition,所以map的中间结果中是有可能包含每一个reduce需要处理的部分数据的。所以,为了优化reduce的执行时间,hadoop中是等job的第一个map结束后,所有的reduce就开始尝试从完成的map中下载该reduce对应的partition部分数据,因此map和reduce是交叉进行的,如下图所示:
educe进程启动数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。由于map通常有许多个,所以对一个reduce来说,下载也可以是并行的从多个map下载,这个并行度是可以通过mapred.reduce.parallel.copies(default 5)调整。默认情况下,每个只会有5个并行的下载线程在从map下数据,如果一个时间段内job完成的map有100个或者更多,那么reduce也最多只能同时下载5个map的数据,所以这个参数比较适合map很多并且完成的比较快的job的情况下调大,有利于reduce更快的获取属于自己部分的数据。
reduce的每一个下载线程在下载某个map数据的时候,有可能因为那个map中间结果所在机器发生错误,或者中间结果的文件丢失,或者网络瞬断等等情况,这样reduce的下载就有可能失败,所以reduce的下载线程并不会无休止的等待下去,当一定时间后下载仍然失败,那么下载线程就会放弃这次下载,并在随后尝试从另外的地方下载(因为这段时间map可能重跑)。reduce下载线程的这个最大的下载时间段是可以通过mapred.reduce.copy.backoff(default 300秒)调整的。如果集群环境的网络本身是瓶颈,那么用户可以通过调大这个参数来避免reduce下载线程被误判为失败的情况。不过在网络环境比较好的情况下,没有必要调整。通常来说专业的集群网络不应该有太大问题,所以这个参数需要调整的情况不多。
merge
这里的merge如map端的merge动作类似,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,然后当使用内存达到一定量的时候才刷入磁盘。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。内存到内存的merge一般不适用,主要是内存到磁盘和磁盘到磁盘的merge。
这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置。这个内存大小的控制就不像map一样可以通过io.sort.mb来设定了,而是通过另外一个参数 mapred.job.shuffle.input.buffer.percent(default 0.7) 来设置, 这个参数其实是一个百分比,意思是说,shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task。
也就是说,如果该reduce task的最大heap使用量(通常通过mapred.child.java.opts来设置,比如设置为-Xmx1024m)的一定比例用来缓存数据。默认情况下,reduce会使用其heapsize的70%来在内存中缓存数据。假设 mapred.job.shuffle.input.buffer.percent为0.7,reduce task的max heapsize为1G,那么用来做下载数据缓存的内存就为大概700MB左右。这700M的内存,跟map端一样,也不是要等到全部写满才会往磁盘刷的,而是当这700M中被使用到了一定的限度(通常是一个百分比),就会开始往磁盘刷(刷磁盘前会先做sort)。这个限度阈值也是可以通过参数 mapred.job.shuffle.merge.percent(default 0.66)来设定。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。这种merge方式一直在运行,直到没有map端的数据时才结束,然后启动磁盘到磁盘的merge方式生成最终的那个文件。
reducer
当reduce将所有的map上对应自己partition的数据下载完成后,就会开始真正的reduce计算阶段。当reduce task真正进入reduce函数的计算阶段的时候,有一个参数也是可以调整reduce的计算行为。也就是mapred.job.reduce.input.buffer.percent(default 0.0)。由于reduce计算时肯定也是需要消耗内存的,而在读取reduce需要的数据时,同样是需要内存作为buffer,这个参数是控制,需要多少的内存百分比来作为reduce读已经sort好的数据的buffer百分比。默认情况下为0,也就是说,默认情况下,reduce是全部从磁盘开始读处理数据。如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,反正reduce的内存闲着也是闲着。
Reduce在这个阶段,框架为已分组的输入数据中的每个 <key, (list of values)>对调用一次 reduce(WritableComparable, Iterator, OutputCollector, Reporter)方法。 Reduce任务的输出通常是通过调用 OutputCollector.collect(WritableComparable, Writable)写入 文件系统的。Reducer的输出是没有排序的。
那么一般需要多少个Reduce呢?
Reduce的数目建议是0.95或1.75乘以 ( * mapred.tasktracker.reduce.tasks.maximum)。 用0.95,所有reduce可以在maps一完成时就立刻启动,开始传输map的输出结果。用1.75,速度快的节点可以在完成第一轮reduce任务后,可以开始第二轮,这样可以得到比较好的负载均衡的效果。
reduces的性能很大程度上受shuffle的性能所影响。应用配置的reduces数量是一个决定性的因素。太多或者太少的reduce都不利于发挥最佳性能: 太少的reduce会使得reduce运行的节点处于过度负载状态,在极端情况下我们见过一个reduce要处理100g的数据。这对于失败恢复有着非常致命的负面影响,因为失败的reduce对作业的影响非常大。太多的reduce对shuffle过程有不利影响。在极端情况下会导致作业的输出都是些小文件,这对NameNode不利,并且会影响接下来要处理这些小文件的mapreduce应用的性能。在大多数情况下,应用应该保证每个reduce处理1-2g数据,最多5-10g。
总结
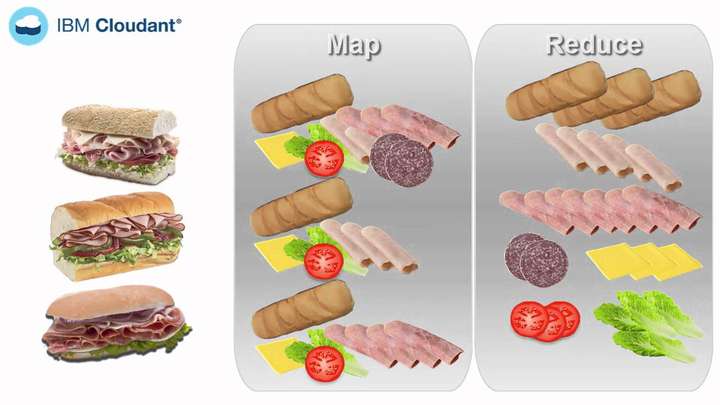
做菜的例子
小红:如何用蔬菜沙拉来解释mapreduce?
小明:Map(映射): 把洋葱、番茄、生菜等等食材切好,这是各自作用在这些物体上的一个Map操作。所以你给Map一个洋葱,Map就会把洋葱切好。 同样的,你把番茄、生菜一一地拿给Map,你也会得到各种切好的块。 所以,当你在切洋葱这样的蔬菜时,你执行就是一个Map操作。 Map操作适用于每一种蔬菜,它会相应地生产出一种或多种碎块,在我们的例子中生产的是蔬菜块。在Map操作中可能会出现有个洋葱坏掉了的情况,你只要把坏洋葱丢了就行了。所以,如果出现坏洋葱了,Map操作就会过滤掉坏洋葱而不会生产出任何的坏洋葱块。
小红:那我们说说的reduce吧
小明:Reduce(化简):在这一阶段,你将各种蔬菜碎都放入盘子/锅里面加入你喜爱的一些佐料和沙拉拌一下,你就可以得到你喜爱的蔬菜沙拉了。这意味要做一盘蔬菜沙拉,你得切好所有的原料。因此,你要将map操作的蔬菜聚集在一起。
小红:那分布式是什么意思?
小明:假设你参加了一个比赛并且你的食谱赢得了最佳蔬菜沙拉奖。得奖之后,你的蔬菜沙拉大受欢迎,于是你想要开始出售自制品牌的蔬菜沙拉。假设你每天需要生产10000份,你会怎么办呢?
小红:我会找一个能为我大量提供原料的供应商。
小明:是的..就是那样的。那你能否独自完成制作呢?也就是说,独自将原料都切碎? 而且现在,我们还需要供应不同种类的蔬菜沙拉,像青菜沙拉、番茄沙拉等等。
小红: 当然不能了,我会租下一间铺子,我会雇佣更多的工人来切蔬菜。这样我就可以更快地生产蔬菜沙拉了。
小明:没错,所以现在你就不得不分配工作了,你将需要几个人一起切蔬菜。每个人都要处理满满一袋的蔬菜,而每一个人都相当于在执行一个简单的Map操作。每一个人都将不断的从袋子里拿出蔬菜来,并且每次只对一种蔬菜进行处理,也就是将它们切碎,直到袋子空了为止。
这样,当所有的工人都切完以后,工作台(每个人工作的地方)上就有了洋葱块、番茄块等等。
小红:但是我怎么会制造出不同种类的蔬菜沙拉呢?
我:现在你会看到MapReduce遗漏的阶段—搅拌阶段。MapReduce将所有输出的蔬菜片都搅拌在了一起,这些蔬菜片都是在以key为基础的 map操作下产生的。搅拌将自动完成,你可以假设key是一种原料的名字,就像洋葱一样。 所以全部的洋葱keys都会搅拌在一起,并转移到同一个盘子。这样,你就能得到洋葱沙拉了。同样地,所有的番茄也会被转移到标记着番茄的盘子里,并制造出番茄沙拉。
小红:我终于明白mapreduce干的活了!
统计图书的例子
map
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes.
reduce
Now we get together and add our individual counts. That’s reduce.
结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号