
Pytorch快速入门
Pytorch快速入门
常用功能的简单使用,到最终模型构建。
- Dataset的使用
- DataLoader的使用
- Transforms的使用
- torchvision中数据集的使用
- Tensorboard的使用
- 对现有网络进行修改
- 模型的保存与读取
- Pytorch创建模型套路
Dataset的使用
Pytorch中提供的一种方式去获取数据集及其对应的标签。
from torch.utils.data import Dataset
from PIL import Image
import os
# 自定义Dataset时,需要继承Dataset类,并重写__init__、__getitem__、__len__三个函数
class MyData(Dataset):
# 类初始化,用于设置数据集和对应标签路径,可以更具情况进行调整
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
# 通过idx获取数据及标签
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
# 返回数据集长度
def __len__(self):
return len(self.img_path)
root_dir = "./hymenoptera_data/train/"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
img, label = bees_dataset[1]
img.show()
DataLoader的使用
用于从Dataset中取出数据,为网络提供不同的数据形式。
import torchvision
from torch.utils.data import DataLoader
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
# dataset设置需要取出的数据集
# batch_size设置每次取出多少数据
# shuffle设置是否打乱顺序
# drop_last设置是否丢弃多余的数据(数据集长度除以batch_size的余数对应的数据)
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, drop_last=True)
step = 0
for data in test_loader:
imgs, targets = data # 每一对都是已经对应好的batch数据集
step += 1
torchvision中数据集的使用
以CIFAR10数据集为例
# root数据集保存的路径
# train设置是否下载训练集,当为True时下载训练集为False时就下载测试集
# download设置是否进行下载
# transform设置转换器
# 创建转换器
trans_resize = transforms.Resize(32)
trans_tensor = transforms.ToTensor()
# 使用Compose
trans_compose = transforms.Compose([trans_resize, trans_tensor])
train_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=True, transform=trans_compose, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=False, transform=trans_compose, download=True)
Transforms的使用
这里的transforms指的是torchvision中的transforms,其作用是对图片进行缩放,翻转等预处理处理。
例如我们要将最原始的图片PIL类型转换为Tensor类型,那么就要使用torchvision.transforms.ToTensor()对图片进行转换处理。
from PIL import Image
from torchvision import transforms
img_path = "dog.jpg"
img = Image.open(img_path)
# 创建转换器
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) # 得到转换后的数据才能输入到模型中
print(tensor_img)
对于transforms.Compose()可以理解为一个容器,对传入的转换列表依次进行处理。
from PIL import Image
from torchvision import transforms
img_path = "dog.jpg"
img = Image.open(img_path)
# 创建转换器
trans_resize = transforms.Resize(32)
trans_tensor = transforms.ToTensor()
# 使用Compose
trans_compose = transforms.Compose([trans_resize, trans_tensor])
tensor_img = trans_compose(img) # 得到转换后的数据才能输入到模型中
print(tensor_img)
Tensorboard的使用
TensorBoard 是一组用于数据可视化的工具。
这里我们将训练过程进行可视化。
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs") # 写入文件
image_path = "./hymenoptera_data/train/ants/1030023514_aad5c608f9.jpg"
img = Image.open(image_path)
img_array = np.array(img)
writer.add_image("train", img_array, 2, dataformats="HWC")# 记录图片
for i in range(100):
writer.add_scalar("y=2x", 3*i, i) #记录数值
writer.close() # 结束
对现有网络进行修改
这里以vgg16模型为例,在原有模型基础上新加一层。
import torchvision
from torchvision.datasets import CIFAR10
from torch.nn import Linear
# weights参数设置是否使用已经训练好的参数
# 可以通过导入对应的模型参数进行设置
# 设置为None则是不使用,即需要重新训练参数
vgg16_true = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.IMAGENET1K_V1)
vgg16_false = torchvision.models.vgg16(weights=None)
print(vgg16_true)
# 在整个模型最后添加一层
# vgg16_true.add_module('add_linear', Linear(1000, 10))
# 在模型的classifier下添加一层
vgg16_true.classifier.add_module('add_linear', Linear(1000, 10))
print(vgg16_true)
模型的保存与读取
模型的保存:
import torch
import torchvision
vgg16 = torchvision.models.vgg16(weights=None)
# 保存方式一
# 将模型架构和训练好的参数一起进行保存
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式二
# 将模型里的参数保存为python的字典格式
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
模型的读取:
import torch
import torchvision
# 方式一:加载模型
# 加载自定义模型时需要,需要将对应的模型类放到加载文件中
model = torch.load("MyModel_10.pth")
print(model)
# 方式二:加载模型(字典)
# weights_dict = torch.load("vgg16_method2.pth")
# vgg16 = torchvision.models.vgg16(weights=None)
# vgg16.load_state_dict(weights_dict)
# print(vgg16)
Pytorch创建模型套路
利用Pytorch框架创建模型,这里以CIFAR10 model为例。
CIFAR10 model struct:
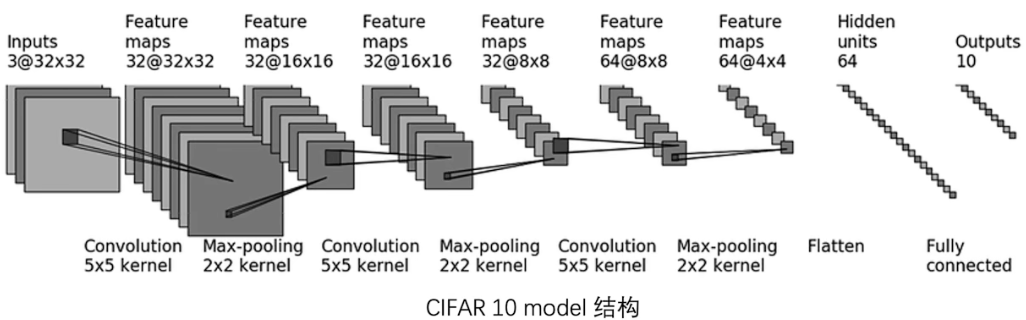
构建模型
import torch
from torch.nn import Module, Sequential, Conv2d, MaxPool2d, Flatten, Linear
# 搭建神经网络
# 自定义神经网络时需要继承Module模块
class MyModel(Module):
def __init__(self) -> None:
super(MyModel, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=(5, 5), stride=1, padding=2),
MaxPool2d(kernel_size=(2, 2)),
Conv2d(in_channels=32, out_channels=32, kernel_size=(5, 5), stride=1, padding=2),
MaxPool2d(kernel_size=(2, 2)),
Conv2d(in_channels=32, out_channels=64, kernel_size=(5, 5), stride=1, padding=2),
MaxPool2d(kernel_size=(2, 2)), # 输出形状(64, 4, 4)
Flatten(),
Linear(64 * 4 * 4, 64),
Linear(64, 10)
)
def forward(self, x):
y = self.model(x)
return y
# 单独验证模型的输入输出是否正确
# 加载数据集训练前判断模型架构是否正确
if __name__ == '__main__':
mymodel = MyModel()
x = torch.ones((64, 3, 32, 32)) # 按dataloader里的形状创建测试数据
y = mymodel(x)
print(y.shape)
从图中可知输入数据的形状是(N, 3, 32, 32),即N个3通道的32×32的图片。
图片中没有给出卷积层的padding值和stride值,可以利用以下公式进行求解:
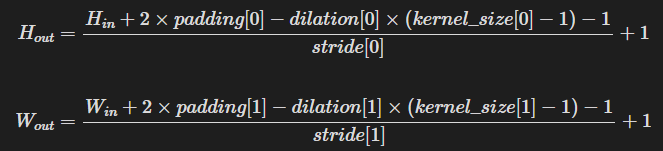
这里以第一个卷积层的padding计算为例,dilation未设置,其默认值为1,stride设置为1,从图中第一个输入层得到,输入是32,kernel为5,输出为32推出padding为2
训练模型:
import torch
import torchvision
from model import MyModel # 从model.py文件中导入写好的模型
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
# 优先使用gpu进行计算
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=True, transform=torchvision.transforms.ToTensor(), download=True) # 加载训练数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True) # 加载测试数据集
# 查看数据集的长度
print("训练数据集的长度为:{}".format(len(train_data)))
print("测试数据集的长度为:{}".format(len(test_data)))
# 使用DataLoader加载数据集
train_dataloader = DataLoader(dataset=train_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
# 创建网络模型,即实例化写好的类
mymodel = MyModel()
# 在指定设备上运行
mymodel.to(device)
# 选择损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 在指定设备上运行
loss_fn.to(device)
# 选择优化器
learing_rate = 0.01 # 学习率
optimizer = torch.optim.SGD(mymodel.parameters(), lr=learing_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 使用tensorboard记录训练情况
writer = SummaryWriter("logs_train")
# 每一轮模型都会将训练数据集中所有的数据拿来训练一次
# 即每训练一轮,所有的训练数据都将被模型遍历一次
for i in range(epoch):
print("------第{}轮训练------".format(i + 1))
# 训练步骤开始
# 设置训练模式,仅对某些层有用
mymodel.train()
# 通过dataloader来拿数据
for data in train_dataloader:
# 训练数据batch和标签batch被dataloader对应取出
imgs, labels = data
imgs = imgs.to(device) # 在指定设备上运行
labels = labels.to(device)
predict = mymodel(imgs) # 利用模型进行预测
loss = loss_fn(predict, labels) # 计算损失
optimizer.zero_grad() # 利用优化器先将参数的梯度置0
loss.backward() # 对loss进行反向传播计算,得到参数对应的梯度
optimizer.step() # 利用优化器进行梯度更新
total_train_step += 1 # 更新总的训练次数
# 每训练一百次,打印一次
if total_train_step % 100 == 0:
print("Train_count: {}, Loss: {}".format(total_train_step, loss.item()))
# 将训练情况加入到tensorboard中
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
mymodel.eval() # 设置测试模式,仅对某些层有用
# 每训练完一轮后,利用测试数据进行测试,观察模型的训练效果
total_test_loss = 0 # 总的测试损失
total_accuracy = 0 # 总的测试准确的数量
with torch.no_grad(): # torch.no_grad()即不进行梯度计算和梯度更新,只进行预测
for data in test_dataloader:
imgs, labels = data
imgs = imgs.to(device)
labels = labels.to(device)
predict = mymodel(imgs)
loss = loss_fn(predict, labels)
total_test_loss += loss.item()
accuracy = (predict.argmax(1) == labels).sum()
total_accuracy += accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/len(test_data)))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step += 1
# 保存每一轮的训练结果
# 将模型本身和对应的参数字典一起保存
torch.save(mymodel, "MyModel_{}.pth".format(i))
# 仅保存参数字典(推荐,不用保存模型本身,可以节省空间)
# torch.save(mymodel.state_dict(), "MyModel_Dict_{}.pth".format(i))
writer.close()
验证模型:
import torch
import torchvision
from PIL import Image
from model import MyModel # 导入自定义模型
image_path = "dog.png"
image = Image.open(image_path)
image = image.convert('RGB') # 将图片设置为RGB三通道
# 设置转换器,先将图片大小重新设置为32×32,再将图片转为tensor类,即图片矩阵
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image = transform(image) # 对图片进行转换
print(image.shape)
# 由于输入是以batch为单位输入的,所以还需要增加一个维度
image = torch.reshape(image, (1, 3, 32, 32))
print(image.shape)
# 方法一:加载已经训练好的模型和对应的参数
# model = torch.load("MyModel_5.pth")
# 方法二:加载参数字典(推荐)
weights_dict = torch.load("MyModel_Dict_4.pth") # 加载参数
model = MyModel() # 创建模型实例
model.load_state_dict(weights_dict) # 给模型传入训练好的参数
print(model)
model.eval()
with torch.no_grad():
predict = model(image)
print(predict)
print(predict.argmax(1)) # 输出预测结果,即值最大的下标
Referencess
https://www.bilibili.com/video/BV1hE411t7RN/?spm_id_from=333.999.0.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号