5.RDD操作综合实例
一、词频统计
A.分步骤实现:1. 准备文件
文章地址:https://www.neelc.org/posts/web3-centralized/
Web3_is_centralized是文件名
hdfs dfs -put ./Web3_is_centralized.txt ./Web3_is_centralized.txt
2. 读文件创建RDD
lines = sc.textFile("Web3_is_centralized.txt")
lines.count()

3. 分词
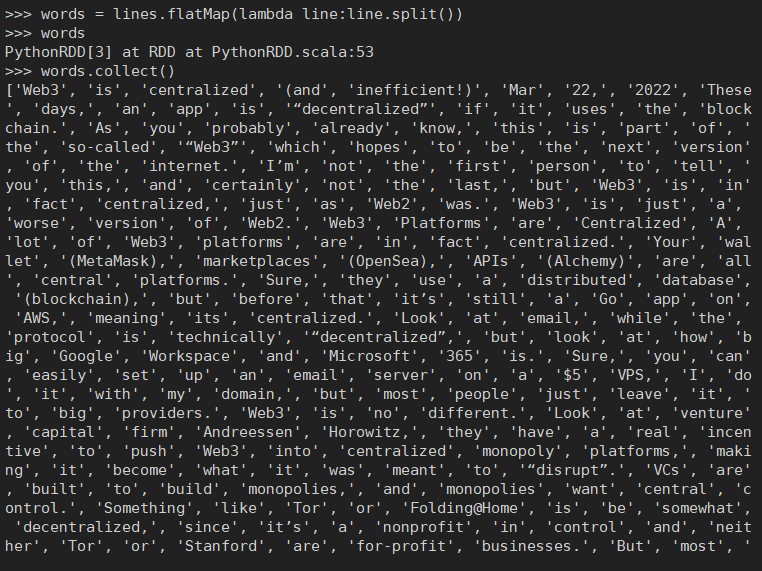
words = lines.flatMap(lambda line:line.split())
words.collect()
4. 排除大小写,标点符号,停用词,长度小于2的词
排除大小写
words = words.map(lambda word:word.lower())
words.collect()

排除标点符号
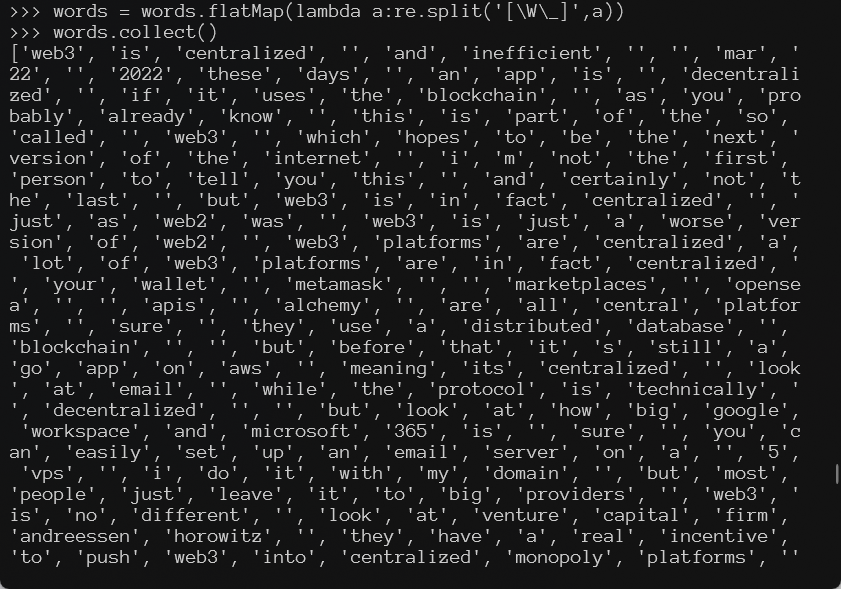
words = words.flatMap(lambda a:re.split('[\W\_]',a))
words.collect()
排除停用词
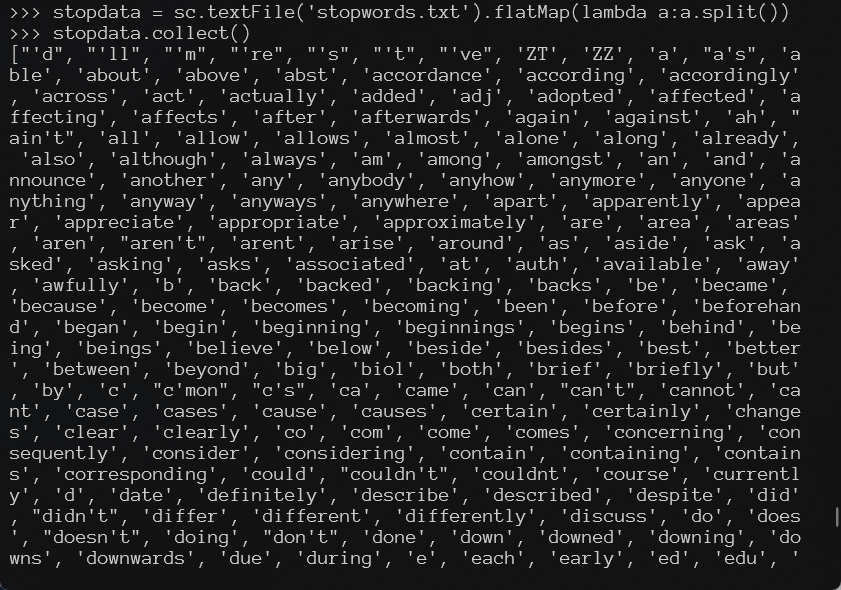
# 读取停用词
stopdata = sc.textFile('stopwords.txt').flatMap(lambda a:a.split())
stopdata.collect()
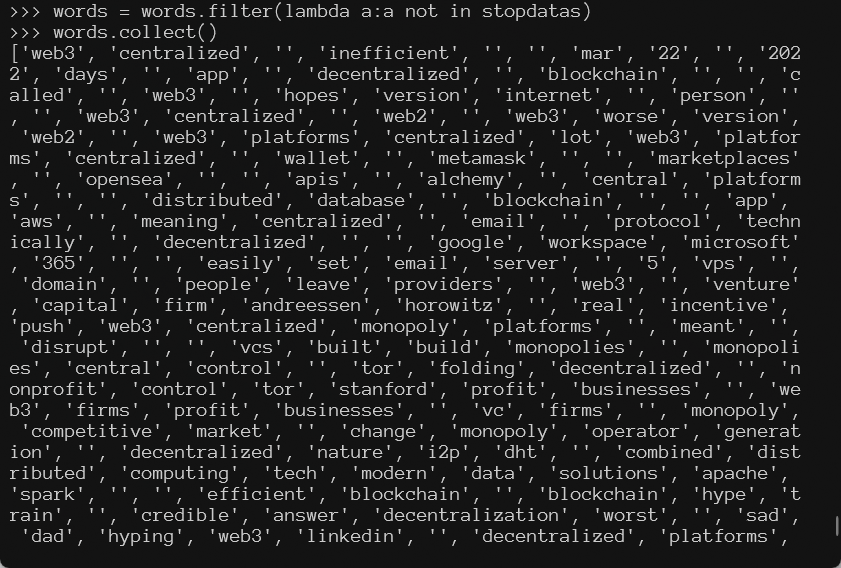
# 排除停用词
stopdatas = stopdata.collect()
words = words.filter(lambda a:a not in stopdatas)
words.collect()
排除长度小于2的词
words = words.filter(lambda a:len(a)>2)
words.collect()
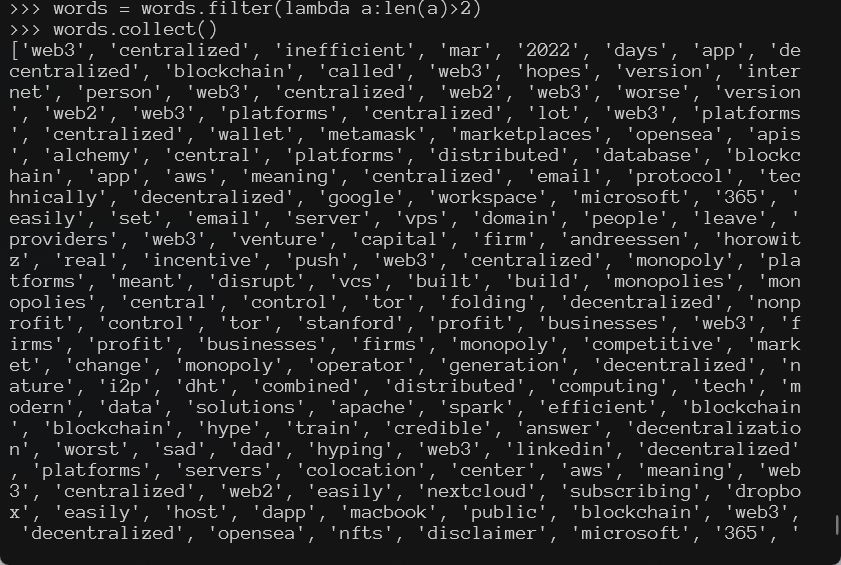
5. 统计词频
words = words.map(lambda word:(word,1))
wordCount = words.reduceByKey(lambda a,b:a+b)
wordCount.collect()
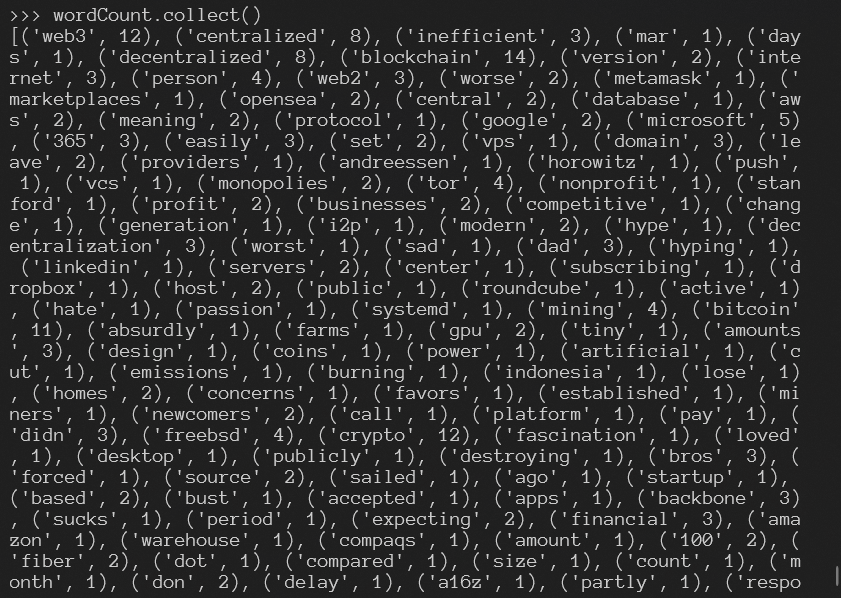
6. 排序
wcSort = wordCount.sortBy(lambda wc:wc[1],False)
wcSort.collect()
7. 输出到文件
wcSort.saveAsTextFile("wc_out_Web3_is_centralized")
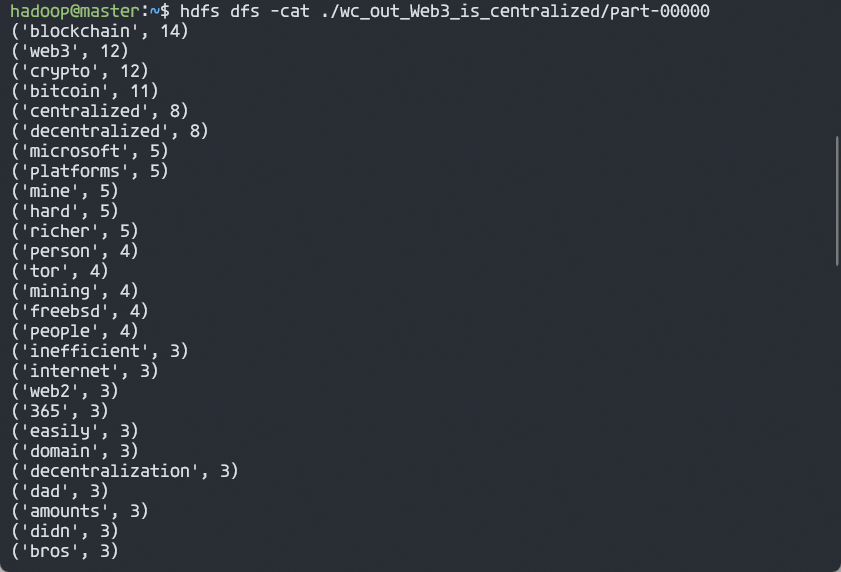
8. 查看结果
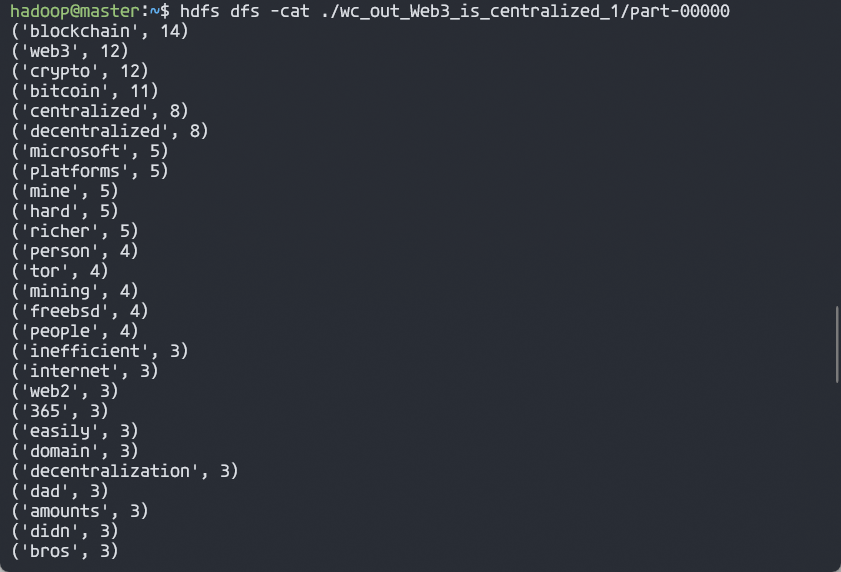
hdfs dfs -cat ./wc_out_Web3_is_centralized/part-00000
B.一句话实现
# 读取停用词
stopdatas = sc.textFile('stopwords.txt').flatMap(lambda a:a.split()).collect()
sc.textFile("Web3_is_centralized.txt")\
.flatMap(lambda line:line.split())\
.map(lambda word:word.lower())\
.flatMap(lambda a:re.split('[\W\_]',a))\
.filter(lambda a:a not in stopdatas)\
.filter(lambda a:len(a)>2)\
.map(lambda word:(word,1))\
.reduceByKey(lambda a,b:a+b)\
.sortBy(lambda wc:wc[1],False)\
.saveAsTextFile("wc_out_Web3_is_centralized_1")
查看结果
hdfs dfs -cat ./wc_out_Web3_is_centralized_1/part-00000
C. 理解Spark编程的特点
- Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
- Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
- Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
二、求Top值
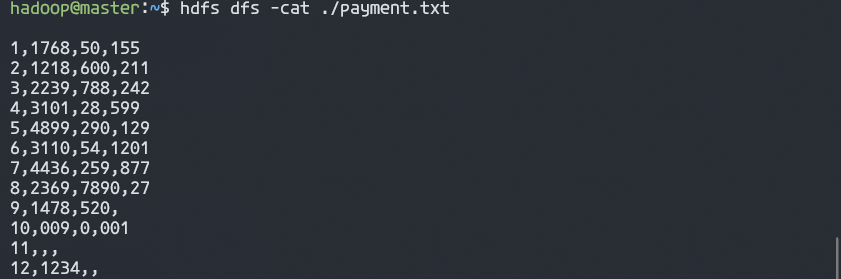
1. 丢弃不合规范的行:
拆分字段
items = lines.map(lambda line:line.split(','))
items.collect()
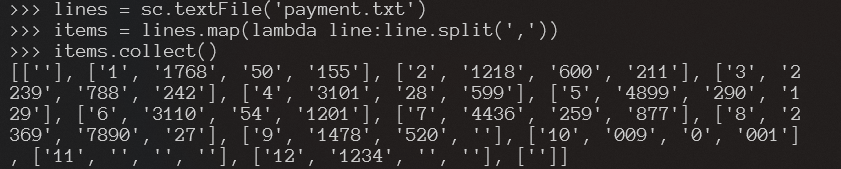
丢弃空行与字段不完整的行
items.map(lambda item:len(item)).collect()
items.count()
items.filter(lambda item:len(item)==4).collect()
items.filter(lambda item:len(item)==4).map(lambda item:len(item)).collect()
items.filter(lambda item:len(item)==4).map(lambda item:len(item)).count()
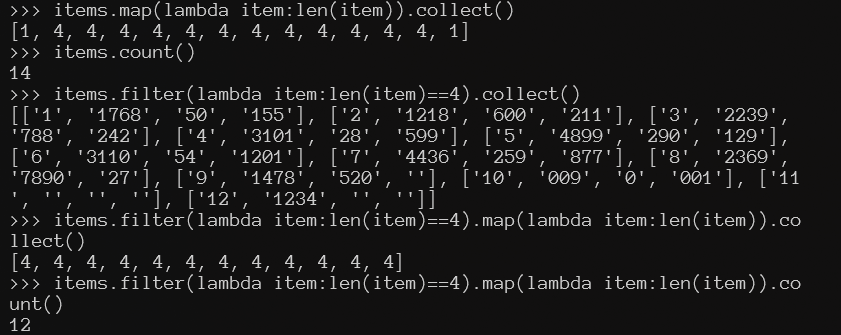
丢弃有空值的行
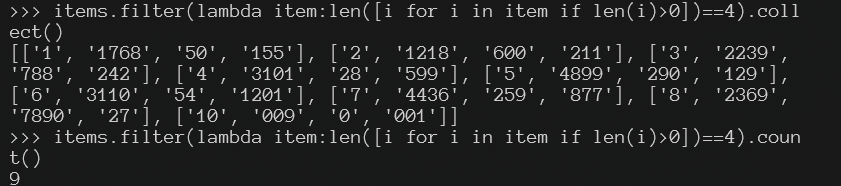
items.filter(lambda item:len([i for i in item if len(i)>0])==4).collect()
items.filter(lambda item:len([i for i in item if len(i)>0])==4).count()
2-3. 按支付金额排序,取出Top3
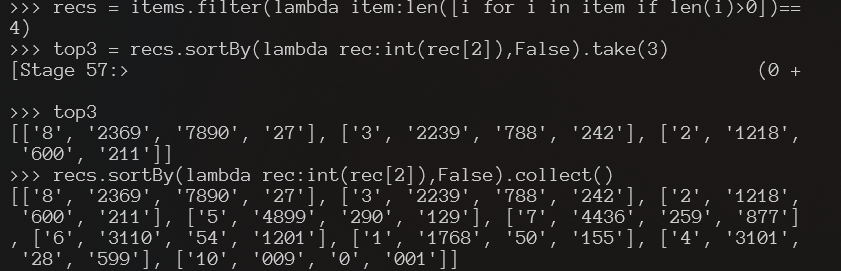
recs = items.filter(lambda item:len([i for i in item if len(i)>0])==4)
recs.sortBy(lambda rec:int(rec[2]),False).collect()
top3 = recs.sortBy(lambda rec:int(rec[2]),False).take(3)
top3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号