

并发编程
目录
并发编程
在本章的学习中,我们的学习目标如下:
- 掌握三种并发的方式:进程、线程、I/O多路复用
- 掌握线程控制及相关系统调用
- 掌握线程同步互斥及相关系统调用
并发的概念:
如果逻辑控制流在时间上是重叠的,那么它们就是并发的。
应用级并发的应用:
- 访问慢速I/O设备。当一个应用正在等待来自慢速I/O设备(例如磁盘)的数据到达时,内核会运行其他进程,使CPU保持繁忙。这是通过交替执行I/O请求和其他有用的工作来使用并发。
- 与人交互。用户希望计算机有同时执行多个任务的能力。每次用户请求某种操作(如单击鼠标)时,一个独立的并发逻辑流被创建来执行这个操作。
通过推迟工作来降低延迟。 - 服务多个网络客户端。我们期望服务器每秒为成百上千的客户端提供服务,并发服务器为每个客户端创建一个单独的逻辑流。
- 在多核机器上进行并行计算。被划分成并发流的应用程序通常在多核机器上比在单处理器上运行得快,因为这些流会并行执行,而不是交错执行。
现代操作系统中三种构造并发程序的方法:
- 进程。每个逻辑流都是一个进程,由内核来调度和维护。
- I/O多路复用。在这种形式中,应用程序在一个进程的上下文中显式地调度它们自己的逻辑流。逻辑流被模型化为状态机。因为程序是一个单独的进程,所以所有的流都共享同一个地址空间。
- 线程。线程是运行在单一进程上下文中的逻辑流,由内核进行调度
线程与进程的区分:
- 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位;
- 线程是进程的一个实体,是CPU调度和分派的基本单位。它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),一个线程可以创建和撤销另一个线程;
一、基于进程的并发编程
构造并发编程最简单的方法就是用进程,使用那些大家都很熟悉的函数,像fork、exec和waitpid。
步骤:
- 服务器监听一个监听描述符上的连接请求。
- 服务器接受了客户端1的连接请求,并返回一个已连接描述符。
- 在接受了连接请求之后,服务器派生一个子进程,这个子进程获得服务器描述符表的完整拷贝。子进程关闭它的拷贝中的监听描述符3,而父进程关闭它的已连接描述符4的拷贝,因为不再需要这些描述符了。
- 子进程正忙于为客户端提供服务,父进程继续监听新的请求。
四个步骤的示意图如下:
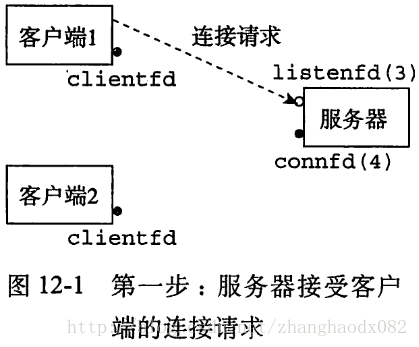
注意:子进程关闭监听描述符和父进程关闭已连接描述符是很重要的,因为父子进程共用同一文件表,文件表中的引用计数会增加,只有当引用计数减为0时,文件描述符才会真正关闭。所以,如果父子进程不关闭不用的描述符,将永远不会释放这些描述符,最终将引起存储器泄漏而最终消耗尽可以的存储器,是系统崩溃。
使用进程并发编程要注意的问题:
- 首先,通常服务器会运行很长的时间,所以我们必须要包括一个SIGCHLD处理程序,来回收僵死子进程的资源。因为当SIGCHLD处理程序执行时,SIGCHLD信号时阻塞的,而Unix信号时不排队的,所以SIGCHLD处理程序必须准备好回收多个僵死子进程的资源。
- 其次,子进程必须关闭它们各自的connfd拷贝。就像我们已经提到过的,这对父进程而言尤为重要,它必须关闭它的已连接描述符,以避免存储器泄漏。
- 最后,因为套接字的文件表表项中的引用计数,直到父子进程的connfd都关闭了,到客户端的连接才会终止。
进程的优劣:
对于在父、子进程间共享状态信息,进程有一个非常清晰的模型:共享文件表,但是不共享用户地址空间。进程有独立的地址控件爱你既是优点又是缺点。由于独立的地址空间,所以进程不会覆盖另一个进程的虚拟存储器。但是另一方面进程间通信就比较麻烦,至少开销很高。
编写的代码如下:
#include "csapp.h"
void echo(int connfd);
void sigchld_handler(int sig)
{
while (waitpid(-1, 0, WNOHANG) > 0)
;
return;
}
int main(int argc, char **argv)
{
int listenfd, connfd, port, clientlen=sizeof(struct sockaddr_in);
struct sockaddr_in clientaddr;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
port = atoi(argv[1]);
Signal(SIGCHLD, sigchld_handler);
listenfd = Open_listenfd(port);
while (1) {
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
if (Fork() == 0) {
Close(listenfd); /* Child closes its listening socket */
echo(connfd); /* Child services client */
Close(connfd); /* Child closes connection with client */
exit(0); /* Child exits */
}
Close(connfd); /* Parent closes connected socket (important!) */
}
}
二、基于i/o多路复用的并发编程
面对困境——服务器必须响应两个互相独立的I/O事件:
- 网络客户端发起的连接请求
- 用户在键盘上键入的命令
针对这种困境的一个解决办法就是I/O多路复用技术。
I/O多路复用技术基本思想是:
可以使用select、poll和epoll来实现I/O复用。使用select函数,要求内核挂起进程,只有在一个或者多个I/O事件发生后,才将控制返给应用程序。
select函数如下图所示:

使用select函数的过程如下:
- 初始化fd_set集
- 调用select
- 根据fd_set集合现在的值,判断是哪种I/O事件
基于i/o多路复用的并发事件驱动服务器:
I/O多路复用可以用做并发事件驱动程序的基础,在事件驱动程序中,流是因为某种事件而前进的,一般概念是将逻辑流模型化为状态机,不严格地说,一个状态机就是一组状态,输入事件和转移,其中转移就是将状态和输入事件映射到状态,每个转移都将一个(输入状态,输入事件)对映射到一个输出状态,自循环是同一输入和输出状态之间的转移,通常把状态机画成有向图,其中节点表示状态,有向弧表示转移,而弧上的标号表示输人事件,一个状态机从某种初始状态开始执行,每个输入事件都会引发一个从当前状态到下一状态的转移,对于每个新的客户端k,基于I/O多路复用的并发服务器会创建一个新的状态机S,并将它和已连接描述符d联系起来。
I/O多路复用技术的优点:
-
使用事件驱动编程,这样比基于进程的设计给了程序更多的对程序行为的控制。
-
一个基于I/O多路复用的事件驱动服务器是运行在单一进程上下文中的,因此每个逻辑流都访问该进程的全部地址空间。这使得在流之间共享数据变得很容易。一个与作为单进程运行相关的优点是,你可以利用熟悉的调试工具,例如GDB来调试你的并发服务器,就像对顺序程序那样。最后,事件驱动设计常常比基于进程的设计要高效很多,因为它们不需要进程上下文切换来调度新的流。
缺点:
事件驱动设计的一个明星的缺点就是编码复杂。我们的事件驱动的并发服务器需要比基于进程的多三倍。不幸的是,随着并发粒度的减小,复杂性还会上升。这里的粒度是指每个逻辑流每个时间片执行的指令数量。
基于事件的设计的另一重大的缺点是它们不能充分利用多核处理器。
编写的代码如下:
#include "csapp.h"
void echo(int connfd);
void command(void);
int main(int argc, char **argv)
{
int listenfd, connfd, port, clientlen = sizeof(struct sockaddr_in);
struct sockaddr_in clientaddr;
fd_set read_set, ready_set;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
port = atoi(argv[1]);
listenfd = Open_listenfd(port);
FD_ZERO(&read_set);
FD_SET(STDIN_FILENO, &read_set);
FD_SET(listenfd, &read_set);
while (1) {
ready_set = read_set;
Select(listenfd+1, &ready_set, NULL, NULL, NULL);
if (FD_ISSET(STDIN_FILENO, &ready_set))
command(); /* read command line from stdin */
if (FD_ISSET(listenfd, &ready_set)) {
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
echo(connfd); /* echo client input until EOF */
}
}
}
void command(void) {
char buf[MAXLINE];
if (!Fgets(buf, MAXLINE, stdin))
exit(0); /* EOF */
printf("%s", buf); /* Process the input command */
}
三、基于线程的并发编程
在使用进程并发编程中,我们为每个流使用了单独的进程。内核会自动调用每个进程。每个进程有它自己的私有地址空间,这使得流共享数据很困难。在使用I/O多路复用的并发编程中,我们创建了自己的逻辑流,并利用I/O多路复用来显式地调度流。因为只有一个进程,所有的流共享整个地址空间。而基于线程的方法,是这两种方法的混合。
线程执行模型:
线程和进程的执行模型有些相似。每个进程的声明周期都是一个线程,我们称之为主线程。线程是对等的,主线程跟其他线程的区别就是它先执行。
线程就是运行在进程上下文的逻辑流,如下图所示。线程由内核自动调度。每个线程都有它自己的线程上下文,包括一个唯一的整数线程ID、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有的运行在一个进程里的线程共享该进程的整个虚拟地址空间。
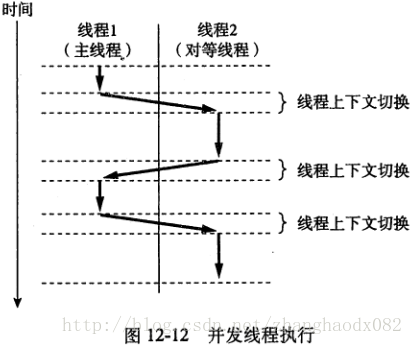
基于线程的逻辑流结合了基于线程和基于I/O多路复用的流的特性。同进程一样,线程由内核自动调度,并且内核通过一个整数ID来标识线程。同基于I/O多路复用的流一样,多个线程运行在单一进程的上下文中,因此共享这个线程虚拟地址空间的整个内容,包括它的代码、数据、堆、共享库和打开的文件。
posix线程
POSIX线程是在C程序中处理线程的一个标准接口。它最早出现在1995年,而且在大多数Unix系统上都可用。Pthreads定义了大约60个函数,允许程序创建、杀死和回收线程,与对等线程安全地共享数据,还可以通知对等线程系统状态的变化。
创建线程:
pthread_create函数用来创建其他进程。

pthread_create函数创建一个新的线程,并带着一个输入变量arg,在新线程的上下文中运行线程例程f。能用attr参数来改变新创建线程的默认属性。
当pthread_create返回时,参数tid包含新创建线程的ID。
获取自身ID:
pthread_self函数用来获取自身ID。

终止线程:
一个线程是以下列方式之一来终止的:
- 当顶层的线程例程返回时,线程会隐式地终止
- 通过调用pthread_exit函数,线程会显式地终止。如果主线程调用pthread_exit,它会等待所有其他对等线程终止,然后再终止主线程和这个进程,返回值为thread_return。
- 某个对等线程调用exit函数,则函数终止进程和所有与该进程相关的线程;
- 另一个对等线程调用以当前ID为参数的函数ptherad_cancel来终止当前线程。
pthread_exit函数和ptherad_cancel函数函数如下所示:


回收已终止线程的资源:
pthread_join函数会终止,直到线程tid终止。和wait不同,该函数只能回收指定id的线程,不能回收任意线程。

** 分离线程:**
在任何一个时间点上,线程是可结合的或者是分离的。一个可结合的线程能够被其他线程收回其资源和杀死。在被其他线程回收之前,它的存储器资源(例如栈)式没有被释放的。相反,一个分离的线程是不能被其他线程回收和杀死的。它的存储器资源在它终止时由系统自动释放。
默认情况下,线程被创建成可结合的。为了避免存储器泄漏,每个可结合线程都应该要么被其他线程显式地收回,要么通过调用pthread_detach函数被分离。
pthread_detach函数分离可结合线程tid。线程能够通过以pthread_self()为参数的pthread_detach调用来分离它们自己。

初始化线程:
pthread_once()函数用来初始化多个线程共享的全局变量。

编写代码如下:
/*
* echoservert.c - A concurrent echo server using threads
*/
/* $begin echoservertmain */
#include "csapp.h"
void echo(int connfd);
void *thread(void *vargp);
int main(int argc, char **argv)
{
int listenfd, *connfdp, port, clientlen=sizeof(struct sockaddr_in);
struct sockaddr_in clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
port = atoi(argv[1]);
listenfd = Open_listenfd(port);
while (1) {
connfdp = Malloc(sizeof(int));
*connfdp = Accept(listenfd, (SA *) &clientaddr, &clientlen);
Pthread_create(&tid, NULL, thread, connfdp);
}
}
/* thread routine */
void *thread(void *vargp)
{
int connfd = *((int *)vargp);
Pthread_detach(pthread_self());
Free(vargp);
echo(connfd);
Close(connfd);
return NULL;
}
四、多线程程序中的共享变量
每个线程都有它自己独自的线程上下文,包括线程ID、栈、栈指针、程序计数器、条件码和通用目的寄存器值。每个线程和其他线程一起共享进程上下文的剩余部分。寄存器是从不共享的,而虚拟存储器总是共享的。线程化的c程序中变量根据它们的存储器类型被映射到虚拟存储器:全局变量,本地自动变量(不共享),本地静态变量。
线程存储器模型:
一组并发线程运行在一个进程的上下文中。每个线程都有它自己独立的线程上下文,包括线程ID、栈、栈指针、程序计数器、条件码和通用目的寄存器值。每个线程和其他线程一起共享进程上下文的剩余部分。这包括整个用户虚拟地址空间,它是由只读文本代码、读/写数据、堆以及所有的共享库代码和数据区域组成的。线程也共享同样的打开文件的集合。
从实际操作的角度来说,让一个线程去读或写另一个线程的寄存器值是不可能的。另一方面,任何线程都可以访问共享虚拟存储器的任意位置。如果某个线程修改了一个存储器位置,那么其他每个线程最终都能在它读这个位置时发现这个变化。因此,寄存器是从不共享的,而虚拟存储器总是共享的。
各自独立的线程栈的存储器模型不是那么整齐清楚的。这些栈被保存在虚拟地址空间的栈区域中,并且通常是被相应的线程独立地访问的。我们说通常而不是总是,是因为不同的线程栈是不对其他线程设防的所以,如果个线程以某种方式得到个指向其他线程栈的指慧:那么它就可以读写这个栈的任何部分。
线程化的C程序中变量根据它们的存储类型被映射到虚拟存储器:
- 全局变量。全局变量是定义在函数之外的变量,在运行时,虚拟存储器的读/写区域域只包含每个全局变量的一个实例,任何线程都可以引用。例如第5行声明的全局变量ptr在虚拟存储器的读/写区域中有个运行时实例,我们只用变量名(在这里就是ptr)来表示这个实例。
- 本地自动变量,本地自动变量就是定义在函数内部但是没有static属性的变量,在运行时,每个线程的栈都包含它自己的所有本地自动变量的实例。即使当多个线程执行同一个线程例程时也是如此。例如,有个本地变量tid的实例,它保存在主线程的栈中。我们用tid.m来表示这个实例
- 本地静态变量
共享变量:
我们说一个变量v是共享的,当且仅当它的一个实例被一个以上的线程引用。
编写代码如下:
#include "csapp.h"
#define N 2
void *thread(void *vargp);
char **ptr; /* global variable */
int main()
{
int i;
pthread_t tid;
char *msgs[N] = {
"Hello from foo",
"Hello from bar"
};
ptr = msgs;
for (i = 0; i < N; i++)
Pthread_create(&tid, NULL, thread, (void *)i);
Pthread_exit(NULL);
}
void *thread(void *vargp)
{
int myid = (int)vargp;
static int cnt = 0;
printf("[%d]: %s (cnt=%d)\n", myid, ptr[myid], ++cnt);
}
五、用信号量同步线程
- 进程竞争资源首先必须解决互斥问题。某些资源必须互斥使用,如打印机、共享变量、表格、文件等。
- 这类资源又称为临界资源,访问临界资源的那段代码称为临界区(critical section)。
- 任何时刻,只允许一个进程进入临界区,以此实现进程对临界资源的互斥访问。
- 同步问题:当缓冲区为空,打印进程无法取数据;当缓冲区为满,计算进程无法存数据。进程间需要协作。
临界区使用规则:
- 有空让进:如果临界区空闲,则只要有进程申请就立即让其进入;
- 无空等待:每次只允许一个进程处于临界区;
多中择一:当没有进程在临界区,而同时有多个进程要求进入临界区,只能让其中之一进入临界区,其他进程必须等待; - 让权等待:进入临界区的进程,不能在临界区内长时间阻塞等待某事件,使其它进程在临界区外无限期等待;
- 不能限制进程的并发数量和执行进度。
互斥与同步的解决策略:信号量
OS以一个地位高于进程的管理者的角度来解决公有资源的使用问题,信号量就是OS提供的管理公有资源的有效手段。
- 两个或多个进程通过传递信号进行合作,可以迫使进程在某个位置暂时停止执行(阻塞等待),直到它收到一个可以“向前推进”的信号(被唤醒);
- 将实现信号灯作用的变量称为信号量,常定义为记录型变量s,其一个域为整型,另一个域为队列,其元素为等待该信号量的阻塞进程(FIFO)。
信号量的定义:
type semaphore=record
count: integer;
queue: list of process
end;
var s:semaphore;
对信号量的两个原子操作:
进程进入临界区之前,首先执行wait(s)原语,若s.count小于0,则进程调用阻塞原语,将自己阻塞,并插入到s.queue队列排队;
一旦其它某个进程执行了signal(s)原语中的s.count+1操作后,发现s.count ≤0,即阻塞队列中还有被阻塞进程,则调用唤醒原语,把s.queue中第一个进程修改为就绪状态,送就绪队列,准备执行临界区代码。
- wait操作用于申请资源(或使用权),进程执行wait原语时,可能会阻塞自己;
- signal操作用于释放资源(或归还资源使用权),进程执行signal原语时,有责任唤醒一个阻塞进程。
wait(s)
s.count :=s.count-1;
if s.count<0 then
begin
进程阻塞;
进程进入s.queue队列;
end;
signal(s)
s.count :=s.count+1;
if s.count ≤0 then
begin
唤醒队首进程;
将进程从s.queue阻塞队列中移出;
end;
- 信号量分为:互斥信号量和资源信号量。
- 互斥信号量用于申请或释放资源的使用权,常初始化为1;
- 资源信号量用于申请或归还资源,可以初始化为大于1的正整数,表示系统中某类资源的可用个数。
经典进程互斥与同步问题:
- 生产者/消费者问题
- 要求:必须保证对缓冲区的访问是互斥的;还需要调度对缓冲区的访问,即,如果缓冲区是满的(没有空的槽位),那么生产者必须等待直到有一个空的槽位为止,如果缓冲区是空的(即没有可取的项目),那么消费者必须等待直到有一个项目变为可用。
- 读者/写者问题
- 修改对象的线程叫做写者;只读对象的线程叫做读者。写着必须拥有对对象的独占访问,而读者可以和无限多个其他读者共享对象。读者——写者问题基本分为两类:第一类,读者优先,要求不要让读者等待,除非已经把使用对象的权限赋予了一个写者。换句话说,读者不会因为有一个写者等待而等待;第二类,写者优先,要求一定能写者准备好可以写,它就会尽可能地完成它的写操作。同第一类问题不同,在一个写者后到达的读者必须等待,即使这个写者也是在等待。
基于预线程化的并发服务器
在如图所示的并发服务器中,我们为每一个新客户端创建了一个新线程这种方法的缺点是我们为每一个新客户端创建一个新线程,导致不小的代价。一个基于预线程化的服务器试图通过使用如图所示的生产者-消费者模型来降低这种开销。服务器是由一个主线程和一组工作者线程构成的。主线程不断地接受来自客户端的连接请求,并将得到的连接描述符放在一个不限缓冲区中。每一个工作者线程反复地从共享缓冲区中取出描述符,为客户端服务,然后等待下一个描述符。
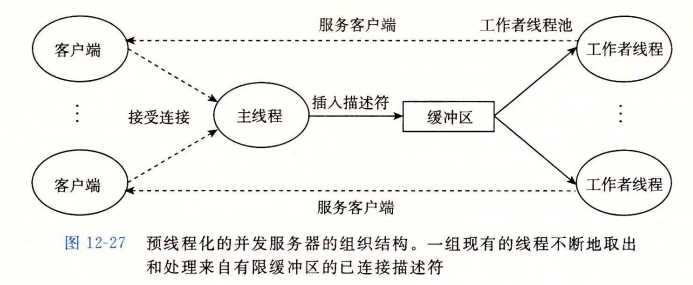
编写代码如下:
/*
* badcnt.c - An improperly synchronized counter program
*/
/* $begin badcnt */
#include "csapp.h"
#define NITERS 200000000
void *count(void *arg);
/* shared counter variable */
unsigned int cnt = 0;
int main()
{
pthread_t tid1, tid2;
Pthread_create(&tid1, NULL, count, NULL);
Pthread_create(&tid2, NULL, count, NULL);
Pthread_join(tid1, NULL);
Pthread_join(tid2, NULL);
if (cnt != (unsigned)NITERS*2)
printf("BOOM! cnt=%d\n", cnt);
else
printf("OK cnt=%d\n", cnt);
exit(0);
}
/* thread routine */
void *count(void *arg)
{
int i;
for (i = 0; i < NITERS; i++)
cnt++;
return NULL;
}
六、使用线程提高并行性
到目前为止,在对并发的研究中,我们都假设并发线程是在单处许多现代机器具有多核处理器。并发程序通常在这样的机器上运理器系统上执行的。然而,在多个核上并行地调度这些并发线程,而不是在单个核顺序地调度,在像繁忙的Web服务器、数据库服务器和大型科学计算代码这样的应用中利用这种并行性是至关重要的。
七、其他并发问题
1.四种不安全函数

(1):不保护共享变量的函数。
(2):保持跨越多个调用的状态的函数。一个伪随机数生成器是这类线程不安全函数的简单例子。rand函数是线程不安全的,因为档期调用的结果依赖于前次调用的中间结果。当调用srand为rand设置了一个终止后,我们从一个但线程中反复地调用rand,能够预期得到一个可重复的随机数字序列。
(3):返回指向静态变量的指针的函数。某些函数,例如ctime和gethostbyname,将计算结果放在一个static变量中,然后返回一个指向这个变量的指针。如果我们从并发线程中调用这些函数,那么将可能发生灾难,因为正在被一个线程使用的结果会被另一个线程悄悄地覆盖了。
有两种方法来处理这类线程不安全函数。一种选择是重写函数,使得调用者传递存放结果的变量的地址。这就消除了所有共享数据,但是它要求程序员能够修改函数的源代码。
如果线程不安全是难以修改或不可能修改的,那么另外一种选择是使用加锁-拷贝技术。基本思想是将线程不安全函数与互斥锁联系起来,在每一个调用位置,对互斥锁加锁,调用线程不安全函数,将函数返回的结果拷贝到一个私有的存储器位置,然后对互斥锁解锁。为了尽可能减少对调用者的修改,你应该定义一个线程安全的包装函数,它执行加锁-拷贝,然后通过调用这个包装函数来取代对线程不安全函数的调用。
(4):调用线程不安全函数的函数。如果函数f调用线程不安全函数g,那么f就是线程不安全的吗?不一定。如果g是第二类资源,即依赖于跨越多次调用的状态,那么f也是线程不安全的,而且除了重写g以为,没有办法。然而,如果g是第一类或第三类函数,那么只要你用一个互斥锁保护调用位置和任何得到的共享数据,f仍然可能是线程安全的。
2.可重入函数。可重入函数是线程安全函数的一个真子集,它不访问任何共享数据。可重入安全函数通常比不可重入函数更有效,因为它们不需要任何同步原语。
3.竞争。当程序员错误地假设逻辑流该如何调度时,就会发生竞争。为了消除竞争,通常我们会动态地分配内存空间。
4.死锁。当一个流等待一个永远不会发生的事件时,就会发生死锁。


