Go知识点大纲
注:还有部分未整理,持续整理中...,最近更新日期:2021-4-13
1. 基本介绍
暂略
2. 安装及配置
暂略
3. 变量
func main() {
// 变量定义的三种方法
// 1. var 变量名 类型 //只定义,不赋值
// var 变量名 类型 = 值 // 定义并赋初值
var a int = 3
fmt.Println(a)
// 2. var 变量名 = 值 //类型推导
var b = 3
fmt.Println(b)
// 3. 变量名 := 值 //推荐用法
c := 3
fmt.Println(c)
// 交叉赋值
d := 1
e := 2
fmt.Println("交换前指针", &d, &e)
d, e = e, d
fmt.Println(d, e)
fmt.Println(&d, &e)
}
4. 常量
func main() {
// 常量的定义 使用 const 关键字
const a int = 3
const b = "qwerty"
fmt.Println(a, b)
}
5. 数据类型
5.1 numeric(数字)
// int/uint int8/uint8 int16/uint16 int32/uint32 int64/uint64
// float32/float64
// byte/rune
5.2 string(字符串)
// string
func main() {
var s1 string = "qwerty"
s2 := "asdfgh"
fmt.Println(s1)
fmt.Println(s2)
}
5.3 array(数组)
func main() {
//var a = [4]int{1, 2, 3, 4}
// 一维数组
a := [4]int{1, 2, 3, 4}
b := [3]string{"b1", "b2"}
c := [4]int{2: 5}
d := [...]int{1, 2, 3, 4}
// 数组赋值
a[2] = 10
fmt.Println(a, b, c)
// 数组遍历
for k, v := range a {
fmt.Println(k, v)
}
// 多维数组
d := [2][3]int{{1, 2, 3}, {4, 5, 6}}
fmt.Println(d)
}
5.4 slice(切片)
func main() {
// 切片的定义方式
// 1.申明切片
var s1[] int
fmt.Println(s1)
// 2, 使用 :=
s2 := []int{}
fmt.Println(s2)
// 3. 使用 make([]type, len, cap)
var s3[] int = make([]int, 5) //容量为5
var s4[] int = make([]int, 3, 5) //大小为3,长度为5
fmt.Println(s3, len(s3), cap(s3))
fmt.Println(s4, len(s4), cap(s4))
// 初始化赋值
var s5 = []int{1, 2, 3}
s6 := [] int{1, 2, 3}
fmt.Println(s5,s6)
// 从数组切片
arr := [5]int{1, 2, 3, 4, 5}
// var s7 = arr[1:3]
s7 := arr[1: 3]
fmt.Println(s7)
arr2 := [5]int{1, 2, 3, 4, 5}
s8 := arr2[:4]
fmt.Println(arr2, s8, len(s8), cap(s8))
s8 = append(s8, 5, 2)
fmt.Println(s8, len(s8), cap(s8))
// 对比底层数组的起始指针
fmt.Println(&arr2[0], &s8[0])
// 切片遍历与数组一样
}
5.5 Map
5.5.1 什么是 map
map 是 go 中 key-value 形式的一种数据结构,通过 key 可以获取到 value,类似于 Python 中的字典
5.5.2 map 的定义
// key 的类型:必须是支持相等运算符(==,!=)的数据类型,如数字,字符串,指针,数组,结构体,以及对应的接口类型
func main() {
/*
map 的定义
1. 使用
var 变量名 map[key 类型] value 类型 {
key1: value1,
key2: value2,
...
}
2. 使用 make 创建
变量名 := make(map[key 类型] value 类型)
赋值操作,添加,删除等...
*/
m1 := map[string] int{
"a": 1,
"b": 2,
}
fmt.Println(m1)
m2 := make(map[string] int)
m2["c"] = 3
m2["d"] = 4
fmt.Println(m2)
}
5.5.3 map 操作
func main() {
m = map[string] int{
"a": 1,
"b": 2
}
m["c"] = 3 //新增
m["a"] = 10 //修改
// 访问不存在的值,默认返回零值,但推荐使用 ok-idiom,因为返回零值无法判断元素是否存在
if v, ok := m["a"]; ok { // 判断 key 是否存在,返回 value
fmt.Println(v)
}
delete(m, "a") // 删除元素,不存在不会报错
}
5.6 pointer(指针)
5.6.1 什么是指针
- 指针就是一个变量,用来存储另一个变量的内存地址
func main() {
// 指针地址,指针类型,指针取值
// &取地址,*根据地址取值(解引用)
a := 10
b := &a
fmt.Println(*b)
//指针类型 *int *unit *float *string *array *struct 等
// 指针的定义
// var 变量名 指针类型
var p1 *int //定义空指针
fmt.Println(p1) // nil
p1 = &1
fmt.Println(p1)
}
5.6.2 数组指针和指针数组
- 数组指针:是一个指针,用来存储数组的内存地址
func main() {
arr := [4] int{1, 2, 3, 4}
fmt.Println(arr)
// 定义一个数组指针
var p1 *[4] int
fmt.Println(p1) // nil 空指针
fmt.Ptintf("%T\n", p1) // *[4] int
p1 = &arr1
fmt.Println(p1)
fmt.Printf("%p\n", p1)
fmt.Printf("%p\n", &p1)
// 通过数组指针操作数组
(*p1)[0] = 100
// 可以简写为
// p1[0] = 200
fmt.Println(arr) // [100 2 3 4]
}
- 指针数组:是一个数组,元素为指针
func main() {
a := 1
b := 2
c := 3
d := 4
arr1 := [4] int{a, b, c, d}
arr2 := [4] *int{&a, &b, &c, &d}
fmt.Println(arr1)
fmt.Println(arr2)
// 操作数组与指针数组的区别
//arr1[0] = 100
//fmt.Println(a)
//fmt.Println(arr1, &arr1[0]) // 值类型,将a,b,c,d的值拷贝过来放到数组中,修改的是数组空间内的数据,与a,b,c,d没有关系
//fmt.Println(arr2)
*arr2[0] = 1000
fmt.Println(a)
fmt.Println(arr1, &arr1[0])
fmt.Println(arr2, *arr2[0]) // 通过指针数组中的内存地址,修改了a,b,c,d的值,类似于Python列表
b = 2000
fmt.Println(b)
fmt.Println(arr1, &arr1[1])
fmt.Println(arr2, *arr2[1])
}
总结:
数组是值类型,将值拷贝了一份放到数内存中,二者相互独立,互不影响,修改数组后数组内存中的值改变,不会影响拷贝的源数据,源数据改变,也不会影响数组
Go中切片是对原数组的引用,二者互相关联,修改切片元素的值后,与之关联的底层数组的也会受到影响,同理,底层数组的改变也会影响切片的值
Python中的列表是引用类型,基于指针数组,修改可变元素后(可变类型与不可变类型),引用的源数据也会受到影响---
- Go中切片与Python中列表的区别
- go的切片,其成员是相同类型的,python的列表和元组则不限制类型。
- 两种语言都有[a: b]这种切片操作,意义也类似,但是go的a、b两个参数不能是负数,python可以是负数,此时就相当于从末尾往前数。
- 两种语言都有[a: b: c]这种切片操作,意义却是完全不同的。go的c,表示的是容量;而python的c表示的是步长。
- python的切片产生的是新的对象,对新对象的成员的操作不影响旧对象;go的切片产生的是旧对象一部分的引用,对其成员的操作会影响旧对象。
- 底层实现的不同
- go的切片,底层是一个三元组,一个指针,一个长度,一个容量。指针指向一块连续的内存,长度是已有成员数,容量是最大成员数。切片时,一般并不会申请新的内存,而是对原指针进行移动,然后和新的长度、容量组成一个切片类型值返回。也就是说,go的切片操作通常会和生成该切片的切片共用内存。不仅是切片,字符串、数组的切片也是一样的,通常会共用内存。当然也有异常情况,那就是切片时,提供的容量过大,此时会申请新内存并拷贝;或者对切片append超出容量,也会如此。这时,新的切片,才不会和老切片共享内存。(如果你切片/创建时提供的容量小于长度,会panic)
- python的列表,其实是个指针数组。当然在下层也会提供一些空位之类的,但基本就是个数组。对它们切片,会创建新的数组,注意,是创建新的数组!python的列表可没有容量的概念。这其实也体现了脚本语言和编译语言的不同。虽然两个语言都有类似的切片操作;但是python主要目标是方便;go主要目标却是快速(并弥补丢弃指针运算的缺陷)。
5.6.3 函数指针与指针函数
// 函数指针
// Go中函数默认就是一个指针类型,不需要*
func main() {
var a func()
a = func1
a()
}
func func1() {
fmt.Println("这是func1()")
}
// 指针函数
// 返回值为指针的函数
func main() {
// arr1是数组,值传递,将func1中返回的arr的值拷贝到arr1中,当func1调用结束,arr被销毁
arr1 := func1()
fmt.Printf("arr1的类型:%T,内存地址:%p,值:%v\n",arr1, &arr1, arr1)
// arr2是指针类型,值传递,将func2中返回的arr的内存地址保存到arr2中,arr不会随着func2的结束而销毁(和闭包一样改变了变量的生命周期?)
arr2 := func2()
fmt.Printf("arr2的类型:%T,内存地址:%p,值:%v\n",arr2, &arr2, arr2)
}
// 这是普通函数
func func1() {
arr := [4] int{1, 2, 3, 4}
return arr
}
// 这是指针函数
func func2() *[4] int {
arr := [4] int{1, 2, 3, 4}
return &arr
}
5.6.4 指针作为参数
func main() {
/*
指针作为参数
参数:值传递和引用传递
总结:值传递,拷贝一份,不会影响原数据,但消耗内存
引用传递通过指针操作数据,会改变原数据,但节省内存(拷贝的数据可能很大)
*/
n := 10
// 值传递,func1改变不会影响n,a随着func1结束而被销毁
func1(n)
fmt.Println(n)
// 引用传递,将n的内存地址拷贝到a中,通过*a更改了n,a也会随着func2的结束而被销毁,但n已经改变
func2(&n)
fmt.Println(n)
}
func func1(a int) {
a = 100
fmt.Println(a)
}
func func1(a *int) {
*a = 100
fmt.Println(*a)
5.7 function(函数)
见 7. 函数
5.8 struct(结构体)
见 9. 结构体
5.9 interface(接口)
见 11. 接口
5.10 channel(通道)
见 12.通道
5.11 boolean(布尔值)
// true
// false
6. 流程控制
6.1 if 判断
func main() {
if 条件 {
代码块1
} else if 条件 {
代码块2
} else {
代码块3
}
}
6.2 for循环
func main() {
// 完整结构
for 初始化;终止条件;自增{
代码块
}
// 在外部定义初始化值
i := 0
for ; i<10; i++ {
代码块
}
// 在内部实现自增/自减
for i:=0; i<5; {
i++
}
// 利用for循环实现其他语言while的效果
for true {
代码块
}
}
6.3 switch语句
func main() {
// switch
switch 变量名: { // 对此变量做条件判断
case 值1, 值2, ...:
代码块
case 值3, 值4, ...:
代码块
default: // 不管以上打码是否执行,此部分肯定执行
代码块
}
}
6.4 break与continue
// break终止当前循环,执行循环下面的代码
// continue终止本次循环,继续执行下次循环
7. 函数
7.1 函数的定义
/*
func 函数名(参数1 类型,参数2 类型,...)(返回值1 类型, 返回值2 类型,...){
//函数体
}
*/
func f1(a int, b int)(c int){
return a+b
}
7.2 函数参数
// 函数参数
func f2(a, b int)() { //相邻的相同类型的参数可以合并
fmt.Println(a, b)
}
func f3(a int, b ...int) { // b ...int 表示接受int类型可变长参数,必须放在尾部
fmt.Println(a)
fmt.Println(b...)
}
7.3 函数返回
// 函数返回值
func f1(a int, b int)(c int){ // 第二个括号中的返回参数必须与return的数量一致
return a+b
}
// 返回多个值,要有多个变量去接收,不想要的值可以用“_”忽略,不能将所有返回值都忽略
_, a := f4(3, 4)
func f4(a int, b int)(c int, d int){
reyurn a, b
}
7.4 匿名函数
// 匿名函数
// 没有定义名字符号的函数
// 可以复制给变量,作为参数,作为返回值使用
func main() {
func(s string) {
fmt.Println(s)
}("abc")
}
7.5 闭包
外层函数中的局部变量被内层函数引用,外层函数的返回值是内层函数,按理来说,外层函数中的变量应该随着外层函数的结束而销毁,但由于它被内层函数引用,其生命周期也发生了改变
func main() {
res := closure()
fmt.Printlm(res1()) // 1
fmt.Printlm(res1()) // 2
}
// 闭包函数
func closure() func int {
i := 0
return func() int {
i++
return i
}
}
7.6 延迟调用
// 延迟调用
func main() {
f,err := os.Open("./main.go")
if err != nil {
log.Fatalln(err)
}
drfer f.close() // 仅注册,直到main退出前才执行
}
// 多个延迟调用按栈(FILO)次序执行,最前面的最后执行
8. 错误处理
Golang没有类似try...catch 这种异常处理机制,而是使用 panic 和 recover 处理异常. 其实相当于python的raise。
8.1 error
// error 是一种数据类型
// 标准库将error定义为接口类型,以便实现自定义错误类型
type error interface {
Error() string
}
// 创建error对象
var errDivByZore = errors.New("divis by zore")
func div(x, y int) (int error) {
if y == 0 {
return 0, errDivByZore
}
return x/y, nil
}
func main() {
z, err := div(5, 0)
if err != nil {
log.Fatalln(err)
}
fmt,Println(z)
}
自定义错误类型
type DivError struct { // 自定义错误类型
x, y int
}
func (DivError) Error() string { // 实现error接口方法
return "division by zore"
}
func div(x, y int) (int, error) {
if y == 0 {
return 0, DivError{x, y} // 返回自定义错误类型
}
return x/y, nil
}
func main() {
z, err := div(4, 0)
if err != nil {
switch e := err.(type) { // 根据类型匹配
case DivError:
fmt.Println(e, e.x, e.y)
default:
fmt.Println(e)
}
log.Fatalln(err)
}
fmt.Println(z)
}
8.2 panic/recover
更接近try/catch结构化异常,它们是内置函数而非语句
panic会立即中断当前函数流程,执行延迟调用(类似于Python中raise?)
在延迟调用函数中,recover可捕获并返回panic提交的错误对象
func main() {
defer func() {
if err := recover(); err != nil { // 捕获错误
log.Fatalln(err)
}
}()
panic("i am dead") // 引发错误
fmt.Println("exit.") // 永远不会执行
}
总结:
使用panic抛出异常,抛出异常后将立即停止当前函数的执行并运行所有被defer的函数,然后将panic抛向上一层,直至程序crash。但是也可以使用被defer的recover函数来捕获异常阻止程序的崩溃,recover只有被defer后才是有意义的。
必须注意:
- defer 需要放在 panic 之前定义,另外recover只有在 defer 调用的函数中才有效。
- recover处理异常后,逻辑并不会恢复到 panic 那个点去,函数跑到 defer 之后的那个点.
- 多个 defer 会形成 defer 栈,后定义的 defer 语句会被最先调用
panic:主动抛出异常
recover :收集异常
recover 用来对panic的异常进行捕获. panic 用于向上传递异常,执行顺序是在 defer 之后。
defer有点类似try...catch...finally中的finally
9. 结构体
Go语言中没有“类”的概念,也不支持“类”的继承等面向对象的概念。Go语言中通过结构体的内嵌再配合接口比面向对象具有更高的扩展性和灵活性。
9.1 自定义类型
// 通过type关键字自定义类型
type MyInt int //自定义了一个MyInt类型,它具有int类型的特性
9.2 类型别名
type TypeAlias = type //TypeAlias就是type的别名
// 数据类型中,byte,rune也是别名,他们的定义如下
type byte = uint8
type rune = int32
9.3 自定义类型与类型别名的区别
//类型定义
type NewInt int
//类型别名
type MyInt = int
func main() {
var a NewInt
var b MyInt
fmt.Printf("type of a:%T\n", a) //type of a:main.NewInt
fmt.Printf("type of b:%T\n", b) //type of b:int
}
// 总结:类型别名只是在代码中存在,编译后不会存在,而自定义类型会一直存在
9.4 结构体的定义
/*
使用type和struct关键字来定义结构体,具体代码格式如下:
type 类型名 struct {
字段名 字段类型
字段名 字段类型
...
}
*/
// 定义一个人类结构体
type person struct {
name string
age int
height int
// age, height int // 同类型的字段可以写在一起
}
9.5 结构体实例化
// var 结构体实例 结构体类型
type person struct {
name string
age, height int
}
func main() {
// 方法1
var p1 person
p1.name = 'qqq'
p1.age = 28
p1.height = 180
fmt.Ptintf("p1=%V\n", p1)
fmt.Ptintf("p1=%#V\n", p1)
// 方法2
p2 := person{"sss", 18, 149}
fmt.Ptintf("p1=%V\n", p1)
// 方法3
p3:= Person{}
p3.name = 'yyy'
p3.age = 18
p3.height = 149
fmt.Ptintf("p1=%V\n", p3)
fmt.Ptintf("p1=%#V\n", p3)
// 方法4
p4 := person{name="sss", age=18, height=149}
fmt.Ptintf("p1=%V\n", p4)
}
9.6 结构体指针
结构体是值传递,将一个实例赋值给另一个实例,发生的是深拷贝
func main() {
p1 := Person{
name: "qqq",
age: 18,
height: 180,
}
p2 := p1
fmt.Printf("%p\n", &p1) //二者内存地址不一样
fmt.Printf("%p\n", &p2)
p2.name = "www"
fmt.Println(p1) // {qqq 18 180}
fmt.Println(p2) // {www 18 180}
}
type Person struct {
name string,
age int,
height int,
}
如果要创建引用类型的实例,那就要使用结构体指针实例化
func main() {
p1 := Person{
name: "qqq",
age: 18,
height: 180,
}
var p2 *Person
p2 = p1
p2.name = "www"
fmt.Println(p1) // {www 18 180}
fmt.Println(p2) // &{www 18 180}
}
type Person struct {
name string,
age int,
height int,
}
9.7 匿名结构体与结构体的匿名字段
- 匿名结构体
// 没有名字的结构体
func main() {
p1 := struct{
name string
age int
height int
}{
name: "qqq",
age: 18,
height: 185,
}
fmt.Println(p1) // {qqq 18 158}
}
- 结构体的匿名字段
func main() {
p1 := Person{"qqq", 18}
fmt.Println(p1.string)
fmt.Println(p1.int)
}
type Person struct {
//name string
string // 匿名字段,可通过实例.string获取
//age int
int //匿名字段,可通过实例.int获取
}
/*
总结:
结构体的匿名字段就是不写字段名,只写字段类型
可通过 实例.字段类型 来获取匿名字段的值
一个结构体中一种类型的匿名字段最多只能有一个
*/
9.8 结构体的嵌套
9.8.1 结构体的嵌套
结构体内的字段类型为结构体,可通过 实例.嵌套结构体字段.字段 的方式访问和修改
结构体的嵌套类似于面向对象中的聚合
func main() {
addr := Address{
city: "上海市",
zone: "浦东新区",
}
p := Person{
name: "qqq",
age: 18,
address: addr,
}
fmt.Println(p) // {qqq 18 {上海市 浦东新区}}
fmt.Println(p.address.city) // 上海市
// 值传递,与嵌套的结构体互不影响
addr.zone = "杨浦区"
p.address.city = "北京市"
fmt.Println(p) // {qqq 18 {北京市 浦东新区}}
fmt.Println(addr) // {上海市 杨浦区}
}
type Person struct{
name string
age int
address Address
}
type Address struct{
city string
zone string
}
9.8.2 Go语言中的OOP
Golang不是面向对象的语言,所以没有面向对象的三大特征,但我们可以用代码模拟出面向对象的部分特征
// Go语言实现面向对象的继承
func main() {
// 实例化父类
p1 := Person{
name: "张三",
age: 25,
}
fmt.Println(p1)
fmt.Println(p1.name, p1.age)
// 实例化子类
//e1 := Employee{Person{name:"李四", age:35}, "bolome"}
e1 := Employee{
Person:Person{
name:"李四",
age:35,
},
company:"bolome",
}
fmt.Println(e1)
//fmt.Println(e1.Employee.name, e1.Employee.age, e1.company)
//提升字段,如果继承字段为匿名字段,可以省略嵌套的字段,直接点
fmt.Println(e1.name, e1.age, e1.company)
}
// 定义父类
type Person struct{
name string
age int
}
// 定义子类
type Employee struct{
Person // 使用匿名字段,字段类型为结构体,模拟继承关系
company string // 子类新增属性
}
模拟多继承
// 模拟面向对象多继承
func main() {
c := C{
"ccc",
20,
A{"aaa", 18},
B{"bbb", 28}
}
fmt.Println(c.name) // 这种写法要么C中有name属性,要么父类中只有一个有name属性,否则抛错:ambiguous selector c.name
fmt.Println(c.A.name) // 如果要使用父类中重复的属性,必须声明是哪个父类
fmt.Println(c.B.name)
fmt.Println(c.age1)
fmt.Println(c.age2)
fmt.Println(c.age)
}
// 定义父类A
type A struct {
name string
age1 string
}
// 定义父类B
type B struct {
name string
age2 int
}
// 定义子类C
type C struct {
name string
age int
A
B
}
- 总结:
- 结构体嵌套多个结构体可以实现面向对象多继承的效果
- 但没有继承顺序的说法,如果父类中有重复的字段,必须指明是哪个父类的哪个属性(
c.A.name)
10. 方法
方法是与对象实例绑定的特殊函数。这个对象可以是命名类型或者结构体的一个值或一个指针。
10.1 方法的定义
func main() {
p1 := Person{"qqq", 18}
p1.talk()
p1.run()
}
type Person struct{
name string
age int
}
/*
定义方法
func (t type) methodName() {
代码块
}
*/
func (p Person) talk() {
fmt.Println("这是个talk方法")
}
func (p *Person) run() {
//fmt.Println((*p).name)
fmt.Println(p.name)
fmt.Println("这是个run方法")
}
10.2 方法的继承
/* Go语言实现面向对象的继承 */
// 定义父类
type Person struct{
name string
age int
}
// 定义子类
type Employee struct{
Person // 使用匿名字段,字段类型为结构体,模拟继承关系
company string // 子类新增属性
}
// 定义父类方法
func (p Person) talk() {
fmt.Println("父类方法,talk")
}
// 子类新增方法
func (e Empployee) run() {
fmt.Println("子类新增方法,run")
}
//// 子类重写方法
//func (e Employee) talk() {
// fmt.Println("子类重写方法,talk")
//}
func main() {
// 实例化父类
p1 := Person{
name: "张三",
age: 25,
}
fmt.Println(p1)
fmt.Println(p1.name, p1.age)
// 实例化子类
//e1 := Employee{Person{name:"李四", age:35}, "bolome"}
e1 := Employee{
Person:Person{
name:"李四",
age:35,
},
company:"bolome",
}
fmt.Println(e1)
//fmt.Println(e1.Employee.name, e1.Employee.age, e1.company)
//提升字段,如果继承字段为匿名字段,可以省略嵌套的字段,直接点
fmt.Println(e1.name, e1.age, e1.company)
e1.talk() // 子类没有从写,使用父类,重写后使用子类的
e1.run() // 子类从写方法
}
- 总结:
- 结构体嵌套多个结构体可以实现面向对象多继承的效果,包括属性和方法
- 但没有继承顺序的说法,如果父类中有重复的属性或方法,必须指明是哪个父类的哪个属性或方法(
c.A.test()) - 子类可以新增和重写方法
11. 接口
11.1 什么是接口
接口代表一种调用契约,是多个方法声明的集合。
接口要实现的是做什么,而不关心怎么做,谁来做。
Go中接口机制:只要目标方法集合包含接口声明的全部方法,就被视为实现了该接口,无需做显示声明(非入侵式)。
目标类型可实现多个接口。
接口通常以er作为后缀
11.2 接口的定义
type tester interface {
test()
str() string
}
type data struct{}
func (d *data) test() {}
func (d data) str() string { return "" }
func main() {
var d data
// var t tester = d // *data实现了接口中的两个方法,data只实现了一个,不能判断为实现了接口
var t tester = &d
t.test()
fmt.Println(t.str())
}
/* 一个比较好的接口实现案例 */
// 定义一个USB接口
type USB interface {
startWork() // USB设备开始工作
stopWork() // USB设备结束工作
}
// 实现类
type Mouse struct {
name string
}
type KeyBoard struct {
name string
}
// Mouse实现接口方法
func (m Mouse) startWork() {
fmt.Println("Mouse开始工作")
}
func (m Mouse) stopWork() {
fmt.Println("Mouse结束工作")
}
// KeyBoard实现接口方法k
func (k KeyBoard) startWork() {
fmt.Println("KeyBoard开始工作")
}
func (k KeyBoard) stopWork() {
fmt.Println("KeyBoard结束工作")
}
// 定义一个测试方法
func testInterface(usb USB) { // 当需要接口类型对象时,可使用任意的实现类代替
usb.startWork() // 如果传入Mouse类型,usb = m,传入KeyBoard类型,usb = k
usb.stopWork()
}
func main() {
m := Mouse{"鼠标"}
//m.startWork()
//m.stopWork()
testInterface(m)
k := KeyBoard{"键盘"}
//k.startWork()
//k.stopWork()
testInterface(k)
var m1 USB
m1 = m
//m1.name // 接口对象不能访问实现类中的属性
m1.startWork() // 接口对象可以访问实现类中的方法
m1.stopWork()
}
- 总结:
- 当需要接口类型对象时,可使用任意的实现类代替,如果传入Mouse类型,usb = m,传入KeyBoard类型,usb = k
- 接口对象不能访问实现类中的属性,可以访问实现类中的方法
- 多个实现类实现一个接口,类似面向对象中的多态
11.3 空接口
内部没有任何方法的接口,可以看做任何对象都实现了空接口
使用空接口可以向函数传入任意类型参数,定义可以接受任意类型参数的容器
type A interface{}
type Sct struct{
name string
}
func func1(a interface{}) {
fmt.Println(a)
}
func main() {
s := Sct{"aaa"}
var a0 A = s // 空接口类型可以接受任意类型数值
var a1 A = 1
var a2 A = "aaa"
var a3 A = func() {}
var a4 A = 3.14
fmt.Println(a0)
fmt.Println(a1)
fmt.Println(a2)
fmt.Println(a3)
fmt.Println(a4)
// 使用空接口向函数传入任意类型参数
func1(1)
func1("abc")
// 使用空接口定义可以接受任意类型参数的容器
m := map[int] interface{}{
1: 1,
2: "qwerty",
3: [3] int{1, 2, 3},
}
fmt.Println(m)
}
11.4 接口嵌套
接口嵌套类似面向对象中多继承的效果
func main() {
var s struct = struct{}
var a1 A = s
a1.test1()
var b1 B = s
b1.test2()
var c1 C = s
c1.test1()
c1.test2()
c1.test3()
}
type A interface{
test1()
}
type B interface{
test2()
}
type C interface{
A
B
test3()
}
type Sct struct {
}
func (s *Sct) test1() {
fmt.Println("这是test1")
}
func (s *Sct) test2() {
fmt.Println("这是test2")
}
func (s *Sct) test3() { // 如果要实现接口C,就要实现接口A和B
fmt.Println("这是test3")
}
11.5 接口断言
因为Golang中所有类型都实现了空接口,要判断接口对象的实际类型,就要使用到断言
- 断言的语法格式
//安全类型断言
断言类型的值, 布尔值 := 表达式.(目标类型)
//非安全类型断言
断言类型的值 := 表达式.(目标类型)
- 断言示例
type A struct {}
func main {
a := A{}
// t := a.(A) //非安全类型,如果断言失败,会直接panic
t, ok := a.(A) //安全类型,如果断言失败,不会panic,ok为false
if ok {
fmt.Println(t)
}
}
-
用switch来断言
使用
断言类型的值 := 表达式.(type)得到断言类型,通过swith来判断具体的类型,每一个case会被顺序地考虑,当命中一个case 时,就会执行 case 中的语句,因此 case 语句的顺序是很重要的,因为很有可能会有多个 case匹配的情况
type A string
func main {
var a A
switch t := a.(type) {
//这里优先匹配A
case A:
fmt.Println("A")
case string:
fmt.Println("string")
default:
fmt.Println("int")
}
}
12. 通道
channel是Go语言中各个并发结构体(goroutine)之前的通信机制。 通俗的讲,就是各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
12.1 通道
// var 变量名 chan 数据类型
// 方法一:channel的创建赋值
var ch chan int;
ch = make(chan int);
// 方法二:短写法
ch:=make(chan int);
// 方法三:综合写法:全局写法!!!!
var ch = make(chan int);
12.2 单向Chan
//定义只读的channel
read_only := make (<-chan int)
//定义只写的channel
write_only := make (chan<- int)
12.3 缓冲通道
- 带缓冲区channel:定义声明时候制定了缓冲区大小(长度),可以保存多个数据。
//带缓冲区 (只有当队列塞满时发送者会阻塞,队列清空时接受着会阻塞。)
ch := make(chan int, 10)
/*
无缓冲channel详细解释:
1.一次只能传输一个数据
2.同一时刻,同时有 读、写两端把持 channel,同步通信。
如果只有读端,没有写端,那么 “读端”阻塞。
如果只有写端,没有读端,那么 “写端”阻塞。
读channel: <- channel
写channel: channel <- 数据
举一个形象的例子:
同步通信: 数据发送端,和数据接收端,必须同时在线。 —— 无缓冲channel
打电话。打电话只有等对方接收才会通,要不然只能阻塞
*/
- 不带缓冲区channel:只能存一个数据,并且只有当该数据被取出时候才能存下一个数据。
//不带缓冲区
ch := make(chan int)
/*
带缓channel详细解释:
举一个形象的例子:
异步通信:数据发送端,发送完数据,立即返回。数据接收端有可能立即读取,也可能延迟处理。 —— 有缓冲channel 不用等对方接受,只需发送过去就行。
发信息。短信。发送完就好,管他什么时候读信息。
*/
12.4 关闭通道
读写操作注意:
- 向已关闭的channel发送数据,则会引发pannic;
- channel关闭之后,仍然可以从channel中读取剩余的数据,直到数据全部读取完成。
- 关闭已经关闭的channel会导致panic
- channel如果未关闭,在读取超时会则会引发deadlock异常
问题来了,如何知道channel是否关闭,如何优雅的关闭channel:
一个适用的原则是不要从接收端关闭channel,也不要关闭有多个并发发送者的channel。
关闭只读 channel 在语法上就彻底被禁止使用了。
读取channel的方式有两种:
close(ch)
- 一种方式:
value, ok := <- ch
ok是false,就表示已经关闭。
- 另一种方式,就是上面例子中使用的方式:
for value := range ch {
}
channel关闭之后,仍然可以从channel中读取剩余的数据,
直到数据全部读取完成,会跳出循环
12.5 select
select是Golang在语言层面提供的多路IO复用的机制,其可以检测多个channel是否ready(即是否可读或可写)
- 总结select:
- select语句中除default外,每个case操作一个channel,要么读要么写
- select语句中除default外,各case执行顺序是随机的
- 如果select所有case中的channel都未ready,则执行default中的语句然后退出select流程
- select语句中如果没有default语句,则会阻塞等待任一case
- select语句中读操作要判断是否成功读取,关闭的channel也可以读取
- 举例一
package main
import (
"fmt"
"time"
)
func main() {
chan1 := make(chan int)
chan2 := make(chan int)
go func() {
chan1 <- 1
time.Sleep(5 * time.Second)
}()
go func() {
chan2 <- 1
time.Sleep(5 * time.Second)
}()
select {
case <-chan1:
fmt.Println("chan1 ready.")
case <-chan2:
fmt.Println("chan2 ready.")
default:
fmt.Println("default")
}
fmt.Println("main exit.")
}
13. 并发
13.1 Groutine
131.1 什么是Goroutine
Goroutine是轻量级的线程,初始会在堆上分配4kb的内存
13.1.2 主Goroutine
封装main函数的Goroutine称为主Goroutine,主Goroutine除了执行main函数,还进行了一系列其他操作:
设定每个Goroutine所能申请的栈空间最大尺寸,在32位计算机中,最大尺寸为250MB,在64位计算机中则为1GB。如果某个Goroutine的栈空间尺寸大于这个限制,那么运行时就会引发栈溢出(stack overflow)的恐慌,随后这个go程序会被终止。整个过程中主Goroutine会进行一系列的初始化工作,主要包含以下内容:
- 创建一个特殊的defer语句,用于在主Goroutine退出时做出必要的善后处理(主Goroutine也有可能非正常退出)
- 启用专门用于在后台清理内存的Goroutine,并设置GC可用标识
- 执行main函数中的init函数
- 执行main函数
- 执行完main函数后,还会检查主Goroutine是否引发可运行时的恐慌,并进行必要的处理
- 主Goroutine结束自己以及当前进程的运行
func main() {
go printNum()
for i:=0;i<1000;i++ {
fmt.Println("主Goroutine:",i)
}
}
func printNum() {
for i:=0;i<100;i++ {
fmt.Println("子Goroutine":i)
}
}
13.1.3 如何使用Goroutine
13.1.4 启动多个Goroutine
13.2 GMP模型
13.2.1 储备知识点
- 内核级线程模型
- 用户级线程模型
- 两级线程模型
13.2.2 GMP模型
在操作系统提供的内核线程之上,go搭建了一个特有的两级线程模型。Goroutine机制实现了M:N的线程模型,Goroutine机制是协程的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
//go语言中新建一个goroutine
go func() {
//do something
}()
- Sched:调度器,维护存储M和G的队列以及调度器的一些状态信息等
- G:groutine实现的核心结构,在这里是Goroutine的控制结构,是对Goroutine的抽象,包含了栈,指令指针,以及其他对调度Goroutine很重要的信息,例如其阻塞的channel等,不同版本的Goroutine默认栈大小不同,在1.11中为2KB
- M:结构是Machine,即系统线程,由操作系统管理,Goroutine运行于M之上;如果不对该线程栈提供内存的话,系统会给该线程提供内存;当指定了线程栈,则M.Stack->G.stack,M的PC寄存器指向G提供的函数,然后去执行;M是一个很大的结构,里面维护小对象内存cache(mcache),当前执行的Goroutine,随机数发生器等信息
- P:结构是Processor,即处理器,是一个抽象的概念,并不是真正的物理CPU,主要用于执行Goroutine,维护了一个Goroutine队列,即runqueue,P是从N:1调度到M:N的调度的重要部分;当P有任务时需要创建或者唤醒一个系统线程来执行它队列里的任务,所以P和M需要绑定,构成一个执行单元;P决定了同时可以并发的任务数,可以通过GONAXPROCS限制同时执行用户级任务的操作系统线程;可以通过runtime.GOMAXPROCS进行指定,在Go1.5之后GOMAXPROCS被默认设置可用的核数,而之前则默认为1
13.2.3 场景分析
我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。
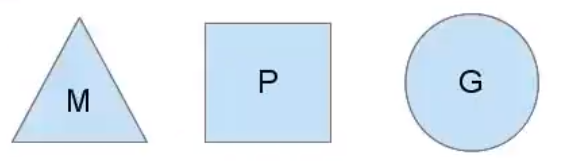
- 正常情况下
所有的goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个Goroutine,其他Goroutine在runqueue中等待。一个Goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
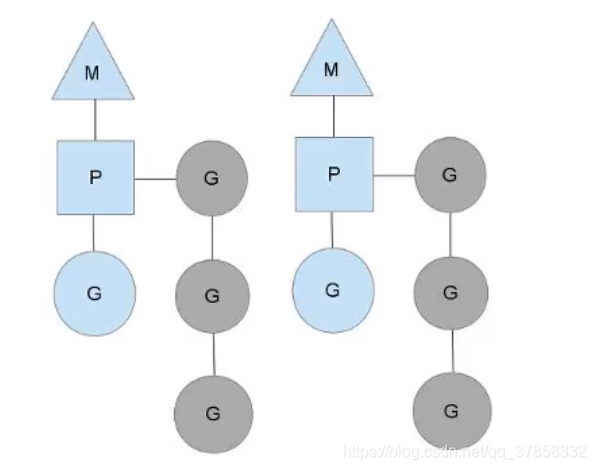
如果两个M都在一个CPU上运行,这就是并发;如果两个M在不同的CPU上运行,这就是并行。在正常情况下,scheduler(调度器)会按照上面的流程进行调度,当一个G(Goroutine)的时间片结束后将P(Processor)分配给下一个G,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
- 线程阻塞
当正在运行的Goroutine(G0)阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M0线程放弃了它的Processor(P),P转到新的线程中去运行。
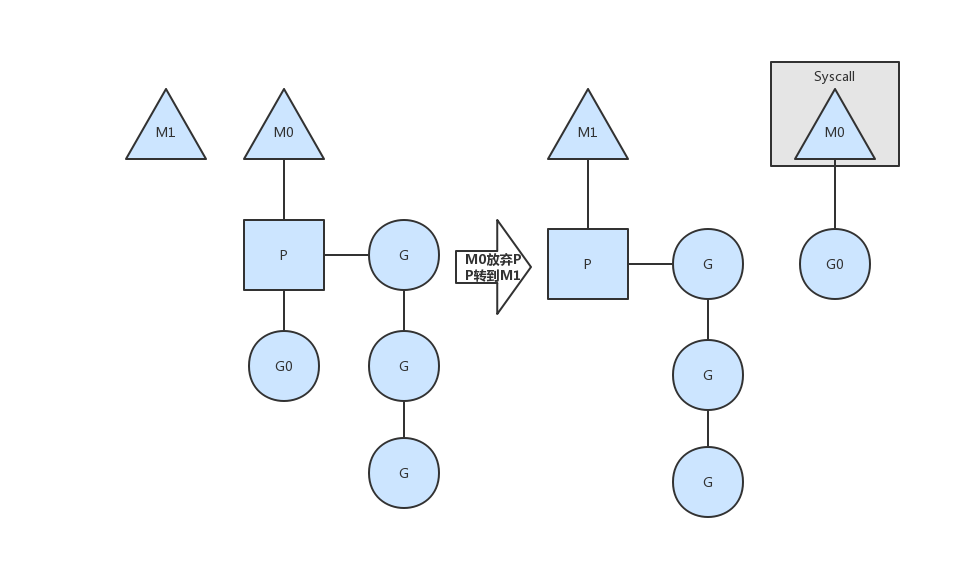
- runqueue执行完成
当其中一个Processor的runqueue为空,没有Goroutine可以调度,它会从另外一个上下文偷取一半的Goroutine。
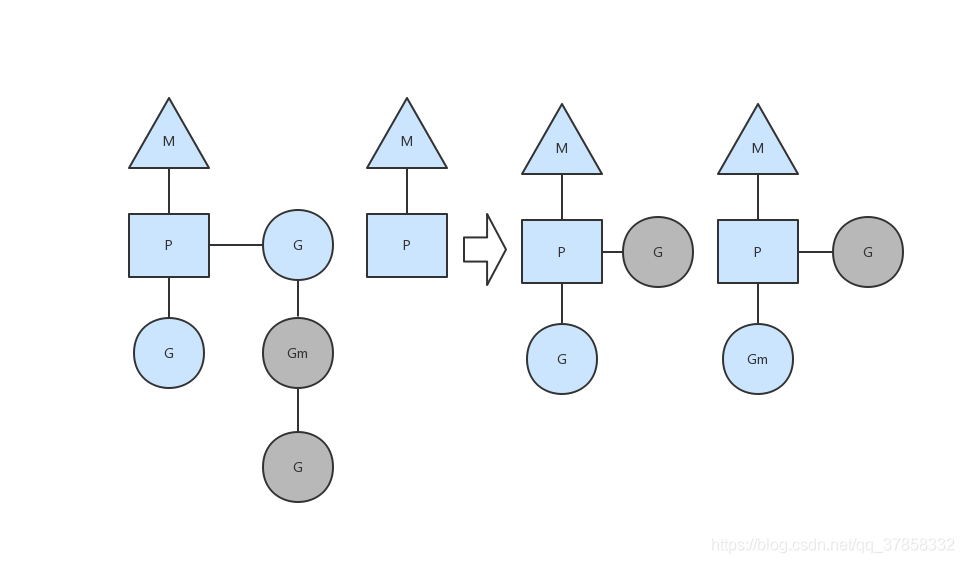
首先创建一个G对象,G对象保存到P本地队列或者是全局队列。P此时去唤醒一个M。P继续执行它的执行序。M寻找是否有空闲的P,如果有则将该G对象移动到它本身。接下来M执行一个调度循环(调用G对象->执行->清理线程→继续找新的Goroutine执行)。
M执行过程中,随时会发生上下文切换。当发生上线文切换时,需要对执行现场进行保护,以便下次被调度执行时进行现场恢复。Go调度器M的栈保存在G对象上,只需要将M所需要的寄存器(SP、PC等)保存到G对象上就可以实现现场保护。当这些寄存器数据被保护起来,就随时可以做上下文切换了,在中断之前把现场保存起来。如果此时G任务还没有执行完,M可以将任务重新丢到P的任务队列,等待下一次被调度执行。当再次被调度执行时,M通过访问G的vdsoSP、vdsoPC寄存器进行现场恢复(从上次中断位置继续执行)。
14. 包结构
14.1 main包
main函数所在的包,是Go程序的入口,main包想要引用别的代码,就需要使用inport导入
14.2 package
- 一个目录下的文件同属一个包,package声明要一致
- package声明的包名可以和目录名不一致,但习惯上还是写成一样的
- 包可以嵌套
- 同一个包下的函数可以直接调用,不需要导入
- main包是主函数所在的包,其他包不要使用
package xxx
//大写开头表示可以导出
func Abc() {
//do something
}
package main
import xxx //可以使用绝对路径和相对路径
//import a xxx //别名导入 a.Abc
func main(){
xxx.Abc()
}
14.3 init函数
Golang 的init函数和其他函数或方法有诸多不同. 它是 Golang package 初始化中使用的重要角色, 可以说是语法糖. 当对于 Golang 这样一门工程化编程语言来说,init函数有着很多巧妙的使用.
- 不唯一性:
init函数和其他函数最大的区别之一就是, 同一个 package 或源文件中, 可以有很多个. - 生命周期:
init函数在一个 package 中的所有全局变量都初始化完成之后, 才开始运行. 其次init函数只会运行一次, 即使被 import 了很多次. - 没有输入输出的参数:如果我们给init函数写上输入参数或输出参数,Compiler 会告诉我们, 这样写是语法错误的
- 运行顺序:
- 同一个源文件中, 写在更靠近文件上面的 init 函数更早运行
- 同一个 package 中, 文件名排序靠前的文件中的 init 函数更早运行
- 不同的包中,按import的顺序执行
- 如果包之间存在依赖,则最后依赖的最先执行,main中最后执行
- 包之间存在依赖,不能循环导入
- 用作side effect:标准库中的 MySQL Driver 就是通过导入一个匿名的 package 来实现 side effect.
- Test文件中:同一个 package 中, test 文件中的
init函数和非 test 文件中的互不相干. 这样设计也是为了 test 能够足够独立和灵活.
Tips:init函数并不一定需要写在源文件的最上面, 从语法层面说, 写在任何地方都可以. 标准库里有很多实践的例子.
14.4 包管理
-
GOROOT:Golang安装目录
-
GOPATH:Go命令环境依赖:主要包含
- bin:可执行文件
- pkg:编译包相关
- src:源码包相关
-
GO111MULE:从1.13开始,默认为on
-
使用:
-
进入项目,go mod init 项目名,执行完会生成初始化名为项目名的模块,并且生成
go.mod和go.sum记录当前依赖包名及版本信息,由程序自动维护 -
手动改变
go.mod后需要手动清空go.sum再重新生成:go mod tidy -
引入包规则为
模块名+路径格式,比如:import ( "hello/utils" //引入`hello`模块,在`utils`目录下的包 "github.com/astaxie/beego" //引入`github.com`模块,文件在`astaxie/beego`目录下的包 )
-
-
tips
Q1: 我的包下哪去了?
A: 依赖的第三方包被下载到了
$GOPATH/pkg/mod路径下。Q2:
GO111MODULE的三个参数auto、on、off有什么区别?A:
auto根据是否在src下自动判定,on只用go.mod,off只用src。Q3: 依赖包中的地址失效了怎么办?比如 golang. org/x/… 下的包都无法下载怎么办?
A: 在
go.mod文件里用replace替换包,例如replace golang.org/x/text => github.com/golang/text latest这样,
go会用github.com/golang/text替代golang.org/x/textQ4: 在
go mod模式中,项目自己引用自己中的某些模块怎么办?A:
go.mod文件里的第一行会申明module main,把这个main改为你的项目名,引用的时候就import "项目名/模块名"即可。
15. 反射
//待整理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号