zookeeper客户端KeeperErrorCode = ConnectionLoss异常问题排查历险记
经过线报,说前方应用有异常,导致了可用性变差。咦!讨厌的异常,抛异常是程序猿最讨厌的事情之一。
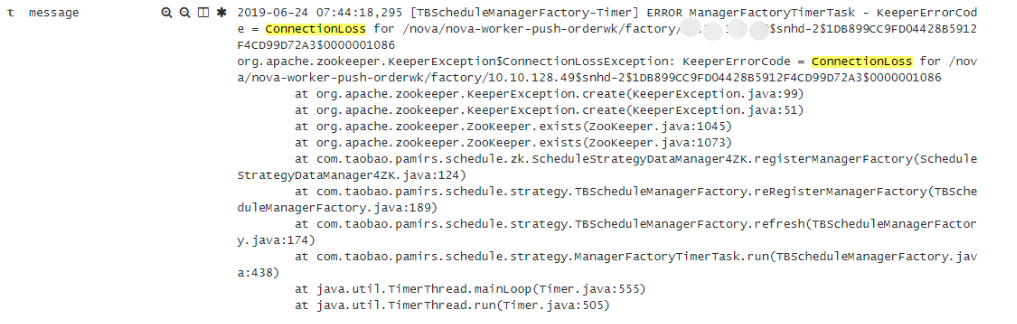
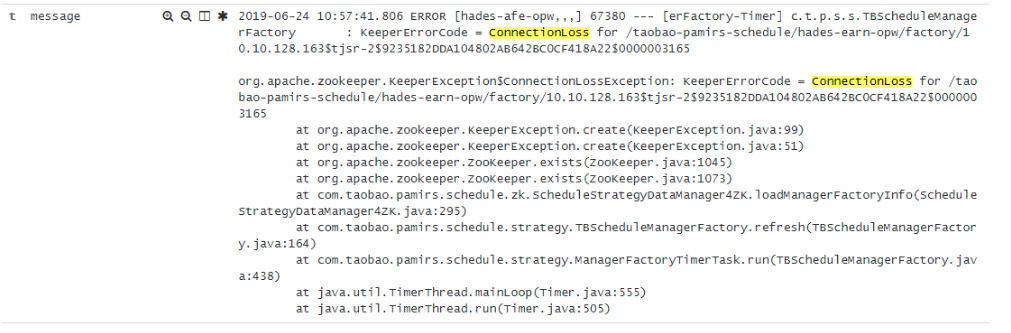
经过收集异常信息如下
![]()
![]()
一看异常很神秘,
从异常的表面意思看就是去zookeeper查询某个node是否存在然后爆出了 KeeperErrorCode = ConnectionLoss这个错误
经过各种查询说需要调优zookeeper,具体情况大家可以自行进行搜索。
我们的实现马上转移到zookeeper上面,观察zk的运行环境。
我们经过了如下各种过程处理(以下是未成功的处理):
加内存:2G-->4G(虽然我们知道加内存没有用,自己心里安慰一下万一能解决那,哈哈)
加CPU:4C-->6C
换磁盘空间并打开虚拟机读写限制
移动虚拟机主机位置
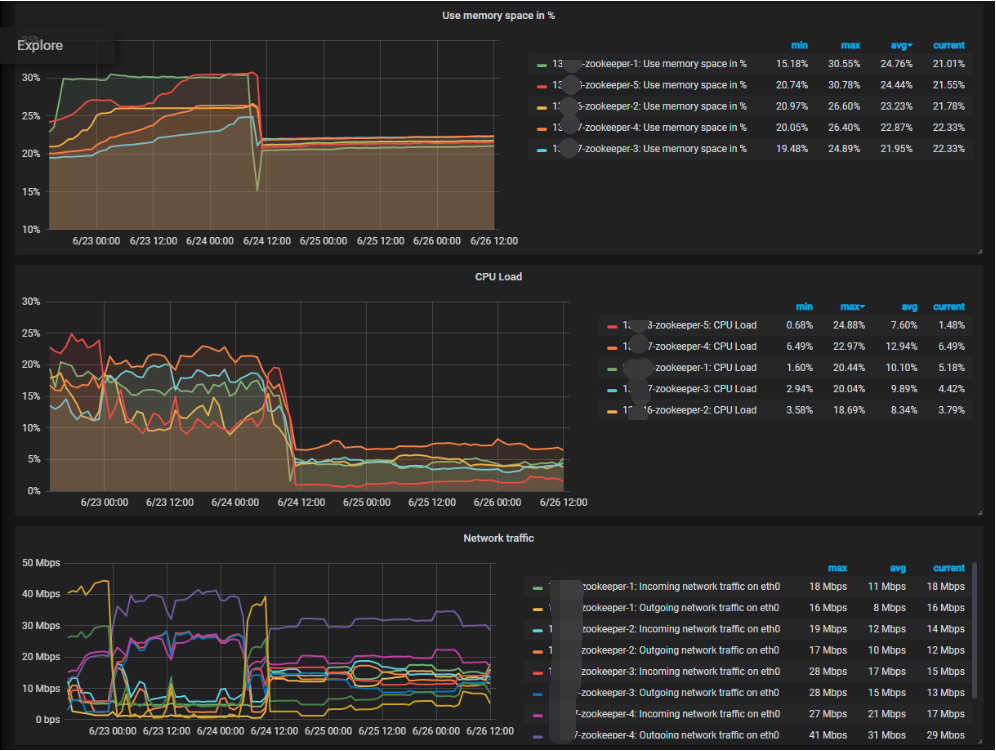
调整前后统计对比图:
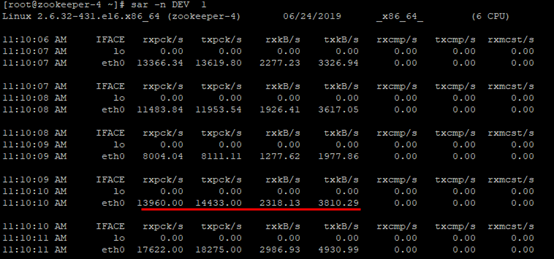
网络 I/O:sar -n DEV 1
![]()
CPU I/O: vmstat 1

磁盘 I/O : sar -d 1

这里我说下经过各种环境的取值分析得出如下现象和结论:
现象:
CPU有点高但是在可接受范围内
内存完全够用不存在内存溢出可能
磁盘读写完全没有达到所能承受的上限
网络同样没有达到可用的上限
问题指标
发现cpu执行的IO等待高,why?
经过各种数据的分析有了如下大胆的猜测,
zookeeper是强一致性的分布式系统,
CAP理论中它属于CP系列,
所以对于读写有强一致的要求,
大量并发情况下对一个文件的读写(zookeeper日志文件 log.xxxxx的那个文件)会有排队想象同时他还会对从机进行分发数据,
搞得主机(master)很忙造成cpu的操作都在等待那一个文件上面,
但实际上读写的内容并不多,
也就没有达到磁盘的上限。
然后就造成了主动断开连接上面的异常 ConnectionLoss。
也就是说这个异常个人猜测是zookeeper的主动行为,否则的话会报超时异常。
所以针对各种分析与搜索以及实践有如下两种方法解决:
- 设置zookeeper本身的参数forceSync=no
- 将日志文件写入目录指向内存句柄
本次采用第二种方法:修改zoo.cfg配置文件:
dataLogDir=/zookeeper/logs 修改为
dataLogDir=/dev/shm
从目前情况看问题基本解决,也请大家调整相关系统框架与zookeeper的心跳频率,以减少zk的压力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号