改进一致性hash算法
1 最常见的hash算法:
value = hash(key), value是一个32位的数据。
假设开始存储数据的server有N个,数据需要均匀的存放在这N个节点上。可以简单的通过value %(N + 1)来决定这个值存放在哪个server上。如下图所示:

数据会均匀的分布在N个server上,但是这种结构碰到一个节点挂了会是一个什么过程呢?

这个时候所有的数据都会重新hash,再分配一次,不仅挂掉的那台机器上的数据需要分布上剩余的(N - 1)台机器上,原有的数据也会重新分配,很明显传统hash策略很大的一个弊端就是坏掉一个节点后需要迁移大量的数据。为此有人提出了哈希一致性算法。
2 哈希一致性算法:
将所有的哈希值组成一个圆环,即 0 -> (2^32 - 1) -> 0 这样的一个圆环。N个server 均匀的分布在这个圆环上,即有N个点,落在这个两个点之间的值,按照顺时针方向获取需要存放的server。如下图所示:

如果节点一坏掉的话,根据上面的原则,节点1的数据会转移到节点2上,而其他节点的数据是没有任何变化的。所以需要迁移的数据比上一个方案要小很多。但是,这里也有一个问题,万一碰巧,很多数据的hash值都集中在了节点1和节点2之间,那么节点2的数据将会非常的大,这种情况对于节点少的场景非常容易出现,对于这种情况,又有人提出了基于虚拟节点的改进哈希一致性算法。
3 改进哈希一致性算法:
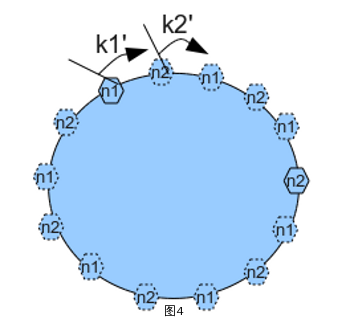
上图中,server一共就两个,如果按照(2)中的方法,整个环上就两个节点,容易造成某个节点数据过多,现在给n1和n2赋予6多个副本,也就是虚拟节点,然后按照n1 -> n2 -> n1 -> n2 ... 的方式放在hash环上。这样就可以有效的避免单节点数据过多问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号