Java Stream函数式编程图文详解(二):管道数据处理

一、Java Stream管道数据处理操作
在本号之前发布的文章《Java Stream函数式编程?用过都说好,案例图文详解送给你》中,笔者对Java Stream的介绍以及简单的使用方法给大家做了介绍。在开始本文之前,我们有必要介绍一下这张Java Stream 数据处理过程图,图中主要分三个部分:
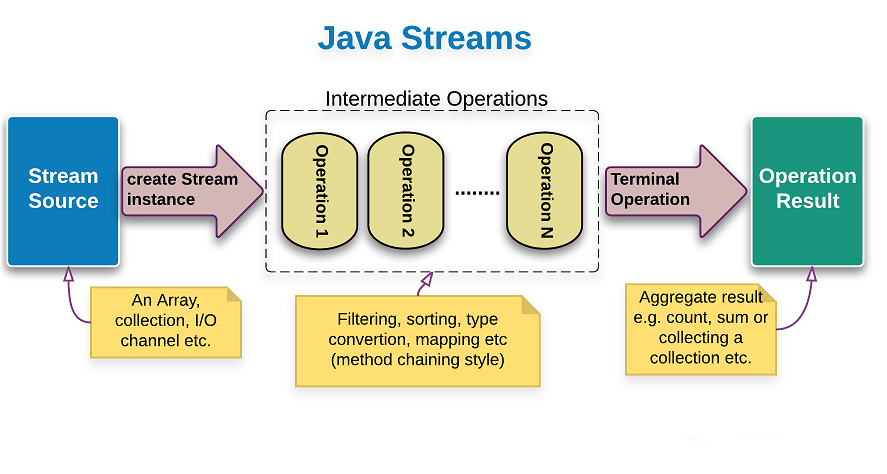
- 将数组、集合类、文本文件转换为管道流(图中的蓝色方块的部分,在本号的上一篇文章中已经给大家介绍过了)
- Java Stream管道数据处理操作(也就是下图中中间的虚线内的数据处理操作,本文的主要内容)
- 管道流处理结果的聚合、累加、计数、转换为集合类等操作(图中的绿色方块部分)
需要注意的是:Java Stream的中间数据处理操作的输入是一个管道流(Stream),输出仍然是一个管道流(Stream)。下面我们就来详细的学习一下!在上一篇文章中,我们给大家讲了这样一个例子:
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);
这个例子完成的功能就是:首先使用stream()函数将数组转换为管道流,然后对管道流中的元素进行过滤filter(),只保留L开头的元素,然后对每一个元素转换为大写(map(String::toUpperCase)),然后排序sorted(),最终转换为List类型。经过处理之后的输出结果是: [LEMUR, LION].在上面的例子中,filter()、map()、sorted()都属于中间数据处理操作,下面就给大家讲解一下这些函数的详细用法。
二、filter管道数据过滤
根据笔者的的经验,filter()是Stream API最有用的操作之一,它可以过滤掉不符合条件的元素。下面的代码过滤掉管道中的不是以L开头的字符串元素。处理完成之后,管道中剩下的元素是:[Lion, Lemur]
Stream<String> startsWithT = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.filter(s -> s.startsWith("L"));
如果没有学过lambda表达式的同学,可能对上面的代码感到困惑。其实很简单,lambda表达式用来表达函数,箭头左侧是参数,箭头右侧是函数体。函数的参数类型和返回值类型,会根据上下文做自动化的判断,不用你管。上文中的lambda表达式写成函数是这样的
public static boolean filterUpperL(String str){
return str.startsWith("L");
}
//.filter(BootLaunchApplicationTests::filterUpperL)
我甚至见过有的人排斥使用lambda表达式,说这种语法使代码的可读性下降。这个怎么说呢,如果一篇专业期刊中包含英语专业名词与引用,而读者恰巧不会英语就不想读了,我觉得这不是文章的问题,而是读者的问题。而且lamdba表达式在各种编程语言里面得到广泛的使用,提高编码效率。其实很简单:箭头左侧是参数,箭头右侧是函数体,你已经学会了!
三、Limit与Skip管道数据截取
Stream<String> startsWithT = Stream.of("Monkey", "Lion", "Giraffe", "Lemur").limit(2);
Stream<String> startsWithT = Stream.of("Monkey", "Lion", "Giraffe", "Lemur").skip(2);
- limt方法传入一个整数n,用于截取管道中的前n个元素。经过管道处理之后的数据是:[Monkey, Lion]。
- skip方法与limit方法的使用相反,用于跳过前n个元素,截取从n到末尾的元素。经过管道处理之后的数据是: [Giraffe, Lemur]
四、Distinct元素去重
我们还可以使用distinct方法对管道中的元素去重,涉及到去重就一定涉及到元素之间的比较,distinct方法时调用Object的equals方法进行对象的比较的,如果你有自己的比较规则,可以重写equals方法。
Stream<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct();
上面代码去重之后的结果是: ["Monkey", "Lion", "Giraffe", "Lemur"]
五、Sorted排序
默认的情况下,sorted是按照字母的自然顺序进行排序。如下代码的排序结果是:[Giraffe, Lemur, Lion, Monkey],字数按顺序G在L前面,L在M前面。第一位无法区分顺序,就比较第二位字母。
Stream<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted();
有的时候,我们希望排序的规则能够自定义,这就需要使用到Comparator。有的朋友这里可能忘了,可以自行回顾一下java基础的Comparator和Comparable接口。下面的代码是根据字符串的长度排序,排序结果是:[Lion, Lemur, Monkey, Giraffe]
Stream<String> lengthOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted(Comparator.comparing(String::length));
六、Map数据转换处理
map()函数的作用是将管道流中的每一个元素,以某种规则转换为另外一个元素。下面代码处理过的管道中的元素为: [monkey, lion, giraffe, lemur],所有元素的字母全部小写。
Stream<String> lowerCase = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.map(String::toLowerCase);
//这两种写法的实现效果是一样的,一个是lambda表达式,一个是函数引用的方式
Stream<String> lowerCase = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.map(s -> s.toLowerCase());
map()函数不仅可以处理数据,还可以转换数据的类型。如下:
IntStream lengths = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length);
上面代码的处理结果是:[6, 4, 7, 5],规则是字符串的长度。将管道流的字符串,使用mapToInt方法,以String::length为规则进行转换。当然除了mapToInt,还为我们提供了mapToDouble()和mapToLong()方法。我们可以通过自定义转换规则函数,返回int、double、long类型的返回值。
期待您的关注
- 博主最近新写了一本书:《手摸手教您学习SpringBoot系列-16章97节》
- 本文转载注明出处(必须带连接,不能只转文字):字母哥博客。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号