

HBase 10分钟快速入门
hbase这种基于列族的数据库 使用phoenix套娃后就能用sql操作,与mysql一样简单。
当然这里不讲phoenix,只讲hbase基础用法。
Introduction
HBase offers an alternative to Hive which is based on HDFS and has a write-once, read-many approach.
HBase is a column-oriented NoSQL system based in Google's Big Table and built on top of HDFS
Ideal for:
- Large, sparsely populated tables
- Real-time processing
- Read/write random access
Characterized as a sparse, distributed, multi-dimensional, sorted map
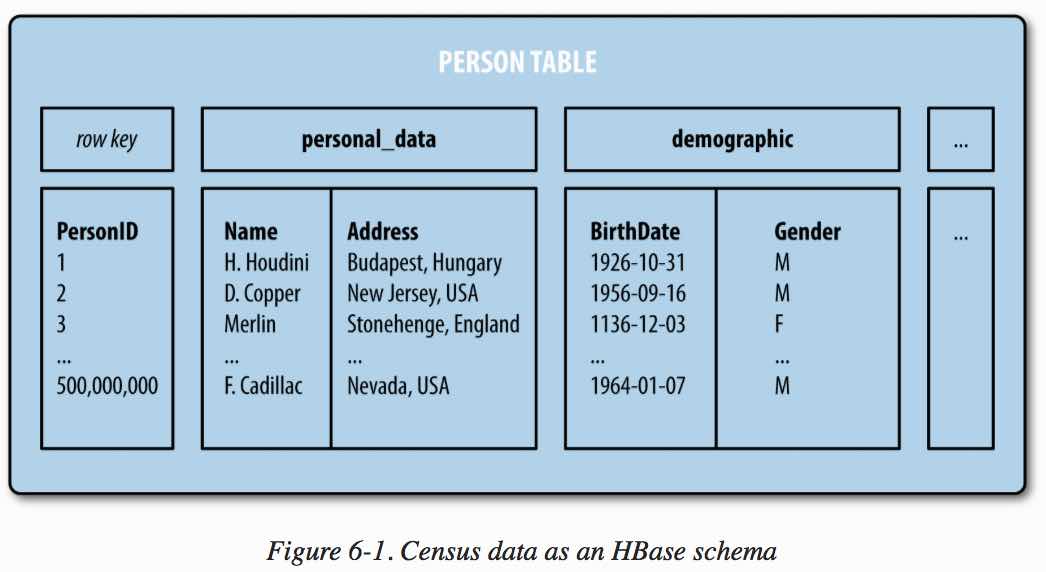
HBase organizes the data as column-oriented with column families. Rows are kept organized by the same row-key. Data from a classic tuple may be separately stored in different columns.
HBase offers:
- Random (row-level) read/write access
- Strong consistency
- "Schema-less" or flexible data modeling
Differences from relational tables:
- Cell values are uninterpreted byte arrays (no notion of different data types)
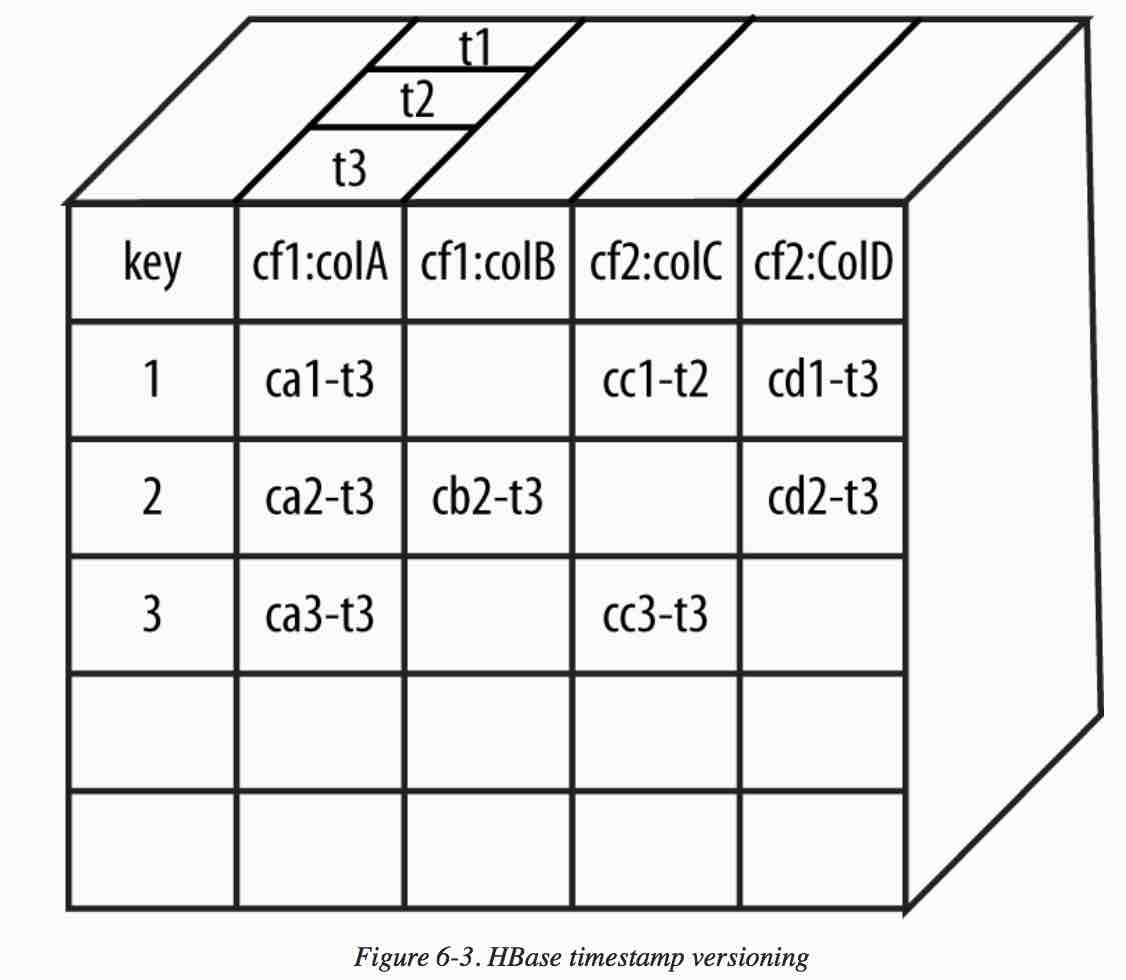
- Individual cells of a table can be versioned, storing the history of values for a cell
- Each row has a row key, with the table sorted by the row key
- Atomicity is only guaranteed at the row level (no atomicity for multi-row updates)
- Major difference: Columns in Hbase are not the same as columns in relational tables!
HBase and RDBMS comparison
| HBase | RDBMS |
|---|---|
| HBase is schema-less, it doesn't have the concept of fixed columns schema; defines only column families. | An RDBMS is governed by its schema, which describes the whole structure of tables. |
| It is built for wide tables. HBase is horizontally scalable. | It is thin and built for small tables. Hard to scale. |
| No transactions exist in HBase. | RDBMS is transactional. |
| It has de-normalized data tables. | It will have normalized data. |
| It is good for semi-structured as well as structured data. | It is good for structured data. |
Features of HBase
- HBase is linearly scalable.
- It has automatic failure support.
- It provides consistent read and writes.
- It integrates with HDFS, both as a source and a destination.
- It has easy java API for client.
- It provides data replication across clusters.
- It provides fast random access to available data.
Columns in HBase:
- Columns are known as column qualifiers
- Column qualifiers are organized into column families
- Column families conceptually organize column qualifiers into groups that have the same access patterns
- Column families must be defined when a table is created
- The number of column qualifiers in a column family is dynamic and can be defined as needed, giving HBase flexibility for dealing with unstructured data
- The number of column families should be limited to no more than two or three families for storage efficiency
Data that has missing data can be stored more efficiently as sparse columns as in this social media example:
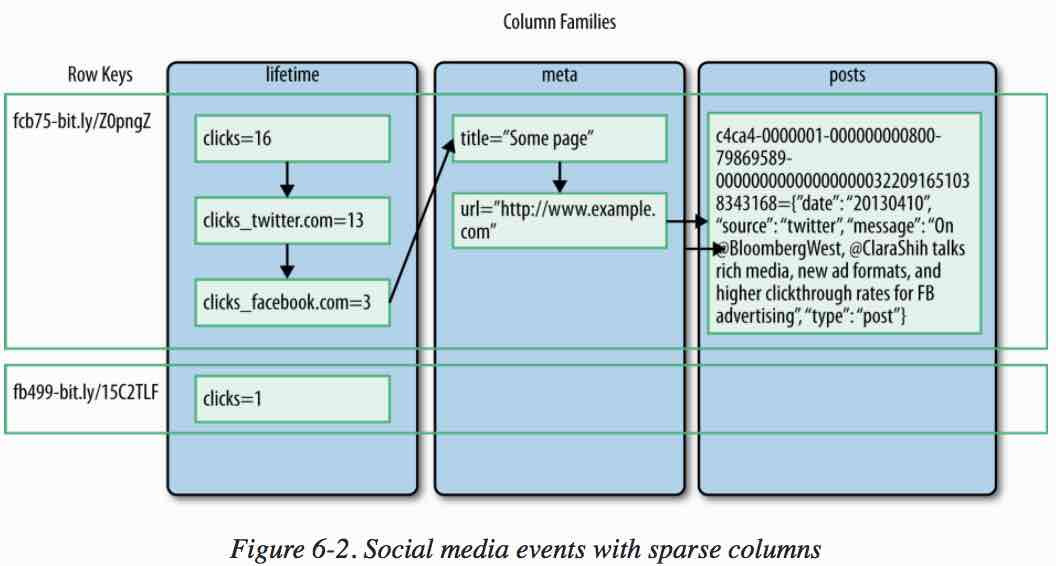
Table cells are also stored as version each with a UTC timestamp:
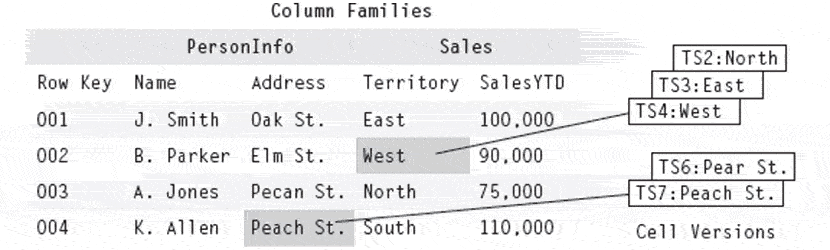
Two column families: PersonInfo and Sales
PersonInfo column family has two column qualifiers: Name and Address
Sales column family has two column qualifiers: Territory and SalesYTD
All values have a timestamp
Territory for row key 002 has multiple values that have changed over time (same for Address of row key 004)
The above can be represented as this JSON -like map:
{"001" : {"PersonInfo" :
{"Name" :
{TS1: "J. Smith"}
"Address" :
{TS1: "Oak St"}}
"Sales" :
{"Territory" :
{TS1: "East"}
"SalesYTD" :
{TS1: "100,000"}}}
"002" : {"PersonInfo" :
{"Name" :
{TS2: "B. Parker"}
"Address" :
{TS2: "Elm St."}}
"Sales" :
{"Territory" :
{TS4: "West"
TS3: "East"
TS2: "North"}
"SalesYTD" :
{TS2: "90,000"}}}
…}
Hbase table design issues
More complex than relational table design as table design is driven by data access patterns.
Tables should be structured to return data in an efficient manner.
Important considerations:
- What values should compose the key?
- What column families are needed (specified at table creation)?
- What column qualifiers are associated with each column family?
HBase Shell Environment
Allows a user to interactively
- Create tables
- Insert data
- Retrieve data
Main commands
- create
- put
- get
- scan
Example create tablename, family-name....
hbase> create 'salesPerson', 'personinfo', 'sales'
Alternate syntax with version specification
hbase> create 'salesperson', {NAME => 'personinfo', VERSIONS => 3}, {NAME => 'sales', VERSIONS => 3}
Data manipulation
The put command is used to write a single cell
hbase> put 'salesPerson','001','personinfo:name','J. Smith'
hbase> put 'salesperson','001','personinfo:address','Oak St.'
hbase> put 'salesperson','001','sales:territory','East'
hbase> put 'salesperson','001','sales:salesytd','100,000'
To change a cell value, use the put command to write to the same cell. Hbase will automatically assign timestamps to each cell version
hbase> put 'salesPerson','002','sales:territory','North'
hbase> put 'salesPerson','002','sales:territory','East'
Retrieve all contents of a row
hbase> get 'salesperson','001'
Restrict data of a row to a time stamp range
hbase> get 'salesperson', 001',{TIMERANGE =>[ts1, ts5]}
Retrieve a specific column value of a row
hbase> get 'salesperson','001,{COLUMN => 'personinfo:name'}
Retrieve several column values of a row
hbase> get 'salesperson','001',{COLUMN => ['personinfo:name','personinfo:address']}
Indicate number of versions to retrieve
hbase> get 'salesperson','001',{COLUMN => ['personinfo:name','personinfo:address'],VERSIONS => 3}
Filters can be specified on columns
hbase> get 'salesperson','001',{FILTER => "ValueFilter(=,'binary:Oak St.')"}
A ValueFilter is used to filter cell values using a comparison operator and a comparator (in single quotes).
The comparator indicates a comparison type together with a value separated by a colon
Comparison types:
- binary (byte-to-byte comparison of values)
- binaryprefix (a cell should begin with the value)
- regexstring (specifies a pattern for the value)
The following statement will read the entire table and print the data in key-value pair format:
hbase> scan 'salesperson'
Specify start and stop row keys for the scan
hbase> scan 'salesperson',{STARTROW =>'001',STOPROW => '003'}
Specify a timestamp for the data to retrieve
hbase> scan 'salesperson', {TIMESTAMP => TS1}
Scan and return key-value pairs of the indicated columns
hbase> scan 'salesperson',{COLUMN => ['personinfo:name','personinfo:address']}
Scan and return key-value pairs of all columns in a column family
hbase> scan 'salesperson',{COLUMN => 'personinfo'}
文章来源 https://jcsites.juniata.edu/faculty/rhodes/smui/hbase.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号