
深度学习之注意力机制
一、前提
该篇为基于实现LSTM中文情感倾向分析的基础上,为提高情感倾向预测的准确度,而引入的一个注意力机制模块,通过翻阅相关学术文献和其他资料所作的归纳总结。
二、注意力机制简介
简单来说,注意力机制与人类视觉注意力相似,正如人在看事物一样,会选择重点的对象,而忽略次要对象。近几年来,注意力机制在图片处理领域和自然语言处理领域得到广泛的应用,并展现出显著的效果。注意力机制主要是利用神经网络找到输入特征的有效部分。
三、Encoder-Decoder模型
注意力机制的框架主要是基于Encoder-Decoder框架发展而来。Encoder-Decoder模型又被称为编码-解码模型,其中Encoder会将输入的句子序列转化为一个固定长度的向量,Decoder会将该向量在转化为其他语言形式的句子序列。自然语言处理中的Encoder-Decoder框架如下图1所示(注:图片来源于网络)
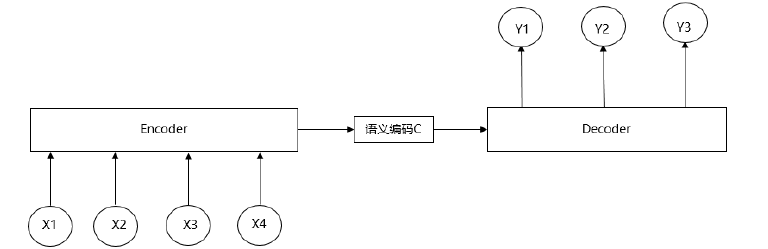
图1 Encoder-Decoder框架
给出一组文本(X,Y),其中X={x1,x2,x3,...,xn},Y={y1,y2,y3,...,ym}。Encoder对X文本进行编码处理,通过非线性变换转化,将X文本转化为中间语义C,其表达式为:
C=φ(x1,x2,x3,...,xn)
Decoder对中间语义C和已生成的历史信息{y1,y2,y3,...,yi-1}来生成i时刻的信息yi,其表达式为:
yi=φ(C,y1,y2,y3,...,yi-1)
四、Attention模型
从Encoder-Decoder框架中可以注意到,每预测一个yi所对应的语义编码都是C,说明X中的每个词汇对Y中的每个词汇的影响程度都是相同的,这样会导致语义向量无法表达整个文本的信息,使得解码效果降低。基于Encoder-Decoder框架无法突出输入序列的区分度,因而专家们提出了注意力机制使Encoder-Decoder框架缺陷得到改善。注意力机制的结构框架如图2所示:
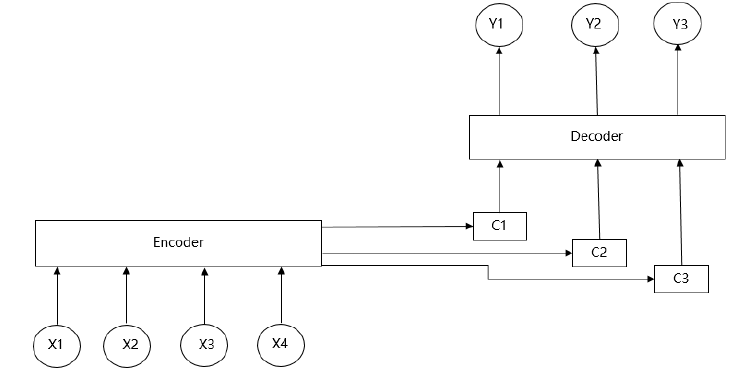
图2 注意力机制框架
当生成目标句子词汇yi时,都有唯一中间语义Ci与之对应,其中i=(1,2,3,...),其表达式如下所示:
y1=Φ(C1)
y2=Φ(C2,y1)
y3=Φ(C3,y1,y2)
以此类推,当i时刻时,
yi=Φ(Ci,y1,y2,y3,...,yi-1)
其中Ci与Encoder-Decoder框架中的中间语义C有所区别,它是一个权重处理后的权值,Ci的表达式为(注:由于博客无法使用MathType编写的公式,且本地编写困难,这里用截图代替)

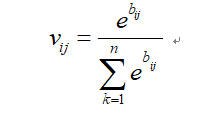
其中,Vij表示为编码中的第j个词汇与解码中的第i个词汇之间的权值,hj表示为Encoder中第j个词汇的隐向量,bij表示一个矩阵,用于衡量编码中第i个词汇对解码中的第j个词汇的影响程度。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号