Python 自建 IP 代理池 - Scrapy 重构
1 重构说明
这是项目 Python 自建 IP 代理池 的重构版本,学习了 scrapy 框架的使用,并用该框架对之前项目进行了重构,得益于 scrapy 框架本身的优秀设计,之前手撸的小框架逻辑得到了很大的优化,并且由于 scrapy 本身是个异步的框架,所以也不需要自己构建进程池来并行爬取了。
首先有必要了解 scrapy 框架的整体结构:
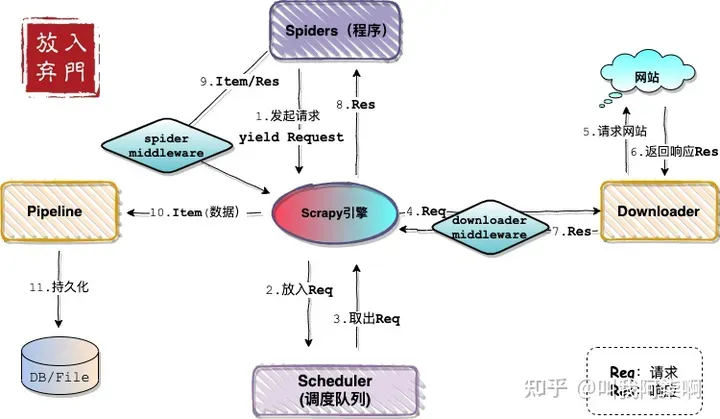
结合本项目自身的任务需求,其实都可以直接抛弃之前那个对比起来显得粗糙的框架设计了,只需要将不同代理网站的爬取逻辑封装成一个个的 spider,然后在 items 中定义一个 proxy 对象类,最后在管道中配置一个存 json 文件的管道组件。这样整个流程就自动的解耦和模块化了,是不是很简单 ~
2 Spiders 模块
借助于 scrapy 本身的设计,我们直接在 spiders 文件夹写针对每个代理资源网站的 spider 就可以了,但是这个项目涉及到了同时对多个代理资源网站的爬取,所以需要同时(或者依次)运行多个 spider,相对于单个网站的爬取来说,需要多做一步处理。
我们先从单个 spider 的逻辑开始实现,之后会讲解多个 spider 的并发情况。
2.1 单个 spider 的爬取逻辑 - seo
我们先看单个 spider 的编写逻辑,这里我以 seo 网站( https://proxy.seofangfa.com/ )为例(为啥,当然是因为它足够简单了~),写一个 spider。
-
首先创建 seospider
scrapy genspider seospider https://proxy.seofangfa.com/ -
确定好要爬取的字段,并定义 item(items.py)
class FreeIPProxyItem(scrapy.Item): ip = scrapy.Field() port = scrapy.Field() type = scrapy.Field() position = scrapy.Field() checktime = scrapy.Field() -
写好解析逻辑(seospider.py)
import scrapy from FreeIPProxyGettingPro_Scrapy.items import FreeIPProxyItem class SeospiderSpider(scrapy.Spider): name = "seospider" allowed_domains = ["proxy.seofangfa.com"] start_urls = ["https://proxy.seofangfa.com/"] def parse(self, response): item_list = response.xpath('//table[@class="table"]/tbody/tr') for item in item_list: proxy_item = FreeIPProxyItem() proxy_item['ip'] = item.xpath('./td[1]/text()').extract_first("") proxy_item['port'] = item.xpath('./td[2]/text()').extract_first("") proxy_item['position'] = item.xpath('./td[4]/text()').extract_first("") proxy_item['checktime'] = item.xpath('./td[5]/text()').extract_first("") yield proxy_item -
在 pipeline 中进行代理验证并保存成 json 文件(pipelines.py)
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter from scrapy.exceptions import DropItem import json from FreeIPProxyGettingPro_Scrapy.utils import common import os class SaveToJsonFilePipeline(object): def __init__(self): file_path = os.path.dirname(os.path.abspath(__file__)) self.file = open(os.path.join(file_path, 'results', 'freeproxyip.json'), 'w', encoding='utf-8') def process_item(self, item, spider): # 对 proxy 进行验证,验证通过的存 json 文件 res, proxy = common.check_proxy_900cha(item) if res: self.file.write(json.dumps(dict(item), ensure_ascii=False) + '\n') return item else: raise DropItem('IP proxy is useless ~') def close_spider(self): self.file.close()
其中代理验证函数和之前一直,就是下面这个函数,我抽象放到 commo 文件中了(common.py):
import requests
from lxml import etree
def check_proxy_900cha(proxy, timeout=3, realtimeout=False):
"""
方式三:根据 https://ip.900cha.com/ 返回结果来判断
:param proxy:
:param timeout:
:param realtimeout: 是否实时输出可用代理
:return:
"""
url = 'https://ip.900cha.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
proxies = {
'http': '{}:{}'.format(proxy['ip'], proxy['port']),
'https': '{}:{}'.format(proxy['ip'], proxy['port'])
}
try:
response = requests.get(url=url, headers=headers, proxies=proxies, timeout=timeout)
except Exception as e:
return False, None
else:
tree = etree.HTML(response.text)
ret_ip = tree.xpath('//div[@class="col-md-8"]/h3/text()')[0].strip()
if ret_ip == proxies['http'].split(':')[0]:
if realtimeout:
print(f'代理 {proxy["ip"]}:{proxy["port"]} 有效!')
return True, proxy
else:
return False, None
至此,seospider 就写好了,运行一下,能正常爬取并验证 proxy 后进行保存。
2.2 单个 spider + 多 start_urls 的爬取逻辑 - kuai
在讲解多个 spider 同时爬取前,可不得先有多个 spider,所以这里我们再写一个 spider,这个 spider 对快代理( https://www.kuaidaili.com/free/inha/ )进行爬取。
由于快代理有两种代理:高匿、普通。所以又涉及到在一个 spider 中指定多个 url 请求的情况,当然这个在现在的 scrapy 版本中写起来简单,直接 start_urls 中指定多个 url 就行了,但是这里有个反爬的坑,后面再说,先把代码逻辑写好。
-
创建 kuaispider
scrapy genspider kuaispider https://www.kuaidaili.com/free/inha/ -
编写爬取逻辑(kuaispider.py)
import scrapy from FreeIPProxyGettingPro_Scrapy.items import FreeIPProxyItem import time from urllib.parse import urljoin class KuaispiderSpider(scrapy.Spider): name = "kuaispider" allowed_domains = ["www.kuaidaili.com"] start_urls = ['https://www.kuaidaili.com/free/inha/', 'https://www.kuaidaili.com/free/intr/'] def parse(self, response): continue_tag = True today = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())).split(' ')[0].strip() proxies_obj = response.xpath('//div[@id="list"]//tbody/tr') for proxy_obj in proxies_obj: checktime = proxy_obj.xpath('./td[@data-title="最后验证时间"]/text()').extract_first('') if checktime.split(' ')[0] != today: continue_tag = False break else: proxy_item = FreeIPProxyItem() proxy_item['ip'] = proxy_obj.xpath('./td[@data-title="IP"]/text()').extract_first('') proxy_item['port'] = proxies_obj.xpath('./td[@data-title="PORT"]/text()').extract_first('') proxy_item['type'] = proxy_obj.xpath('./td[@data-title="类型"]/text()').extract_first('') proxy_item['position'] = proxy_obj.xpath('./td[@data-title="位置"]/text()').extract_first('') proxy_item['checktime'] = proxy_obj.xpath('./td[@data-title="最后验证时间"]/text()').extract_first('') yield proxy_item # 翻页 if continue_tag: next_page = response.xpath('//li[@class="v3__pagination-next "]/a/@href').extract_first('') teet = urljoin(response.url, next_page) yield scrapy.Request(url=urljoin(response.url, next_page), callback=self.parse)
至此,写完,运行一下,不报错。
但是,此时停下来仔细翻翻日志,会发现虽然 start_urls 中指定了两个 url,但是实际上只运行了一个,为了更直观的看结果,我们可以将 parse 逻辑改成下面这样:
...
class KuaispiderSpider(scrapy.Spider):
name = "kuaispider"
allowed_domains = ["www.kuaidaili.com"]
start_urls = ['https://www.kuaidaili.com/free/inha/', 'https://www.kuaidaili.com/free/intr/']
def start_requests(self):
for url in self.start_urls:
print('xxx: ' + url)
yield scrapy.Request(url=url, dont_filter=True, callback=self.parse)
def parse(self, response):
print('--->', response.url)
然后看下输出结果,会发现 https://www.kuaidaili.com/free/intr/并没有被打印。
任你怎么说,这个逻辑都是没问题的,但是就是没有想要的结果,气不气?
最后经过测试,发现问题还是出在了快代理的反爬机制上,之前的项目中也提到过,快代理在两个 url 的请求之间需要有一定的间隔,否则服务端会直接返回 -10。而 scrapy 是一个异步的框架,这就导致两个 request 之间的间隔非常短,因此我们需要设置 scrapy 的请求间隔。
可以参考官方文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/autothrottle.html
-
在 settings.py 中开启自动限速
AUTOTHROTTLE_ENABLED = True未开启前的爬取延迟是 0,开启后延迟默认为 5。此时重新运行程序,两个 url 都被请求了。
-
如果对觉得默认限速大了,可以在 settings.py 中修改以下配置项
# The initial download delay #AUTOTHROTTLE_START_DELAY = 5
注意这里并不能通过直接简单的在 start_request() 中 sleep(),因为这里的多个 url 的 Request 被 yield 后并不会马上执行,而是等所有 url 的 Request 都被 yield 后 scrapy 才会进行异步请求,所以直接在 Request 这个级别上修改并不会奏效。
2.3 多个 spider 同时爬取
要实现多个 spider 同时运行,首先需要知道如何在 scrapy 中通过 api 的方式运行程序,而不是通过在命令行中执行 scrapy crawl。
那么如何通过 script 的方式运行 spider?此时可以通过 scrapy.crawler.CrawlerProcess将命令封装成 script,官方文档:https://docs.scrapy.org/en/latest/topics/practices.html#run-scrapy-from-a-script 。
具体的这儿不过多说明了,如果要运行多个 spider,只需要通过 CrawlerProcess 依次配置多个 spider,然后统一 start() 即可。这里直接介绍多个 spider 同时运行的写法。
官方文档参考:https://docs.scrapy.org/en/latest/topics/practices.html#running-multiple-spiders-in-the-same-process
-
在项目根目录下创建 multi_spider_main.py 文件
import scrapy from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings # 引入多个 spider from FreeIPProxyGettingPro_Scrapy.spiders.seospider import SeospiderSpider from FreeIPProxyGettingPro_Scrapy.spiders.kuaispider import KuaispiderSpider settings = get_project_settings() process = CrawlerProcess(settings) process.crawl(SeospiderSpider) process.crawl(KuaispiderSpider) process.start()目录位置大概长这样:
之后,右键运行该文件就可以同时以异步的方式运行多个 spider 了。
3 Zday 为例介绍一些自定义问题
站大爷这个网站好啊,好就好在他限制多啊~
之前用 requests 请求时的两个典型限制:
- SSL 证书验证需要关闭,否则访问不了
- 需要自定义 headers(即使是最简单的换个 Accept)
现在使用 scrapy 后照样面临着这两个问题,但是运行 scrapy 代码却并不直接报对应的 SSL error,调试起来感觉不友好。下面一个一个解决问题。
3.1 Scrapy 关闭 SSL 证书验证
这个问题真的 debug 了好久,一开始直接搜各种解决方案,方法都没奏效,去看了下最新版 scrapy 官方文档说的是默认 scrapy 是不执行 SSL 验证的,一下子给我整不会了,github 上也有人提了这个问题认为是 scrapy 的 bug:
- https://docs.scrapy.org/en/latest/topics/settings.html#downloader-clientcontextfactory
- https://github.com/scrapy/scrapy/issues/4040
即使是这样,但是我们既然爬到了这个页面,怎么能够停滞不前?(穿越时空,竭尽全力,奇迹一定会实现...相信光,嘻嘻)
怎么说呢,有的时候顺序很重要,这里官方文档既然说了默认是进行远程 SSL 验证的,那么不妨先越过这个问题,继续解决定制 headers 的问题,果然,在设置了 headers 后,就可以正常爬取了,这真是无语了,关键是 scrapy 的错误提示也没说是这个问题啊,害~
3.2 Scrapy 中自定义 headers
这个简单,两种常用方法:
-
settings 文件中通过 DEFAULT_REQUEST_HEADERS 常量设置
-
自己的 spider 中通过 Request(headers) 参数指定(这种方式在一个项目有多个 spider,且每个 spider 有自己的定制需求时比较好用)
import scrapy class AddHeadersSpider(scrapy.Spider): name = 'add_headers' allowed_domains = ['sina.com'] start_urls = ['https://www.sina.com.cn'] headers = { 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', "Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.5,en;q=0.3", "Accept-Encoding": "gzip, deflate", 'Content-Length': '0', "Connection": "keep-alive" } def start_requests(self): for url in self.start_urls: # 指定请求头 yield scrapy.Request(url, headers=self.headers, callback=self.parse) def parse(self,response): print("---------------------------------------------------------") print("response headers: %s" % response.headers) print("request headers: %s" % response.request.headers) print("---------------------------------------------------------")
参考:https://blog.csdn.net/atuo200/article/details/102710347
4 优化
写到这里,基本上的项目功能都实现了,并且借助于 scrapy 框架,我们也不用自己设计构造整体的爬取逻辑,不用管什么失败重试、多进程爬取、针对不同情况自定义异常并做对应的处理等操作了,都交给 scrapy 框架,省心~
但是,上面的项目还是有继续优化的空间的,为了提升爬取效率,我们有必要进行一些优化操作。
4.1 代理验证异步优化
上面我们将对爬取代理的验证放在了 pipeline 中,在运行过程中,可以发现,整体爬虫运行速度并没有我们想想的那么块,scrapy 框架中多个 item 的数据处理操作在 pipeline 中是顺序执行的。尽管 parse 过程是异步的,但是其 yield 出去的 item 貌似并没有异步的调用 pipeline 中的处理逻辑。
官方文档中对 item pipeline 的定义很直观:
Each item pipeline component (sometimes referred as just “Item Pipeline”) is a Python class that implements a simple method.
所以在 settings 中配置多个 pipeline 其实就是配置的多个 pipeline component,这些 component 以不同的优先级串行构成 item pipeline 这个整体。
继续阅读文档,从:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#duplicates-filter 这个去重的例子的代码逻辑中,我们可以验证之前的推断,也就是 yield 出去的 item 在管道中并不会异步的运行,而是逐一被处理。
但是从这个回答( https://www.codenong.com/45461359/ )来看,确实也并不知道上面的示例是不是只是为了演示的伪代码写法,并且文档中也确实有 CONCURRENT_ITEMS配置项的说明:
Default: 100
Maximum number of concurrent items (per response) to process in parallel in item pipelines.
如果如字面所述,那么 yield 出去的多个 item 在 pipeline 中应该是并发执行的。
但是为什么从运行过程来看,像是串行执行的呢,我们修改验证逻辑到 parse() 中做个测试。
-
修改 seospider,将代理验证逻辑加进去
import scrapy from FreeIPProxyGettingPro_Scrapy.items import FreeIPProxyItem from FreeIPProxyGettingPro_Scrapy.utils import common class SeospiderSpider(scrapy.Spider): name = "seospider" allowed_domains = ["proxy.seofangfa.com", 'ip.900cha.com'] start_urls = ["https://proxy.seofangfa.com/"] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36', } def parse(self, response): item_list = response.xpath('//table[@class="table"]/tbody/tr') for item in item_list: proxy_item = FreeIPProxyItem() proxy_item['ip'] = item.xpath('./td[1]/text()').extract_first("") proxy_item['port'] = item.xpath('./td[2]/text()').extract_first("") proxy_item['position'] = item.xpath('./td[4]/text()').extract_first("") proxy_item['checktime'] = item.xpath('./td[5]/text()').extract_first("") yield scrapy.Request(url='https://ip.900cha.com/', headers=self.headers, meta={'proxy_item': proxy_item}, dont_filter=True, callback=self.parse_proxy_check) def parse_proxy_check(self, response): """ 验证代理是否可用 """ proxy_item = response.meta.get('proxy_item', None) print(proxy_item) ret_ip = response.xpath('//div[@class="col-md-8"]/h3/text()').extract_first('').strip() if ret_ip == proxy_item['ip']: yield proxy_item -
修改 pipeline 中存储逻辑,去掉代理验证
class SaveToJsonFilePipeline(object): def __init__(self): file_path = os.path.dirname(os.path.abspath(__file__)) self.file = open(os.path.join(file_path, 'results', 'freeproxyip.json'), 'a+', encoding='utf-8') # def process_item(self, item, spider): # # 对 proxy 进行验证,验证通过的存 json 文件 # res, proxy = common.check_proxy_900cha(item) # if res: # self.file.write(json.dumps(dict(item), ensure_ascii=False) + '\n') # return item # else: # raise DropItem('IP proxy is useless ~') def process_item(self, item, spider): self.file.write(json.dumps(dict(item), ensure_ascii=False) + '\n') return item def close_spider(self, spider): self.file.close()
运行下 seospider 后,速度快很多,这是否表明多个 item 在管道中并不是并发执行的?
我们可以进一步做验证,还是使用 2.1 节的写法,即在 pipeline 中做代理验证,但是加入 sleep 操作(pipelines.py):
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
import json
from FreeIPProxyGettingPro_Scrapy.utils import common
import os
class FreeipproxygettingproScrapyPipeline:
def process_item(self, item, spider):
return item
class SaveToJsonFilePipeline(object):
def __init__(self):
file_path = os.path.dirname(os.path.abspath(__file__))
self.file = open(os.path.join(file_path, 'results', 'freeproxyip.json'), 'a+', encoding='utf-8')
def process_item(self, item, spider):
print(item['ip'], 'sleeping...')
import time
time.sleep(5)
print(item['ip'], 'wake up...')
# 对 proxy 进行验证,验证通过的存 json 文件
res, proxy = common.check_proxy_900cha(item)
if res:
self.file.write(json.dumps(dict(item), ensure_ascii=False) + '\n')
return item
else:
raise DropItem('IP proxy is useless ~')
# def process_item(self, item, spider):
# self.file.write(json.dumps(dict(item), ensure_ascii=False) + '\n')
# return item
def close_spider(self, spider):
self.file.close()
同步修改 seospider.py:
import scrapy
from FreeIPProxyGettingPro_Scrapy.items import FreeIPProxyItem
from FreeIPProxyGettingPro_Scrapy.utils import common
class SeospiderSpider(scrapy.Spider):
name = "seospider"
allowed_domains = ["proxy.seofangfa.com"]
start_urls = ["https://proxy.seofangfa.com/"]
def parse(self, response):
item_list = response.xpath('//table[@class="table"]/tbody/tr')
for item in item_list:
proxy_item = FreeIPProxyItem()
proxy_item['ip'] = item.xpath('./td[1]/text()').extract_first("")
proxy_item['port'] = item.xpath('./td[2]/text()').extract_first("")
proxy_item['position'] = item.xpath('./td[4]/text()').extract_first("")
proxy_item['checktime'] = item.xpath('./td[5]/text()').extract_first("")
yield proxy_item
然后运行下看下输出:
...
121.10.1.178 sleeping...
121.10.1.178 wake up...
139.224.190.222 sleeping...
139.224.190.222 wake up...
47.111.173.88 sleeping...
47.111.173.88 wake up...
115.236.55.186 sleeping...
115.236.55.186 wake up...
47.100.201.85 sleeping...
47.100.201.85 wake up...
...
好了,破案了,可以发现 yield 的多个 item 在每个 pipeline component 中是串行处理的。
所以验证代理的操作还是得放在 spider 模块中,通过 yield 的方式异步执行,其实这本身也符合 scrapy 的设计,即将含有 request 的操作都放在 spider 中后接 parse 逻辑,然后 item pipeline 中只做:
Typical uses of item pipelines are:
- cleansing HTML data
- validating scraped data (checking that the items contain certain fields)
- checking for duplicates (and dropping them)
- storing the scraped item in a database【这里记得之前 insert 操作速度慢,采用异步的方式做吗?也从侧面验证了 item 在 pipeline 中是串行处理的】
4.2 异步 & 循环
这个问题倒是意料之外,在准备添加一个新的代理 spider 后发现的。
proxyhub 代理:https://proxyhub.me/zh/all-http-proxy-list.html
这个网站的代理是动态的通过 ajax 请求来获取下一页数据,然后用 js 更新到当前页面上的,由于当前页面的 url 始终不变,所以一个很直观的方式就是先获取所有总页面数,然后使用 for 循环去发送请求,事实上我下意识也就是这么写得:
-
创建 spider
genspider spider proxyhubspider https://proxyhub.me/zh/all-http-proxy-list.html -
首先请求首页,并从首页中解析出总页数
import scrapy class ProxyhubspiderSpider(scrapy.Spider): name = "proxyhubspider" allowed_domains = ["proxyhub.me"] start_urls = [ 'https://proxyhub.me/zh/all-http-proxy-list.html', 'https://proxyhub.me/zh/all-https-proxy-list.html', ] def parse(self, response): total_page = int(response.xpath('//span[@class="page-link"]/@page')[-1].extract()) -
对分页的 ajax 请求接口,经抓包测试,是通过在 cookie 中设定分页字段来实现分页数据请求的,所以自定义 headers 并指定 cookies 就好了(当然这里在 scrapy 中也可以单独设定 cookies 属性)
import scrapy from FreeIPProxyGettingPro_Scrapy.items import FreeIPProxyItem import time class ProxyhubspiderSpider(scrapy.Spider): name = "proxyhubspider" allowed_domains = ["proxyhub.me"] start_urls = [ 'https://proxyhub.me/zh/all-http-proxy-list.html', 'https://proxyhub.me/zh/all-https-proxy-list.html', ] checktime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())).split(' ')[0].strip() def parse(self, response): total_page = int(response.xpath('//span[@class="page-link"]/@page')[-1].extract()) # 循环请求每个分页 for i in range(1, total_page): page_headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'cache-control': 'max-age=0', 'cookie': 'page={}; anonymity=all'.format(i + 1), 'sec-ch-ua': '"Not_A Brand";v="99", "Google Chrome";v="109", "Chromium";v="109"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': 'Windows', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36', } proxies_obj = response.xpath('//table/tbody/tr') for proxy_obj in proxies_obj: proxy_item = FreeIPProxyItem() proxy_item['ip'] = proxy_obj.xpath('./td[1]/text()').extract_first('').strip() proxy_item['port'] = proxy_obj.xpath('./td[2]/text()').extract_first('').strip() proxy_item['type'] = proxy_obj.xpath('./td[3]/text()').extract_first('').strip() proxy_item['position'] = proxy_obj.xpath('./td[5]/text()').extract_first('').strip() proxy_item['checktime'] = self.checktime yield scrapy.Request(url='https://ip.900cha.com/', headers=self.headers, meta={'proxy_item': proxy_item}, dont_filter=True, callback=self.parse_proxy_check) # 翻页 yield scrapy.Request(url=response.url, headers=page_headers, dont_filter=True, callback=self.parse)
运行一下,是不是好像乍一看也没什么问题?
但是,稍微回想一下,scrapy 是一个异步框架,在 parse 中我们是使用 yield 构造的生成器函数,而不是像第一个版本那样都是直接 return,这会导致在下面这一步:
# 翻页
yield scrapy.Request(url=response.url, headers=page_headers, dont_filter=True, callback=self.parse)
我们指定的 callback 函数又是 parse() 自身,完了就进去 for 循环了一遍请求了所有的分页。由于这个 yield 是写在最外层的 for 循环里面,这会导致无限循环(只需要在 for 循环中打印一些字符就可以发现这个 for 循环被执行了许多次,而并不是如预料的那般只执行一次)。
所以这里需要修改逻辑,也很简单,只需要将 for 循环去掉,然后翻页的时候去请求“下一页”的按钮即可:
import scrapy
from FreeIPProxyGettingPro_Scrapy.items import FreeIPProxyItem
import time
class ProxyhubspiderSpider(scrapy.Spider):
name = "proxyhubspider"
allowed_domains = ["proxyhub.me"]
start_urls = [
'https://proxyhub.me/zh/all-http-proxy-list.html',
'https://proxyhub.me/zh/all-https-proxy-list.html',
]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
checktime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())).split(' ')[0].strip()
def parse(self, response):
# 解析当前页数据
proxies_obj = response.xpath('//table/tbody/tr')
for proxy_obj in proxies_obj:
proxy_item = FreeIPProxyItem()
proxy_item['ip'] = proxy_obj.xpath('./td[1]/text()').extract_first('').strip()
proxy_item['port'] = proxy_obj.xpath('./td[2]/text()').extract_first('').strip()
proxy_item['type'] = proxy_obj.xpath('./td[3]/text()').extract_first('').strip()
proxy_item['position'] = proxy_obj.xpath('./td[5]/text()').extract_first('').strip()
proxy_item['checktime'] = self.checktime
yield scrapy.Request(url='https://ip.900cha.com/', headers=self.headers, meta={'proxy_item': proxy_item}, dont_filter=True, callback=self.parse_proxy_check)
# 翻页
page_headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'cache-control': 'max-age=0',
'sec-ch-ua': '"Not_A Brand";v="99", "Google Chrome";v="109", "Chromium";v="109"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': 'Windows',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
next_page = response.xpath('//span[@class="page-link"][i[@class="fas fa-angle-right"]]/@page').extract_first()
if next_page:
cookies = {
'page': next_page,
'anonymity': 'all',
}
yield scrapy.Request(url=response.url, headers=page_headers, cookies=cookies, dont_filter=True, callback=self.parse)
def parse_proxy_check(self, response):
"""
验证代理是否可用
:param response:
:return:
"""
proxy_item = response.meta.get('proxy_item', None)
ret_ip = response.xpath('//div[@class="col-md-8"]/h3/text()').extract_first('').strip()
if ret_ip == proxy_item['ip']:
yield proxy_item
运行测试一下,没问题~
4.3 xpath 高级写法
在上一节提取 nextpage 的时候,由于是多个同级标签,大概长这样:

当然也可以直接通过 li[3] 取第三个,也就是下一页的 li 标签进而获取 page 属性值。但是这种写死了的做法显然不是一种好的解决方案,此时我们可以使用 []来做子查询,以上面提取 nextpage 为例:
next_page = response.xpath('//span[@class="page-link"][i[@class="fas fa-angle-right"]]/@page').extract_first()
在 span 层级后包一个 //span[i[@class="fas fa-angle-right"]] 即可实现搜索所有 span 中包含 i 标签的 class 属性值为 fas fa-angle-right 的 span 标签(好像有点拗口,可能得稍稍捋一下~)
至此,重构完了,回顾来看,这次既是对之前的项目重构计划的填坑,也是希望通过实际项目尽快的上手 scrapy 框架,学不如写,实践果然还是上手技术的最快途径。
本文来自博客园,作者:sinatJ,转载请注明原文链接:https://www.cnblogs.com/zishu/p/17516900.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号