

数据采集与技术融合班级作业三102302119庄靖轩
数据采集与融合实验第三次报告
作业1
1)实验内容
要求:指定一个网站,爬取这个网站中的所有的所有图片,中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
代码说明
说一下想法,我先使用了
1.is_jpg_png(url):判断 URL 是否为 .jpg/.jpeg/.png 图片,同时过滤掉 data:image 这种内嵌图片。
2.filename_from_url(url):从 URL 中提取文件名,并进行 URL 解码。
3.ensure_unique_path(base_dir, name):若存在同名文件,就自动在文件名后加 (1), (2)…,避免覆盖。
我使用通过 Selenium(因为这个web的懒加载图片比较多) 启动 Chrome,使用一个循环向下滚动页面来触发页面中的懒加载图片。匹配爬取用的是CSS
单线程的代码
import os
import re
import time
import pathlib
import requests
from urllib.parse import urljoin, urlparse, urlsplit, unquote, urlunsplit
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
# ====== 可配置项 ======
start_url = "http://www.weather.com.cn"
chrome_driver_path = r"D:\HuaweiMoveData\Users\33659\Desktop\python\chromedriver-win64\chromedriver.exe"
save_dir = pathlib.Path("images单线程")
scroll_max_rounds = 19 # 最多爬取19 页
request_timeout = 20 # 单张图片下载超时(秒)
max_images = 119 # 最多下载 119 张图片
save_dir.mkdir(parents=True, exist_ok=True)
def is_jpg_png(url: str) -> bool:
if not url:
return False
url = url.strip().strip('\'"')
if url.lower().startswith("data:image"):
return False
path = urlsplit(url).path.lower()
return path.endswith(".jpg") or path.endswith(".jpeg") or path.endswith(".png")
def filename_from_url(url: str) -> str:
parts = urlsplit(url)
path = parts.path
name = os.path.basename(path)
name = unquote(name)
if not name:
name = "image"
return name
def ensure_unique_path(base_dir: pathlib.Path, name: str) -> pathlib.Path:
p = base_dir / name
if not p.exists():
return p
stem, ext = os.path.splitext(name)
idx = 1
while True:
candidate = base_dir / f"{stem}({idx}){ext}"
if not candidate.exists():
return candidate
idx += 1
def normalize_url(u: str, base: str) -> str:
if not u:
return ""
u = u.strip().strip('\'"')
if u.startswith("url(") and u.endswith(")"):
u = u[4:-1].strip('\'"')
if u.startswith("//"):
return "http:" + u
return urljoin(base, u)
def download_image(url: str, referer: str):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome Safari",
"Referer": referer,
"Accept": "image/avif,image/webp,image/apng,image/*,*/*;q=0.8",
}
resp = requests.get(url, headers=headers, timeout=request_timeout, stream=True)
resp.raise_for_status()
name = filename_from_url(url)
if not os.path.splitext(name)[1]:
ct = resp.headers.get("Content-Type", "").lower()
if "png" in ct:
name += ".png"
elif "jpeg" in ct or "jpg" in ct:
name += ".jpg"
path = ensure_unique_path(save_dir, name)
with open(path, "wb") as f:
for chunk in resp.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
print(f"[OK] {url} -> {path}")
return True
except Exception as e:
print(f"[FAIL] {url} - {e}")
return False
chrome_options = Options()
# chrome_options.add_argument("--headless=new")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
try:
driver.get(start_url)
# ====== 限制最多“滚动 19 次” ======
last_height = driver.execute_script("return document.body.scrollHeight;")
rounds = 0
while rounds < scroll_max_rounds:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1.0)
new_height = driver.execute_script("return document.body.scrollHeight;")
rounds += 1
if new_height == last_height:
break
last_height = new_height
img_urls = set()
img_attrs = ["src", "data-src", "data-original", "data-url", "src2"]
for attr in img_attrs:
try:
elems = driver.find_elements(By.CSS_SELECTOR, f"img[{attr}]")
except Exception:
elems = []
for el in elems:
try:
val = el.get_attribute(attr)
full = normalize_url(val, start_url)
if is_jpg_png(full):
img_urls.add(full)
except Exception:
pass
elems = driver.find_elements(By.CSS_SELECTOR, "*")
for el in elems:
try:
bg = el.value_of_css_property("background-image")
if not bg or bg == "none":
continue
for m in re.findall(r'url\((.*?)\)', bg):
full = normalize_url(m, start_url)
if is_jpg_png(full):
img_urls.add(full)
except Exception:
pass
html = driver.page_source
for m in re.findall(
r'<img[^>]+?(?:src|data-src|data-original|data-url|src2)\s*=\s*["\']([^"\']+)["\']',
html,
flags=re.IGNORECASE
):
full = normalize_url(m, start_url)
if is_jpg_png(full):
img_urls.add(full)
print(f"共发现候选图片 {len(img_urls)} 张(仅当前首页、JPG/PNG)")
# ====== 限制最多下载 119 张图片 ======
ok = 0
for url in sorted(img_urls):
if ok >= max_images: # 达到上限就停止
print(f"已达到最大下载数量 {max_images} 张,停止下载。")
break
if download_image(url, referer=start_url):
ok += 1
print(f"下载完成:成功 {ok} / 发现 {len(img_urls)}")
finally:
driver.quit()
想法和单线程一样,只是改成了多线程
这是多线程的代码
import os
import re
import time
import pathlib
import requests
from urllib.parse import urljoin, urlparse, urlsplit, unquote
from concurrent.futures import ThreadPoolExecutor, as_completed
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
start_url = "http://www.weather.com.cn"
chrome_driver_path = r"D:\HuaweiMoveData\Users\33659\Desktop\python\chromedriver-win64\chromedriver.exe"
save_dir = pathlib.Path("images多线程") # 保存目录
# ====== 新增:最大“页数”与最大图片数量 ======
max_pages = 19 # 最多“爬取 19 页”(这里用 19 次滚动来模拟)
max_images = 119 # 最多下载 119 张图片
scroll_max_rounds = max_pages # 滚动次数上限,直接等于 max_pages
scroll_pause = 1.0 # 每次滚动后的停顿时间(秒)
request_timeout = 20 # 单张图片下载超时(秒)
max_workers = 16 # 并发下载线程数
max_retries = 3 # 每张图片最大重试次数
save_dir.mkdir(parents=True, exist_ok=True)
def is_jpg_png(url: str) -> bool:
if not url:
return False
url = url.strip().strip('\'"')
if url.lower().startswith("data:image"):
return False
path = urlsplit(url).path.lower()
return path.endswith(".jpg") or path.endswith(".jpeg") or path.endswith(".png")
def filename_from_url(url: str) -> str:
parts = urlsplit(url)
name = os.path.basename(parts.path)
name = unquote(name)
if not name:
name = "image"
return name
def ensure_unique_path(base_dir: pathlib.Path, name: str) -> pathlib.Path:
p = base_dir / name
if not p.exists():
return p
stem, ext = os.path.splitext(name)
idx = 1
while True:
candidate = base_dir / f"{stem}({idx}){ext}"
if not candidate.exists():
return candidate
idx += 1
def normalize_url(u: str, base: str) -> str:
if not u:
return ""
u = u.strip().strip('\'"')
if u.startswith("url(") and u.endswith(")"):
u = u[4:-1].strip('\'"')
if u.startswith("//"): # 协议相对
return "http:" + u
return urljoin(base, u)
def build_headers(referer: str):
return {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome Safari",
"Referer": referer,
"Accept": "image/avif,image/webp,image/apng,image/*,*/*;q=0.8",
"Connection": "keep-alive",
}
def download_once(url: str, referer: str) -> pathlib.Path:
headers = build_headers(referer)
with requests.get(url, headers=headers, timeout=request_timeout, stream=True) as resp:
resp.raise_for_status()
name = filename_from_url(url)
if not os.path.splitext(name)[1]:
ct = resp.headers.get("Content-Type", "").lower()
if "png" in ct:
name += ".png"
elif "jpeg" in ct or "jpg" in ct:
name += ".jpg"
path = ensure_unique_path(save_dir, name)
with open(path, "wb") as f:
for chunk in resp.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
return path
def download_with_retry(url: str, referer: str) -> tuple[str, bool, str]:
# 返回 (url, 是否成功, 本地路径/错误信息)
for attempt in range(1, max_retries + 1):
try:
path = download_once(url, referer)
return (url, True, str(path))
except Exception as e:
err = f"{type(e).__name__}: {e}"
if attempt < max_retries:
time.sleep(0.5 * attempt)
else:
return (url, False, err)
def collect_image_urls(driver, base_url: str) -> set[str]:
img_urls = set()
# 1) 常见 <img> 懒加载属性
img_attrs = ["src", "data-src", "data-original", "data-url", "src2"]
for attr in img_attrs:
try:
elems = driver.find_elements(By.CSS_SELECTOR, f"img[{attr}]")
except Exception:
elems = []
for el in elems:
try:
val = el.get_attribute(attr)
full = normalize_url(val, base_url)
if is_jpg_png(full):
img_urls.add(full)
except Exception:
pass
# 2) CSS 背景图
elems = driver.find_elements(By.CSS_SELECTOR, "*")
for el in elems:
try:
bg = el.value_of_css_property("background-image")
if not bg or bg == "none":
continue
for m in re.findall(r'url\((.*?)\)', bg):
full = normalize_url(m, base_url)
if is_jpg_png(full):
img_urls.add(full)
except Exception:
pass
# 3) 源码兜底
html = driver.page_source
for m in re.findall(
r'<img[^>]+?(?:src|data-src|data-original|data-url|src2)\s*=\s*["\']([^"\']+)["\']',
html,
flags=re.IGNORECASE,
):
full = normalize_url(m, base_url)
if is_jpg_png(full):
img_urls.add(full)
return img_urls
def main():
chrome_options = Options()
# 如需无头模式,取消下一行注释
# chrome_options.add_argument("--headless=new")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
try:
driver.get(start_url)
# ====== 最多滚动 max_pages(=19) 次,相当于“最多爬取 19 页” ======
last_height = driver.execute_script("return document.body.scrollHeight;")
rounds = 0
while rounds < scroll_max_rounds:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(scroll_pause)
new_height = driver.execute_script("return document.body.scrollHeight;")
rounds += 1
if new_height == last_height:
break
last_height = new_height
img_urls = collect_image_urls(driver, start_url)
print(f"共发现候选图片 {len(img_urls)} 张(首页、JPG/PNG)")
# ====== 限制最多下载 max_images(=119) 张 ======
img_list = sorted(img_urls)
if len(img_list) > max_images:
print(f"由于设置了最多下载 {max_images} 张图片,只会下载前 {max_images} 个 URL。")
img_list = img_list[:max_images]
else:
print(f"将尝试下载全部 {len(img_list)} 张图片。")
ok = 0
fails = 0
futures = []
referer = start_url
with ThreadPoolExecutor(max_workers=max_workers) as executor:
for url in img_list: # ✅ 只对截断后的列表提交任务
futures.append(executor.submit(download_with_retry, url, referer))
for fut in as_completed(futures):
url, success, info = fut.result()
if success:
ok += 1
print(f"[OK] {url} -> {info}")
else:
fails += 1
print(f"[FAIL] {url} - {info}")
print(f"下载完成:成功 {ok} / 实际尝试 {len(img_list)} / 失败 {fails}")
finally:
driver.quit()
if __name__ == "__main__":
main()
结果展示
单线程的结果
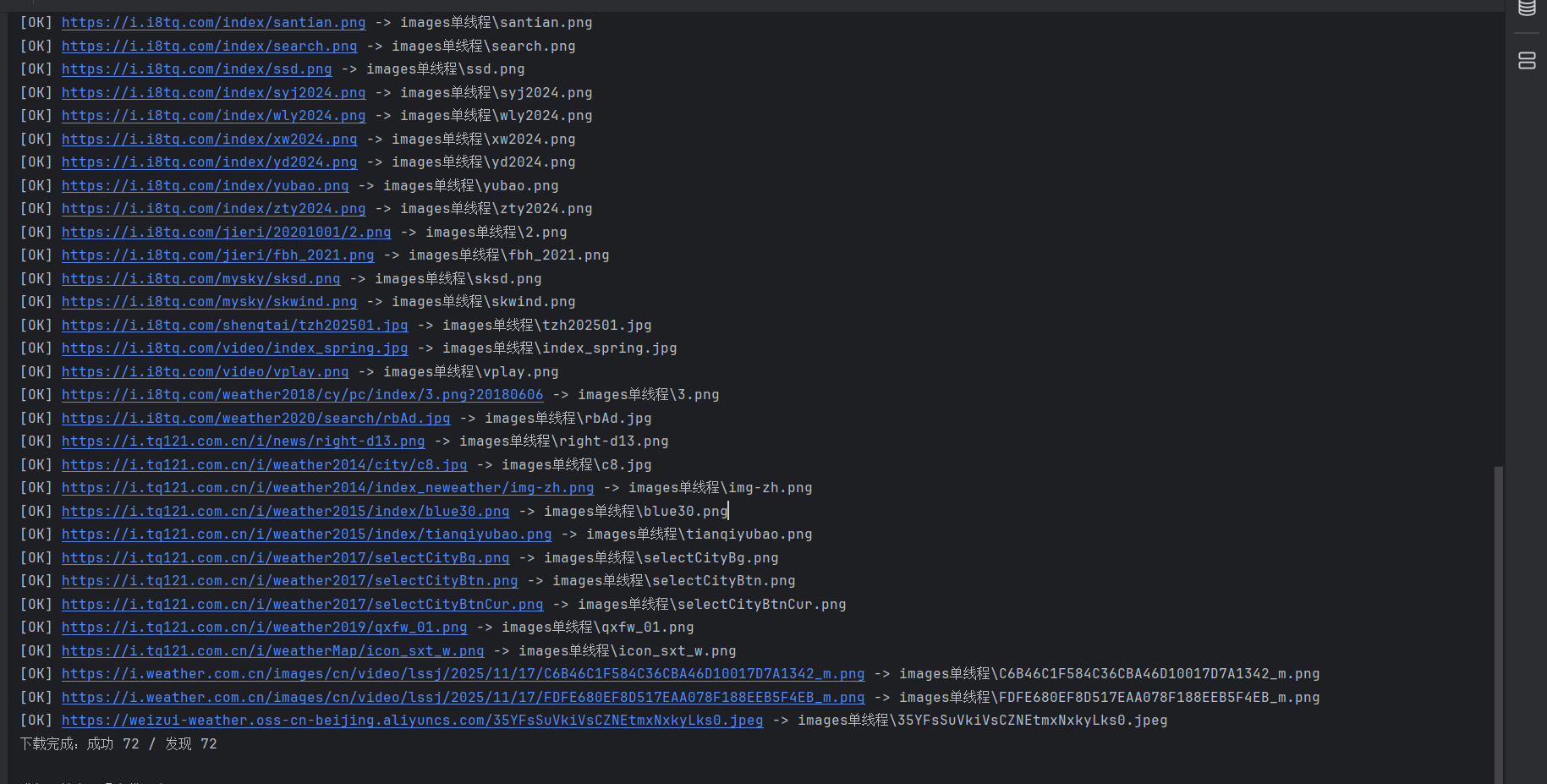
多线程的结果
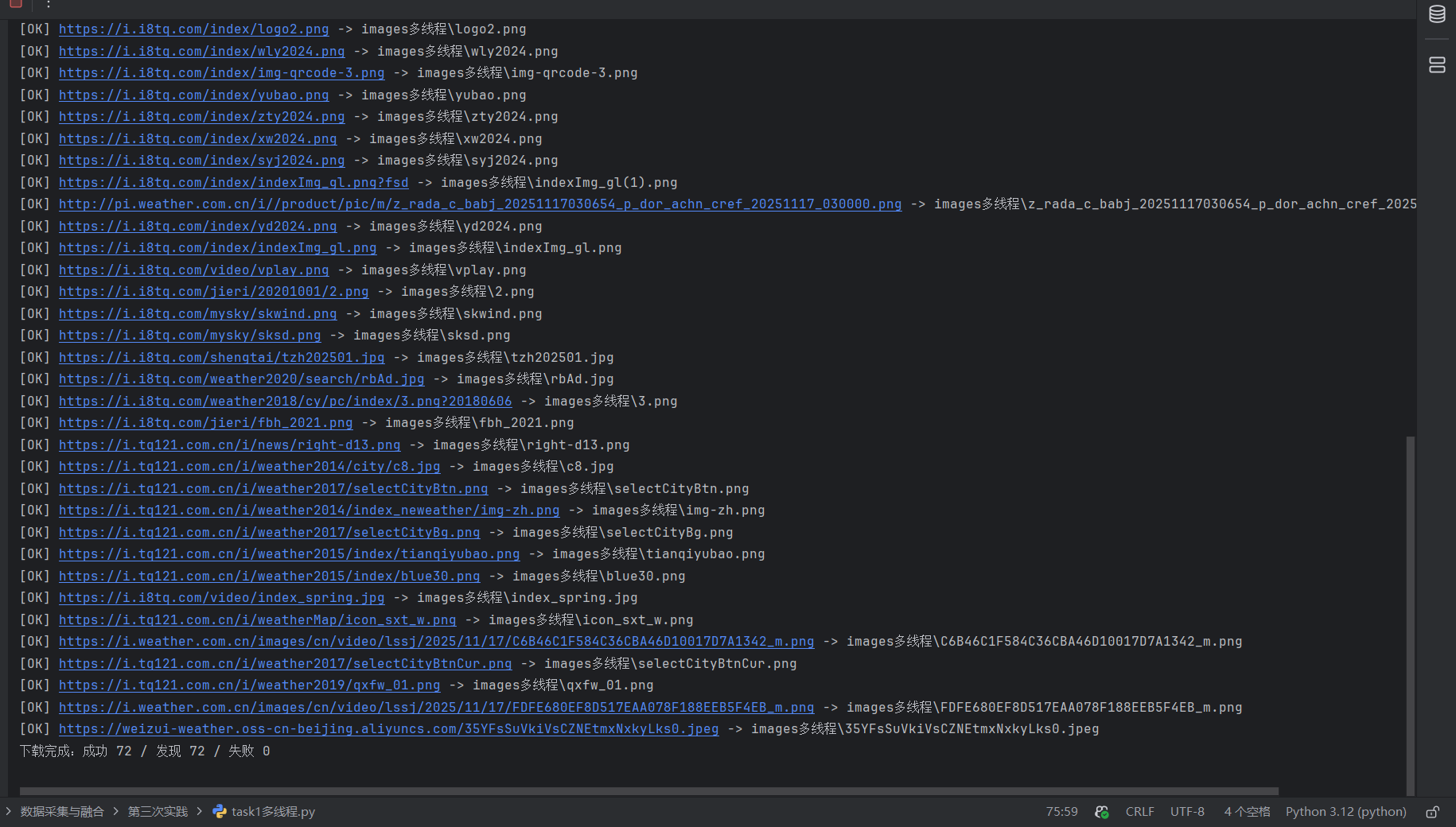
Gitee文件夹链接:https://gitee.com/zhuang-jingxuan/data/blob/master/作业代码/第三次作业/task1单线程.py
Gitee文件夹链接:https://gitee.com/zhuang-jingxuan/data/blob/master/作业代码/第三次作业/task1多线程.py
2)心得体会
1.Selenium + requests 的组合很实用:前者负责把页面“滚动到位”,后者负责稳定地下载二进制内容。
2.多线程确实能显著提升 IO 密集型任务的效率,但前提是要想清楚共享资源和异常处理的问题。
3.边写边调试的过程中,其实是在不断理解“浏览器如何加载页面”和“网页如何组织资源”的过程,这比单纯背 API 更有意思。
作业2
1)实验内容
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
这里我爬取的是新浪股票的京交所的行情页面,爬取了5页,每页40个。
代码说明
这是项目结构
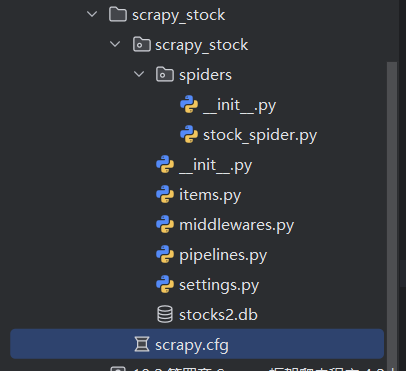
这是项目的item,他详细介绍了项目的变量结构,服务于通道
import scrapy
class StockItem(scrapy.Item):
code = scrapy.Field() # 股票代码
name = scrapy.Field() # 股票名称
trade = scrapy.Field() # 最新价
pricechange = scrapy.Field() # 涨跌额
changepercent = scrapy.Field() # 涨跌幅
buy = scrapy.Field() # 买入
sell = scrapy.Field() # 卖出
settlement = scrapy.Field() # 昨收
open = scrapy.Field() # 今开
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
volume = scrapy.Field() # 成交量/手
amount = scrapy.Field() # 成交额/万
这是项目的通道,用于爬取文件的交换,储存,数据库的搭建
import sqlite3
class StockDBPipeline:
def open_spider(self, spider):
"""创建数据库与表"""
self.con = sqlite3.connect('stocks2.db')
self.cursor = self.con.cursor()
try:
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
code TEXT PRIMARY KEY,
name TEXT,
trade TEXT,
pricechange TEXT,
changepercent TEXT,
buy TEXT,
sell TEXT,
settlement TEXT,
open TEXT,
high TEXT,
low TEXT,
volume TEXT,
amount TEXT
)
""")
except Exception as e:
print(f"创建数据库表失败: {e}")
def process_item(self, item, spider):
"""插入或更新股票数据"""
try:
self.cursor.execute("""
INSERT OR REPLACE INTO stocks
(code, name, trade, pricechange, changepercent, buy, sell, settlement, open, high, low, volume, amount)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
item['code'], item['name'], item['trade'], item['pricechange'],
item['changepercent'], item['buy'], item['sell'], item['settlement'],
item['open'], item['high'], item['low'], item['volume'], item['amount']
))
self.con.commit()
except Exception as e:
print(f"插入数据失败: {e}")
return item
def close_spider(self, spider):
"""关闭数据库连接"""
self.con.close()
这是项目的设置,在这里设置项目的名字,超参数
BOT_NAME = 'scrapy_stock'
SPIDER_MODULES = ['scrapy_stock.spiders']
NEWSPIDER_MODULE = 'scrapy_stock.spiders'
ROBOTSTXT_OBEY = True
# 启用数据库存储的Pipeline
ITEM_PIPELINES = {
'scrapy_stock.pipelines.StockDBPipeline': 1,
}
# 设置下载延迟,避免请求过快被封
DOWNLOAD_DELAY = 2
# 配置并发请求数
CONCURRENT_REQUESTS = 1
这是项目的爬虫主体,使用抓包的方法获取json文件,在解析他的格式
import scrapy
from scrapy_stock.items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['vip.stock.finance.sina.com.cn']
start_urls = [
'https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page=1&num=40&sort=changepercent&asc=0&node=hs_a&symbol=&_s_r_a=init'
]
# 设置爬取的最大数量
MAX_ITEMS = 200
def parse(self, response):
"""解析页面数据"""
# 获取JSON数据
stock_data = response.json()
# 处理每个股票的数据
for item in stock_data:
# 当前页面爬取的数量
total_scraped = self.crawler.stats.get_value('item_scraped_count', 0)
# 如果已经爬取了200条数据,停止爬取
if total_scraped >= self.MAX_ITEMS:
self.logger.info("达到最大爬取条数 200,停止爬取")
return # 停止继续爬取
stock_item = StockItem()
stock_item['code'] = item.get('symbol')
stock_item['name'] = item.get('name')
stock_item['trade'] = item.get('trade')
stock_item['pricechange'] = item.get('pricechange')
stock_item['changepercent'] = item.get('changepercent')
stock_item['buy'] = item.get('buy')
stock_item['sell'] = item.get('sell')
stock_item['settlement'] = item.get('settlement')
stock_item['open'] = item.get('open')
stock_item['high'] = item.get('high')
stock_item['low'] = item.get('low')
stock_item['volume'] = item.get('volume')
stock_item['amount'] = item.get('amount')
# Yield the stock item to the pipeline
yield stock_item
# 检查是否有下一页数据
# 获取当前URL中的分页信息
current_page = int(response.url.split('page=')[-1].split('&')[0]) # 获取当前页码
next_page_num = current_page + 1
next_url = f'https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page={next_page_num}&num=40&sort=changepercent&asc=0&node=hs_a&symbol=&_s_r_a=init'
# 如果当前页的数据不为空且爬取数量未达到200,继续爬取下一页
if stock_data:
total_scraped = self.crawler.stats.get_value('item_scraped_count', 0)
if total_scraped < self.MAX_ITEMS:
yield scrapy.Request(next_url, callback=self.parse)
def close_spider(self, spider):
"""在爬虫结束时输出爬取的总数"""
total_items = self.crawler.stats.get_value('item_scraped_count')
print(f"总共爬取了 {total_items} 条股票数据。")
结果展示
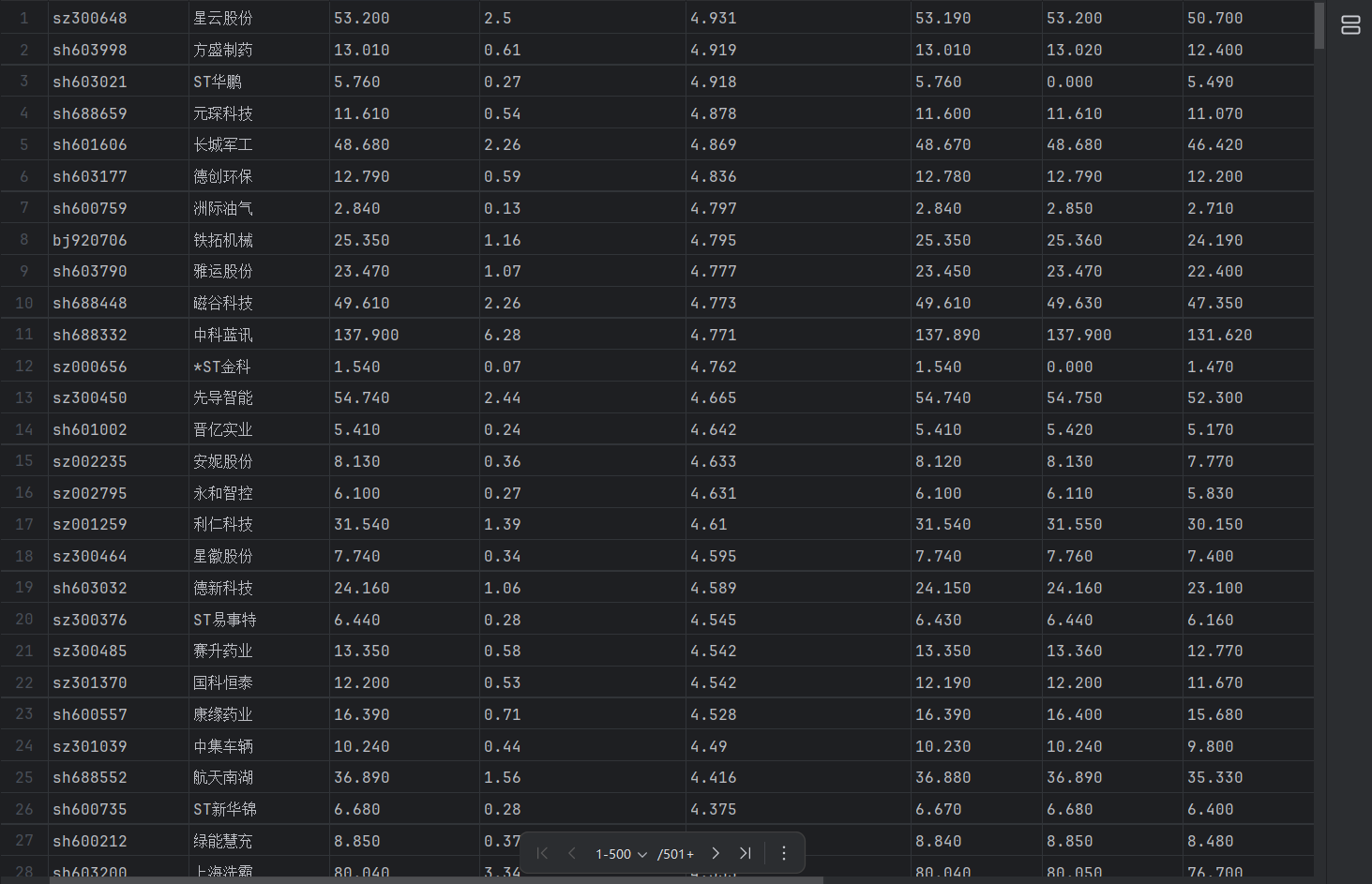
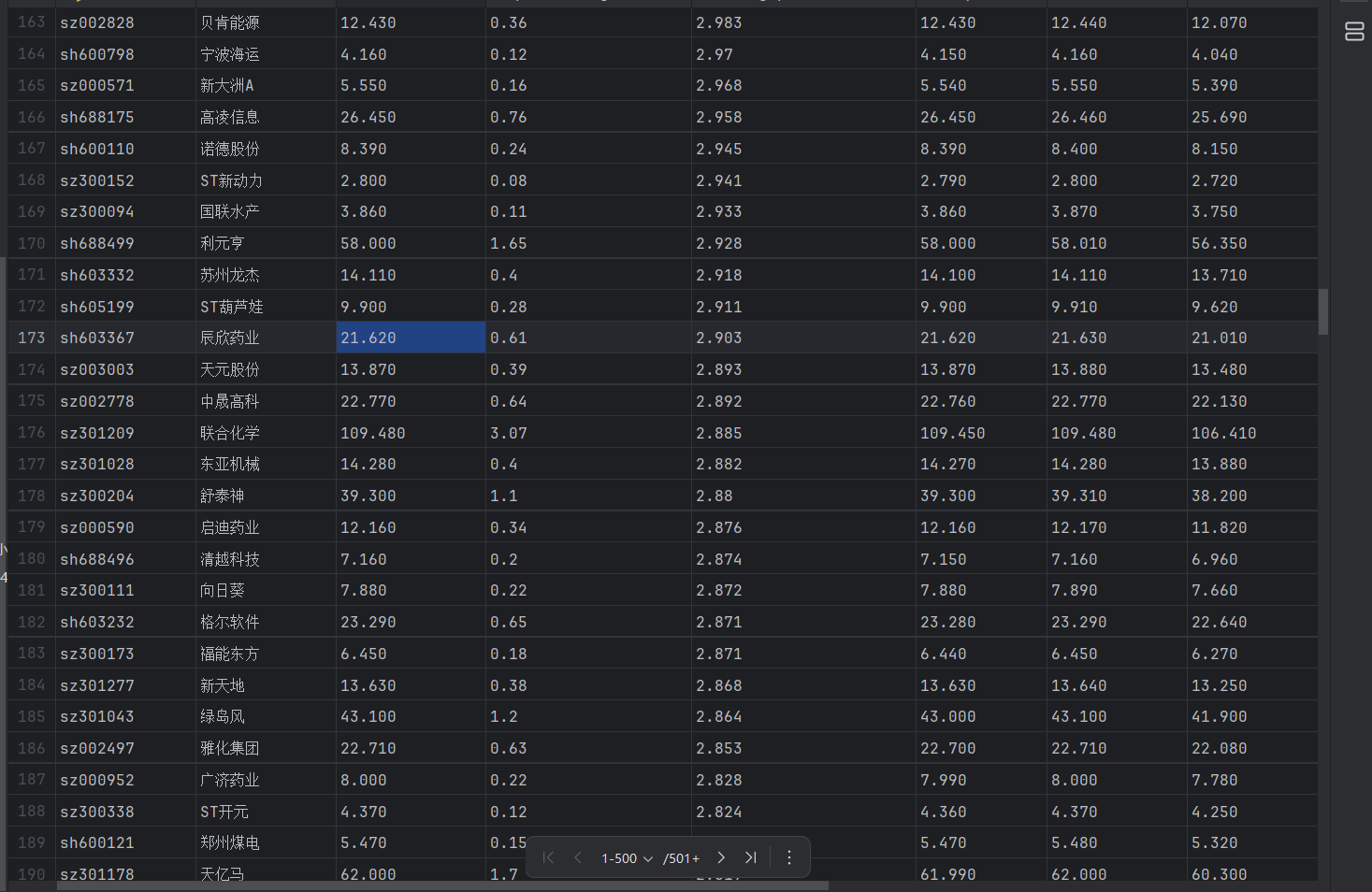
2)心得体会
scrapy项目结构清晰,爬取与储存分离,但是我没有解决爬取动态页面的问题,只能使用抓包来另辟蹊径,也是比较遗憾。返回的json文件比较结构化,所以不怎么需要匹配,直接load就可以了。
Gitee文件夹链接:https://gitee.com/zhuang-jingxuan/data/tree/master/作业代码/第三次作业/scrapy_stock
作业3
1)实验内容
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
爬取网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码说明
项目结构展示:
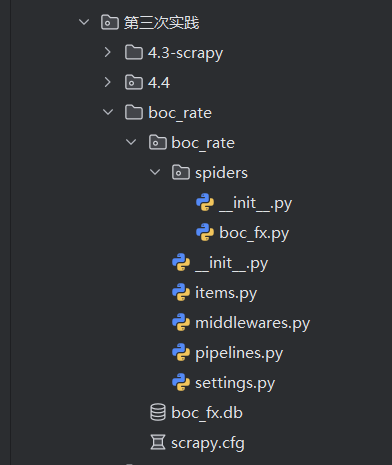
这是项目的item,他详细介绍了项目的变量结构,服务于通道
# boc_rate/items.py
import scrapy
class BocRateItem(scrapy.Item):
currency_name = scrapy.Field() # 货币名称
buy_spot = scrapy.Field() # 现汇买入价
buy_cash = scrapy.Field() # 现钞买入价
sell_spot = scrapy.Field() # 现汇卖出价
sell_cash = scrapy.Field() # 现钞卖出价
middle_rate = scrapy.Field() # 中行折算价
pub_date = scrapy.Field() # 发布日期
pub_time = scrapy.Field() # 发布时间
这是项目的通道,用于爬取文件的交换,储存,数据库的搭建
# boc_rate/pipelines.py
import sqlite3
class BocFxDBPipeline:
def open_spider(self, spider):
self.con = sqlite3.connect('boc_fx.db')
self.cursor = self.con.cursor()
try:
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS boc_fx (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency_name TEXT,
buy_spot TEXT,
buy_cash TEXT,
sell_spot TEXT,
sell_cash TEXT,
middle_rate TEXT,
pub_date TEXT,
pub_time TEXT,
UNIQUE(currency_name, pub_date, pub_time)
)
""")
self.con.commit()
except Exception as e:
print(f"创建数据库表失败: {e}")
def process_item(self, item, spider):
try:
self.cursor.execute("""
INSERT OR REPLACE INTO boc_fx
(currency_name, buy_spot, buy_cash, sell_spot, sell_cash, middle_rate, pub_date, pub_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
item.get('currency_name'),
item.get('buy_spot'),
item.get('buy_cash'),
item.get('sell_spot'),
item.get('sell_cash'),
item.get('middle_rate'),
item.get('pub_date'),
item.get('pub_time'),
))
self.con.commit()
except Exception as e:
print(f"插入数据失败: {e}")
return item
def close_spider(self, spider):
self.con.close()
这是项目的设置,在这里设置项目的名字,超参数
BOT_NAME = "boc_rate"
SPIDER_MODULES = ["boc_rate.spiders"]
NEWSPIDER_MODULE = "boc_rate.spiders"
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
),
"Accept-Language": "zh-CN,zh;q=0.9",
}
ITEM_PIPELINES = {
"boc_rate.pipelines.BocFxDBPipeline": 300,
}
# 输出文件(如果你用 -o 导出)保证中文 UTF-8
FEED_EXPORT_ENCODING = "utf-8"
这是项目的爬虫主体,使用抓包的方法获取json文件,在解析他的格式
import scrapy
from boc_rate.items import BocRateItem
class BocRateSpider(scrapy.Spider):
name = "boc_rate"
allowed_domains = ["boc.cn"]
def start_requests(self):
"""
第1页: index.html
第2~10页: index_1.html ~ index_9.html
"""
base = "https://www.boc.cn/sourcedb/whpj/"
# 第 1 页
yield scrapy.Request(base + "index.html", callback=self.parse)
# 第 2~10 页
for i in range(1, 10): # 如果以后有更多页,可以把 10 改大一点
url = f"{base}index_{i}.html"
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
"""
解析每一页的外汇牌价表格
"""
table = response.xpath(
'//table[.//tr[1]/th[1][contains(normalize-space(.),"货币名称")]][1]'
)
rows = table.xpath('.//tr[position() > 1]')
for row in rows:
tds = row.xpath('./td')
if len(tds) < 8:
continue
item = BocRateItem()
item["currency_name"] = tds[0].xpath("normalize-space(text())").get()
item["buy_spot"] = tds[1].xpath("normalize-space(text())").get()
item["buy_cash"] = tds[2].xpath("normalize-space(text())").get()
item["sell_spot"] = tds[3].xpath("normalize-space(text())").get()
item["sell_cash"] = tds[4].xpath("normalize-space(text())").get()
item["middle_rate"] = tds[5].xpath("normalize-space(text())").get()
pub_dt_text = tds[6].xpath("normalize-space(text())").get() or ""
parts = pub_dt_text.split()
if len(parts) == 2:
item["pub_date"] = parts[0]
item["pub_time"] = parts[1]
else:
item["pub_date"] = pub_dt_text
item["pub_time"] = tds[7].xpath("normalize-space(text())").get()
yield item
结果展示
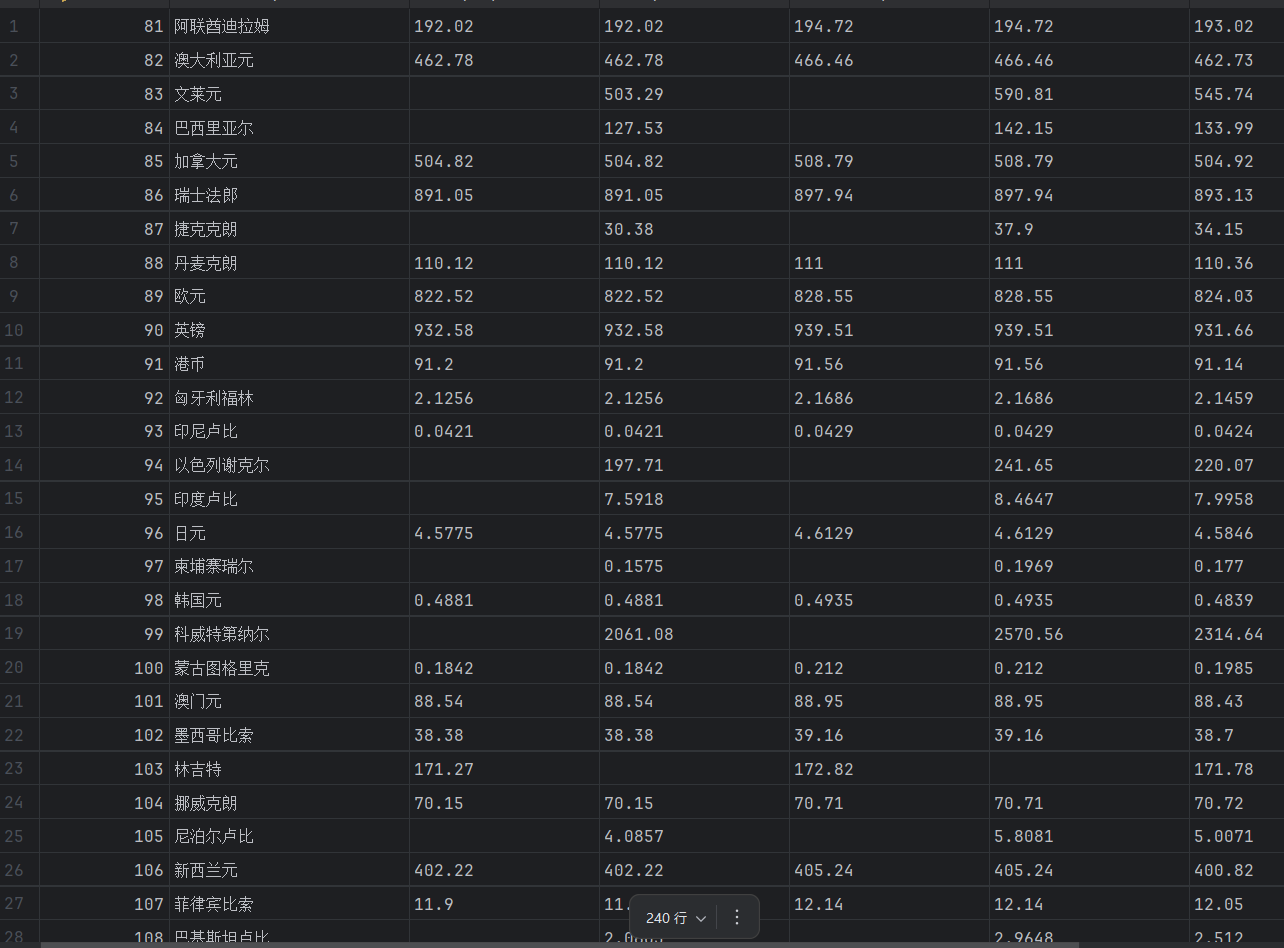
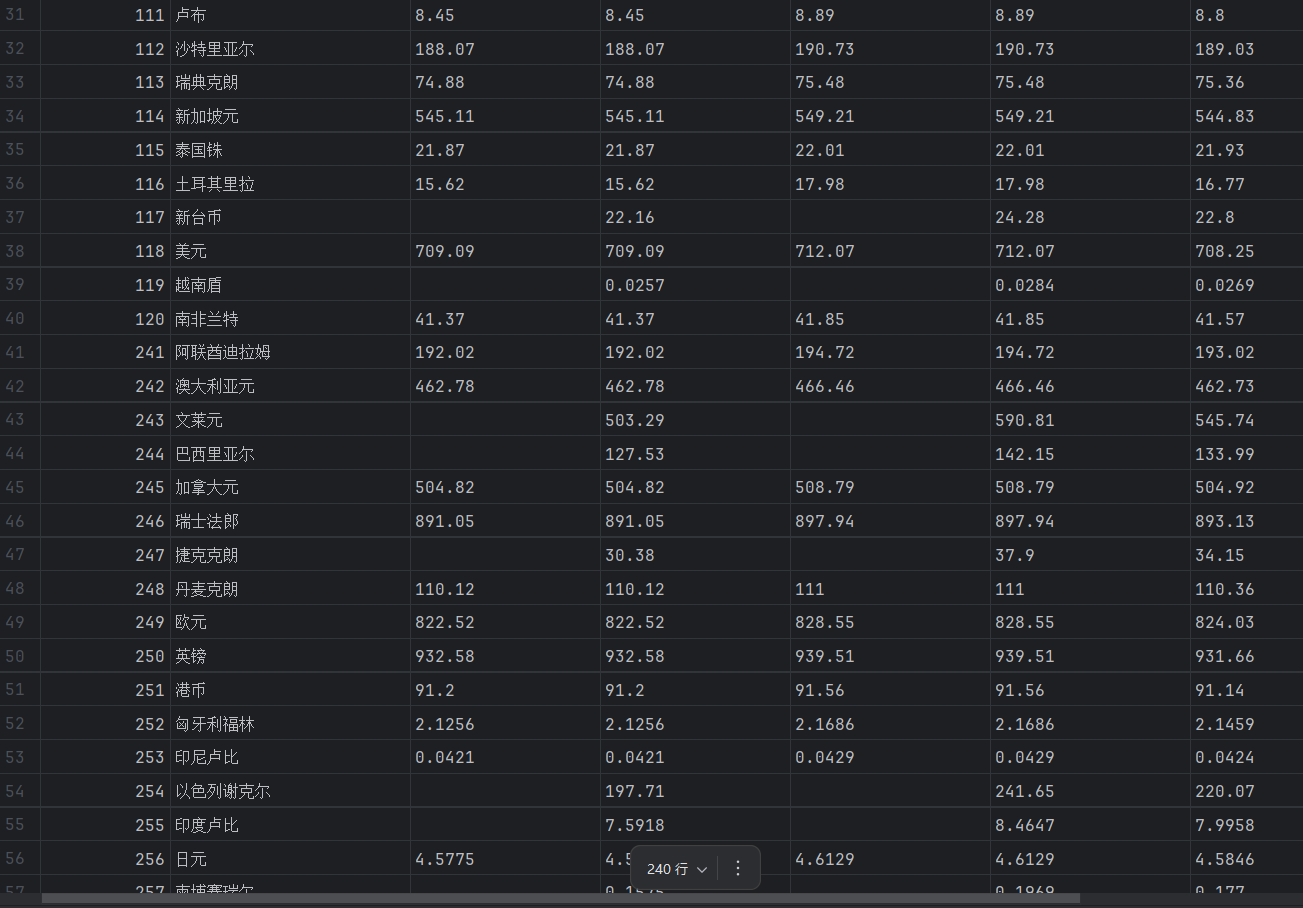
2)心得体会
这一题我做的挺懵逼的,因为他给的网页每一页的数据全部都一模一样,我也不知道为什么,反正就爬取完了,存到DB里。
Gitee文件夹链接:https://gitee.com/zhuang-jingxuan/data/tree/master/作业代码/第三次作业/boc_rate

 浙公网安备 33010602011771号
浙公网安备 33010602011771号