
文本分类算法之TextRCNN模型
概述
就深度学习领域来说,RNN和CNN作为文本分类问题的主要模型架构,都存在各自的优点及局限性。
- RNN的优势是擅长处理序列结构,能够考虑到句子的上下文信息,但RNN属于“biased model”,后送入模型的单词会比之前的单词更重要。在使用RNN获取整个文档的语义时,RNN的偏倚会降低模型的效果,因为关键部分是可能出现在句子的任意位置的。
- CNN属于无偏模型,能够通过最大池化获得最重要的特征,但是CNN的滑动窗口大小不容易确定,选的过小容易造成重要信息丢失,选的过大会造成巨大参数空间。
为了解决RNN、CNN两个模型各自存在的问题,论文Recurrent Convolutional Neural Networks for Text Classification提出了一种叫做RCNN的模型架构,
- 用双向循环结构来尽可能多地获取上下文信息,这比传统的基于窗口的神经网络更能减少噪声,而且在学习文本表达时可以大范围的保留词序。
- 其次使用最大池化层获取文本的重要部分,自动判断哪个特征在文本分类过程中起更重要的作用。
这里解释一下为啥叫做 RCNN:
- 在TextCNN网络中,网络结构是卷积层+池化层的形式,卷积层用于提取n-gram类型的特征,
- 在RCNN中,卷积层的特征提取的功能被双向RNN替代,因此整体结构变为了双向RNN+池化层,所以叫RCNN,就有那么点 RCNN 的味道。
下面我们会详细地介绍RCNN的网络架构。通过加入RNN,比纯CNN提升了1-2个百分点。
网络架构
RCNN的网络架构如下图所示:
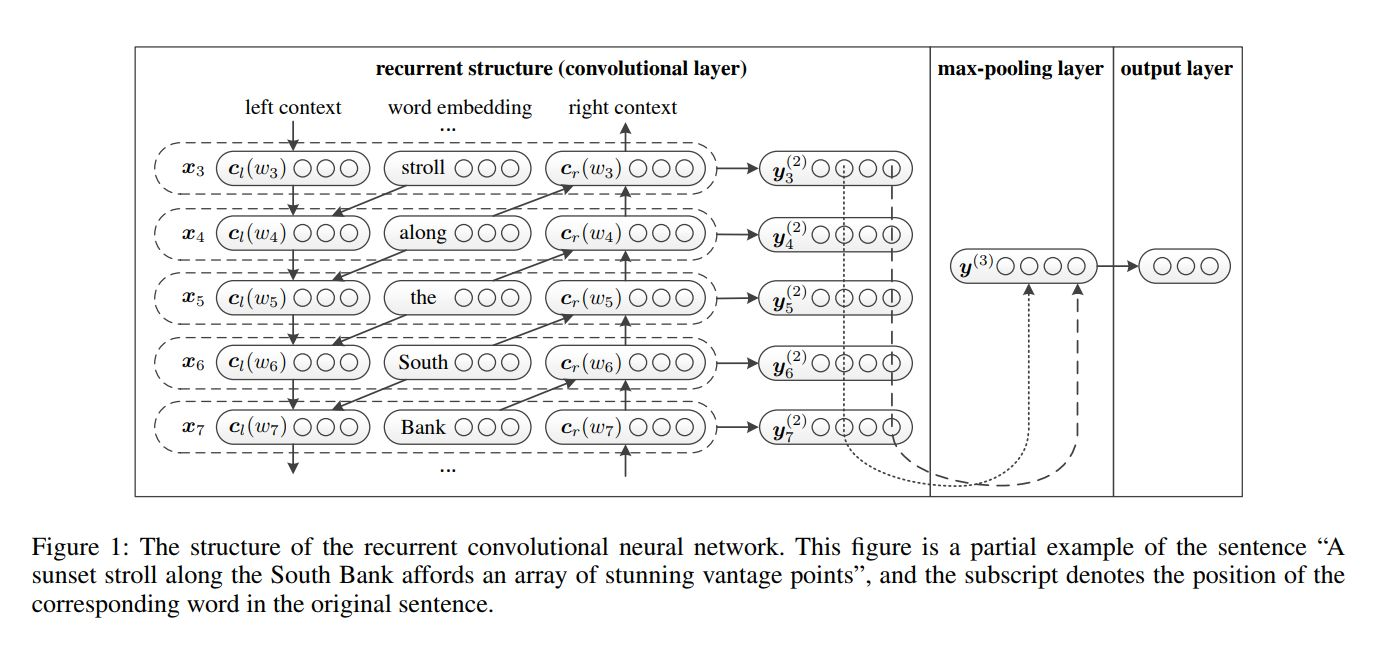
模型的前向过程是:
- 首先将词进行词向量编码,即第一栏中间的word embedding 层;得到单词\(w_i\)的表示\(e(w_i)\).
- 利用前向和后向RNN得到每个词的前向和后向上下文的表示:
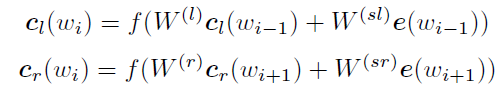
文中说,这么做的好处是,可以抓到词汇更多的上下文信息。注意这里的使用的RNN不是我们常见的RNN,我们在实现时会使用我们常见的LSTM。
将这两个向量和\(e(w_i)\)拼接起来就得到单词\(w_i\)的表示:
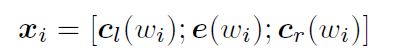
- 再把词的表示经过一个变换和tanh激活函数,得到词的最终表示:
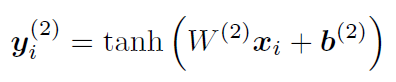
- 当所有的词表示都计算完成后,模型对所有词表示的同一位使用了max-pooling:
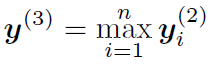
这样模型将变长的文本转换为了固定长度的向量。 - 然后将这个句子的表示向量喂进一个全连接softmax层进行分类概率预测。
pytorch实现中的关键代码部分
这里给出pytorch代码实现中的关键的代码部分,至于整个的代码流程的其它部分,这里不再详述。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class TextRCNN(nn.Module):
def __init__(self, config):
super(TextRCNN, self).__init__()
if config.embedding_pretrained is not None:
#模型的嵌入层
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embeding_size, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embeding_size, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.W2 = nn.Linear(2 * config.hidden_size + config.embeding_size, config.output_size)
self.maxpool = nn.MaxPool1d(config.max_seq_len)
self.fc = nn.Linear(config.output_size, config.num_classes)
def forward(self, x):
#x:[batch_size, seq_len, embeding_size]
embed = self.embedding(x)
out, _ = self.lstm(embed)
xx = torch.cat((embed, out), 2)
y2 = torch.tanh(self.W2(xx)).permute(0, 2, 1)
y3 = self.maxpool(y2).squeeze(2)
out = self.fc(y3)
return out
参考
TextRCNN 阅读笔记
篇章级建模_RCNN
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号