
2020寒假(6)
今天继续进行spark实验4RDD编程初级实践,对于shell交互式编程,其中包含几种计算方法。
1.spark-shell 交互式编程
请到本教程官网的“下载专区”的“数据集”中下载 chapter5-data1.txt,该数据集包含
了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
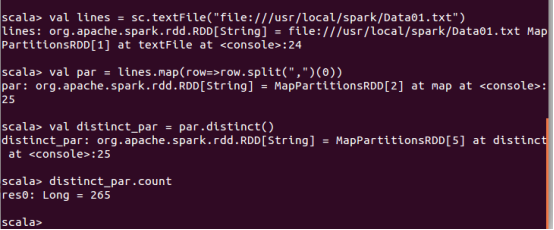
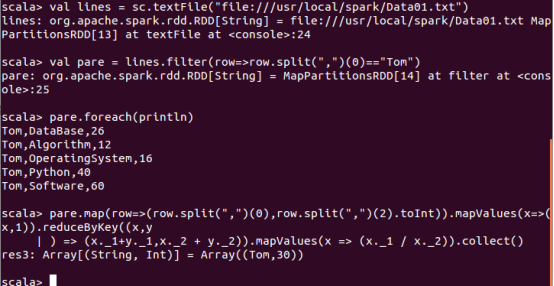
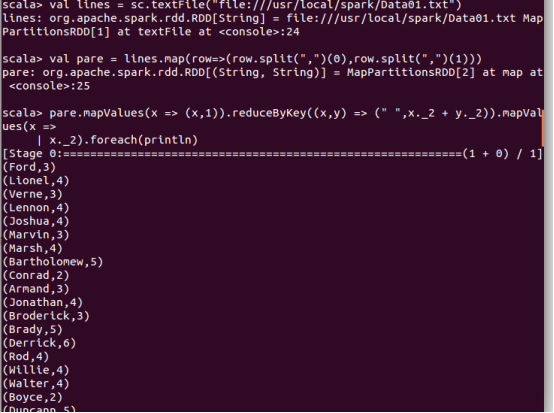
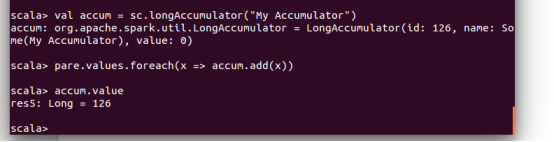
请根据给定的实验数据,在 spark-shell 中通过编程来计算以下内容:

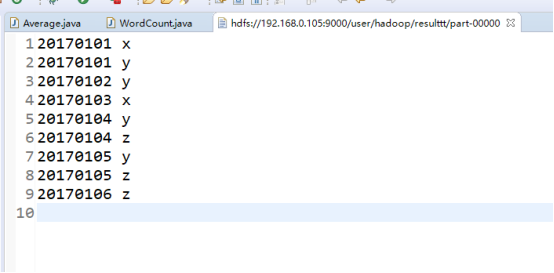
2.编写独立应用程序实现数据去重
重点:对两个文件的数据的操作,最终讲结果保存到另一个文件中,
源代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object RemDup {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("RemDup")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/spark/mycode/remdup/data1.txt,file:///usr/local/spark/mycode/remdup/data2.txt"
val data = sc.textFile(dataFile,2)
val res = data.filter(_.trim().length>0).map(line=>(line.trim,"")).partitionBy(new
HashPartitioner(1)).groupByKey().sortByKey().keys
res.saveAsTextFile("resulttt")
} }

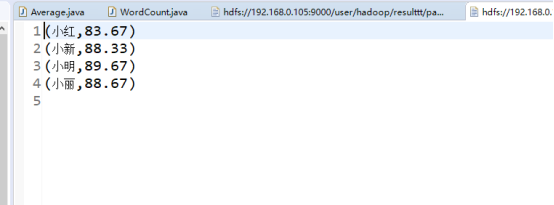
3.编写独立应用程序实现求平均值问题
重点:用到了求平均值的方法,
源代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object AvgScore {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("AvgScore")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/spark/mycode/avgscore/data3.txt"
val data = sc.textFile(dataFile,3)
val res = data.filter(_.trim().length>0).map(line=>(line.split(" ")(0).trim(),line.split
(" ")(1).trim().toInt)).partitionBy(new HashPartitioner(1)).groupByKey().map(x => {
var n = 0
var sum = 0.0
for(i <- x._2){
sum = sum + i
n = n +1
}
val avg = sum/n
val format = f"$avg%1.2f".toDouble
(x._1,format)
})
res.saveAsTextFile("result1")
} }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号