爬虫—使用多进程爬取视频数据
以梨视频为例分析页面请求抓取网页数据。本次抓取梨视频生活分类页面下的部分视频数据,并保存到本地。
一、分析网页
打开抓取网页,查看网页代码结构,发现网页结构里面存放视频的地址并不是真正的视频地址。
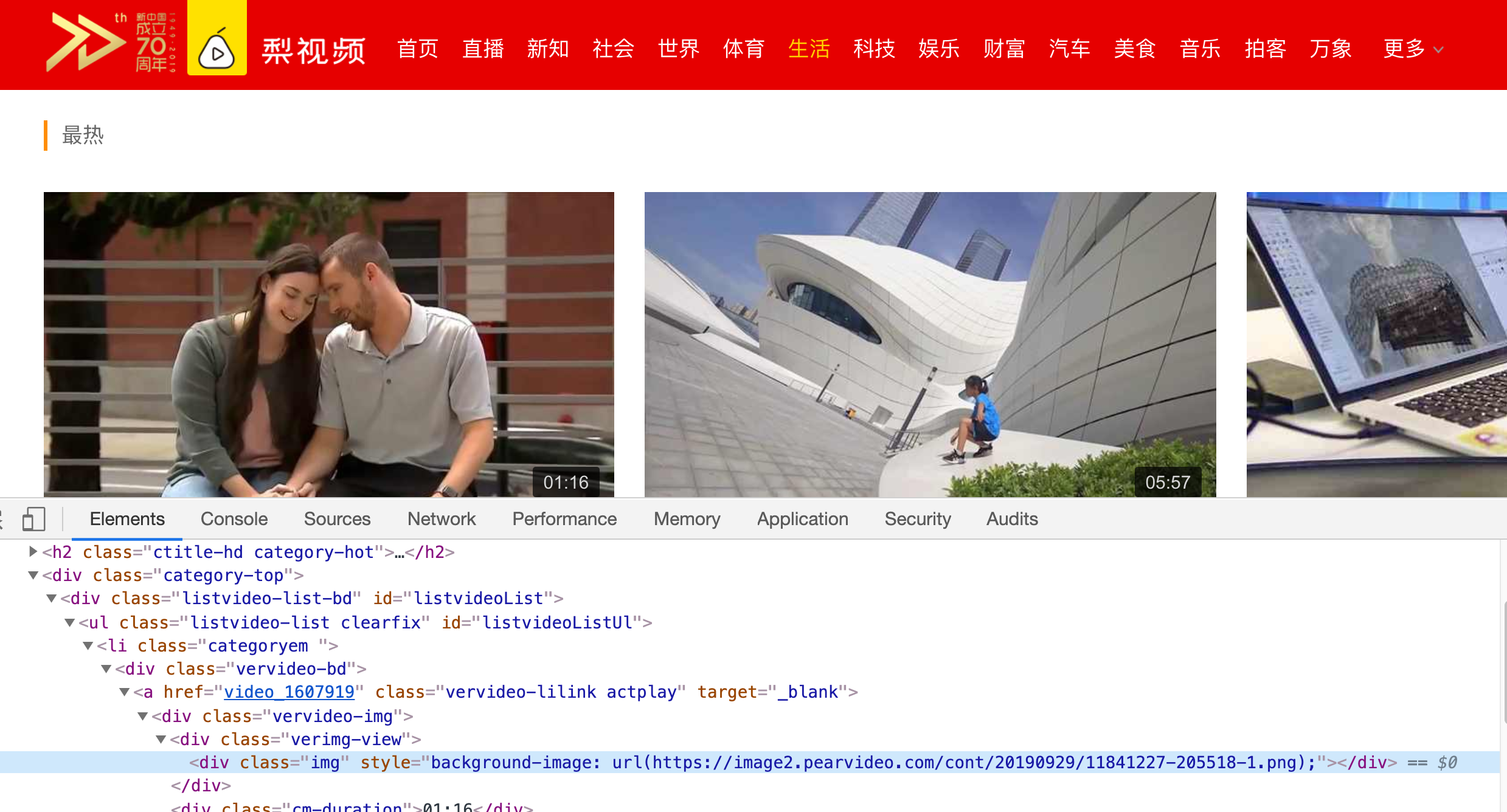
进入视频详情页面查看后,可以在response中找到真正的视频地址。保存这个地址的并不是标签,而是一个变量,我们使用re来解析这个变量,提取信息。
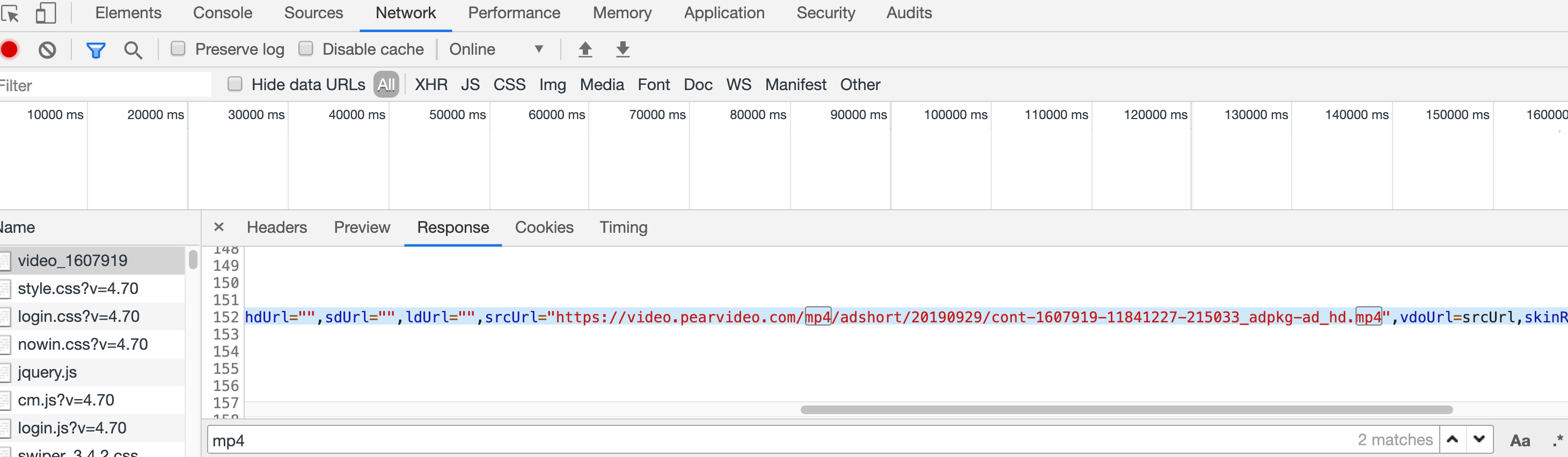
二、代码实现
"""使用多线程爬取梨视频视频数据""" import requests import re from lxml import etree from multiprocessing.dummy import Pool url = 'https://www.pearvideo.com/category_5' page_text = requests.get(url=url).text tree = etree.HTML(page_text) # 1、获取页面中视频详情地址 li_list = tree.xpath('//ul[@id="listvideoListUl"]/li') url_list = [] for i in li_list: # 2、构造出每个视频的详情地址 detail_url = "https://www.pearvideo.com/" + i.xpath('./div/a/@href')[0] name = i.xpath('./div/a/div[2]/text()')[0] + '.mp4' # 3、向视频详情地址发起请求 detail_page = requests.get(url=detail_url).text # 4、从response中解析出视频的真实地址 ex = 'srcUrl="(.*?)",vdoUrl' video_url = re.findall(ex, detail_page)[0] dic = { 'name': name, 'url': video_url } url_list.append(dic) def get_video_data(d): """ 向视频地址发起请求,二进制写入本地文件 :param d: :return: """ url = d['url'] data = requests.get(url=url).content print(d['name'], "正在下载。。。") with open(d['name'], 'wb') as f: f.write(data) print(d['name'], "下载成功。。。") # 使用多进程处理 pool = Pool(4) pool.map(get_video_data, url_list) pool.close() pool.join()
运行结果:
与新中国同岁!70名70岁老人的故事.mp4 正在下载。。。
与新中国同岁!70名70岁老人的故事.mp4 下载成功。。。
妻子每天失忆,丈夫用视频帮找记忆.mp4 正在下载。。。
妻子每天失忆,丈夫用视频帮找记忆.mp4 下载成功。。。
中国时尚引领国际潮流.mp4 正在下载。。。
中国时尚引领国际潮流.mp4 下载成功。。。
10后女孩7岁就拿3项少儿跑酷赛大奖.mp4 正在下载。。。
10后女孩7岁就拿3项少儿跑酷赛大奖.mp4 下载成功。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号