Ollama 安装与模型部署
本文主要是介绍如何内网、离线等无法直接访问 ollma 官网等外部网站的情况下,安装 ollama。
1 在线
不必多说,直接参考官方文档即可。
2 离线安装(linux 服务器)
参考:
2.1 ollama 程序下载 & 离线安装
ollama 支持程序安装以及通过 docker 的方式安装,程序安装非常简单,直接在官网下载对应操作系统的程序,然后直接安装即可。单个人还是推荐使用 docker 方式进行安装,方便进行程序以及环境管理,也方便迁移。
1)本地安装方式
直接访问官网下载页:https://ollama.com/download ,按自己的操作系统下载好对应的程序,然后上传到离线机器上安装即可。
2)docker 安装方式
首先,关于 docker 本身的安装不做赘述,请先自行搜索安装好 docker 环境。
-
如果机器可以联网,直接拉取镜像 ollama docker 镜像即可:
docker run -d -v /home/ollama:/root/.ollama -p 11435:11434 --name ollama ollama/ollama -
如果机器无法联网,离线下载 Docker 镜像通常需要先在一个可联网的设备上拉取镜像,然后将其导出为 tar 文件,最后将该文件传输到离线设备并加载。以下是详细步骤:
a. 步骤 1:在可联网设备上拉取镜像
-
拉取 Ollama 镜像
在联网的设备上打开终端或命令行工具,运行以下命令:docker pull ollama/ollama可以采用国内的镜像源来加速:
> 参考:https://blog.csdn.net/weixin_47575974/article/details/145922927 > 国内镜像源汇集网站:渡渡鸟: https://docker.aityp.com/#google_vignette # 临时使用,命令行方式 # docker pull [镜像源]/[镜像名称] docker pull docker.registry.cyou/ollama/ollama # 如需将镜像源配置到系统中,参考上述链接 -
检查镜像是否成功拉取
使用以下命令查看已拉取的镜像:docker images确保
ollama/ollama镜像出现在列表中。
b. 步骤 2:导出镜像为 tar 文件
- 导出镜像
将拉取的镜像导出为 tar 文件,以便离线传输:
这会在当前目录下生成一个名为 ollama-docker-image.tar 的文件。docker save ollama/ollama > ollama-docker-image.tar
c. 步骤3:将 tar 文件传输到离线设备
- 传输文件
使用外部存储设备(如 USB 驱动器)或网络传输工具(如 SCP),将 ollama-docker-image.tar 文件从联网设备复制到离线设备。
d. 步骤4:在离线设备上加载镜像
- 加载镜像
在离线设备上,将 tar 文件加载为 Docker 镜像:
加载完成后,使用以下命令验证镜像是否成功加载:docker load < ollama-docker-image.tar # 或下面命令 docker load -i xxx.tar
如果一切正常,你会看到docker imagesollama/ollama镜像出现在列表中。
e. 步骤5:运行 Ollama 容器
- 运行容器
现在可以在离线设备上运行 Ollama 容器。根据你的需求选择以下命令之一:# 仅使用 CPU: docker run -d -v /app/zzkf_jiang/llms/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama # 使用 GPU(如果支持): docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
-
-
进入容器内部(后面所有关于 ollama 的命令都是在容器中执行):
docker exec -it ollama /bin/bash
2.2 ollama 常用命令
# 查看当前有哪些模型
ollama list
# 查看ollama执行
ollama
ollama serve # 启动ollama
ollama create # 从模型文件创建模型
ollama show # 显示模型信息
ollama run # 运行模型,会先自动下载模型
ollama pull # 从注册仓库中拉取模型
ollama push # 将模型推送到注册仓库
ollama list # 列出已下载模型
ollama ps # 列出正在运行的模型
ollama cp # 复制模型
ollama rm # 删除模型
2.3 ollama 离线更新
pass
3 导入 gguf 模型
参考:
注意:
您应该至少有 8 GB 的 RAM 来运行 7B 型号,16 GB 的 RAM 来运行 13B 的型号,32 GB 的 RAM 来运行 33B 型号。
模型参数说明:
- q8_0:与浮点数16几乎无法区分。资源使用率高,速度慢。不建议大多数用户使用。
- q6_k:将Q8_K用于所有张量。
- q5_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q5_K。
- q5_0: 原始量化方法,5位。精度更高,资源使用率更高,推理速度更慢。
- q4_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q4_K
- q4_0:原始量化方法,4 位。
- q3_k_m:将 Q4_K 用于 attention.wv、attention.wo 和 feed_forward.w2 张量,否则Q3_K
- q2_k:将 Q4_K 用于 attention.vw 和 feed_forward.w2 张量,Q2_K用于其他张量。
根据经验,建议使用 Q5_K_M,因为它保留了模型的大部分性能。或者,如果要节省一些内存,可以使用 Q4_K_M。
这里有一个坑需要注意,gguf 模型在使用 ollama 加载时使用的 modefile 文件内容如果没有指定 template,会导致模型回复时一直一直继续,无法自动停止。所以我们需要参考 ollama 官网对应模型的 template 内容,将其复制到 modefile 文件中
3.1 先去 Huggingface 下载模型
推荐先在联网环境,从 ollama 官网中找到所需的模型,然后再去 huggingface 上搜该模型的 gguf 格式的模型文件,下载下来。
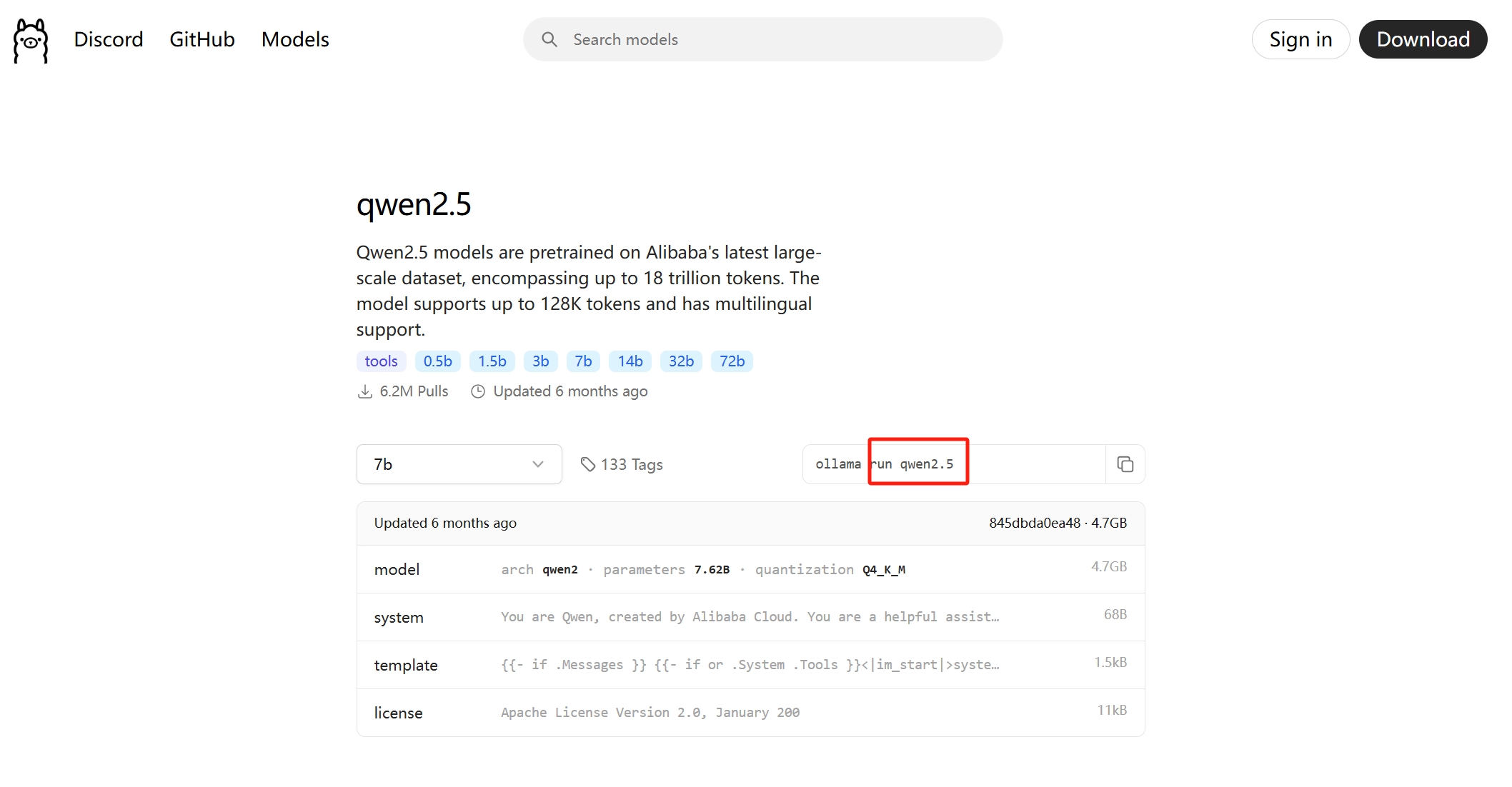
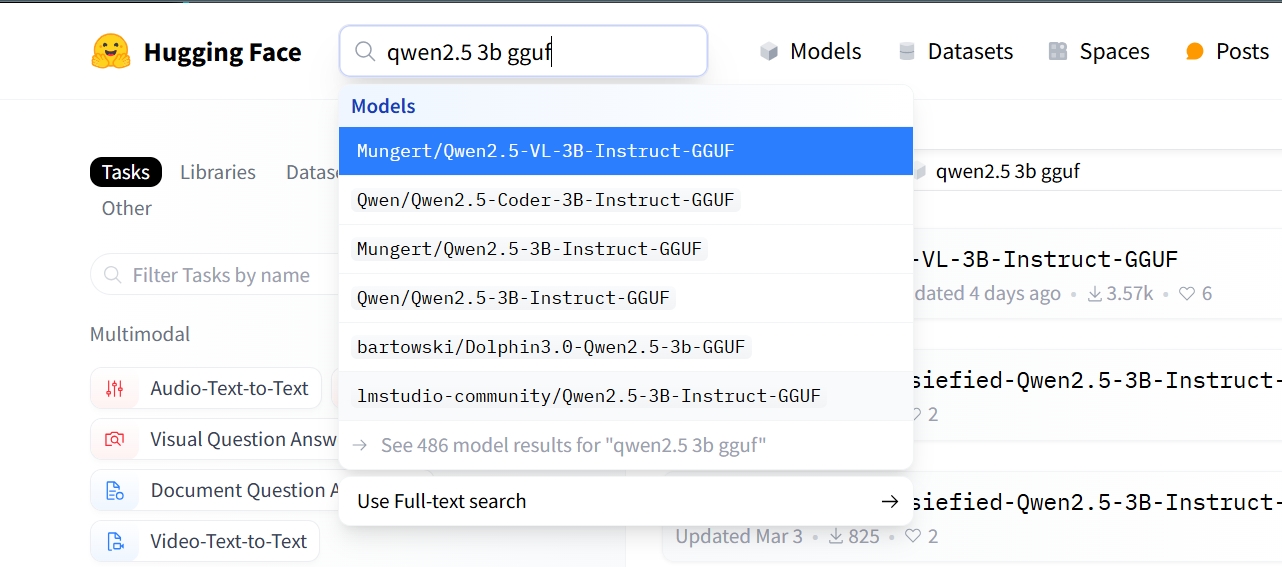
1-最好是在主机的 /home/ollama 文件夹下新建 huggingface_models 文件夹。
2-再在 huggingface_models 文件夹下新建 qwen2-05b-q4{对应你的模型文件} 文件夹。
3-将模型文件和Modelfile上传到上一步创建的 qwen2-05b-q4 文件夹中。
3.2 配置 Modelfile 文件
这块可以在 gguf 同级的目录下增加一个 Modelfile 文件,文件第一行固定写法:
# 上一步的模型名
FROM ./qwen2.5-0.5b-instruct-q4_k_m.gguf
只是这样写也能运行,但会导致模型问答回复时无法自动终止,还需要配置模版信息,模版可以在 ollama 官网对应的模型下面找:
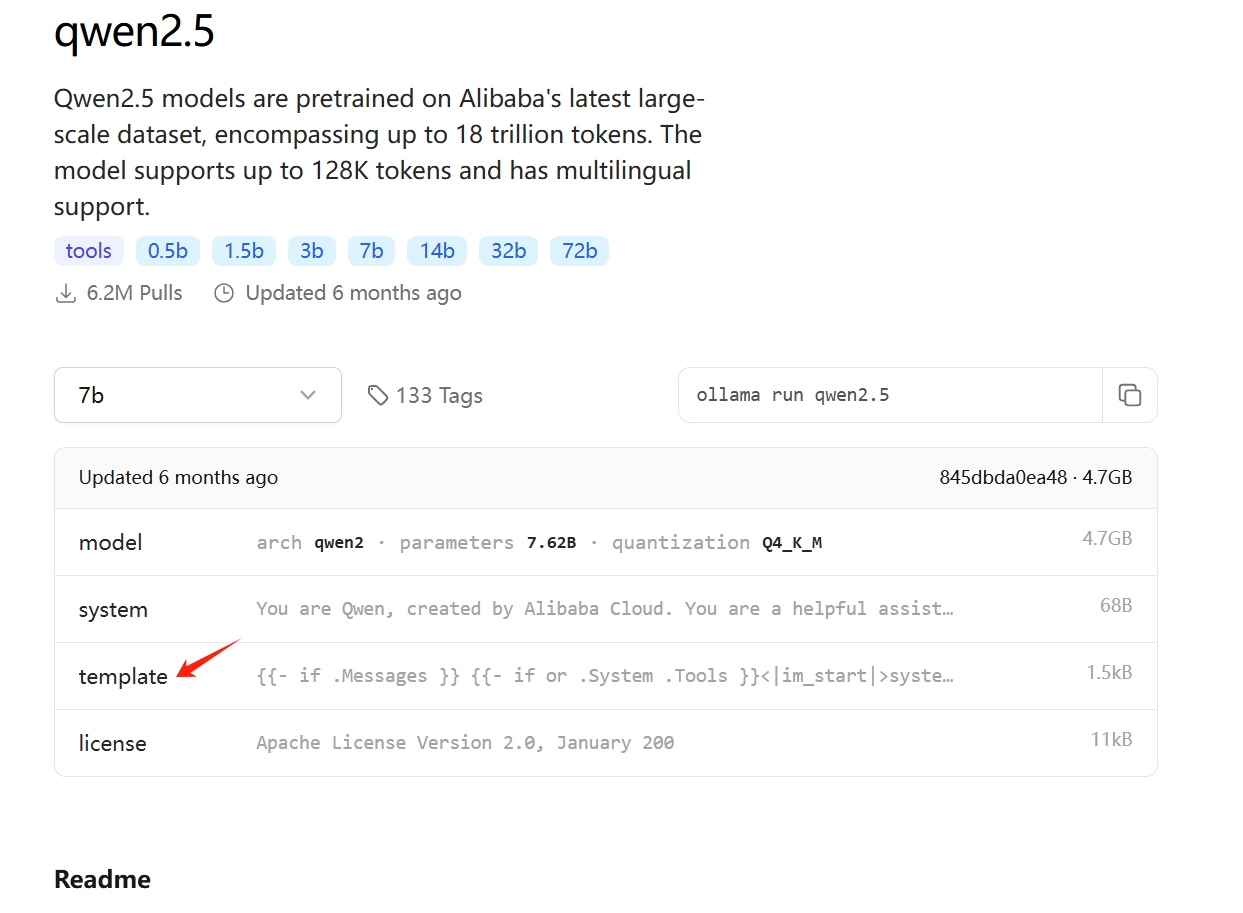
点进这个文件将其中的内容全部直接复制到 TEMPLATE 关键词之后的三个双引号中间:
# 上一步的模型名
FROM ./qwen2.5-0.5b-instruct-q4_k_m.gguf
# 可以到 ollama 网站上的模型库去寻找, 如 qwen2.5-3b 的模板地址: https://ollama.com/library/qwen2.5:3b/blobs/eb4402837c78
# 直接复制 ollama 上的 Template 到如下三个双引号中间
TEMPLATE """{{- if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{- if .System }}
{{ .System }}
{{- end }}
{{- if .Tools }}
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}
{{- end }}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}
"""
# 这一步参考 ollama 上的 parameters, 但是 ollama 上的 qwen2.5-3b 是没有参数的, 按照下面的格式添加即可
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
3.3 导入模型文件
打开 Modelfile 所在文件夹下打开终端,执行命令导入模型文件:
# ollama create 模型名称 -f ./Modelfile
# eg
ollama create qwen2.5-0.5b-instruct-q4_k_m -f ./Modelfile
导入成功之后,我们就可以通过 list 命令,看到名为 qwen2-05b-q4 的本地模型了,后续可以和其他模型一样进行管理了。
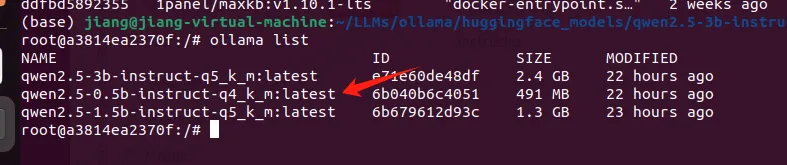
3.4 运行模型
ollama run qwen2.5-0.5b-instruct-q4_k_m:latest
结果如下:

4 导入 safetensors 模型文件(多了一个将safetensors转换成gguf文件的过程)
优先找 gguf 模型,如果有的模型没有提供 gguf,可参考:https://blog.51cto.com/u_14121041/12339312 。
发现 ollama 似乎可以直接加载 safetensors 格式的模型文件,先插个眼:https://ollama.readthedocs.io/modelfile/#build-from-a-safetensors-model ,待后续研究验证。
本文来自博客园,作者:sinatJ,转载请注明原文链接:https://www.cnblogs.com/zishu/p/18812832

 浙公网安备 33010602011771号
浙公网安备 33010602011771号