发展历史
--------
Apache mesos 资源连接管理器(分布式资源管理框架) 推特在用 加州大学伯克利分校开发出来的
推特使用kubernetes
docker swarm 201907 阿里云宣布 dokcer swarm 踢出
k8s组件说明
borg 组件说明
kubernetes google 10年容器化基础架构 borg go语言 编译borg 开发出来
特点:
轻量级:消耗的资源小
开源
弹性伸缩:资源不够,从一台变成十台,从主节点用一条命令,把一些节点剥离到集群节点里去,如果访问量不需要这些节点,就可以释放节点
负载均衡:IPVS 张文松
软件工程师 测试工程师 运维工程师 项目经理
pod概念
kubernetes中最小的封装集合,在我们容器化里,每个容器就是个封装集合,一个pod里面会封装多个容器,达到一个子节点的的运行环境,它是kubernetes中管理的最小单位
pod协同
管理pod的控制器(kubernetes灵魂):
#deployment
# DaemonSet
#StatefullSet
#Job, Cronjob
#HPA
#RS ,RC
# 在kubernetes里运行一组pod或者一组容器,这容器死亡的话,控制器会发现,并且把这些死亡的容器进行重建,重建它的副本
通讯模式:
网络通讯模式说明
组件通讯模式说明:pod与pod怎么通讯的
#本节点通讯和跨主机通讯
kubernetes安装
系统初始化
kubeadm部署安装
常见问题
资源清单
--------
导演需要剧本,演员就按照剧本内容演出即可,这里的导演和演员,就可以理解为我们kubernetes集群,导演把剧本分发给我们所谓演员k8s子节点,它们通过剧本做自己对应的工作,达到集群化运行,剧本就是我们的资源清单
k8s中资源的概念
什么是资源
名称空间级别的资源
集群级别的资源
资源清单: yam语法格式
通过资源清单编写pod
pod的生命周期 ******
pod phase
容器探针 1 livenessprobe
2 readinessprobe
pod hook
initC
服务发现
我们刚才运行了许多pod,通过服务器运行的,这个pod没办法给一个客户端去访问的,这个客户端可能是一组服务,可能是一个用户,由于我们kubernetes都是一些私有地址,没办法提供客户端访问,那怎么办了,我们通过服务发现,把这个服务暴露给客户端,这样客户端就可以通过我暴露的地址加端口访问我们多个pod,也就说我们能先定义一组pod,就刚说的4盆花,然后定义一个统一的访问入口,如果用户想访问服务的话,那就访问入口即可,并且还是个负载均衡的方案,选择轮训的算法svc原理
service含义
service常见分类 nodePort
clusterIP
ExternalName
service 实现方式 ipvs
iptables
userspace
服务分类
有状态服务 DBMS数据库管理系统
无状态服务 lvs APACHE
# 我是项目经理,老板有接私活,把我踢出去了,干完了又把我推回来,不能很好做nginx
,这就是有状态服务
#我是流水线工人,老板有接私活,把我踢出去,干完又把我推回来,还是做相同简单的工作,这就是无状态服务
# apache 无状态服务 ,它的数据可以通过共享服务来完成,对于主件本身,它不需要数据更新,对于docker来说它更实用于无状态服务中,kubernetes的目标的它必须克服这些有状态服务,它有些数据需要保存
数据保存工具
volume hostPath 存储的基本网页数据
emptyDir
configMap 创建configMap 存储数据文件
pod中使用configMap: 1 configMap代替环境变量 2 configMap设置命令行参数 3 通过数据卷使用configMap
secret service Account 存储用户比较重要的数据密码
kubernetes.io/dockerconfigjson
opaque secret 1 secret 挂载到volume 2 secret 导出环境变量中
PV 动态的创建过程
调度器
------
kubernetes会自动完成,会把这个docker容器调度到对应的节点,能够根据要求把pod定义到想要的节点运行,如果有一天我就想把pod调度到node1节点和node2节点,有一天有个pod1和pod2调度到不同的节点,根据自己的想法把pod调度到不同的节点
集群安全机制
认证 HHTP Token
HHTP Base
HTTP
鉴权 AlwayDeny
AlwayAllow
ABAC
webbook
RBAC 创建一个系统用户管理k8s dev名称空间
to Subjects
Resources
Role and ClusterRole
RBAC
rolebinding and clusteRrolebinding
HELM概念
----------
就是我们linux系统的yum管理器 ,yum安装的是安装包,helm安装的是我们的mougoDB集群,只需要一条命令就可以它部署到k8s中
HElM部署实列:
HELM部署dashboard
metrics-server: HPA 通过cpu当前使用率进行平滑扩展 日志收集 日志展示
资源限制: pod
名称空间
prometheus
EFK
运维
---------
kubernetes高可用构建
kubeadm 源码修改 证书改成很多年,不需要再每年更新,能够构建高可用集群
apiserver: 所有服务访问统一入口
scheduler调度器 负责介绍任务,选择合适节点
把任务交给
apiserver,apiserver把请求写入etcd
RC(replication controller)控制器用来维护副本的数目的或者说是期望值的,我想让容器运行几个副本都是它控制,创建对应的pod或者删除相应的pod
RS(replicaset)控制器我们创建pod的时候会被RS打标签,比如app=apache ,当有一天我们想删除容器做对应的一些设置的时候
Deployment :用来自动管理RS标签,支持滚动更新
node节点安装需要
kubelet 用来维持docker运行周期
kube proxy 负载的工作,默认对象是操作防火墙实现端口映射
docker
k8s组件
-------
apiserver: 所有服务访问统一入口(kubectl etcd RC scheduler kubelet kube proxy)
crontrollerManager控制器:维护副本的期望数目
scheduler调度器:负责接受任务,选择合适的节点进行分配任务,保持这个节点有足够的资源能足够我的pod运行
etcd:键值对数据库,存储k8s集群所有重要信息(持久化),需要持久化的数据,如果我么们想恢复k8s集群的时候,只需要对etcd进行还原即可。
kubelet :直接跟容器引擎交互实现容器的生命周期管理,kubelet接受k8s的指令后先理解指令,然后在把我们理解的转化为container容器能够听懂的命令
kube-proxy:负责写入规则至IPTABLES,IPVS实现服务映射访问的
COREDNS:可以为集群中svc创建一个域名IP的对应关系解析,我集群中访问其他pod的时候,我完全不需要pod的ip地址通过coredns生成一个域名实现访问,它也是集群重要组件,实现负载均衡的其中一项功能。
DASHBOARD:给k8s集群提供一个B/S结构访问体系
ingress controller 官方只能4层代理,ingress可以7层代理,可以更主机名和域名进行负载均衡
federation: 提供一个可以跨集群中心多k8s统一管理的功能
prometheus(普罗米修斯):提供k8s集群的监控能力
ELK: 提供k8s集群日志统一分析接入平台
高可用集群副本数据最好是>=3 奇数个
pause:只要有pod,pause容器就要被启动,一个pause里会有很多个容器,里面的多个pod容器就要共用pause的网络站,共用pause的存储卷,这个多个pod没有自己的ip地址,有的只是pause的地址,一个运行的php,一个运行nginx,nginx想要反向代理,直接localhost:9000即可。在同一个pod里容器的端口不能相同.
RC&RS&Deployment
RC :用来确保容器应用的副本数始终保持在用户定义的副本数,既如果有容器异常退出,会自动创建新的pod来代替;如果异常多出来的容器也会自动回收。
RS : 用来我们创建pod的时候会被RS打标签,比如app=apache ,当有一天我们想删除容器做对应的一些设置的时
Deployment : 是用来自动管理RS的,不用担心不能rolling-update(滚动更新),deployment会创建一个RS1,RS1不是我们定义的,是deployment定义的,deployment在负责创建我们的pod,有一天让deployment更新一下镜像版本,从v1更新v2版本,它会新建一个RS2,每启动一个v2镜像容器就关闭一个v1镜像容器,这样就达到滚动更新的状态,并且可以回滚,v2有小bug了,就可直接回滚kubectl rollout undo deployment/nginx-test
,它就会新建一个老版本的v1,一此类推,为什么能回滚了,应为这个RS并不会被删除,而是被停用,当你回滚,它就会把老版本RS1启用,达到预期状态。
HPA
cpu >80 max 10 min 2
仅使用于deployment和RS ,在v1版本中仅支持根据pod的CPU利用率扩所容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容,HPA也是个对象需要被定义,RS1下管理两个pod,HPA基于RS1去定义的,HPA会去监控pod资源利用率,当cpu达到80的时候RS1会建多个pod ,直到达到它的最大值当cpu利用率变低的时候pod就会被回收,最小值为二。
Statefullset
statefullset是解决有状态服务问题(deployments和RS是为无状态服务而设计),statefullset运用场景: 1 稳定的持久化存储,
一个pod死亡之后从新调度回来,再调度一个新的pod给它取代之后它的存储还之前的存储,并不会变并且里面的数据不会丢失。 2 稳定的网络标识 ,之前的pod叫什么,现在还叫什么,之前的主机名称是什么还是什么,不会变换,防止出现的新的pod名字变了,我们要重新写入,不需要,statefullset会实时的稳定网络标识。 3 有序部署,有序部署分为扩展和回收阶段,叫有序部署和有序回收,有序部署是,只有在前一个pod在runing和ready状态,第二个才可以被创建,mysql ->apche ->nginx .
Daemonset
daemonset是确保全部(或者一些)node上运行一个pod的副本。当有node加入集群时,也会为他们新增一个pod。当有node从集群移除时,这些pod也会被回收。删除daemonset将删除它创建的所有pod.为什么说是一些node了?答 :应为能在我们node上打一些污点,这些污点不会被调度不会运行pod。在一个node上运行了好几个不同pod,我们就可以好几个pod里的主要进程提取出来放到一个pod里不同容器中,通过一个daemonset也可以去设置。
Job
job负责批量处理任务,既仅执行一次的任务,它保证批量处理的一个任务或者多个pod成功结束,我想备份一下我的数据库备份代码,可以把备份代码放pod里去运行,我在pod放到job里去执行一下,这个脚本就可以正常执行一下,就可以把数据库备份出来。1我们封装的pod可以重复利用的,2 如果脚本意外退出是没办法正常执行的,job就会判断这个脚本不是正常退出,它就会重新执行一边,直到正常退出为止,并且还可以设置正常退出的次数,比如正常退出2次这个脚本才执行成功,job含义就是在特定的时间重复执行。
client客户端想要访问一组pod,如果这些pod不相关的话,是不可以通过我们service统一代理的,pod必须要有相关性,比如是同一个RS,RC,deployment创建的,或者拥有同一组标签,都可以被我们service收集到,service收集pod是通过标签去选择到的,选择到后我们的service就会有自己的ip加端口,用户就可以访问service的ip加端口,间接访问到对应的pod,并且还有个Round-Robin(轮巡算法)。
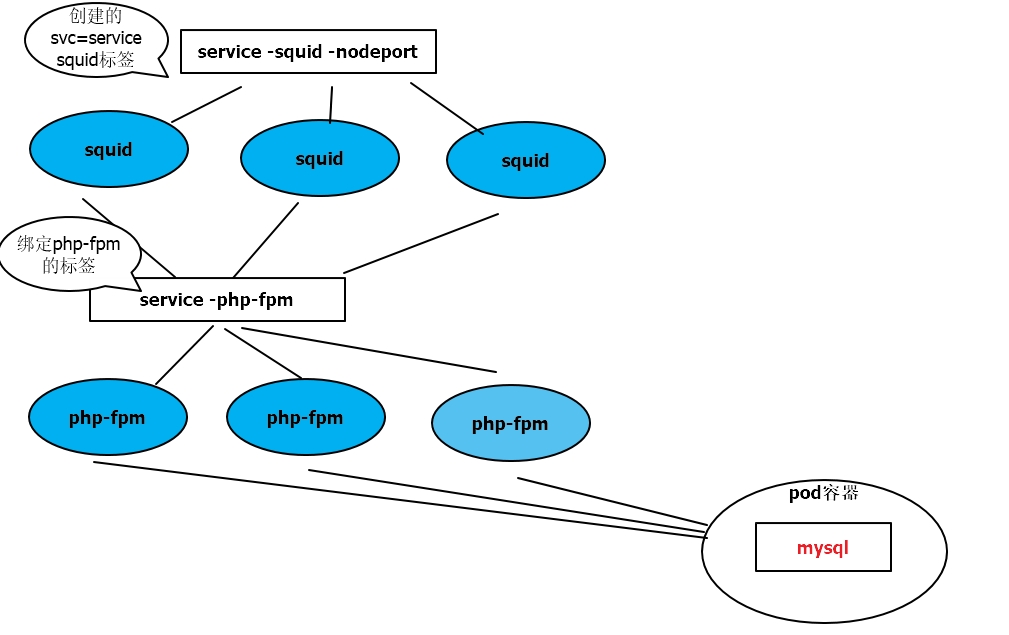
service暴露在外部一种模式nodeport
网络通讯模式
各pod之间的通讯:Overlay Network (全覆盖网络)
pod与service之间的通讯:各节点Iptables规则(ipvs)
Flannel
flannel是coreos团队针对kubernetes设计的一个网络规划服务,让集群的不同节点主机创建的docker容器具有全局唯一的虚拟地址。而且还能再这些IP地址之间建立一个覆盖网络(overlay Network) ,通过这个覆盖网络,将数据包原封不动地传递到目标容器内,我们修改docker启动文件,改docker0分配的网段给它改掉,只要docker0分配的网段不一样,这里容器的ip可定不一样
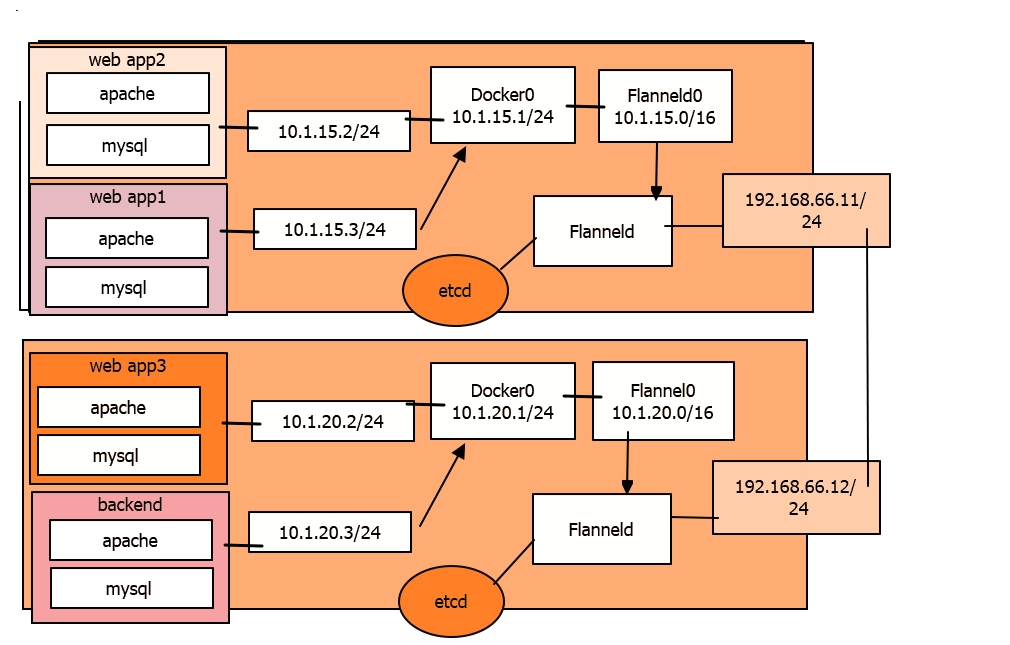
flanneld启动之后会开起一个flannel0,这网桥flannel0专门去收集docker0转发出来的数据报文,可以理解flannel0为钩子函数,强行获取数据报文,让后docker0就会分配自己的ip到对应pod上,如果是同一台主机的两个不同的pod之间访问的话,它走的其实是docker0的网桥,应为大家都在同一个网桥上的两个不同的子网而已。
web app2 --> backend

数据包-->192.168.66.12/24--> flanneld
(目标端口为Flanneld) 只拆了一层
--> docker0 -->backend
(拆第二层)
ETCD与Flannel的关系
etcd最先要高可用组件,官方已经集群化
存储管理flannel可分配的ip地址段资源
flannel启动后,会向etcd里去插入可以被分配的网段,并且把哪个网段分配到哪个机器上它要记录上,防止这个网段在被flannel利用,分配其他的node节点。
监控ETCD中每个pod的实际地址,并在内存中建立维护pod节点路由表
不然会出现找不到66.12这个主机地址。
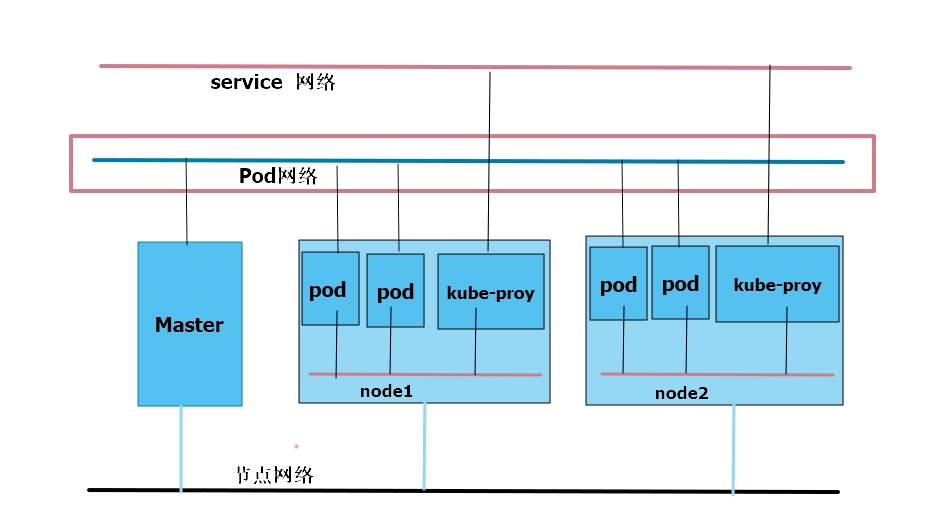
在k8s有三个网络,第一个是节点网络,pod网络,service网络,真实物理网络只有一个节点网络,构建服务器,只需要一张网卡就可以实现。
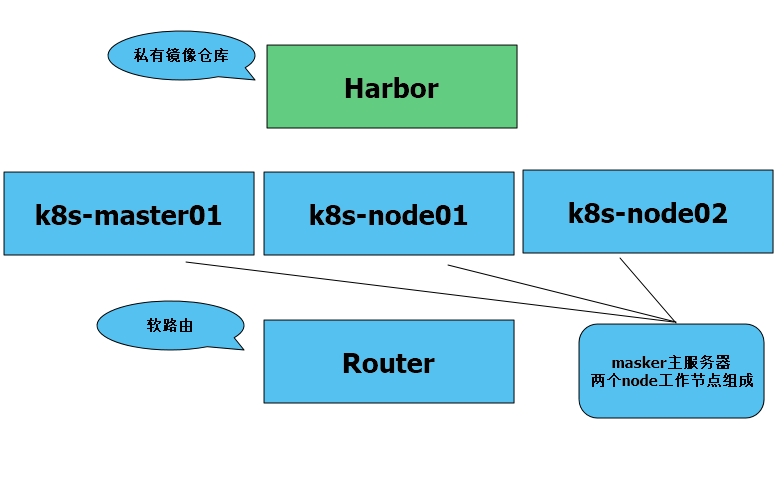
安装方式:k8s官方的集群的安装工具kubedm,源码包构建好处是你能清晰认识它每个组件配置方式,不好的是每个组件都是一个进程的方式,,这些进程可能会死亡,没有自愈功能,世面最好的安装方式是kubedm,我们通过koolshare安装router软路由,harbor,四台centos7,一个软路由。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号